More funny things happened like when I was installing a VirtualBox VM live, and the ZFS pool became irresponsible due hardware errors in one SATA Spinning drive.
Things from broadcasting live…
Some of the feedback I got from talented Engineers is that even if the original matter to talk about was interesting, seeing everything falling apart live due to unexpected hardware problems, and me troubleshooting live is being the best of the show… which I found very amusing.
RAB Radio the new digital world
I keep doing my radio space for Radio America Barcelona, once per week, addressed to the Catalan Community across the world and expats.
This radio program, streamed also via Twitch, is available in Catalan language only. RAB.
Open Source
carleslibs
I’ve been working in version 1.0.8 branch, and after a session of refactor on Twitch where I found a bug in MenuUtils class, I fixed it and released v. 1.0.8. You can see the video on the link.
Now I’m working on the branch v. 1.0.9.
ctop
I’ve been working in the branch 0.8.9.
My first Twitch broadcast was about adding Unit Testing to MemUtils class.
This week I decommissioned my last physical server in a Data Center.
It has been a long journey since I created my company to launch my own projects, and I started having my own infrastructure, back at 2000.
I was offering VPS at that time, with VMWare as Hypervisor.
This last Rack Server served me well for 21 years.
Now everything is Cloud, and is not viable to host and maintain servers unless this is your main occupation. Server’s motherboards die, hard drives die and they need to be replaced. Maintaining infrastructure it’s a full time job and you require somebody to do it. Also using fixed servers only prevents you from moving fast, locks a lot of money, and from spawning more compute capacity.
If you are curious this Rack Server is a Super Micro with Intel Xeon processor and SCSI drives.
Security
Firewall
I keep blocking thousands of IP Addresses every day.
When I see a pattern of an IP trying an attacks against the Server I look at the IP and if it’s from a hosting provider I just block the entire range.
I keep blocking any IP Address coming from Russia or Belarus since they invaded Ukraine.
My Health
I visited the hospital for a programmed following on my health.
The analysis are super good, and it’s super clear that I’ve improved radically. My discipline with the diet, taking the medicines and doing exercise regularly has been crucial.
My Doctor is confident that I’ll have a full recovery, but to do so I need to loss a lot of weight in a year or two.
So, I need to focus on my health and in doing exercise, being happy and avoid any kind of negative stress.
The cost of the travels and the medicines have put some stress into my economy, but I’m fortunate that I can handle it.
Entertainment / Life / Reflections
Star Wars and racism
I’m really enjoying new Start Wars series Obi Wan, and I’ve been profoundly shocked to read that there are fans being racist against the black characters.
In this very long session we went through actual errors in a ZFS pool, we check the Kernel, we remove and reinsert the drive, conduct zpool scrub… in the meantime I talked about Rack, Rack Servers, PSU, redundant components, ECC RAM…
I have read a lot of wrong recommendations about the use of Swap and Swappiness so I want to bring some light about it.
The first to say is that every project is different, so it is not possible to make a general rule. However in most of the cases we want systems to operate as fast and efficiently as possible.
So this suggestions try to covert 99% of the cases.
By default Linux will try to be as efficient as possible. So for example, it will use Free Memory to keep IO efficient by keeping in Memory cache and buffers.
That means that if you are using files often, Linux will keep that information cached in RAM.
The swappiness Kernel setting defines what tradeoff will take Linux between keeping buffers with Free Memory and using the available Swap Memory.
# sysctl vm.swappiness
vm.swappiness = 60
The default value is 60 and more or less means that when RAM memory gets to 60%, swap will start to be used.
And so we can find Servers with 256GB of RAM, that when they start to use more than 153 GB of RAM, they start to swap.
Let’s analyze the output of free -h:
carles@vbi78g:~/Desktop/Software/checkswap$ free -h
total used free shared buff/cache available
Mem: 2.9Gi 1.6Gi 148Mi 77Mi 1.2Gi 1.1Gi
Swap: 2.0Gi 27Mi 2.0Gi
So from this VM that has 2.9GB of RAM Memory, 1.6GB are used by applications.
The are 148MB that can immediately used by Applications, and there are 1.2GB in buffers/cache. Does that means that we can only use 148MB (plus swap)?. No, that mean that Linux tried to optimize io speed by keeping 1.2GB of RAM memory in buffers. But this is the best effort of Linux to have performance, for real applications will be also able to use 1.1GB that corresponds to the available field.
About swap, from 2GB, only 27MB have been used.
As vm.swappiness is set to 60, more RAM will be swapped out to swap, even if we have lots available.
As I said every case is different. If we are talking about a Desktop that has NVMe drives, the impact will be low. But if we are talking about a Server that is a hypervisor running VMs and has high usage on CPU and has the swap partition or the swap in a file, that could lead to huge problems. If there is a physical Server with a single spinning drive (or logical unit through RAID), and one partition is for Swap, and the other for mountpoints, and a process is heavily reading/writing to a partition mounted (an elastic search, or a telegraf, prometheus…), and the System tries to swap, then they will be competing for the magnetic head of disk, slowing down everything.
