So I show here how I launched a fresh Ubuntu 24.04 in Google Cloud, on 2026-05-04, and demostrate the exploit of escalation privileges Copy Fail (CVE-2026-31431) which allows you to become root from a regular user account in almost any Linux since year 2017.
It consists in the execution of a Python 3 code, which is only 732 bytes.
I show how I fixed it by upgrading the kernel and rebooting.
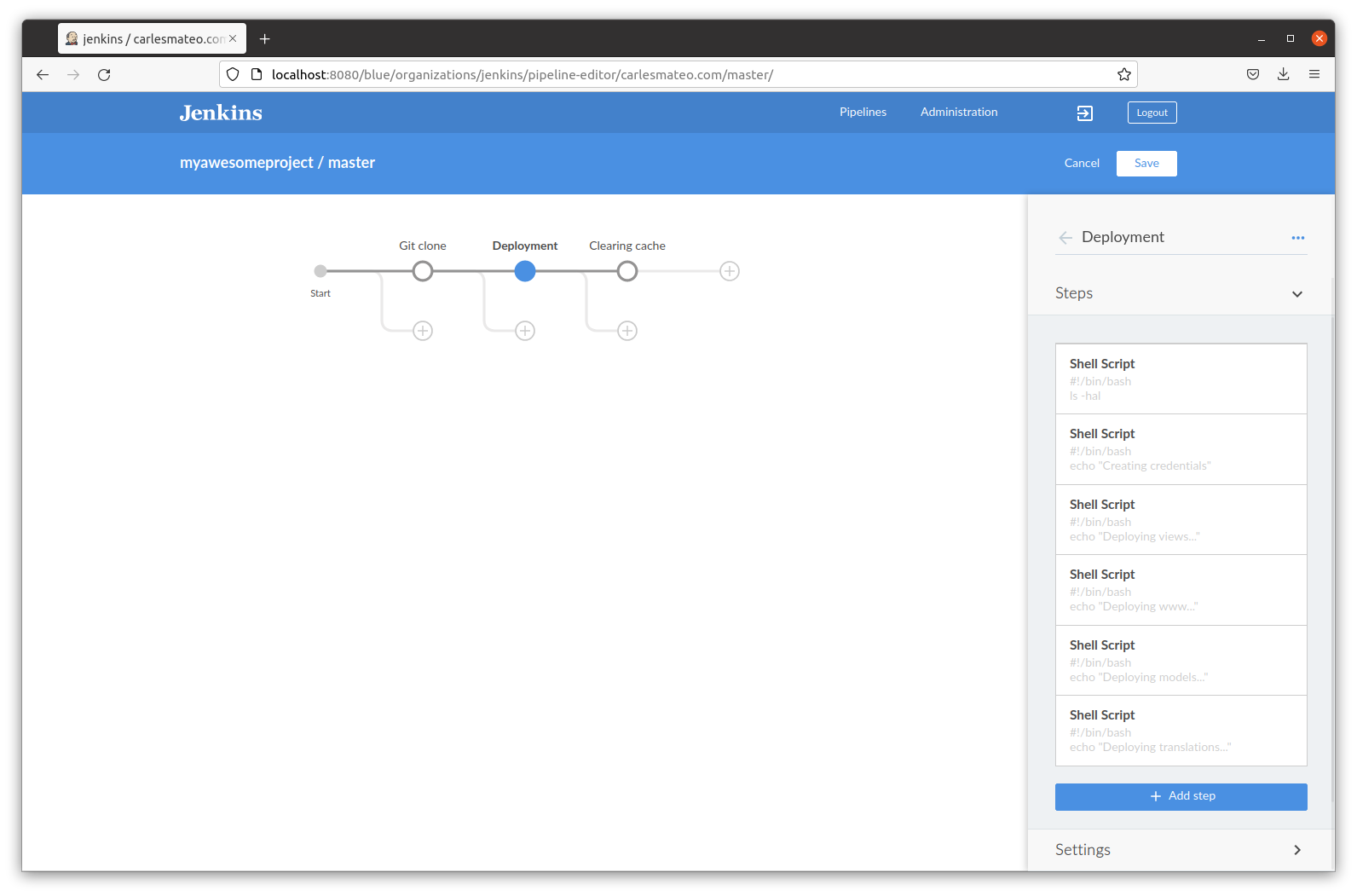
You have installed eZ Launchpad, and you can execute the binary ez from your home folder or other paths, however when you execute it from a project folder you cloned with git (with its .platform.app.yaml file) ez returns to prompt without any error message.
The exit code is 255, but even if you strace the process you don’t find the exact problem.
Inside your project you run ez without any argument in a clean install of Ubuntu 24.04 LTS with PHP 8.3, or with PHP 8.4, without xDebug, without opcache, without memory limit… nothing works with no visible error message in the logs or in the error output. However if you run it outside the project folder, it works, and it displays the typical help messages.
I reproduced this behavior on several Ubuntu computers. The fix I found is to execute ez with PHP 8.1
You can install PHP8.1 from ondrej repository, then you can update alternates to execute PHP 8.1 by default in your system, or you create the project by invoking ez with PHP 8.1 explicitly with:
php8.1 ~/ez create
This will kickstart the creation of your ez project based on Docker containers.
If you are getting an error like this when you try to provision using rsync or running commands from SSH from a Docker Instance from a worker node in Jenkins, having your SSH Key as a variable in Jenkins, here is a way to solve it.
These are the kind of errors that you’ll be receiving:
Load key "ssh_yourserver": invalid format
web@myserver.carlesmateo.com: Permission denied (publickey).
rsync: connection unexpectedly closed (0 bytes received so far) [sender]
rsync error: unexplained error (code 255) at io.c(235) [sender=3.1.3]
script returned exit code 255
So this applies if you copied your .pem file as text and pasted in a variable in Jenkins.
You’ll find yourself with the load key invalid format error.
I would suggest to use tokens and Vault or Consul instead of pasting a SSH Key, but if you need to just solve this ASAP that’s the trick that you need.
First encode your key with base64 without any wrapping. This is done with this command:
Note that in this case I’m ignoring Strict Host Key Checking, which is not the preferred option for security, but you may want to use it depending on your strategy and characteristics of your Cloud Deployments.
