I released recently cmemgzip which compresses files in memory and then replaces the original. I’ve been working a bit on an experimental feature, and I’ve released a new functionality which is limiting the amount of memory used to read from the original file.
That way, if you have in your server, let’s say 500 GB in a log file, you can specify gmemzip to use, for example, blocks of 400 MB of RAM.
You can use any amount starting from 1 MB. The most you use, the better compression you’ll get (as compression is based on repeated patterns). But you have to think that the compressed data requires also some space, so is a good idea to use something around 100 MB of RAM if the log files are really huge and the amount of memory is limited.
For example, in one of my Servers in Amazon:
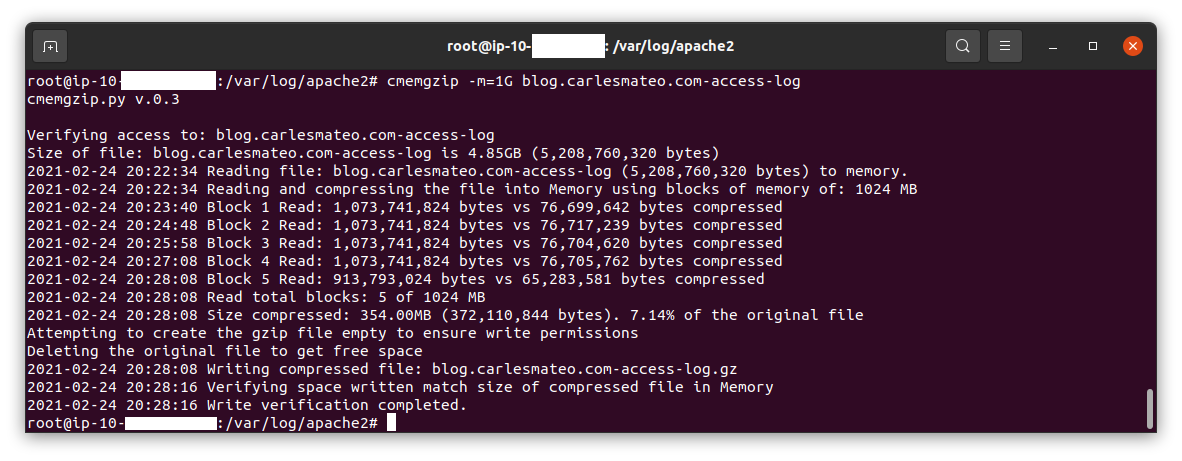
I’ve added a PDF Manual for the usage.
I’ve created also an stable page for the project:
Rules for writing a Comment