If you take a look on how the process of swapping memory pages from the memory to disk, you will understand that applications may need certain pages before being able to run, so in many cases we get to lock situations, that force everything to wait.
In my career I found Servers that temporarily stopped responding to ping. After a while ping came back, I was able to ssh and uptime showed that the Server did not reboot.
I troubleshooted that, and I saw a combination of high CPU usage spikes and Swap usage.
Using iostat and iotop I monitored what was speed of transference of only 1 MB/second!!.
I even did swapoff and it took one hour to free 4 GB swap partition!.
I also saw swap partition being in a spinning disk, and in another partition of the same spinning drive, having a swapfile. Magnetic spinning drives can only access one are of the drive at the same time, so that situation, using swap is very bad.
And I have seen situations were the swap or swapfile was mounted in a block device shared via network with the Server (like iSCSI or NFS), causing terrible performance when swapping.
So you have to adapt the strategy according to the project.
My preferred strategy for Compute Nodes and NoSQL Databases is to not use swap at all. In other cases, like MySQL Databases I may set swappiness to preferably to 1 or to 10.
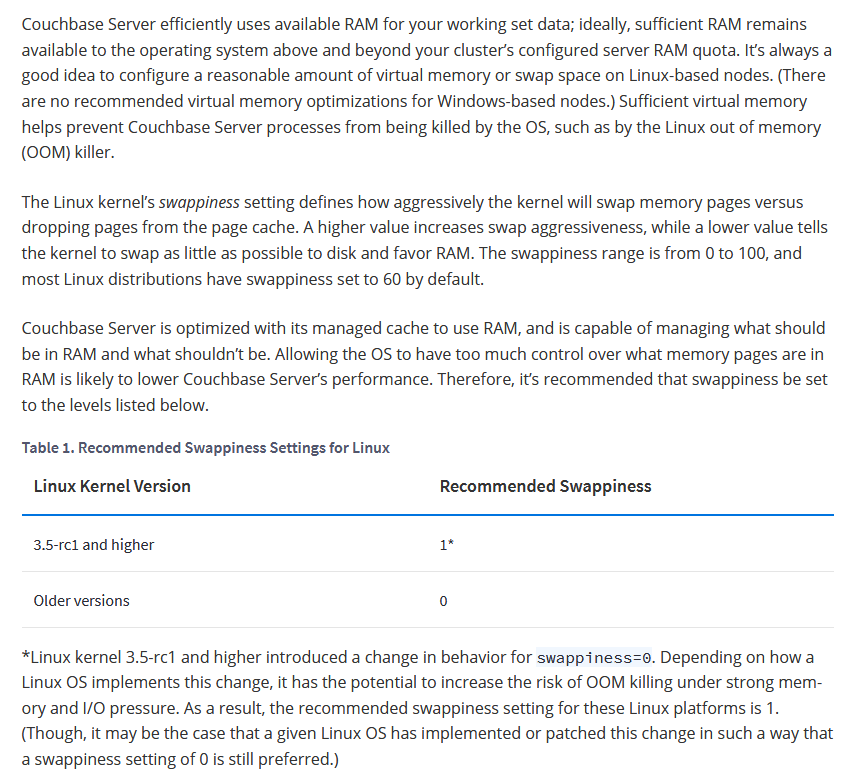
The Linux kernel’s swappiness setting defines how aggressively the kernel will swap memory pages versus dropping pages from the page cache. A higher value increases swap aggressiveness, while a lower value tells the kernel to swap as little as possible to disk and favor RAM. The swappiness range is from 0 to 100, and most Linux distributions have swappiness set to 60 by default.
Couchbase Server is optimized with its managed cache to use RAM, and is capable of managing what should be in RAM and what shouldn’t be. Allowing the OS to have too much control over what memory pages are in RAM is likely to lower Couchbase Server’s performance. Therefore, it’s recommended that swappiness be set to the levels listed below.
Another theme, is when you log to a Server and you see all the Swap memory in use.
Linux may have moved the pages that were less used, and that may be Ok for some cases, for example a Cron Service that waits and runs every 24 hours. It is safe to swap that (as long as the swap IO is decent).
When Kernel Swaps it may generate locks.
But if we log to a Server and all the Swap is in use, how can we know that the Swap has been quiet there?.
Well, you can use iostat or iotop or you can:
cat /proc/vmstat
This file contains a lot of values related to Memory, we will focus on:
Paging refers to writing portions, termed pages, of a process’ memory to disk. Swapping, strictly speaking, refers to writing the entire process, not just part, to disk. In Linux, true swapping is exceedingly rare, but the terms paging and swapping often are used interchangeably.
page-out: The system’s free memory is less than a threshold “lotsfree” and unnused / least used pages are moved to the swap area. page-in: One process which is running requested for a page that is not in the current memory (page-fault), it’s pages are being brought back to memory. swap-out: System is thrashing and has deactivated a process and it’s memory pages are moved into the swap area. swap-in: A deactivated process is back to work and it’s pages are being brought into the memory.