Note also that I’m indicating as User Known Hosts File /dev/null. That is something you may want to have is you provision using Docker Containers that immediately destroyed after and Jenkins has not created the user properly and it is unable to write to ~home/.ssh/known_hosts
I mention the typical errors where engineers go crazy and spend more time fixing.
As in my case my jenkins container Id is 77b6a5a7ae8d in order to know the jenkins administrator password I check the logs for my jenkins Container with docker logs 77b6a5a7ae8d:
docker logs 77b6a5a7ae8d
Running from: /usr/share/jenkins/jenkins.war
webroot: EnvVars.masterEnvVars.get("JENKINS_HOME")
2022-06-26 21:02:05.492+0000 [id=1] INFO org.eclipse.jetty.util.log.Log#initialized: Logging initialized @549ms to org.eclipse.jetty.util.log.JavaUtilLog
2022-06-26 21:02:05.583+0000 [id=1] INFO winstone.Logger#logInternal: Beginning extraction from war file
2022-06-26 21:02:05.613+0000 [id=1] WARNING o.e.j.s.handler.ContextHandler#setContextPath: Empty contextPath
2022-06-26 21:02:05.674+0000 [id=1] INFO org.eclipse.jetty.server.Server#doStart: jetty-9.4.45.v20220203; built: 2022-02-03T09:14:34.105Z; git: 4a0c91c0be53805e3fcffdcdcc9587d5301863db; jvm 11.0.15+10
2022-06-26 21:02:05.986+0000 [id=1] INFO o.e.j.w.StandardDescriptorProcessor#visitServlet: NO JSP Support for /, did not find org.eclipse.jetty.jsp.JettyJspServlet
2022-06-26 21:02:06.020+0000 [id=1] INFO o.e.j.s.s.DefaultSessionIdManager#doStart: DefaultSessionIdManager workerName=node0
2022-06-26 21:02:06.020+0000 [id=1] INFO o.e.j.s.s.DefaultSessionIdManager#doStart: No SessionScavenger set, using defaults
2022-06-26 21:02:06.021+0000 [id=1] INFO o.e.j.server.session.HouseKeeper#startScavenging: node0 Scavenging every 600000ms
2022-06-26 21:02:06.463+0000 [id=1] INFO hudson.WebAppMain#contextInitialized: Jenkins home directory: /var/jenkins_home found at: EnvVars.masterEnvVars.get("JENKINS_HOME")
2022-06-26 21:02:06.647+0000 [id=1] INFO o.e.j.s.handler.ContextHandler#doStart: Started w.@7cf7aee{Jenkins v2.346.1,/,file:///var/jenkins_home/war/,AVAILABLE}{/var/jenkins_home/war}
2022-06-26 21:02:06.668+0000 [id=1] INFO o.e.j.server.AbstractConnector#doStart: Started ServerConnector@4c402120{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
2022-06-26 21:02:06.669+0000 [id=1] INFO org.eclipse.jetty.server.Server#doStart: Started @1727ms
2022-06-26 21:02:06.669+0000 [id=25] INFO winstone.Logger#logInternal: Winstone Servlet Engine running: controlPort=disabled
2022-06-26 21:02:06.925+0000 [id=32] INFO jenkins.InitReactorRunner$1#onAttained: Started initialization
2022-06-26 21:02:07.214+0000 [id=39] INFO jenkins.InitReactorRunner$1#onAttained: Listed all plugins
2022-06-26 21:02:10.781+0000 [id=47] INFO jenkins.InitReactorRunner$1#onAttained: Prepared all plugins
2022-06-26 21:02:10.794+0000 [id=35] INFO jenkins.InitReactorRunner$1#onAttained: Started all plugins
2022-06-26 21:02:10.803+0000 [id=42] INFO jenkins.InitReactorRunner$1#onAttained: Augmented all extensions
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.codehaus.groovy.vmplugin.v7.Java7$1 (file:/var/jenkins_home/war/WEB-INF/lib/groovy-all-2.4.21.jar) to constructor java.lang.invoke.MethodHandles$Lookup(java.lang.Class,int)
WARNING: Please consider reporting this to the maintainers of org.codehaus.groovy.vmplugin.v7.Java7$1
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2022-06-26 21:02:11.634+0000 [id=30] INFO jenkins.InitReactorRunner$1#onAttained: System config loaded
2022-06-26 21:02:11.635+0000 [id=30] INFO jenkins.InitReactorRunner$1#onAttained: System config adapted
2022-06-26 21:02:11.642+0000 [id=48] INFO jenkins.InitReactorRunner$1#onAttained: Loaded all jobs
2022-06-26 21:02:11.645+0000 [id=46] INFO jenkins.InitReactorRunner$1#onAttained: Configuration for all jobs updated
2022-06-26 21:02:11.668+0000 [id=67] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$1: Started Download metadata
2022-06-26 21:02:11.675+0000 [id=67] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$1: Finished Download metadata. 4 ms
2022-06-26 21:02:11.733+0000 [id=52] INFO jenkins.install.SetupWizard#init:
*************************************************************
*************************************************************
*************************************************************
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
3de0910b83894b9294989552e6fa9773
This may also be found at: /var/jenkins_home/secrets/initialAdminPassword
*************************************************************
*************************************************************
*************************************************************
2022-06-26 21:02:22.901+0000 [id=52] INFO jenkins.InitReactorRunner$1#onAttained: Completed initialization
2022-06-26 21:02:23.013+0000 [id=24] INFO hudson.lifecycle.Lifecycle#onReady: Jenkins is fully up and running
In my case the password is at the bottom, between the stars: 3de0910b83894b9294989552e6fa9773
sudo apt install python2 python3 python3-pip
# Install boto for Python 2 for Ansible (alternative way if pip install boto doesn't work for you)
python2 -m pip install boto
# Install Ansible
sudo apt install ansible
If you want to use Dynamic Inventory
So you can use the Python 2 ec2.py and ec2.ini files, adding them as to the /etc/ansible with mask +x, to use the Dynamic Inventory.
Then use the calls inside the shell script, or assuming that the previous file was named credentiasl.sh use source credentials.sh
ec2.py is written in Python 2, so probably will fail for you as it is invoked by python and your default interpreter will be Python 3.
