One of my clients had a problem with a Phantomjs Software.
I was asked to help in their project, that was relying on one of its features.
Phantomjs is an interesting project, but unfortunately it has not had enough maintenance and a terrible lack of sufficient documentation. The last contributions to repo are from mid May, with small frequency. (Latest releases are from Feb 2015, see the Phantomjs releases on github)
The Software from my client ran well for certain requests, but not for others and after a random time, seconds, or minutes, it became irresponsible.
My client wanted to fix that or to use nodejs to scale their phantom code or in the worst case to rewrite the code in nodejs. And it was urgent, because they were losing a lot of money because of their programs malfunctioning.
I began to investigate. That’s the history of how I fixed…
Connections being irresponsible
My client was using the Phantomjs webserver.
The problem with Phantom’s webserver is that it has a hard limit of 10 concurrent connections. After that all the next http connections are queried until one becomes free.
So if you do a telnet to that port, the connection is accepted, but nothing happens. Even sending malformed GET requests.
My guess was that something in the process of parsing the requests was wrong, and then some of those 10 connections became frozen. I started to debug.
I implemented a timedout that will quit the worker after some time.
mTimerExit = setTimeout(forceExitByTimeout, DEFAULT_TIME_TO_EXIT);
Before exiting is important to clear the timers
clearTimeout(mTimerExit);
I also implemented a debug mode to see what was going on with a method consoleDebug that basically did console.log according to if a parameter debug was set to true.
My quickwin system was working, but many urls still were not being parsed by the phantomjs Engine.
Connecting with nodejs
My client had the bad experience of previous versions of Phantomjs crashing a lot.
So it has the idea of running nodejs as the main webserver, for scaling, and invoking Phantomjs from it.
I did several work in this line.
I tried to link with nodejs with products like:
1) https://github.com/alexscheelmeyer/node-phantom
Unfortunately those packets are no longer maintained, having seen the last update from 2013.
It doesn’t work. I found no documentation, and no traces on errors.
I also got errors like:
XMLHttpRequest cannot load http://localhost:8888/start Origin file:// is not allowed by Access-Control-Allow-Origin
And had to figure out what parameters to tune. I did by starting phantomjs with the param:
--web-security=false
In the js scene products and packages are changing very fast and sadly often breaking retrocompatibility.
So you better have a very well defined package.json that installs exactly the software version that you need, or soon, when you deploy to another server it will be a disaster.
2) https://www.npmjs.com/package/ghost-town
Ghost Town is a product that allows to run phantomjs from inside nodejs.
It is a company maintained product, by a contributor, Teddy.
He was very nice replying my questions, but it didn’t help.
The process was failing with no debug, no info.
The package really lacks documentation, and has only the same sample across all the web.
I provide this ghost-town code sample, in case it is useful for people looking for more:
var phantomClusterOptions = require("./phantomClusterOptions");
var town = require("ghost-town")(phantomClusterOptions);
var alerts = require("./qualitynodephantom"); // Do not ad .js
var PORT = 8080;
if (town.isMaster) {
var express = require('express');
var app = express();
app.get('/', function(req, res) {
// Every request comes here
var data = {url:req.query.url,device:req.query.quality};
town.queue(data, function(err,result) {
res.set('Content-Type', 'text/plain');
if (!err) {
res.send(result);
} else {
res.send(err);
}
}, phantomClusterOptions.pageTries);
});
app.listen(PORT);
console.log('App running');
} else {
town.on("queue", function(page, data, callback) {
town.phantom.set('onError', function(msg,trace){});
// quality is the exported method, you pass the useful page object as parameter
quality(page, data, function(str){
callback(null, str);
});
});
town.on("error", function(err) {console.log("error");});
}
And the file phantomClusterOptions has:
//Options here https://github.com/buzzvil/ghost-town
phantomClusterOptions = {
//phantomBinary:'./phantomjs', //if you want to use a different phantomjs version
//phantomBinary:'/usr/bin/phantomjs',
workerDeath: 3, //number of times that instance of phantom will be reused
pageTries:5, //tries to the page before rejecting
pageCount: 1, //number of pages analysed concurrently by the same phantom instance (1 is recommended)
// This is for versions 1.9 and older of ghost-town
//phantomFlags:['--load-images=no', '--local-to-remote-url-access=yes', '--ignore-ssl-errors=true', '--web-security=false', '--debug=true'] //flags (http://phantomjs.org/api/command-line.html)
// For v.2 and newer versions
phantomFlags: {"load-images" : false, "local-to-remote-url-access" : true, "ignore-ssl-errors" : true, "web-security" : false, "debug" : true}
}
module.exports = phantomClusterOptions;
3) Other products
https://www.npmjs.com/package/node-phantom-simple
https://github.com/sgentle/phantomjs-node
I tried to debug with node debugger from command-line:
node debug myapp.js
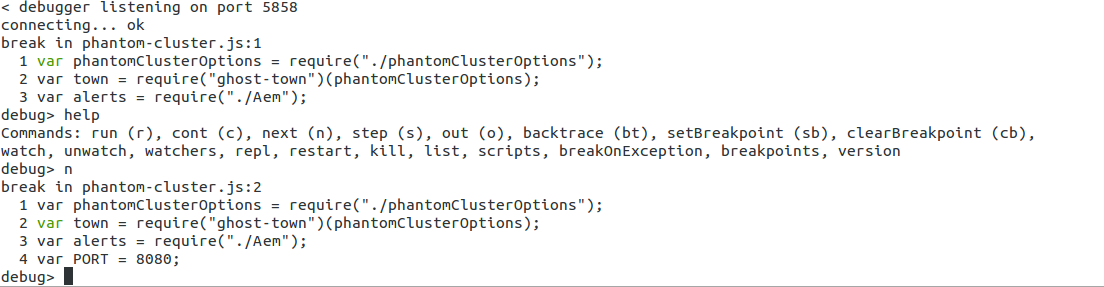
And with node-debug (very nice integration with Chrome):
node-debug myapp.js

But I was unable to see what was failing. The nodejs App was up, and the ghost-town queue was increased, but apparently the worker processing the queue was not working or unable to execute phantomjs. But I saw no errors. When I switched the params for ghost-town to v.2, I got some exception, and it really looks like is unable to execute Phantom, or perhaps phantomjs could not exec the .js due to some dependencies problem.