Values from /proc/vmstat:
pgpgin, pgpgout – number of pages that are read from disk and written to memory, you usually don’t need to care that much about these numbers
pswpin, pswpout – you may want to track these numbers per time (via some monitoring like prometheus), if there are spikes it means system is heavily swapping and you have a problem.
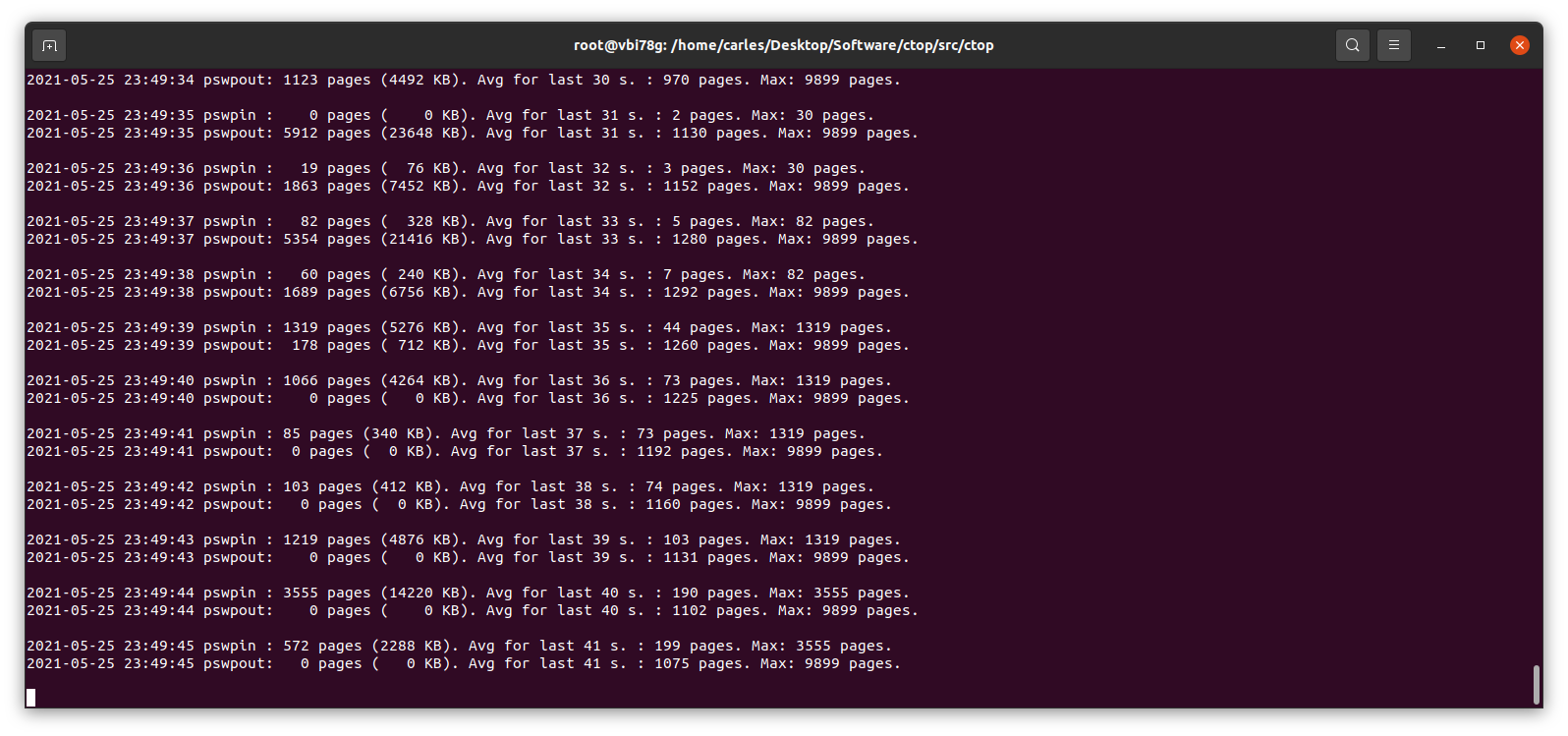
In this actual example that means that since the start of the Server there has been 508992338 Page Swap In (with 4K memory pages this is 1,941 GB, so almost 2 TB transferred) and for Page Swat Out (with 4K memory pages this is 1,071 GB, so 1 TB of transferred). I’m talking about a Server that had a 4GB swap partition in a spinning disk and a 12 GB swapfile in another ext4 partition of the same spinning disk.