So edit the first line of /etc/ansible/ec2.py and add:
#!/bin/env python2
Once credentials.sh is sourced, then you can just invoke ec2.py to get the list of your Instances in a JSON format dumped by ec2.py
/etc/ansible/ec2.py --list
You can get that JSON file and load it and get the information you need, filtering by group.
You can call:
/etc/ansible/ec2.py --list > instances.json
Or you can run a Python program that escapes to shell and executes ec2.py –list and loads the Output as a JSON file.
I use my carleslibs here to escape to shell using my class SubProcessUtils. You can install them, they are Open Source, or you can code manually if you prefer importing subprocess Python library and catching the stdout, stderr.
import json
from carleslibs import SubProcessUtils
if __name__ == "__main__":
s_command = "/etc/ansible/ec2.py"
o_subprocess = SubProcessUtils()
i_error_code, s_output, s_error = o_subprocess.execute_command_for_output(s_command, b_shell=True, b_convert_to_ascii=True, b_convert_to_utf8=False)
if i_error_code != 0:
print("Error escaping to shell!", i_error_code)
print(s_error)
exit(1)
json = json.loads(s_output)
d_hosts = json["_meta"]["hostvars"]
for s_host in d_hosts:
# You'll get a ip/hostnamename in s_host which is the key
# You have to check for groups and the value for the key Name, in order to get the Name of the group
# As an exercise, print(d_hosts[s_host]) and look for:
# @TODO: Capture the s_group_name
# @TODO: Capture the s_addres
if s_group_name == "yourgroup":
# This filters only the instances with your group name, as you want to create an inventory file just for them
# That's because you don't want to launch the playbook for all the instances, but for those in your group name in the inventory file.
a_hostnames.append(s_address)
# After this you can parse you list a_hostnames and generate an inventory file yourinventoryfile
# The [ec2hosts] in your inventory file must match the hosts section in your yaml files
# You'll execute your playbook with:
# ansible-playbook -i yourinventoryfile youryamlfile.yaml
So an example of a yaml to install Apache2 in Ubuntu 20.04 LTS spawned instances , let’s call it install_apache2.yaml would be:
---
- name: Update web servers
hosts: ec2hosts
remote_user: ubuntu
tasks:
- name: Ensure Apache is at the latest version
apt:
name: apache2
state: latest
update_cache: yes
become: yes
As you can see the section hosts: in the YAML playbook matches the [ec2hosts] in your inventory file.
You can choose to have your private key certificate .pem file in /etc/ansible/ansible.cfg or if you want to have different certificates per host, add them after the ip/address in your inventory file, like in this example:
The first method is to use add_host to print in the screen the properties form the ec2 Instances provisioned.
The trick is to escape to shell, executing ansible-playbook and capturing the output, then parsing the text looking for the ‘public_ip:’
This is the Python 3 code I created:
class AwesomeAnsible:
def extract_public_ips_from_text(self, s_text=""):
"""
Extracts the addresses returned by Ansible
:param s_text:
:return: Boolean for success, Array with the Ip's
"""
b_found = False
a_ips = []
i_count = 0
while True:
i_count += 1
if i_count > 20:
print("Breaking look")
break
s_substr = "'public_ip': '"
i_first_pos = s_text.find(s_substr)
if i_first_pos > -1:
s_text_sub = s_text[i_first_pos + len(s_substr):]
# Find the ending delimiter
i_second_pos = s_text_sub.find("'")
if i_second_pos > -1:
b_found = True
s_ip = s_text_sub[0:i_second_pos]
a_ips.append(s_ip)
s_text_sub = s_text_sub[i_second_pos:]
s_text = s_text_sub
continue
# No more Ip's
break
return b_found, a_ips
Then you’ll use with something like:
# Catching the Ip's from the output
b_success, a_ips = self.extract_public_ips_from_text(s_output)
if b_success is True:
print("Public Ips:")
s_ips = ""
for s_ip in a_ips:
print(s_ip)
s_ips = s_ips + self.get_ip_text_line_for_inventory(s_ip)
print("Adding Ips to group1_inventory file")
self.o_fileutils.append_to_file("group1_inventory", s_ips)
print()
The get_ip_text_line_for_inventory_method() returns a line for the inventory file, with the ip and the key to use separated by a tab (\t):
def get_ip_text_line_for_inventory(self, s_ip, s_key_path="ansible.pem"):
"""
Returns the line to add to the inventory, with the Ip and the keypath
"""
return s_ip + "\tansible_ssh_private_key_file=" + s_key_path + "\n"
Once you have the inventory file, like this below, you can execute the playbook for your group of hosts:
You can run this Bash Shell Script to get only the public ips when you provision to Amazon AWS EC2 the Instances from your group named group1 in this case:
I set again the credentials because as this Bash Shell Script is invoked from Python, there are not sourced.
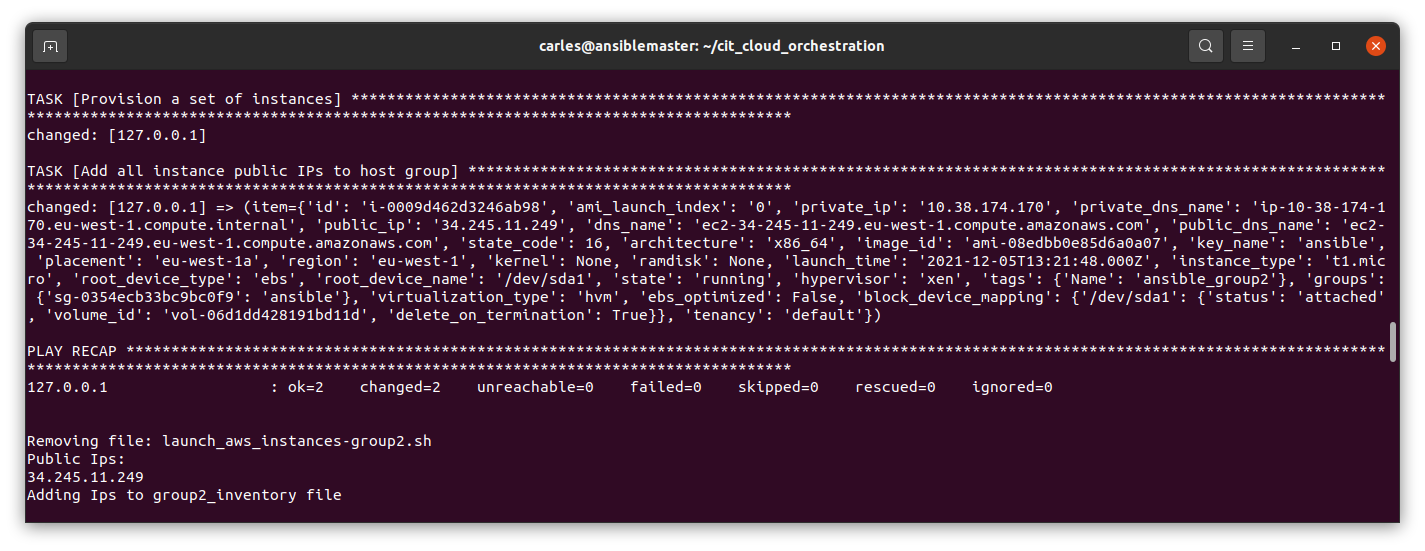
The trick in here is that the launch_aws_instances-group1.yaml file has a task to add the hosts to Ansible’s in memory inventory, and to print the information.