(throw err and error spawn EACCES)
 Also:
Also:
Error: /mypath/node_modules/ghost-town/node_modules/phantom/node_modules/dnode/node_modules/weak/build/Release/weakref.node: undefined symbol: node_module_register
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Module.require (module.js:364:17)
at require (module.js:380:17)
at bindings (/mypath/node_modules/ghost-town/node_modules/phantom/node_modules/dnode/node_modules/weak/node_modules/bindings/bindings.js:76:44)
at Object.<anonymous> (/mypath/node_modules/ghost-town/node_modules/phantom/node_modules/dnode/node_modules/weak/lib/weak.js:7:35)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
/mypath/node_modules/ghost-town/node_modules/phantom/node_modules/dnode/node_modules/weak/node_modules/bindings/bindings.js:83
throw e
But I was unable to find more info on the net, I tried to install additional modules and I even straced the processes but I didn’t find the origin of the problem.
I was using:
npm install browserify express ghost-town phantom socket.io URIjs
async dnode forever node-phantom request underscore.string waitfor
About CentOs and Ubuntu
Some SysAdmins love CentOs. I’m in love with Ubuntu.
Basically, is per the packages system. They are really well maintained.
Ubuntu has LTS Long Time Support versions, that last for 5 years.
And in the other hand, they release a new version every 6 months, and if you install a modern server, you have the latest stable packages of Software.
Working with Open Source, this is a really important point. As I have access to modern versions of PHP, Apache, Tomcat, etc…
To use phantomjs with CentOS you have to download the sources and compile it, it took like an hour in a Cloud commodity Virtual Server, and there were problems of dependencies. Also using a phantomjs compiled with a CentOS system didn’t worked with a Server with a different CentOS version. So it was a bit painful to distribute across heterogeneous machines.
With an Ubuntu 14.04 LTS, just:
sudo apt-get install phantomjs
did the trick installing phantomjs (1.9.0-1)
Scaling with PHP
So we had the decision to make between:
- rewriting completely the application to nodejs, that certainly would take time
- to invest more time trying to determine why workers freeze under phantomjs
Phantomjs is a headless WebKit scriptable so it was very convenient.
Nodejs is built on Chrome’s Javascript runtime, so it would do what we want to.
As we had a time-constraint and for my client was very important to have the system working asap.
So I decided to debug a bit more.
I found that url’s were being stop loading at the event page.onNavigationRequested
So I could keep all the url and after a timedout could force a page.open(url) inside the event if it stopped (timedout)
mPage.onNavigationRequested = function(url, type, willNavigate, main) {
That was working, finally, but was not my favourite solution. I wanted to understand why it was failing initially.
The lack of documentation was frustrating, but debugging the problematic urls, I found that they were doing several redirections, and after some I was getting SSL certificate error on one of the destination urls.
The thing had to be with chain certificates bad configured.
As nowadays there many cheap SSL certificates providers, based on chain certificates, and many sites are configuring them wrong, phantomjs was sensible to that and stopping following urls.
I already had the param:
--ignore-ssl-errors=true
But investigating I found a very interesting contribution on stackoverflow from user Micah:
http://stackoverflow.com/questions/12021578/phantomjs-failing-to-open-https-site
Note that as of 2014-10-16, PhantomJS defaults to using SSLv3 to open HTTPS connections. With the POODLE vulnerability recently announced, many servers are disabling SSLv3 support.
To get around that, you should be able to run PhantomJS with:
phantomjs --ssl-protocol=tlsv1
Hopefully, PhantomJS will be updated soon to make TLSv1 the default instead of SSLv3.
I decided to give a try to forcing the version of SSL to TLSV1:
--ssl-protocol=tlsv1
And it worked. It did the trick. All the urls were now being parsed right and following the redirects to the end (or to my timedout).
The problem and the solution has been there since 2015 October, and the default use of tlsv1 has not been implemented as default in Phantomjs. That lack of maintenance I found disappointing.
That is why, when recently a multinational interviewed me, and asked me about technologies like nodejs I told them that I’m conservative until it is clear that the version has been proved as stable. And I told that, in any case, a member of the company should me a core member of the contributors to the technology. They were surprised but they shouldn’t! they should have known what I told!. I explained them that if you use a new technology in production, at least you should have a member of your staff in the core of that product. So you pay a guy to build an Open Source technology, basically. This warranties you that if a heavy bug or security flaw appears, you’ll not be screwed until the release. You guy can fix it immediately and share the solution with the community.
Companies like google, Facebook or Amazon do that.
That conservativeness is what I drawn in an interview with Facebook Operations, where I was asked about an scenario where I would be requested by some Developers and DevOps to upgrade the Load Balancers Software. They were more for the action, and I told that LB are critical and I was replied that everything in FB was critical. I argued that if a chat component fails, only the chat fails, but if the Load Balancers fail, everything will fail as they are the entrance point. I had the confirmation that I was right when some months ago they had an outage for hours.
Sometimes you have to keep strong, defend your point, because you know you’re right. Even if you are in front of a person that doesn’t see the things like you and will take a decision that will let you out. Being honest is priceless.
Scaling Phantomjs with PHP
So cool, the system was working fine.
But there was something that could be improved.
As Phantomjs had the limit of 10 connections in their webserver, that was the maximum concurrent connections that it can serve at the same time, and so it was a bottleneck.
// Sample code to create a webserver from PhantomJS
mWebserver = require('webserver');
mServer = mWebserver.create();
console.log("Server created");
//consoleDebug('Debug enabled');
mService = mServer.listen(8080,{'keepAlive': true}, function(request, response) {
//consoleDebug('URL:' + request.url);
s_params = request.url;
doRender(s_params, function(res) {
//consoleDebug('Response from URL:' + request.url + ' (processed)');
writeStringResponse(response,res);
});
//consoleDebug('URL:' + request.url + ' ready for processing');
});
I decided to do propose to the company to use one of my tricks.
To launch phantomjs from PHP.
This is doing a wrapper to launch Phantomjs from commandline, and getting the response. I did the same in my CQLSÍ Cassandra wrapper around cqlsh before Cassandra drivers for PHP were available. I did also this to connect the payment gateway of a bank, written in C, with the Java libraries from Ticketing Solutions in 1999.
That way the server would be able to process as many concurrent Phantomjs instances as we want, as each one would be running in its own process.
I modified the js code to remove the webserver functionality and to get parameters from command line.
var system = require('system');
var args = system.args;
var b_debug_write = false;
if (args.length < 2) {
console.log("Minim 2 parameters");
console.log("call with: phantomjs program.js http://myurl.com quality");
console.log("Parameter debug is optional");
args.forEach(function(arg, i) {
console.log(i + ': ' + arg);
});
// Exit with error level 1
phantom.exit(1);
}
var s_url = args[1];
var s_quality = args[2];
if (args.length > 3) {
// Enable debug
b_debug_write = true;
}
consoleDebug("Starting with url:" + s_url + " and quality:" + s_quality);
Then the PHP code:
<?php
/**
* Creator: Carles Mateo
* Date: 2015-05-11 11:56
*/
// Report all PHP errors
error_reporting(E_ALL);
$b_debug = false;
if (!isset($_GET['url']) || !isset($_GET['quality'])) {
echo 'Invalid parameters';
exit();
}
if (isset($_GET['debug'])) {
$b_debug = true;
}
$s_url = $_GET['url'];
$s_quality = $_GET['quality'];
// Just in case is not decoded by the PHP installed
$s_url = urldecode($s_url);
// reencode url
$s_url = urlencode($s_url);
$s_script = '/mypath/myapp_commandline.sh';
$s_script_with_params = $s_script.' '.$s_url.' '.$s_quality;
if ($b_debug == true) {
$s_script_with_params .= ' debug';
echo 'Executing '.$s_script_with_params."<br />\n";
}
//$message=shell_exec("/var/www/scripts/testscript 2>&1");
$s_message = shell_exec($s_script_with_params);
header("Content-Type: text/plain");
echo $s_message;
And finally the bash script myapp_comandline.sh:
#!/bin/bash
PATH_QUALITY=/mypath/
#tlsv1 is recommended to avoid problems with certificates
PARAMETERS="--local-to-remote-url-access=yes --ignore-ssl-errors=true --web-security=false --ssl-protocol=tlsv1"
cd $PATH_QUALITY
#echo "Debug param1=$1 param2=$2 param3=$3"
if [ -z "$3" ]
then
phantomjs $PARAMETERS quality.js $1 $2
else
echo "Launching phantomjs with debug. url=$1 quality=$2"
phantomjs $PARAMETERS quality.js $1 $2 $3
fi
If you don’t need to load the images you can speed up the thing with parameter:
--load-images=false
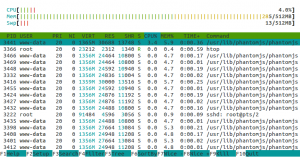
So finally we were able to use only 285 MB of RAM to handle more than 20 concurrent phantomjs processes.