The 16 GB of swap were in use and iotop showed only two sources of IO, one being 2 VMs writing, another was a journaling process writing to the mountpoint where the swapfile was. That was an spinning drive (underlying hardware was raid, for simplicity I refer to one single drive. I checked that both spinning drives were healthy and fast). I saw small variations in the size of the Swap, so I decided to monitor the changes in pswpin and pswpout in /proc/vmstat to see how much was transferred from/to swap.
I saw then how many pages were being transferred!.
I wrote a small Python program to track those changes:
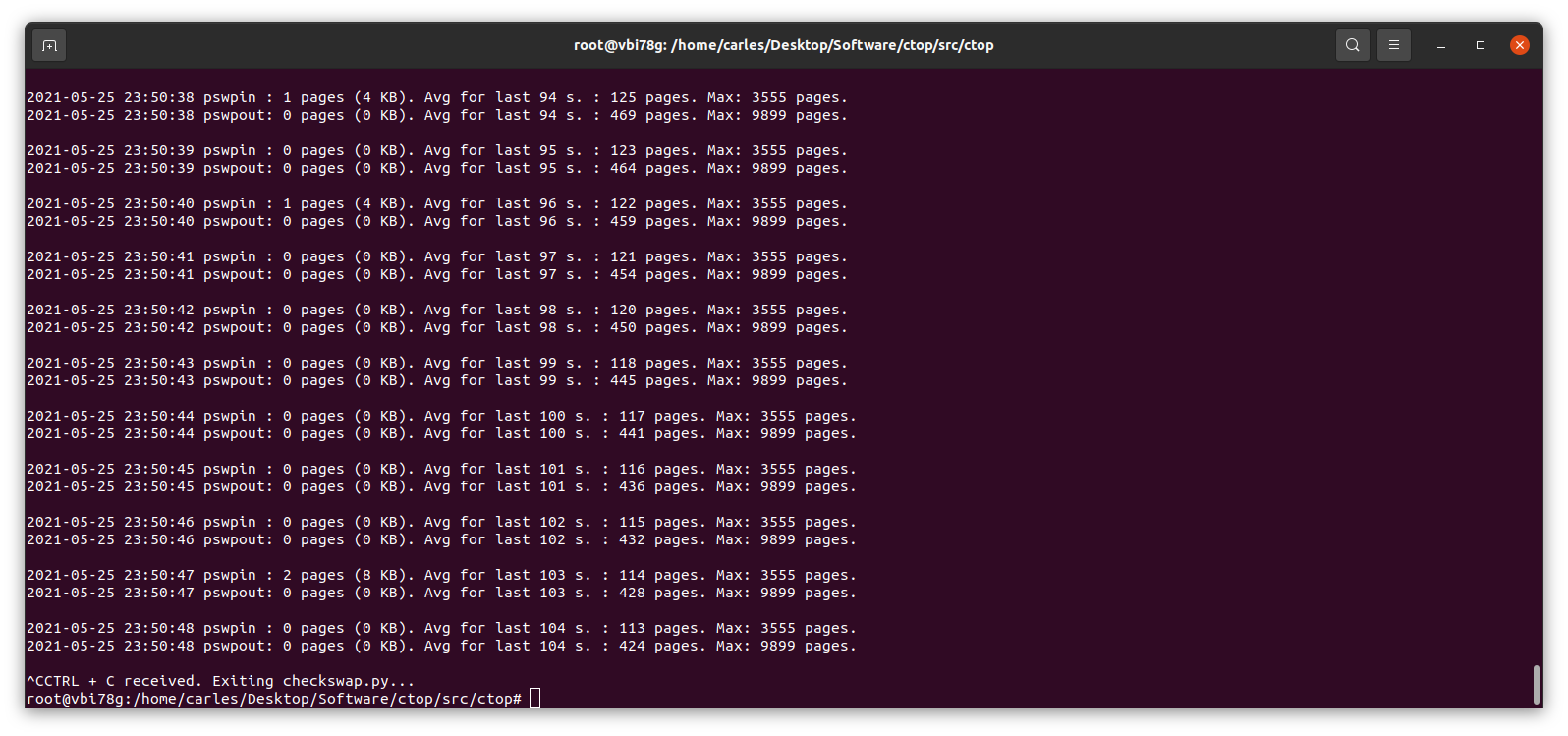
This little program works in Python 2 and Python 3, and will show the evolution of pswpin and pswpout in /proc/vmstat and will offer the average for last 5 minutes and keep the max value detected as well.
As those values show the page swaps since the start of the Server, my little program, makes the adjustments to show the Page Swaps per second.
A cheap way to reproduce collapse by using swap is using VirtualBox: install an Ubuntu 20.04 LTS in there, with 2 GB of less of memory, and one single core. Ping that VM from elsewhere.