That output is what I scrap from Python and then I use extract_public_ips_from_text() showed before.
So my launch_aws_instances-group1.yaml (which I generate from Python customizing the parameter) looks like this:
In this case I use t1.micro cause I provision to EC2-Classic and not to the default VPC, otherwise I would use t2.micro.
So I have a Security Group named ansible created in Amazon AWS EC2 console as EC2-Classic, and not as VPC.
In this Security group I opened the Inbound HTTP Port and the SSH port for the Ip from I’m provisioning, so Ansible can SSH using the Key ansible.pem
The Public Key has been created and named ansible as well (section key_name under ec2).
The Image used is Ubuntu 20.04 LTS (free tier) for the region eu-west-1 which is my wonderful Ireland.
For the variables (vars) I use the MT Notation, so the prefixes show exactly what we are expecting s_ for Strings i_ for Integers and I never have collisions with reserved names.
It is very important to use the count_tag and instance_tags with the name of the group, as the actions will be using that group name. Remember the idempotency.
The task with the add_host is the one that makes the information for the instances to be displayed, like in this screenshot.
Only 2% of the viewers donate, so I answered the call every time it was made.
This is my 5th donation to Wikimedia.
I consider that Freedom is very important.
I bought these new books
One of my secrets to be on top is that I’m always studying.
I study all the time, at work and in my free time.
I use Linux Academy and I buy books in paper. I don’t connect with reading in tablets. I think information is stored better when read in paper. I use also a marker and pointers to keep a direct access to the most interesting points on the books.
And I study all kind of themes. Obviously I know a lot of Web Scraping, but there is always room for learning more. And whatever new I learn helps me to be better with my students and more clear writing my books.
I’ve never been a Front End, but I’ve been able to fix bugs in the Front End engines from the companies I worked for, like Privalia. I was passed a bug that prevented the Internet Explorer users to buy just one hour before we launching a massive campaign. I debugged and I found a variable named “value” so the html looked like <input name="value" value="">. In less than 30 minutes I proved to the incredulous Head of Development and the CTO that a bug in Internet Explored was causing a conflict when fetching the value from the input named value. We deployed to Production the update and the campaign was a total success. So I consider knowing Javascript and Front also a need, even if I don’t work directly with it. I want to be able to understand all the requirements and possibilities, and weaknesses, so I can fix bugs and save the day. That allowed me to fix scalability problems in Nodejs and Phantomjs projects too. (They are Javascript Server Side, event driven, projects)
It seems that Amazon.co.uk works well again for Ireland. My two last orders arrived on time and I had no problems of border taxes apparently.
Nice Python article
I enjoyed a lot this article, cause explains part of what I did with my student and friend Albert, in a project that analyzes the access logs from Apache for patterns of attempts of exploits, then feeds a database, and then blocks those offender Ip Addresses in the Firewall.
The article only covers the part of Pandas, of reading the access.log file and working with it, but is a very well redacted article:
Here is the complete history of why I migrated all the services from my 11 years old Amazon account to other CSP.
Some lessons can be learned from my adventure.
I migrated my last services from Amazon to GCP
Amazon sent me an email on October 6th, this year 2021, telling me that they will disable EC2-Classic by August 2022. I thought I would not be able to keep my Static Ip’s as in the past VPC Ip’s and EC2-Classic Ip’s were not transferable, so considering that I would loss my Static Ip’s anyway I started to migrate to some to other providers like Digital Ocean.
Is not cool losing Static Ip (Elastic Ip in AWS) Addresses as this is bad for SEO, so given that I though I would lose my Static Ips that have been with me for years, I started to migrate certain services to providers much more economic.
Amazon is terrible communicating, and I talked with some product managers in the past about that, when they lost one of my Volumes, and the email was so cold and terrible that actually that hurt more than Amazon losing my Data. I believed that it was a poorly made Scam and when I realized it was true I reached one of my friends, that is manager there, as I know they care for doing things right, and he organized a meeting with two PM so I can pass my feedback.
The Cloud providers are changing things very fast, and nobody is able to be up to date with the changes, unless their work position allows plenty of time to get updated. Even if pages of documentation are provided, you have to react to an event that they externally generated forcing you to action. Action to read all the documentation about EC2-Classic migrations, action to prepare to have migrated by August 2022.
So August 2022… I was counting that I had plenty of time but I’m writing a new book about using the Amazon SDK for Python, boto3, and I was doing some API calls and they started to fail in a very unusual way, Exceptions with timeout, but only for the only region where I had EC2-Classic.
urllib3.exceptions.NewConnectionError: <botocore.awsrequest.AWSHTTPSConnection object at 0x7f0347d545e0>: Failed to establish a new connection: [Errno -2] Name or service not known
But if I switched to another region name, it would work:
region_name='us-west-2',
I made a mistake in here, the region name is “us-east-1” and not “us-east-1a“. “us-east-1a” is the availability zone. So the SDK was giving a timeout because in order to connect to the endpoint it uses the region name as part of the hostname. So it doesn’t find that endpoint because it doesn’t exist.
I never understood why a company like Amazon is unable to provide the SDK with a sample project or projects 100% working, with the source code so people has a base that works to build up.
