I wanted to do a do-release-upgrade to Update from Ubuntu 25.04 to Ubuntu 25.10, but I had almost no space left on the device. I didn’t want to uninstall the snap utilities that were using most of the space after the OS.
I created a video to explain this situation and how to fix it easily.
Host OS: Ubuntu 22.04 LTS, 64 GB of RAM
Guest OS: Ubuntu 25.04, 12 GB of RAM
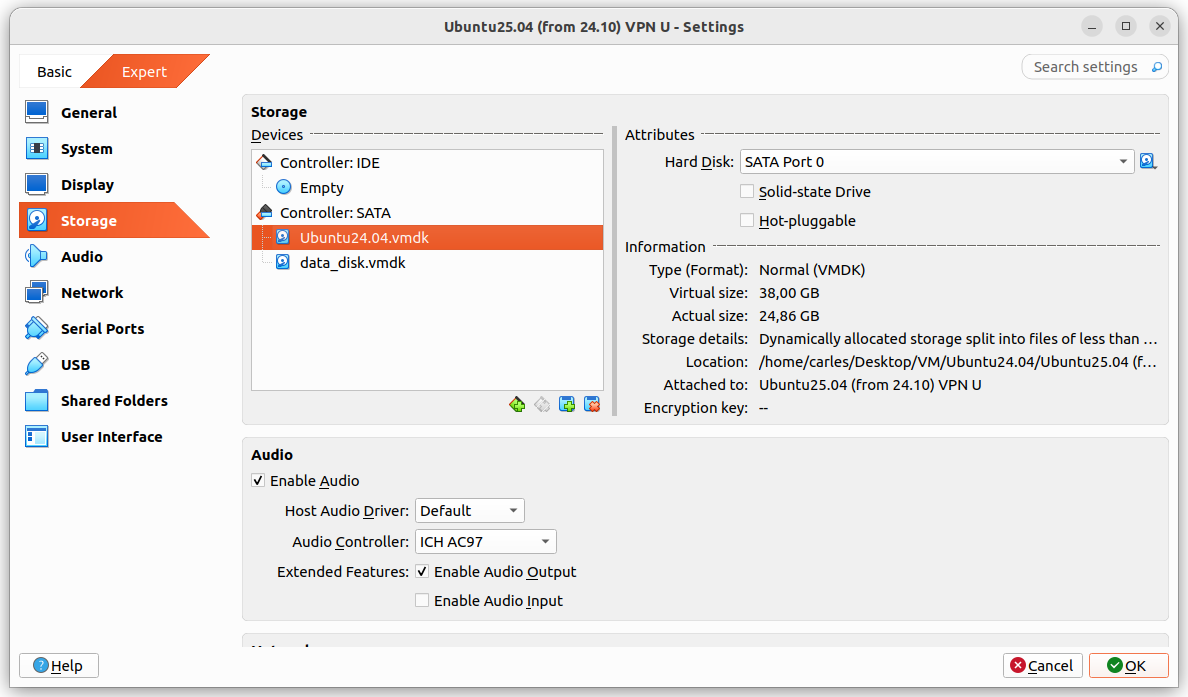
Guest drive: VMDK of 25GB, Dynamically allocated split in 2 GB files. Using 24.86GB
The problem was that I grow a disk with Virtual Box, from 25GB to 35GB and Virtual Box crashed.
It stayed in an error state, unable to access any configuration after I pressed Refresh, so I had to kill it and restart it.
I tried to expand to 36 and 37 GB with same results.
After restarting Virtual Box it shown the drive as 37 GB, so I guessed that the disk growing may have worked somehow and I tried to use the additional space from the guest VM.
I booted the guest VM with Ubuntu 25.04, sudo swapoff -a and deleted the swap partition with fdisk and I used resize2fs and growpart.
When the gues OS saw the 37GB I attempted the do-release-upgrade and it started to download packages.
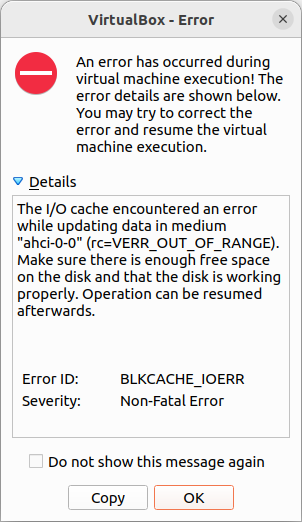
But at the point that the original 25GB were exceeded I got a recoverable IO cache error (rc=VERR_OUT_OF_RANGE).