Then you may run a little program like this in order to force it to swap:
#!/usr/bin/env python3
a_items = []
i_total = 0
# Add zeros if your VM has more memory
for i in range(0, 10000000):
i_total = i_total + i
a_items.append(i_total)
And checkswap will show you the spikes:
Many voices are discordant. Some say swappiness default value of 60 is good, as Linux will use the RAM memory to optimize the IO. In my experience, I’ve seen Hypervisors Servers running Virtual Machines that fit on the available physical RAM and were doing pure CPU calculations, no IO, and the Hypervisor was swapping just because it had swappiness to 60. Also having swap on spinning drives, mixing swap partition and swapfile, and that slowing down everything. In a case like that it would be much better not using Swap at all.
In most cases the price of Swapping to disk is much more higher than the advantage than a buffer for IO brings. And in the case of a swapfile, well, it’s also a file, so my suspect is that the swapfile is also buffered. Nothing I recommend, honestly.
My program https://gitlab.com/carles.mateo/checkswap may help you to demonstrate how much damage the swapping is doing in terms of IO. Combine it with iostat and iotop --only to see how much bandwidth is wasted writing and reading from/to swap.
You may run checkswap from a screen session and launch it with tee so results are logged. For example:
python3 checkswap.py | tee 2021-05-27-2107-checkswap.log
If you want to automatically add the datetime you can use:
python3 checkswap.py | tee `date +%Y-%m-%d-%H%M`-checkswap.log
Press CTRL + a and then d, in order to leave the screen session and return to regular Bash.
Type screen -r to resume your session if this was the only screen session running in background.
An interesting reflection from help Ubuntu:
The “diminishing returns” means that if you need more swap space than twice your RAM size, you’d better add more RAM as Hard Disk Drive (HDD) access is about 10³ slower then RAM access, so something that would take 1 second, suddenly takes more then 15 minutes! And still more then a minute on a fast Solid State Drive (SSD)…
I’ve been working for years within Data centers, with D&R strategies, and then in the middle of COVID-19, with huge demands on increments of bandwidth and compute, some DCs decided to do not allow in the Engineers of their customers.
As somebody that had my own Startup and CSP and had infrastructure in DCs and servers from customers in colocation, and has replaced Hw components at 1AM, replaced drives from broken RAIDs, and fixed systems so many times inside so many Datacenters across the world, I’m shocked about that.
I understand health reasons can be argued, but I still have Servers in Datacenters because we all believed they were the most safe place, prepared for disaster and recovery, with security, 24×7… and now, one realise that cannot enter to fix or upgrade the own machines.
Please note, still you can use the remote hands from the DC, although this is not a good idea many times, I’m not sure this will still be an available option when the lock down in those countries becomes more strict.
I’m wondering if DCs current model have any future at all.
I think most of the D&R strategies from now will be in the cloud, in different regions, with different providers, so companies can resist providers or governments letting them down.
In coding theory, an erasure code is a forward error correction (FEC) code under the assumption of bit erasures (rather than bit errors), which transforms a message of k symbols into a longer message (code word) with n symbols such that the original message can be recovered from a subset of the n symbols. The fraction r = k/n is called the code rate. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception efficiency.
So Raid systems applied to drives are Erasure Code too.
But I want to talk about Erasure Code for the needs of organizations like Instagram, that need to store huge amount of files and they cannot afford to lose the data simply because several drives, or all the Server, fails.
So what is the way to make this sure if you have thousands of Servers?.
Many Start ups that require to host files, cannot afford to have every file duplicated or triplicated in other systems.
So how to do this in a cheap an efficient way?.
Here is where Erasure Coding comes to play.
Erasure Coding work so simply as:
Given a given file, for example, 1 video of 10 MB
We apply the Erasure Coding to encode the file
We select, for example, to generate 3 additional chunks
So our original 10MB file fill be split in 13 blocks (13 new files), each block will have approx. 1MB
We can rebuild the original file by combining any 10 of those 13 files
That means that we can afford to loss 3 blocks (1MB files) and we will still be able to reconstruct the original file.
Examples:
Ok, so now imagine we have 13 identical Servers, and we encode all our files, using Erasure Coding. Imagine that we store each block in a different Server. That means that we can lose 3 Servers and still have all our information intact.
Imagine we have 100 Servers, and we split all those files to the Servers that have more free space available. We could lose 3 Serversand still not having lose any information. If we are really lucky (or the SDS – Software Defined Storage is very clever) we could lose more than 3 Servers.
Now imagine we have 100 Racks full of Servers. Our SDS selects the Rack that has more free space and places one of the blocks in there, and the same for the other 12 blocks. We could afford to lose 3 racks without losing any Data. That’s more manageable for Google or Yahoo than managing at Server Level.
We can use Erasure coding with different configs like 8+3, or 10+4… The sample I choose 10+3 is easy to understand, as we clearly see that will occupy only 30% of additional space.
Those blocks can conveniently be stored in different Servers, across different regions too, for example, using a config of 9+3 you can have 4 different Cloud Providers in different geographic regions, and each holding 25% of the required files, so 3 files each. Then, you only require 3 Cloud providers to rebuild the original file (you only precise 9 surviving blocks, not all 12). Possibilities are infinite.