Every API that I have created, I have provided it with documentation but also with example for several languages for how to use it.
In 2013 I was CTO of an online travel agency, and we had meta-searchers consuming our API and we were having several hundreds of thousands requests per second. Everything was perfectly documented, examples were provided for several languages, the document and the SDK had version numbers…
Everybody forgets about Developers and companies throw terrible and cold products to the poor Developers, so difficult to use. How many Developers would like to say: Listen Mr. President of the big Cloud Company XXXX, I only want to spawn a VM that works, and fast, with easy wizards. I don’t want to learn 50 hours before being able to use your overpriced platform, by doing 20 things before your Ip’s are reflexes of your infrastructure and based in Microservices. Modern JavaScript frameworks can create nice gently wizards even if you have supercold APIs.
Honestly, I didn’t realize my typo in the region and I connected to the Amazon Console to investigate and I saw this.
Honestly, when I read it I understood that they were going to end my EC2 Networking the 30th of October. It was 29th. I misunderstood.
It was my fault not reading it well to the end, I got shocked by the first part telling about shutdown and I didn’t fully understood as they were going to shutdown EC2-Classic for the zones I didn’t had anything running only.
From the long errors (3 exceptions chained) I didn’t realize that the endpoint is built with the region name. (And I was passing the availability zone)
botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL: "https://ec2.us-east-1a.amazonaws.com/"
Here is when I say that a good SDM would had thought and cared for the Developers more, and would had made the SDK to check if that region exists. How difficult is to create a SDK a bit more clever that detects a invalid region id?. It is not difficult.
It is true that it was late in the evening and I was tired of all the day, and two days of the week between work and zoom university classes I work 15 hours and 13 hours respectively, not counting the assignments, so by the end of the week I am very tired. But that’s why it is very important to follow methodology and to read well. I think Amazon has 50% of the fault by the way they do things: how the created the SDK, how they communicate, and by the errors that the console returned me when I tried to create a VPC instance of an EC2-Classic AMI (they seem related to the fact I had old VPC Network objects with shorter hash than the current they use) and the other 50% was my fault for not identifying the source of the error, and not reading the message in their website well.
But the fact that there were having those errors in the API’s and timeouts made me believe they were going to cut the EC2-Classic Networking the next day.
All the mistakes fall together in a perfect storm.
I checked for documentation and I saw it was possible to migrate my Static Ip’s to VPC Static Ip’s.
It was Friday evening, and I cancelled my plans, in order to migrate the Blog to VPC in an attempt to keep running it with Amazon.
As Cloud Architect, I like to have running instances in several CSP as it allows me to stay up to date with the changes they do.
I checked the documentation for the migration. Disassociating the Static Ip (Elastic Ip in AWS jargon) was easy. Turning into VPC as well.
As I progressed, what had to be easy turned into a nightmare, as I was getting many errors from the Amazon API, without any information, and my Instances were not created.
I figured out that their API could have problems with old VPC objects I created time ago, so I had to create new objects for several things.
I managed to spawn my instances but they were being launch and terminated instantly without information. Frustrating.
When launching a new instance from the AMI (a Snapshot of the blog), I was giving shown options to add more volumes without any sense. My Instance was using 16GB from a 20GB total Space, and I was shown different volume configs, depending on the instance, in some case an additional 20GB volume, in other small SSD, ephemeral and 10 GB for the AMI (which requires at least 16GB).
After some fight I manage to make it work after deleting the volumes that made no sense, and keeping only one of 20GB, the same size of my AMI.
But then my nightmare started to make the VPC Instance to have Internet access and to be seen from outside. I had to create a new Internet Gateway, NAT, Network, etc…
As mentioned the old objects I was trying to reusing were making the process to fail.
I was running out of time, and I thought in few time they were going to shutdown EC2-Classic network (as I did not read correctly), so I decided to download everything and to migrate to another provider. For doing that first I blocked all the traffic, except for my Ip.
I worked in parallel, creating the new config in Google Cloud, just in case I had forgot something. I had created a document for the migration and it was accurate.
I managed to do everything fast enough. The slower part was to download all the Data, as I hold entire VM’s for projects like Cassandra Universal Driver.
Then I powered off my Amazon Instance for the Blog forever.
In GCP I blocked all the traffic in the firewall, except for my Ip, so I could work calmly.
When everything was ready, I had to redirect the DNS to the new static Ip from Google.
The DNS provider I used had implemented some changes in their API so I was getting errors replacing my old entry ‘.’ (their JSON calls returned Internal Server Error). Finally I figured it out how to workaround it and I was able to confirm that the first service was up and running.
I did some tests to make sure there were not unexpected permission problems, entries in the logs, etc…
Only then I opened the Google Firewall. I have a second firewall in each instance where I block or open at Ip tables level what I want. Basically abusive bot’s IPs trying to find exploits or brute force by dictionary passwords.
I checked with my phone, without Wifi that the Firewall was all good. (It is always a good idea to use another external Ip, different from the management one, to check)
TLTR: I’m undergoing a Maintenance on all my sites.
The main reason was that I was getting unexpected API Exceptions on the AWS SDK for Python (boto3), so I connected to the AWS Console to get more information.
Then I saw a message indicating that they will stop EC2-Classic today 30th of October. (Please read the Update on the Postmortem analysis as I understood incorrectly that banner message)
I already started migrating my Services, some I move to other providers like Digital Ocean. Other I had plant to keep in Amazon.
EOL (End of Life) was scheduled for 2022 August, so when I saw the message from Amazon the evening of the 29th, I decided to migrate my EC2-Classic Public Ip’s and Compute to VPC. Trying to deploy from an AMI, Amazon APIs were returning many internal errors, and as I figured out where their failures would be I was able get instances being launch without being Terminated immediately without an explanation. Still I had many problems with the Internet Gateway, VPC NAT, etc… after hours fighting with their errors, and their console, that is more a bunch of pages to manage Infrastructure rather than a user/developer friendly Cloud Tool I decided that I had enough.
After 11 years using Amazon AWS, including a trip to Dublin to be hired as Manager for Cloud Watch, and giving them the idea to add AutoScaling (I was told the project was too easy for me and that I would get bored in a year or too so I was not hired), I decided to move my Services to Google Cloud and to Digital Ocean.