From this point Ubuntu would be unable to complete to boot the guest VM.
I had data that I wanted to recover from the VM, so I tried to recover it, successfully.
Basically I booted with an Ubuntu 26.04 LTS live ISO, mounted the disk for read, enabled the network and scp my files to another computer.
scp, rsync, sftp… any of those will do the job.
I could also have created a new disk, attach to the guest VM, boot with Ubuntu Live, and copy from the damaged disk to the new one. Then shutdown, attach the new disk to another VM, and copy the data copied to the new disk to the healthy VM.
Or even I could have plugged an USB pendrive, telling VirtualBox to recognise those.
So I show here how I launched a fresh Ubuntu 24.04 in Google Cloud, on 2026-05-04, and demostrate the exploit of escalation privileges Copy Fail (CVE-2026-31431) which allows you to become root from a regular user account in almost any Linux since year 2017.
It consists in the execution of a Python 3 code, which is only 732 bytes.
I show how I fixed it by upgrading the kernel and rebooting.
If you are running your instances in Google Gloud Compute Engine and you want to increase the size of the Disk without having to reboot, this video explains step by step how you can do it.
Go to Disks in GCP, select the disk of the instance you want to increase, then press Edit.
After you increase the Disk in Google Cloud Dashboard, then ssh to you instance.
There type:
lsblk
in order to list the devices.
In my case is sda and I want to grow the partition 1.
So I proceed with:
sudo growpart /dev/sda 1
Which growing from 30GB to 40GB produces the output:
import ipaddress
def check_ip(s_ip_or_net):
b_valid = True
try:
# The IP Addresses are expected to be passed without / even if it's /32 it would fail
# If it uses / so, the CIDR notation, check it as a Network, even if it's /32
if "/" in s_ip_or_net:
o_net = ipaddress.ip_network(s_ip_or_net)
else:
o_ip = ipaddress.ip_address(s_ip_or_net)
except ValueError:
b_valid = False
return b_valid
if __name__ == "__main__":
a_ips = ["127.0.0.2.4",
"127.0.0.0",
"192.168.0.0",
"192.168.0.1",
"192.168.0.1 ",
"192.168.0. 1",
"192.168.0.1/32",
"192.168.0.1 /32",
"192.168.0.0/32",
"192.0.2.0/255.255.255.0",
"0.0.0.0/31",
"0.0.0.0/32",
"0.0.0.0/33",
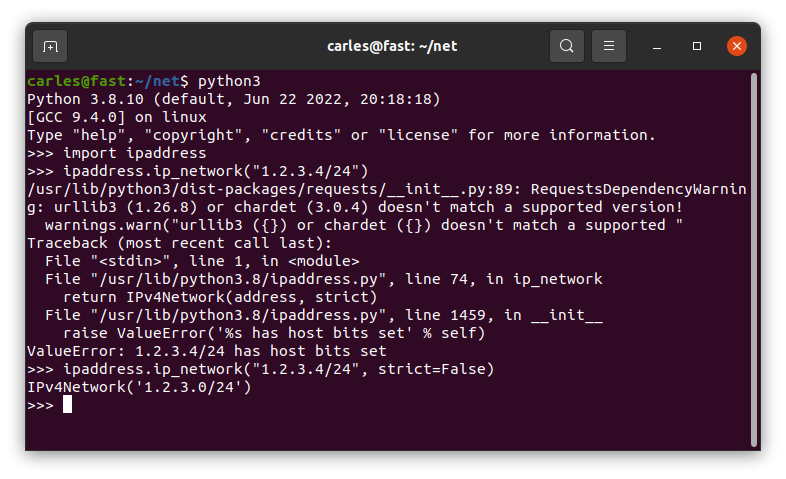
"1.2.3.4",
"1.2.3.4/24",
"1.2.3.0/24"]
for s_ip in a_ips:
b_success = check_ip(s_ip)
if b_success is True:
print(f"The IP Address or Network {s_ip} is valid")
else:
print(f"The IP Address or Network {s_ip} is not valid")
And the output is like this:
The IP Address or Network 127.0.0.2.4 is not valid
The IP Address or Network 127.0.0.0 is valid
The IP Address or Network 192.168.0.0 is valid
The IP Address or Network 192.168.0.1 is valid
The IP Address or Network 192.168.0.1 is not valid
The IP Address or Network 192.168.0. 1 is not valid
The IP Address or Network 192.168.0.1/32 is valid
The IP Address or Network 192.168.0.1 /32 is not valid
The IP Address or Network 192.168.0.0/32 is valid
The IP Address or Network 192.0.2.0/255.255.255.0 is valid
The IP Address or Network 0.0.0.0/31 is valid
The IP Address or Network 0.0.0.0/32 is valid
The IP Address or Network 0.0.0.0/33 is not valid
The IP Address or Network 1.2.3.4 is valid
The IP Address or Network 1.2.3.4/24 is not valid
The IP Address or Network 1.2.3.0/24 is valid
As you can read in the code comments, ipaddress.ip_address() will not validate an IP Address with the CIDR notation, even if it’s /32.