When one Rack is down, you can rebalance all the blocks that were there to another rack.
Also you can have different Servers, with different capacity… your SDS should be clever enough to accommodate the blocks for protection and space efficiency. To checksum them to ensure no corruption in the block as was stored or transported over the network. Your SDS Software should be clever enough to be able to add new nodes and Racks, and to substract nodes, to Rebalance, to checksum the blocks in the Servers… and to store the information effectively on the local Servers (not many files per folder…), to use Commodity Hardware with low memory, or even VM’s… if your System is good enough it will even put to sleep, to save energy, the Servers that are not in use (typically the Servers that are full), until required.
Also, when in need to recover a file, the clever SDS Software, using multithread, will ask to the 9 locations at the same time, in parallel, so using all the available bandwidth, in order to fetch the blocks and rebuild the original file really quick. This can also be implemented with no single point of failure, will all the nodes being able to be the headnode.
That’s exactly what my Erasure Coding solution did.
I invented a lot of technologies to scale out since I created my messenger in 1996.
You can do it yourself, or use existing Erasure Coding solutions. The most known is OpenStack Swift, although in my opinion is a pain to configure and to maintain.
This is the history it happen to me some time ago, and so the commands I used to troubleshot. The purpose is to share knowledge in a interactive way. There are some hidden gems that you’ll acquire if you have the patience to go over all the document and read it all…
I had qualified Intel Xeon single processor platform to run my DRAID (ZFS Declustered RAID) project for my employer.
The platforms I qualified were:
1) single processor for Cold Storage (SAS Spinning drives): 4U60, newest models 4602
2) for multiprocessor: the 4U90 (90 Spinning drives) and Flash: All-Flash-Arrays.
The amounts of RAM I was using for my tests range for 64GB to 384GB.
Somebody in the company, at executive level, assembled an experimental config that was totally new for us and wanted to try by their own. It was the 4602 with multiprocessor and 32GB of RAM.
When they were unable to make it work at the expected speed, they required me to troubleshot and to make it work.
The 4602 single processor had two IOC (Input Output Controller, LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ), while the 4602 double processor had four IOC, so given that each of those IOC can perform at peaks of 6GB/s, with a maximum total of 24 GB/s, the performance when reading/writing from all the drives should be better.
But this Server was returning double times for Rebuilding, respect the single processor version, which didn’t make any sense.
I had to check everything. There was the commands I ran:
Check the upgrade of the CPU:
htop
lscpu
Changing the Zoning.
Those Servers use SAS drives dual ported, which means that two different computers can be connected to the same drive and operate at the same time. Is up to you to make sure you don’t introduce corruption. Those systems are used mainly for HA (High Availability).
Those Systems allow to be configured in different zoning modes. That’s the way on how each of the two servers (Controllers) see the disk. In one zoning each Controller sees only 30 drives, in another each IOC sees all the drives (for redundancy but performance constrained to 1 IOC Speed).
The config I set is each IOC will see 15 drives, so each one of the 4 IOC will have 6GB/s for 15 drives. Given that these spinning drives perform in the outtermost part of the cylinder at 265MB/s, that means that at maximum speed one IOC will be using 3.97 GB/s, will say 4GB/s. Plenty of bandwidth.
Note: Spinning drives have different performance depending on how close you’re to the cylinder. In the innermost part it goes under 145 MB/s, and if you read all of those drive sequentially with dd it will return an average speed of 145 MB/s.
With this command you can sive live how it performs and the average read speed in real time. Use skip to jump to that position (relative to bs) in the drive, so you can test directly the speed at the innermost close to the cylinder part of t.
dd if=/dev/sda of=/dev/null bs=1M status=progress
I saw that the zoning was not right one, so I set it correctly:
The sleeps after rebooting the expanders are recommended. Rebooting the Operating System too, to avoid problems with some Software as the expanders changed live.
If you have ZFS pools or workloads stop them and export the pool before messing with the expanders.
In order to check to which drives is connected each IOC:
I do this for all the drives at the same time and with iostat:
iostat -y 1 1
I check the status of the memory with:
slabtop
free
htop
I checked the memory and htop during a Rebuild. Memory was more than enough. However CPU usage was higher than expected.
The red bars in the image correspond to kernel processes, in this case is the DRAID Rebuild. I see that the load is higher than the usual with a single processor.
I capture all the parameters from ZFS with:
zfs get all
All this information is logged into my forensics document, so later can be checked by my Team or I can share with other Architects or other members of the company. I started this methodology after I knew how Google do their SRE forensics / postmortem documents. Also for myself is useful for the future to have a log of the commands I executed and a verbose output of the results.