I’m very polite and I saw that when I told to one Manager that the User Interface was terrible he didn’t like, but I have to speak up and say that tools for developers cannot be cold as your evil girlfriend. Cannot be API alike, stand alone pages to manage infinite parts of Architecture. Web providing services for developers cannot be created like in cold SysAdmin style. If the infrastructure is hard to manage and internally you use APIs, build nice Wizards in Javascript. I was leading a Team of Developers with infinite less resources than Amazon or Google and we wrote a Multi-Cloud product, with nice, and clever, and easy to use Wizards, and they were infinitely more better that those giant CSPs. We won a prize at European level at that time. But it was 2013.
I’ve migrated everything, moved all the data, statics, VMs… but I’m completing the adjustments for certain services like Cassandra nodes, web sites, bootstrapping some of my sites based of my PHP Catalonia Framework, adding Firewall rules to GCP, doing changes for Ansible provisioning, deploying the Server scripts from IaC, Docker, etc…
My dump takes 88MB, not much, but I compress it with gzip.
gzip wp_mysiteZ.sql
It takes only 15MB compressed.
Do not forget the parameter –databases even if only one database is exported, otherwise the CREATE DATABASE and USE `wp_mysiteZ`; will not be added to your dump.
I will need to take some data form the mysql database, referring to the user used for accessing the blog’s database.
I always keep the CREATE USER and the GRANT permissions, if you don’t check the wp-config.php file. Note that the SQL format to create users and grant permissions may be different from a SQL version to another.
I create a file named mysql.sql with this part and I compress with gzip.
Checking PHP version
php -v
PHP 7.3.23 (cli) (built: Oct 21 2020 20:24:49) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.3.23, Copyright (c) 1998-2018 Zend Technologies
WordPress is updated, and PHP is not that old.
The new Ubuntu 20.04 LTS comes with PHP 7.4. It will work:
php -v
PHP 7.4.3 (cli) (built: Jul 5 2021 15:13:35) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
with Zend OPcache v7.4.3, Copyright (c), by Zend Technologies
The Dockerfile
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# RUN echo "nameserver 8.8.8.8" > /etc/resolv.conf
RUN echo "Europe/Ireland" | tee /etc/timezone
# Note: You should install everything in a single line concatenated with
# && and finalizing with
# apt autoremove && apt clean
# In order to use the less space possible, as every command
# is a layer
RUN apt update && apt install -y apache2 ntpdate libapache2-mod-php7.4 mysql-server php7.4-mysql php-dev libmcrypt-dev php-pear git mysql-server less zip vim mc && apt autoremove && apt clean
RUN a2enmod rewrite
RUN mkdir -p /www
# If you want to activate Debug
# RUN sed -i "s/display_errors = Off/display_errors = On/" /etc/php/7.2/apache2/php.ini
# RUN sed -i "s/error_reporting = E_ALL & ~E_DEPRECATED & ~E_STRICT/error_reporting = E_ALL/" /etc/php/7.2/apache2/php.ini
# RUN sed -i "s/display_startup_errors = Off/display_startup_errors = On/" /etc/php/7.2/apache2/php.ini
# To Debug remember to change:
# config/{production.php|preproduction.php|devel.php|docker.php}
# in order to avoid Error Reporting being set to 0.
ENV PATH_WP_MYSITEZ /var/www/wordpress/wp_mysitez/
ENV PATH_WORDPRESS_SITES /var/www/wordpress/
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
ENV APACHE_PID_FILE /var/run/apache2/apache2.pid
ENV APACHE_RUN_DIR /var/run/apache2
ENV APACHE_LOCK_DIR /var/lock/apache2
ENV APACHE_LOG_DIR /var/log/apache2
RUN mkdir -p $APACHE_RUN_DIR
RUN mkdir -p $APACHE_LOCK_DIR
RUN mkdir -p $APACHE_LOG_DIR
RUN mkdir -p $PATH_WP_MYSITEZ
# Remove the default Server
RUN sed -i '/<Directory \/var\/www\/>/,/<\/Directory>/{/<\/Directory>/ s/.*/# var-www commented/; t; d}' /etc/apache2/apache2.conf
RUN rm /etc/apache2/sites-enabled/000-default.conf
COPY wp_mysitez.conf /etc/apache2/sites-available/
RUN chown --recursive $APACHE_RUN_USER.$APACHE_RUN_GROUP $PATH_WP_MYSITEZ
RUN ln -s /etc/apache2/sites-available/wp_mysitez.conf /etc/apache2/sites-enabled/
# Please note: It would be better to git clone from another location and
# gunzip and delete temporary files in the same line,
# to save space in the layer.
COPY *.sql.gz /tmp/
RUN gunzip /tmp/*.sql.gz; echo "Starting MySQL"; service mysql start && mysql -u root < /tmp/wp_mysitez.sql && mysql -u root < /tmp/mysql.sql; rm -f /tmp/*.sql; rm -f /tmp/*.gz
# After this root will have password assigned
COPY *.zip /tmp/
COPY services_up.sh $PATH_WORDPRESS_SITES
RUN echo "Unzipping..."; cd /var/www/wordpress/; unzip /tmp/*.zip; rm /tmp/*.zip
RUN chown --recursive $APACHE_RUN_USER.$APACHE_RUN_GROUP $PATH_WP_MYSITEZ
EXPOSE 80
CMD ["/var/www/wordpress/services_up.sh"]
Services up
For starting MySQL and Apache I relay in services_up.sh script.
#!/bin/bash
echo "Starting MySql"
service mysql start
echo "Starting Apache"
service apache2 start
# /usr/sbin/apache2 -D FOREGROUND
while [ true ];
do
ps ax | grep mysql | grep -v "grep "
if [ $? -gt 0 ];
then
service mysql start
fi
sleep 10
done
You see that instead of launching apache2 as FOREGROUND, what keeps the loop, not exiting from my Container is a while [ true ]; that will keep looping and checking if MySQL is up, and restarting otherwise.
MySQL shutting down
Some of my sites receive DoS attacks. More than trying to shutdown my sites, are spammers trying to publish comment announcing fake glasses, or medicines for impotence, etc… also some try to hack into the Server to gain control of it with dictionary attacks or trying to explode vulnerabilities.
The downside of those attacks is that some times the Database is under pressure, and uses more and more memory until it crashes.
More memory alleviate the problem and buys time, but I decided not to invest more than $6 USD per month on this old site. I’m just keeping the contents alive and even this site still receives many visits. A restart of the MySQL if it dies is enough for me.
As you have seen in my Dockerfile I only have one Docker Container that runs both Apache and MySQL. One of the advantages of doing like that is that if MySQL dies, the container does not exit. However I could have had two containers with both scripts with the while [ true ];
When planning I decided to have just one single Container, all-in-one, as when I export the image for a Backup, I’ll be dealing only with a single image, not two.
Building and Running the Container
I created a Bash script named build_docker.sh that does the build for me, stopping and cleaning previous Containers:
#!/bin/bash
# Execute with sudo
s_DOCKER_IMAGE_NAME="wp_sitez"
printf "Stopping old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker stop "${s_DOCKER_IMAGE_NAME}"
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run type: sudo docker run -d -p 80:80 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
echo
echo "Debug running Docker:"
echo "docker exec -it ${s_DOCKER_IMAGE_NAME} /bin/bash"
echo
I assign to the image and the Running Container the same name.
Running in Production
Once it works in local, I set the Firewall rules and I deploy the Droplet (VM) with Digital Ocean, I upload the files via SFTP, and then I just run my script build_docker.sh
And assuming everything went well, I run it:
sudo docker run -d -p 80:80 --name wp_mysitez wp_mysitez
I check that the page works, and here we go.
Some improvements
This could also have been put in a private Git repository. You only have to care about not storing the passwords in it. (Like the MySQL grants)
It may be interesting for you to disable directory browsing.
The build from the Git repository can be validated with a Jenkins. Here you have an article about setup a Jenkins for yourself.
I have read a lot of wrong recommendations about the use of Swap and Swappiness so I want to bring some light about it.
The first to say is that every project is different, so it is not possible to make a general rule. However in most of the cases we want systems to operate as fast and efficiently as possible.
So this suggestions try to covert 99% of the cases.
By default Linux will try to be as efficient as possible. So for example, it will use Free Memory to keep IO efficient by keeping in Memory cache and buffers.
That means that if you are using files often, Linux will keep that information cached in RAM.
The swappiness Kernel setting defines what tradeoff will take Linux between keeping buffers with Free Memory and using the available Swap Memory.
# sysctl vm.swappiness
vm.swappiness = 60
The default value is 60 and more or less means that when RAM memory gets to 60%, swap will start to be used.
And so we can find Servers with 256GB of RAM, that when they start to use more than 153 GB of RAM, they start to swap.
Let’s analyze the output of free -h:
carles@vbi78g:~/Desktop/Software/checkswap$ free -h
total used free shared buff/cache available
Mem: 2.9Gi 1.6Gi 148Mi 77Mi 1.2Gi 1.1Gi
Swap: 2.0Gi 27Mi 2.0Gi
So from this VM that has 2.9GB of RAM Memory, 1.6GB are used by applications.
The are 148MB that can immediately used by Applications, and there are 1.2GB in buffers/cache. Does that means that we can only use 148MB (plus swap)?. No, that mean that Linux tried to optimize io speed by keeping 1.2GB of RAM memory in buffers. But this is the best effort of Linux to have performance, for real applications will be also able to use 1.1GB that corresponds to the available field.
About swap, from 2GB, only 27MB have been used.
As vm.swappiness is set to 60, more RAM will be swapped out to swap, even if we have lots available.
As I said every case is different. If we are talking about a Desktop that has NVMe drives, the impact will be low. But if we are talking about a Server that is a hypervisor running VMs and has high usage on CPU and has the swap partition or the swap in a file, that could lead to huge problems. If there is a physical Server with a single spinning drive (or logical unit through RAID), and one partition is for Swap, and the other for mountpoints, and a process is heavily reading/writing to a partition mounted (an elastic search, or a telegraf, prometheus…), and the System tries to swap, then they will be competing for the magnetic head of disk, slowing down everything.
If you take a look on how the process of swapping memory pages from the memory to disk, you will understand that applications may need certain pages before being able to run, so in many cases we get to lock situations, that force everything to wait.
In my career I found Servers that temporarily stopped responding to ping. After a while ping came back, I was able to ssh and uptime showed that the Server did not reboot.
I troubleshooted that, and I saw a combination of high CPU usage spikes and Swap usage.
Using iostat and iotop I monitored what was speed of transference of only 1 MB/second!!.
I even did swapoff and it took one hour to free 4 GB swap partition!.
I also saw swap partition being in a spinning disk, and in another partition of the same spinning drive, having a swapfile. Magnetic spinning drives can only access one are of the drive at the same time, so that situation, using swap is very bad.
And I have seen situations were the swap or swapfile was mounted in a block device shared via network with the Server (like iSCSI or NFS), causing terrible performance when swapping.
So you have to adapt the strategy according to the project.
My preferred strategy for Compute Nodes and NoSQL Databases is to not use swap at all. In other cases, like MySQL Databases I may set swappiness to preferably to 1 or to 10.