You should strip the /32 or use ipaddress.ip_network() instead.
As you can see 1.2.3.4/24 is returned as not valid.
You can pass the parameter strict=False and it will be returned as valid.
One interesting aspect is that I cover how the messages are delivered as byte sequence. I show this by sending Unicode characters
Files in the project
Dockerfile
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# This will make sure printing in the Screen when running in dettached mode
ENV PYTHONUNBUFFERED=1
ARG PATH_RABBIT_INSTALL=/tmp/rabbit_install/
ARG PATH_RABBIT_APP_PYTHON=/opt/rabbit_python/
RUN mkdir $PATH_RABBIT_INSTALL
COPY cloudsmith.sh $PATH_RABBIT_INSTALL
RUN chmod +x ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN apt-get update -y && apt install -y sudo python3 python3-pip mc htop less strace zip gzip lynx && apt-get clean
RUN ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN service rabbitmq-server start
RUN mkdir $PATH_RABBIT_APP_PYTHON
COPY requirements.txt $PATH_RABBIT_APP_PYTHON
WORKDIR $PATH_RABBIT_APP_PYTHON
RUN pwd
RUN pip install -r requirements.txt
COPY *.py $PATH_RABBIT_APP_PYTHON
COPY loop_send_get_messages.sh $PATH_RABBIT_APP_PYTHON
RUN chmod +x loop_send_get_messages.sh
CMD ./loop_send_get_messages.sh
cloudsmith.sh
#!/usr/bin/sh
# From: https://www.rabbitmq.com/install-debian.html#apt-cloudsmith
sudo apt-get update -y && apt-get install curl gnupg apt-transport-https -y
## Team RabbitMQ's main signing key
curl -1sLf "https://keys.openpgp.org/vks/v1/by-fingerprint/0A9AF2115F4687BD29803A206B73A36E6026DFCA" | sudo gpg --dearmor | sudo tee /usr/share/keyrings/com.rabbitmq.team.gpg > /dev/null
## Cloudsmith: modern Erlang repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/gpg.E495BB49CC4BBE5B.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg > /dev/null
## Cloudsmith: RabbitMQ repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/gpg.9F4587F226208342.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg > /dev/null
## Add apt repositories maintained by Team RabbitMQ
sudo tee /etc/apt/sources.list.d/rabbitmq.list <<EOF
## Provides modern Erlang/OTP releases
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
## Provides RabbitMQ
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
EOF
## Update package indices
sudo apt-get update -y
## Install Erlang packages
sudo apt-get install -y erlang-base \
erlang-asn1 erlang-crypto erlang-eldap erlang-ftp erlang-inets \
erlang-mnesia erlang-os-mon erlang-parsetools erlang-public-key \
erlang-runtime-tools erlang-snmp erlang-ssl \
erlang-syntax-tools erlang-tftp erlang-tools erlang-xmerl
## Install rabbitmq-server and its dependencies
sudo apt-get install rabbitmq-server -y --fix-missing
build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="rabbitmq"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -it --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
requirements.txt
pika
loop_send_get_messages.sh
#!/bin/bash
echo "Starting RabbitMQ"
service rabbitmq-server start
echo "Launching consumer in background which will be listening and executing the callback function"
python3 rabbitmq_getfrom.py &
while true; do
i_MESSAGES=$(( RANDOM % 10 ))
echo "Sending $i_MESSAGES messages"
for i_MESSAGE in $(seq 1 $i_MESSAGES); do
python3 rabbitmq_sendto.py
done
echo "Sleeping 5 seconds"
sleep 5
done
echo "Exiting loop"
More funny things happened like when I was installing a VirtualBox VM live, and the ZFS pool became irresponsible due hardware errors in one SATA Spinning drive.