I install the smp_utils
yum install smp_utils
Check things:
ls -al /dev/bsg/
total 0drwxr-xr-x. 2 root root 3020 May 22 10:16 .
drwxr-xr-x. 20 root root 8680 May 22 10:16 ..
crw-------. 1 root root 248, 76 May 22 10:00 1:0:0:0
crw-------. 1 root root 248, 126 May 22 10:00 10:0:0:0
crw-------. 1 root root 248, 127 May 22 10:00 10:0:1:0
crw-------. 1 root root 248, 136 May 22 10:00 10:0:10:0
crw-------. 1 root root 248, 137 May 22 10:00 10:0:11:0
crw-------. 1 root root 248, 138 May 22 10:00 10:0:12:0
crw-------. 1 root root 248, 139 May 22 10:00 10:0:13:0
[...]
There are some errors, and I check with the Hardware Team, which pass a battery of tests on the machine and say that the machine passes. They tell me that if the errors counted were in order of millions then it would be a problem, but having few of them is usual.
My colleagues previously reported that the memory was performing well, and the CPU too. They told me that the speed was exactly double respect a platform with one single CPU of the same kind.
Even if they told me that, I ran cmips tests to make sure.
git clone https://github.com/cmips/cmips_bin
It scored 16,000. The performance was Ok in general terms but the problem is that I didn’t have a baseline for that processor in single processor, so I cannot make sure that the memory bandwidth was Ok. The performance was less that an Amazon c3.8xlarge. The system I was testing is a two processor system, but each CPU is cheap, around USD $400.
Still my gut feeling was telling me that this double processor server should score more.
lscpu
[root@DRAID-1135-14TB-2CPU ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2299.951
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4199.73
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts spec_ctrl intel_stibp
I check the memory configuration with:
dmidecode -t memory
I examined the results, I see that the processor can only operate the DDR4 ECC 2400 Memory at 2133 and… I see something!. This Controller before was a single processor with 2 Memory Sticks of 16GB each, dual rank.
I see that now I have the same number of sticks in that machine, but I have two CPU!. So 2 Memory sticks in total, for 2 CPU.
That’s no good. The memory must be in pairs and in the right slots to get the maximum performance.
1 memory module for 1 CPU doesn’t allow to have Dual Channel and probably is affecting the performance. Many Servers will not even boot if you add an odd number of memory sticks per CPU.
And many Servers can operate at full speed only if all the banks are filled.
I request to the Engineers in Silicon Valley to add 4 modules in the right slots. They did, and I repeated the tests and the performance was doubled then.
After some days I had some time with the machine, I repeated the test and I got a CMIPS Score of around 20,000.
Multiprocessor world is far more complicated than single processor. Some times things can work not as expected, and not be evident, for example cache pipeline can act diferent for a program working in multiprocessor and single processor. Or the QPI could be saturated.
After this I shared my forensics document with as many Engineers as I could, so they could learn how I did to troubleshot the problem, and what was the origin of it, and I asked them to do the same so we can track their steps and progress if something needs to be troubleshoot.
After proper intensive testing the Server was qualified. Lesson here is that changes cannot be commited quickly, need their time.
This trick may be useful for you. Almost surely if you power cycle, completely powering down your Server you’ll fix booting too. Unfortunately we do not always have access to the Data Center or Remote Hands service available, so this trick may be useful for you.
Note 2019-05-28:This article was written in 2013. It is still valid, but since then 10Gbps have dropped in price a lot. In my DRAID Solution I’ve qualified 10GbE based in copper, RJ45, and for fiber: 10, 25, 40 and 100 Gbps. Mellanox switches and NICs are a reference. 10GbE based in copper are cheap and easy to deploy, as you can reuse existing infrastructure and grow your segments. https://en.wikipedia.org/wiki/10_Gigabit_Ethernet
I’ve found this problem in several companies, and I’ve had to show their error and convince experienced SysAdmins, CTOs and CEO about the erroneous approach. Many of them made heavy investments in NAS, that they are really wasting, and offering very poor performance.
Normally the rack servers have their local disks, but for professional solutions, like virtual machines, blade servers, and hundreds of servers the local disk are not used.
NAS – Network Attached Storage- Servers are used instead.
This NAS Servers, when are powerful (and expensive) offer very interesting features like hot backups, hot backups that do not slow the system (the most advanced), hot disk replacement, hot increase of total available space, the Enterprise solutions can replicate and copy data from different NAS in different countries, etc…
Smaller NAS are also used in configurations like Webservers’ Webfarms, were all the nodes has to have the same information replicated, and when a used uploads a new profile image, has to be available to all the webservers for example.
In this configurations servers save and retrieve the needed data from the NAS Servers, through LAN (Local Area Network).
The main error I have seen is that no one ever considers the pipe where all the data is travelling, so most configurations are simply Gigabit, and so are bottleneck.
Imagine a Dell blade server, like this in the image on the left.
This enclosure hosts 16 servers, hot plugable, with up to two CPU’s each blade, we also call those blade servers “pizza” (like we call before to rack servers).
A common use is to use those servers to have Vmware, OpenStack, Xen or other virtualization software, so the servers run instances of customers. In this scenario the virtual disks (the hard disk of the virtual machines) are stored in the NAS Server.
So if a customer shutdown his virtual server, and start it later, the physical server where its virtual machine is running will be another, but the data (the disk of the virtual server) is stored in the NAS and all the data is saved and retrieved from the NAS.
The enclosure is connected to the NAS through a Gigabit connection, as 10 Gigabit connections are still too expensive and not yet supported in many servers.
Once we have explained that, imagine, those 16 servers, each with 4 or 5 virtual machines, accessing to their disks through a Gigabit connection.
If only one of these 80 virtual machines is accessing to disk, the will be no problem, but if more than one is accessing the Gigabit connection, that’s a maximum of 125 MB (Megabytes) per second, will be shared among all the virtual machines.
So imagine, 70 virtual machines are accessing NAS to serve web pages, with not much traffic, OK, but the other 10 virtual machines are doing heavy data transmission: for example one is serving data through FTP server, the other is broadcasting video, the other is copying heavy log files, and so… Imagine that scenario.
The 125 MB per second is divided between the 80 servers, so those 10 servers using extensively the disk will monopolize the bandwidth, but even those 10 servers will have around 12,5 MB each, that is 100 Mbit each and is very slow.
Imagine one of the virtual machines broadcast video. To broadcast video, first it has to get it from the NAS (the chunks of data), so this node serving video will be able to serve different videos to few customers, as the network will not provide more than 12,5 MB under the circumstances provided.
This is a simplified scenario, as many other things has to be taken in count, like the SATA, SCSI and SAS disks do not provide sustained speeds, speed depends on locating the info, fragmentation, etc… also has to be considered that NAS use protocol iSCSI, a sort of SCSI commands sent through the Ethernet. And Tcp/Ip uses verifications in their protocol, and protocol headers. That is also an overhead. I’ve considered only traffic in one direction, so the servers downloading from the NAS, as assuming Gigabit full duplex, so Gigabit for sending and Gigabit for receiving.
So instead of 125 MB per second we have available around 100 MB per second with a Gigabit or even less.
Also the virtualization servers try to handle a bit better the disk access, by keeping a cache in memory, and not writing immediately to disk.
So you can’t do dd tests in virtual machines like you would do in any Linux with local disks, and if you do go for big files, like 10 GB with random data (not just 0, they have optimizations for that).
Let’s recalculate it now:
70 virtual machines using as low as 0.10 MB/second each, that’s 7 MB/second. That’s really optimist as most webservers running PHP read many big files for attending a simple request and webservers server a lot of big images.
10 virtual machines using extensively the NAS, so sharing 100 MB – 7 MB = 93 MB. That is 9.3 MB each.
So under these circumstances for a virtual machine trying to read from disk a file of 1 GB (1000 MB), this operation will take 107 seconds, so 1:47 minutes.
So with this considerations in mind, you can imagine that the performance of the virtual machines under those configurations are leaved to the luck. The luck that nobody else of the other guests in the servers are abusing the disk I/O.
I’ve explained you in a theoretical plan. Sadly reality is worst. A lot worst. Those 70 web virtual machines with webservers will be so slow that they will leave your company very disappointed, and the other 10 will not even be happier.
One of the principal problems of Amazon EC2 has been always disk performance. Few months ago they released IOPS, high performance disks, that are more expensive, but faster.
It has to be recognized that in Amazon they are always improving.
They have also connection between your servers at 10 Gbit/second.
Returning to the Blades and NAS, an easy improvement is to aggregate two Gigabits, so creating a connection of 2 Gbit. This helps a bit. Is not the solution, but helps.
Probably different physical servers with few virtual machines and a dedicated 1 Gbit connection (or 2 Gbit by 1+1 aggregated if possible) to the NAS, and using local disks as much as possible would be much better (harder to maintain at big scale, but much much better performance).
But if you provide infrastructure as a Service (IaS) go with 2 x 10 Gbit Fibre aggregated, so 20 Gigabit, or better aggregate 2 x 20 Gbit Fibre. It’s expensive, but crucial.
Now compare the 9.3 MB per second, or even the 125 MB theoretical of Gigabit of the average real sequential read of 50 MB/second that a SATA disk can offer when connected on local, or nearly the double for modern SAS 15.000 rpm disks… (writing is always slower)
… and the 550 MB/s for reading and 550 MB/s for writing that some SSD disks offer when connected locally. (I own two OSZ SSD disks that performs 550 MB).
I’ve seen also better configuration for local disks, like a good disk controller with Raid 5 and disks SSD. With my dd tests I got more than 900 MB per second for writing!.
So if you are going to spend 30.000 € in your NAS with SATA disks (really bad solution as SATA is domestic technology not aimed to work 24×7 and not even fast) or SAS disks, and 30.000 € more in your blade servers, think very well what you need and what configuration you will use. Contact experts, but real experts, not supposedly real experts.
Otherwise you’ll waste your money and your customers will have very very poor performance on these times where applications on the Internet demand more and more performance.