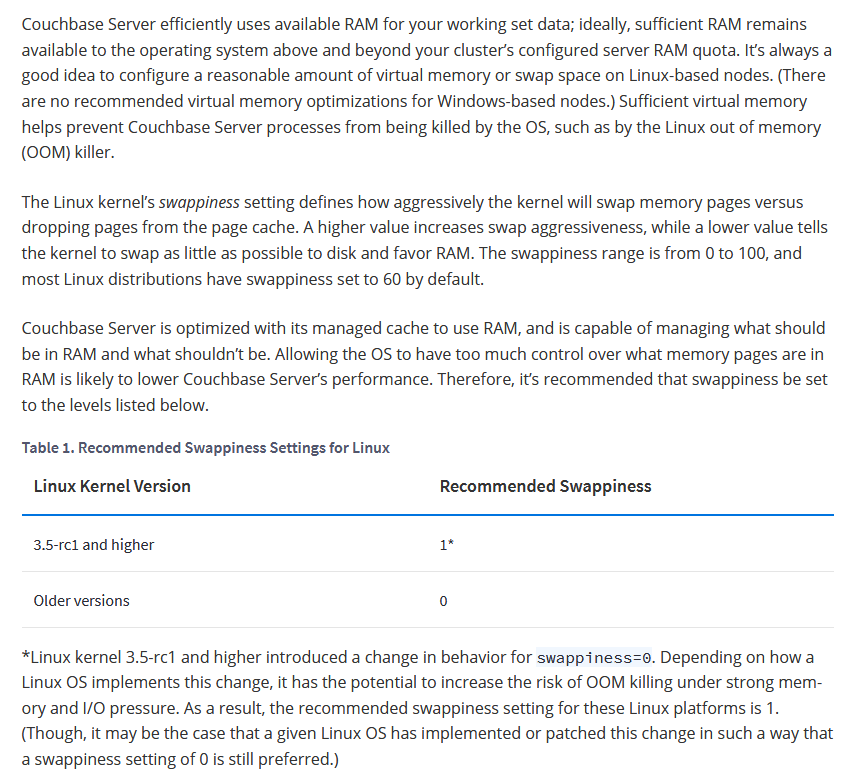
The Linux kernel’s swappiness setting defines how aggressively the kernel will swap memory pages versus dropping pages from the page cache. A higher value increases swap aggressiveness, while a lower value tells the kernel to swap as little as possible to disk and favor RAM. The swappiness range is from 0 to 100, and most Linux distributions have swappiness set to 60 by default.
Couchbase Server is optimized with its managed cache to use RAM, and is capable of managing what should be in RAM and what shouldn’t be. Allowing the OS to have too much control over what memory pages are in RAM is likely to lower Couchbase Server’s performance. Therefore, it’s recommended that swappiness be set to the levels listed below.
Another theme, is when you log to a Server and you see all the Swap memory in use.
Linux may have moved the pages that were less used, and that may be Ok for some cases, for example a Cron Service that waits and runs every 24 hours. It is safe to swap that (as long as the swap IO is decent).
When Kernel Swaps it may generate locks.
But if we log to a Server and all the Swap is in use, how can we know that the Swap has been quiet there?.
Well, you can use iostat or iotop or you can:
cat /proc/vmstat
This file contains a lot of values related to Memory, we will focus on:
Paging refers to writing portions, termed pages, of a process’ memory to disk. Swapping, strictly speaking, refers to writing the entire process, not just part, to disk. In Linux, true swapping is exceedingly rare, but the terms paging and swapping often are used interchangeably.
page-out: The system’s free memory is less than a threshold “lotsfree” and unnused / least used pages are moved to the swap area. page-in: One process which is running requested for a page that is not in the current memory (page-fault), it’s pages are being brought back to memory. swap-out: System is thrashing and has deactivated a process and it’s memory pages are moved into the swap area. swap-in: A deactivated process is back to work and it’s pages are being brought into the memory.
Values from /proc/vmstat:
pgpgin, pgpgout – number of pages that are read from disk and written to memory, you usually don’t need to care that much about these numbers
pswpin, pswpout – you may want to track these numbers per time (via some monitoring like prometheus), if there are spikes it means system is heavily swapping and you have a problem.
In this actual example that means that since the start of the Server there has been 508992338 Page Swap In (with 4K memory pages this is 1,941 GB, so almost 2 TB transferred) and for Page Swat Out (with 4K memory pages this is 1,071 GB, so 1 TB of transferred). I’m talking about a Server that had a 4GB swap partition in a spinning disk and a 12 GB swapfile in another ext4 partition of the same spinning disk.
The 16 GB of swap were in use and iotop showed only two sources of IO, one being 2 VMs writing, another was a journaling process writing to the mountpoint where the swapfile was. That was an spinning drive (underlying hardware was raid, for simplicity I refer to one single drive. I checked that both spinning drives were healthy and fast). I saw small variations in the size of the Swap, so I decided to monitor the changes in pswpin and pswpout in /proc/vmstat to see how much was transferred from/to swap.
I saw then how many pages were being transferred!.
I wrote a small Python program to track those changes:
This little program works in Python 2 and Python 3, and will show the evolution of pswpin and pswpout in /proc/vmstat and will offer the average for last 5 minutes and keep the max value detected as well.
As those values show the page swaps since the start of the Server, my little program, makes the adjustments to show the Page Swaps per second.
A cheap way to reproduce collapse by using swap is using VirtualBox: install an Ubuntu 20.04 LTS in there, with 2 GB of less of memory, and one single core. Ping that VM from elsewhere.
Then you may run a little program like this in order to force it to swap:
#!/usr/bin/env python3
a_items = []
i_total = 0
# Add zeros if your VM has more memory
for i in range(0, 10000000):
i_total = i_total + i
a_items.append(i_total)
And checkswap will show you the spikes:
Many voices are discordant. Some say swappiness default value of 60 is good, as Linux will use the RAM memory to optimize the IO. In my experience, I’ve seen Hypervisors Servers running Virtual Machines that fit on the available physical RAM and were doing pure CPU calculations, no IO, and the Hypervisor was swapping just because it had swappiness to 60. Also having swap on spinning drives, mixing swap partition and swapfile, and that slowing down everything. In a case like that it would be much better not using Swap at all.
In most cases the price of Swapping to disk is much more higher than the advantage than a buffer for IO brings. And in the case of a swapfile, well, it’s also a file, so my suspect is that the swapfile is also buffered. Nothing I recommend, honestly.
My program https://gitlab.com/carles.mateo/checkswap may help you to demonstrate how much damage the swapping is doing in terms of IO. Combine it with iostat and iotop --only to see how much bandwidth is wasted writing and reading from/to swap.
You may run checkswap from a screen session and launch it with tee so results are logged. For example:
python3 checkswap.py | tee 2021-05-27-2107-checkswap.log
If you want to automatically add the datetime you can use:
python3 checkswap.py | tee `date +%Y-%m-%d-%H%M`-checkswap.log
Press CTRL + a and then d, in order to leave the screen session and return to regular Bash.
Type screen -r to resume your session if this was the only screen session running in background.
An interesting reflection from help Ubuntu:
The “diminishing returns” means that if you need more swap space than twice your RAM size, you’d better add more RAM as Hard Disk Drive (HDD) access is about 10³ slower then RAM access, so something that would take 1 second, suddenly takes more then 15 minutes! And still more then a minute on a fast Solid State Drive (SSD)…