Things from broadcasting live…
Some of the feedback I got from talented Engineers is that even if the original matter to talk about was interesting, seeing everything falling apart live due to unexpected hardware problems, and me troubleshooting live is being the best of the show… which I found very amusing.
RAB Radio the new digital world
I keep doing my radio space for Radio America Barcelona, once per week, addressed to the Catalan Community across the world and expats.
This radio program, streamed also via Twitch, is available in Catalan language only. RAB.
Open Source
carleslibs
I’ve been working in version 1.0.8 branch, and after a session of refactor on Twitch where I found a bug in MenuUtils class, I fixed it and released v. 1.0.8. You can see the video on the link.
Now I’m working on the branch v. 1.0.9.
ctop
I’ve been working in the branch 0.8.9.
My first Twitch broadcast was about adding Unit Testing to MemUtils class.
This week I decommissioned my last physical server in a Data Center.
It has been a long journey since I created my company to launch my own projects, and I started having my own infrastructure, back at 2000.
I was offering VPS at that time, with VMWare as Hypervisor.
This last Rack Server served me well for 21 years.
Now everything is Cloud, and is not viable to host and maintain servers unless this is your main occupation. Server’s motherboards die, hard drives die and they need to be replaced. Maintaining infrastructure it’s a full time job and you require somebody to do it. Also using fixed servers only prevents you from moving fast, locks a lot of money, and from spawning more compute capacity.
If you are curious this Rack Server is a Super Micro with Intel Xeon processor and SCSI drives.
Security
Firewall
I keep blocking thousands of IP Addresses every day.
When I see a pattern of an IP trying an attacks against the Server I look at the IP and if it’s from a hosting provider I just block the entire range.
I keep blocking any IP Address coming from Russia or Belarus since they invaded Ukraine.
My Health
I visited the hospital for a programmed following on my health.
The analysis are super good, and it’s super clear that I’ve improved radically. My discipline with the diet, taking the medicines and doing exercise regularly has been crucial.
My Doctor is confident that I’ll have a full recovery, but to do so I need to loss a lot of weight in a year or two.
So, I need to focus on my health and in doing exercise, being happy and avoid any kind of negative stress.
The cost of the travels and the medicines have put some stress into my economy, but I’m fortunate that I can handle it.
Entertainment / Life / Reflections
Star Wars and racism
I’m really enjoying new Start Wars series Obi Wan, and I’ve been profoundly shocked to read that there are fans being racist against the black characters.
In this very long session we went through actual errors in a ZFS pool, we check the Kernel, we remove and reinsert the drive, conduct zpool scrub… in the meantime I talked about Rack, Rack Servers, PSU, redundant components, ECC RAM…
Only 2% of the viewers donate, so I answered the call every time it was made.
This is my 5th donation to Wikimedia.
I consider that Freedom is very important.
I bought these new books
One of my secrets to be on top is that I’m always studying.
I study all the time, at work and in my free time.
I use Linux Academy and I buy books in paper. I don’t connect with reading in tablets. I think information is stored better when read in paper. I use also a marker and pointers to keep a direct access to the most interesting points on the books.
And I study all kind of themes. Obviously I know a lot of Web Scraping, but there is always room for learning more. And whatever new I learn helps me to be better with my students and more clear writing my books.
I’ve never been a Front End, but I’ve been able to fix bugs in the Front End engines from the companies I worked for, like Privalia. I was passed a bug that prevented the Internet Explorer users to buy just one hour before we launching a massive campaign. I debugged and I found a variable named “value” so the html looked like <input name="value" value="">. In less than 30 minutes I proved to the incredulous Head of Development and the CTO that a bug in Internet Explored was causing a conflict when fetching the value from the input named value. We deployed to Production the update and the campaign was a total success. So I consider knowing Javascript and Front also a need, even if I don’t work directly with it. I want to be able to understand all the requirements and possibilities, and weaknesses, so I can fix bugs and save the day. That allowed me to fix scalability problems in Nodejs and Phantomjs projects too. (They are Javascript Server Side, event driven, projects)
It seems that Amazon.co.uk works well again for Ireland. My two last orders arrived on time and I had no problems of border taxes apparently.
Nice Python article
I enjoyed a lot this article, cause explains part of what I did with my student and friend Albert, in a project that analyzes the access logs from Apache for patterns of attempts of exploits, then feeds a database, and then blocks those offender Ip Addresses in the Firewall.
The article only covers the part of Pandas, of reading the access.log file and working with it, but is a very well redacted article: