In this very long session we went through actual errors in a ZFS pool, we check the Kernel, we remove and reinsert the drive, conduct zpool scrub… in the meantime I talked about Rack, Rack Servers, PSU, redundant components, ECC RAM…
I have read a lot of wrong recommendations about the use of Swap and Swappiness so I want to bring some light about it.
The first to say is that every project is different, so it is not possible to make a general rule. However in most of the cases we want systems to operate as fast and efficiently as possible.
So this suggestions try to covert 99% of the cases.
By default Linux will try to be as efficient as possible. So for example, it will use Free Memory to keep IO efficient by keeping in Memory cache and buffers.
That means that if you are using files often, Linux will keep that information cached in RAM.
The swappiness Kernel setting defines what tradeoff will take Linux between keeping buffers with Free Memory and using the available Swap Memory.
# sysctl vm.swappiness
vm.swappiness = 60
The default value is 60 and more or less means that when RAM memory gets to 60%, swap will start to be used.
And so we can find Servers with 256GB of RAM, that when they start to use more than 153 GB of RAM, they start to swap.
Let’s analyze the output of free -h:
carles@vbi78g:~/Desktop/Software/checkswap$ free -h
total used free shared buff/cache available
Mem: 2.9Gi 1.6Gi 148Mi 77Mi 1.2Gi 1.1Gi
Swap: 2.0Gi 27Mi 2.0Gi
So from this VM that has 2.9GB of RAM Memory, 1.6GB are used by applications.
The are 148MB that can immediately used by Applications, and there are 1.2GB in buffers/cache. Does that means that we can only use 148MB (plus swap)?. No, that mean that Linux tried to optimize io speed by keeping 1.2GB of RAM memory in buffers. But this is the best effort of Linux to have performance, for real applications will be also able to use 1.1GB that corresponds to the available field.
About swap, from 2GB, only 27MB have been used.
As vm.swappiness is set to 60, more RAM will be swapped out to swap, even if we have lots available.
As I said every case is different. If we are talking about a Desktop that has NVMe drives, the impact will be low. But if we are talking about a Server that is a hypervisor running VMs and has high usage on CPU and has the swap partition or the swap in a file, that could lead to huge problems. If there is a physical Server with a single spinning drive (or logical unit through RAID), and one partition is for Swap, and the other for mountpoints, and a process is heavily reading/writing to a partition mounted (an elastic search, or a telegraf, prometheus…), and the System tries to swap, then they will be competing for the magnetic head of disk, slowing down everything.
If you take a look on how the process of swapping memory pages from the memory to disk, you will understand that applications may need certain pages before being able to run, so in many cases we get to lock situations, that force everything to wait.
In my career I found Servers that temporarily stopped responding to ping. After a while ping came back, I was able to ssh and uptime showed that the Server did not reboot.
I troubleshooted that, and I saw a combination of high CPU usage spikes and Swap usage.
Using iostat and iotop I monitored what was speed of transference of only 1 MB/second!!.
I even did swapoff and it took one hour to free 4 GB swap partition!.
I also saw swap partition being in a spinning disk, and in another partition of the same spinning drive, having a swapfile. Magnetic spinning drives can only access one are of the drive at the same time, so that situation, using swap is very bad.
And I have seen situations were the swap or swapfile was mounted in a block device shared via network with the Server (like iSCSI or NFS), causing terrible performance when swapping.
So you have to adapt the strategy according to the project.
My preferred strategy for Compute Nodes and NoSQL Databases is to not use swap at all. In other cases, like MySQL Databases I may set swappiness to preferably to 1 or to 10.
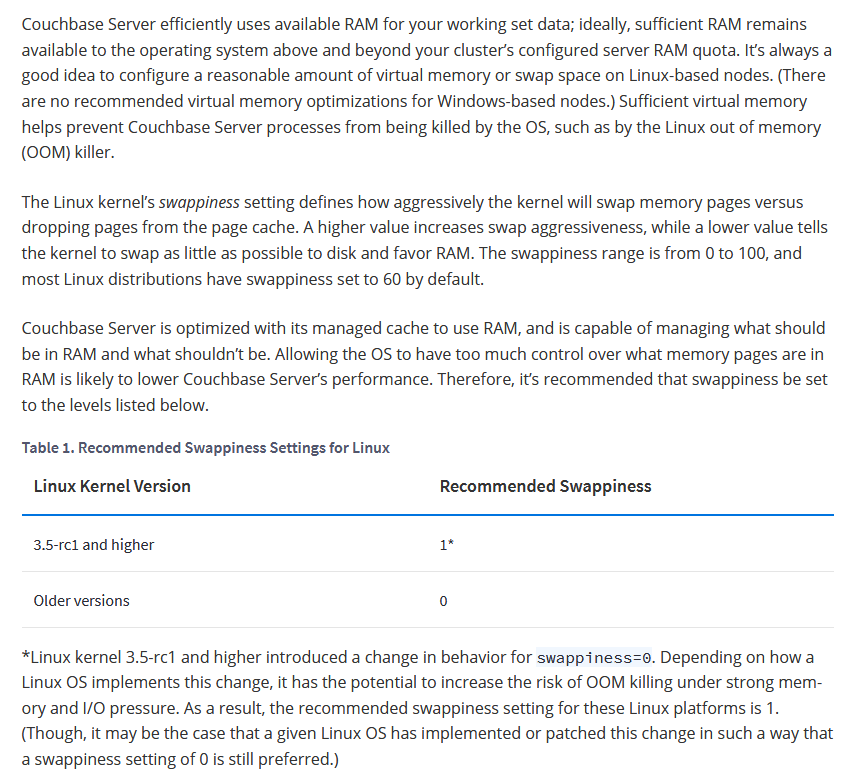
The Linux kernel’s swappiness setting defines how aggressively the kernel will swap memory pages versus dropping pages from the page cache. A higher value increases swap aggressiveness, while a lower value tells the kernel to swap as little as possible to disk and favor RAM. The swappiness range is from 0 to 100, and most Linux distributions have swappiness set to 60 by default.
Couchbase Server is optimized with its managed cache to use RAM, and is capable of managing what should be in RAM and what shouldn’t be. Allowing the OS to have too much control over what memory pages are in RAM is likely to lower Couchbase Server’s performance. Therefore, it’s recommended that swappiness be set to the levels listed below.
Another theme, is when you log to a Server and you see all the Swap memory in use.
Linux may have moved the pages that were less used, and that may be Ok for some cases, for example a Cron Service that waits and runs every 24 hours. It is safe to swap that (as long as the swap IO is decent).
When Kernel Swaps it may generate locks.
But if we log to a Server and all the Swap is in use, how can we know that the Swap has been quiet there?.
Well, you can use iostat or iotop or you can:
cat /proc/vmstat
This file contains a lot of values related to Memory, we will focus on:
Paging refers to writing portions, termed pages, of a process’ memory to disk. Swapping, strictly speaking, refers to writing the entire process, not just part, to disk. In Linux, true swapping is exceedingly rare, but the terms paging and swapping often are used interchangeably.
page-out: The system’s free memory is less than a threshold “lotsfree” and unnused / least used pages are moved to the swap area. page-in: One process which is running requested for a page that is not in the current memory (page-fault), it’s pages are being brought back to memory. swap-out: System is thrashing and has deactivated a process and it’s memory pages are moved into the swap area. swap-in: A deactivated process is back to work and it’s pages are being brought into the memory.
Values from /proc/vmstat:
pgpgin, pgpgout – number of pages that are read from disk and written to memory, you usually don’t need to care that much about these numbers
pswpin, pswpout – you may want to track these numbers per time (via some monitoring like prometheus), if there are spikes it means system is heavily swapping and you have a problem.
In this actual example that means that since the start of the Server there has been 508992338 Page Swap In (with 4K memory pages this is 1,941 GB, so almost 2 TB transferred) and for Page Swat Out (with 4K memory pages this is 1,071 GB, so 1 TB of transferred). I’m talking about a Server that had a 4GB swap partition in a spinning disk and a 12 GB swapfile in another ext4 partition of the same spinning disk.
The 16 GB of swap were in use and iotop showed only two sources of IO, one being 2 VMs writing, another was a journaling process writing to the mountpoint where the swapfile was. That was an spinning drive (underlying hardware was raid, for simplicity I refer to one single drive. I checked that both spinning drives were healthy and fast). I saw small variations in the size of the Swap, so I decided to monitor the changes in pswpin and pswpout in /proc/vmstat to see how much was transferred from/to swap.
I saw then how many pages were being transferred!.
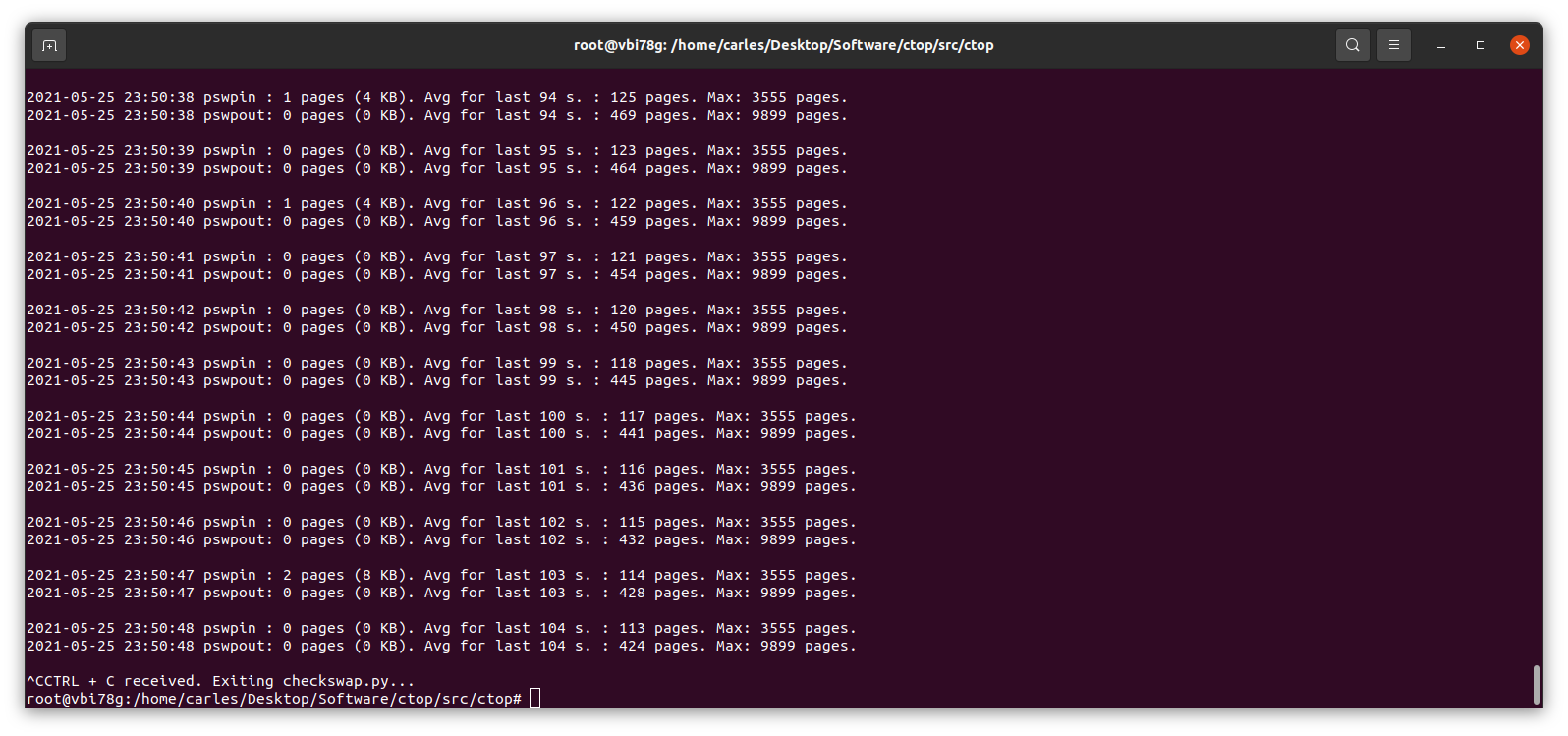
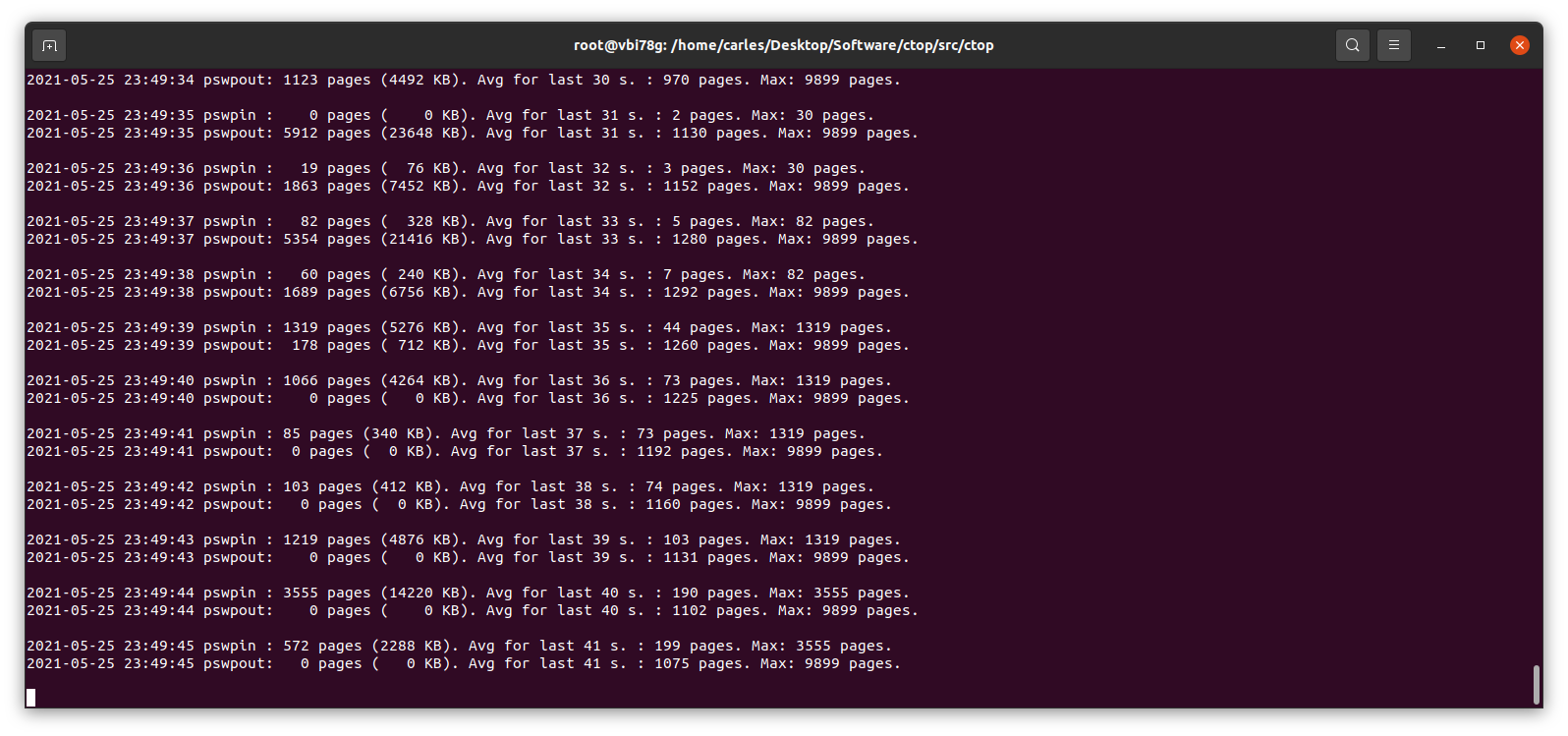
I wrote a small Python program to track those changes:
This little program works in Python 2 and Python 3, and will show the evolution of pswpin and pswpout in /proc/vmstat and will offer the average for last 5 minutes and keep the max value detected as well.
As those values show the page swaps since the start of the Server, my little program, makes the adjustments to show the Page Swaps per second.
A cheap way to reproduce collapse by using swap is using VirtualBox: install an Ubuntu 20.04 LTS in there, with 2 GB of less of memory, and one single core. Ping that VM from elsewhere.
Then you may run a little program like this in order to force it to swap:
#!/usr/bin/env python3
a_items = []
i_total = 0
# Add zeros if your VM has more memory
for i in range(0, 10000000):
i_total = i_total + i
a_items.append(i_total)
And checkswap will show you the spikes:
Many voices are discordant. Some say swappiness default value of 60 is good, as Linux will use the RAM memory to optimize the IO. In my experience, I’ve seen Hypervisors Servers running Virtual Machines that fit on the available physical RAM and were doing pure CPU calculations, no IO, and the Hypervisor was swapping just because it had swappiness to 60. Also having swap on spinning drives, mixing swap partition and swapfile, and that slowing down everything. In a case like that it would be much better not using Swap at all.
In most cases the price of Swapping to disk is much more higher than the advantage than a buffer for IO brings. And in the case of a swapfile, well, it’s also a file, so my suspect is that the swapfile is also buffered. Nothing I recommend, honestly.
My program https://gitlab.com/carles.mateo/checkswap may help you to demonstrate how much damage the swapping is doing in terms of IO. Combine it with iostat and iotop --only to see how much bandwidth is wasted writing and reading from/to swap.
You may run checkswap from a screen session and launch it with tee so results are logged. For example:
python3 checkswap.py | tee 2021-05-27-2107-checkswap.log
If you want to automatically add the datetime you can use:
python3 checkswap.py | tee `date +%Y-%m-%d-%H%M`-checkswap.log
Press CTRL + a and then d, in order to leave the screen session and return to regular Bash.
Type screen -r to resume your session if this was the only screen session running in background.
An interesting reflection from help Ubuntu:
The “diminishing returns” means that if you need more swap space than twice your RAM size, you’d better add more RAM as Hard Disk Drive (HDD) access is about 10³ slower then RAM access, so something that would take 1 second, suddenly takes more then 15 minutes! And still more then a minute on a fast Solid State Drive (SSD)…
Here is an easy trick that you can use for adding swap temporarily to a Server, VMs or Workstations, if you are in an emergency.
In this case I had a cluster composed from two instances running out of memory.
I got an alert for one of the Servers, reporting that only had 7% of free memory.
Immediately I checked it, but checked also any other forming part of the cluster.
Another one appeared, had just only a bit more memory than the other, but was considered in Critical condition too.
The owner of the Service was contacted and asked if we can hold it until US Business hours. Those Servers were going to be replaced next day in US Business hours, and when possible it would be nice not to wake up the Team. It was day in Europe, but night in US.
I checked the status of the Server with those commands:
# df -h
There are 13GB of free space in /. More than enough to be safe as this service doesn’t use much.
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 139M 298M 738M 320M
Swap: 0B 0B 0B
I checked the memory, ok, there are only 139MB free in this node, but 738MB are buff/cache. Buff/Cache is memory used by Linux to optimize I/O as long as it is not needed by application. These 738 MB in buff/cache (or most of it) will be used if needed by the System. The field available corresponds to the memory that is available for starting new applications (not counting the swap if there was any), and basically is the free memory plus a fragment of the buff/cache. I’m sure we could use more than 320MB and there is a lot if buff/cache, but to play safe we play by the book.
With that in mind it seemed that it would hold perfectly to Business hours.
I checked top. It is interesting to mention the meaning of the Column RES, which is resident memory, in other words, the real amount of memory that the process is using.
I had a Java process using 4.57GB of RAM, but a look at how much Heap Memory was reserved and actually being used showed a Heap of 4GB (Memory reserved) and 1.5GB actually being used for real, from the Heap, only.
It was unlikely that elastic search would use all those 4GB, and seemed really unlikely that the instance will suffer from memory starvation with 2.5GB of 4GB of the Heap free, ~1GB of RAM in buffers/cache plus free, so looked good.
To be 100% sure I created a temporary swap space in a file on the SSD.
(# means that I’m executing this as root, if you type literally with # in front, this will be a comment)
# fallocate -l 1G /swapfile-temp
# dd if=/dev/zero of=/swapfile-temp bs=1024 count=1048576 status=progress
1034236928 bytes (1.0 GB) copied, 4.020716 s, 257 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 4.26152 s, 252 MB/s
If you ask me why I had to dd, I will tell you that I needed to. I checked with command blkid and filesystem was xfs. I believe that was the reason.
The speed writing to the file is fair enough for a swap.
# chmod 600 /swapfile-temp
# mkswap /swapfile-temp
Setting up swapspace version 1, size = 1048572 KiB
no label, UUID=5fb12c0c-8079-41dc-aa20-21477808619a
# swapon /swapfile-temp
I check that memory is good:
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 117M 298M 770M 329M
Swap: 1.0G 0B 1.0G
And finally I check that the Kernel parameter swappiness is not too aggressive:
# sysctl vm.swappiness
vm.swappiness = 30
Cool. 30 is a fair enough value.
2022-01-05 Update for my students that need to add additional 16GB of swap to their SSD drive:
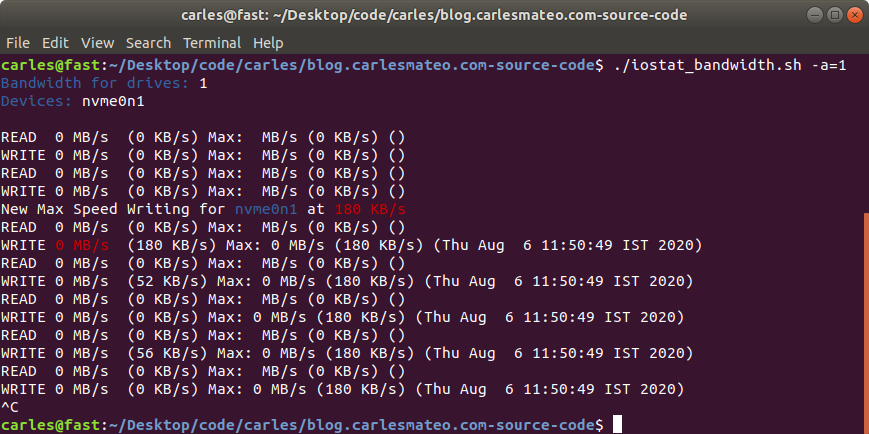
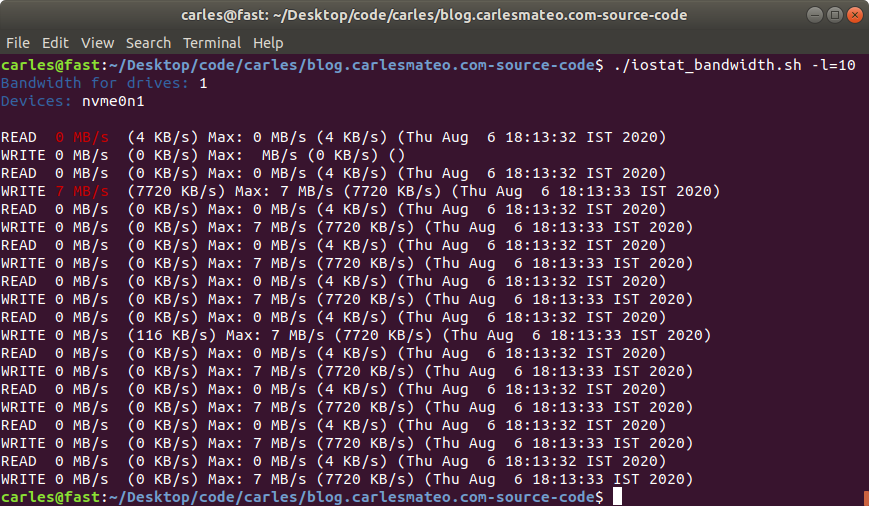
This is a shell script I made long time ago and I use it to monitor in real time what’s the total or individual bandwidth and maximum bandwidth achieved, for READ and WRITE, of Hard drives and NMVe devices.
It uses iostat to capture the metrics, and then processes the maximum values, the combined speed of all the drives… has also an interesting feature to let out the booting device. That’s very handy for Rack Servers where you boot from an SSD card or and SD, and you want to monitor the speed of the other (SAS probably) devices.
I used it to monitor the total bandwidth achieved by our 4U60 and 4U90 Servers, the All-Flash-Arrays 2U and the NVMe 1U units in Sanmina and the real throughput of IOC (Input Output Controllers).
I used also to compare what was the real data written to ZFS and mdraid RAID systems, and to disks and the combined speed with different pool configurations, as well as the efficiency of iSCSI and NFS from clients to the Servers.
You can specify how many times the information will be printed, whether you want to keep the max speed of each device per separate, and specify a drive to exclude. Normally it will be the boot drive.
If you want to test performance metrics you should make sure that other programs are not running or using the swap, to prevent bias. You should disable the boot drive if it doesn’t form part of your tests (like in the 4U60 with an SSD boot drive in a card, and 60 hard drive bays SAS or SATA).
You may find useful tools like iotop.
You can find the code here, and in my gitlab repo:
#!/usr/bin/env bash
AUTHOR="Carles Mateo"
VERSION="1.4"
# Changelog
# 1.4
# Added support for NVMe drives
# 1.3
# Fixed Decimals in KB count that were causing errors
# 1.2
# Added new parameter to output per drive stats
# Counting is performed in KB
# Leave boot device empty if you want to add its activity to the results
# Specially thinking about booting SD card or SSD devices versus SAS drives bandwidth calculation.
# Otherwise use i.e.: s_BOOT_DEVICE="sdcv"
s_BOOT_DEVICE=""
# If this value is positive the loop will be kept n times
# If is negative ie: -1 it will loop forever
i_LOOP_TIMES=-1
# Display all drives separatedly
i_ALL_SEPARATEDLY=0
# Display in KB or MB
s_DISPLAY_UNIT="M"
# Init variables
i_READ_MAX=0
i_WRITE_MAX=0
s_READ_MAX_DATE=""
s_WRITE_MAX_DATE=""
i_IOSTAT_READ_KB=0
i_IOSTAT_WRITE_KB=0
# Internal variables
i_NUMBER_OF_DRIVES=0
s_LIST_OF_DRIVES=""
i_UNKNOWN_OPTION=0
# So if you run in screen you see colors :)
export TERM=xterm
# ANSI colors
s_COLOR_RED='\033[0;31m'
s_COLOR_BLUE='\033[0;34m'
s_COLOR_NONE='\033[0m'
for i in "$@"
do
case $i in
-b=*|--boot_device=*)
s_BOOT_DEVICE="${i#*=}"
shift # past argument=value
;;
-l=*|--loop_times=*)
i_LOOP_TIMES="${i#*=}"
shift # past argument=value
;;
-a=*|--all_separatedly=*)
i_ALL_SEPARATEDLY="${i#*=}"
shift # past argument=value
;;
*)
# unknown option
i_UNKNOWN_OPTION=1
;;
esac
done
if [[ "${i_UNKNOWN_OPTION}" -eq 1 ]]; then
echo -e "${s_COLOR_RED}Unknown option${s_COLOR_NONE}"
echo "Use: [-b|--boot_device=sda -l|--loop_times=-1 -a|--all-separatedly=1]"
exit 1
fi
if [ -z "${s_BOOT_DEVICE}" ]; then
i_NUMBER_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | wc --lines`
s_LIST_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | awk '{printf $1" ";}'`
else
echo -e "${s_COLOR_BLUE}Excluding Boot Device:${s_COLOR_NONE} ${s_BOOT_DEVICE}"
# Add an space after the name of the device to prevent something like booting with sda leaving out drives like sdaa sdab sdac...
i_NUMBER_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | grep -v "${s_BOOT_DEVICE} " | wc --lines`
s_LIST_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | grep -v "${s_BOOT_DEVICE} " | awk '{printf $1" ";}'`
fi
AR_DRIVES=(${s_LIST_OF_DRIVES})
i_COUNTER_LOOP=0
for s_DRIVE in ${AR_DRIVES};
do
AR_DRIVES_VALUES_AVG[i_COUNTER_LOOP]=0
AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]=0
AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]=0
i_COUNTER_LOOP=$((i_COUNTER_LOOP+1))
done
echo -e "${s_COLOR_BLUE}Bandwidth for drives:${s_COLOR_NONE} ${i_NUMBER_OF_DRIVES}"
echo -e "${s_COLOR_BLUE}Devices:${s_COLOR_NONE} ${s_LIST_OF_DRIVES}"
echo ""
while [ "${i_LOOP_TIMES}" -lt 0 ] || [ "${i_LOOP_TIMES}" -gt 0 ] ;
do
s_READ_PRE_COLOR=""
s_READ_POS_COLOR=""
s_WRITE_PRE_COLOR=""
s_WRITE_POS_COLOR=""
# In MB
# s_IOSTAT_OUTPUT_ALL_DRIVES=`iostat -d -m -y 1 1 | grep "sd\|nvm"`
# In KB
s_IOSTAT_OUTPUT_ALL_DRIVES=`iostat -d -y 1 1 | grep "sd\|nvm"`
if [ -z "${s_BOOT_DEVICE}" ]; then
s_IOSTAT_OUTPUT=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
else
# Add an space after the name of the device to prevent something like booting with sda leaving out drives like sdaa sdab sdac...
s_IOSTAT_OUTPUT=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | grep -v "${s_BOOT_DEVICE} " | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
fi
if [ "${i_ALL_SEPARATEDLY}" -eq 1 ]; then
i_COUNTER_LOOP=0
for s_DRIVE in ${AR_DRIVES};
do
s_IOSTAT_DRIVE=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | grep $s_DRIVE | head --lines=1 | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
i_IOSTAT_READ_KB=`printf "%s" "${s_IOSTAT_DRIVE}" | awk -F '|' '{print $1;}'`
i_IOSTAT_WRITE_KB=`printf "%s" "${s_IOSTAT_DRIVE}" | awk -F '|' '{print $2;}'`
if [ "${i_IOSTAT_READ_KB%.*}" -gt ${AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]%.*} ]; then
AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]=${i_IOSTAT_READ_KB}
echo -e "New Max Speed Reading for ${s_COLOR_BLUE}$s_DRIVE${s_COLOR_NONE} at ${s_COLOR_RED}${i_IOSTAT_READ_KB} KB/s${s_COLOR_NONE}"
echo
fi
if [ "${i_IOSTAT_WRITE_KB%.*}" -gt ${AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]%.*} ]; then
AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]=${i_IOSTAT_WRITE_KB}
echo -e "New Max Speed Writing for ${s_COLOR_BLUE}$s_DRIVE${s_COLOR_NONE} at ${s_COLOR_RED}${i_IOSTAT_WRITE_KB} KB/s${s_COLOR_NONE}"
fi
i_COUNTER_LOOP=$((i_COUNTER_LOOP+1))
done
fi
i_IOSTAT_READ_KB=`printf "%s" "${s_IOSTAT_OUTPUT}" | awk -F '|' '{print $1;}'`
i_IOSTAT_WRITE_KB=`printf "%s" "${s_IOSTAT_OUTPUT}" | awk -F '|' '{print $2;}'`
# CAST to Integer
if [ "${i_IOSTAT_READ_KB%.*}" -gt ${i_READ_MAX%.*} ]; then
i_READ_MAX=${i_IOSTAT_READ_KB%.*}
s_READ_PRE_COLOR="${s_COLOR_RED}"
s_READ_POS_COLOR="${s_COLOR_NONE}"
s_READ_MAX_DATE=`date`
i_READ_MAX_MB=$((i_READ_MAX/1024))
fi
# CAST to Integer
if [ "${i_IOSTAT_WRITE_KB%.*}" -gt ${i_WRITE_MAX%.*} ]; then
i_WRITE_MAX=${i_IOSTAT_WRITE_KB%.*}
s_WRITE_PRE_COLOR="${s_COLOR_RED}"
s_WRITE_POS_COLOR="${s_COLOR_NONE}"
s_WRITE_MAX_DATE=`date`
i_WRITE_MAX_MB=$((i_WRITE_MAX/1024))
fi
if [ "${s_DISPLAY_UNIT}" == "M" ]; then
# Get MB
i_IOSTAT_READ_UNIT=${i_IOSTAT_READ_KB%.*}
i_IOSTAT_WRITE_UNIT=${i_IOSTAT_WRITE_KB%.*}
i_IOSTAT_READ_UNIT=$((i_IOSTAT_READ_UNIT/1024))
i_IOSTAT_WRITE_UNIT=$((i_IOSTAT_WRITE_UNIT/1024))
fi
# When a MAX is detected it will be displayed in RED
echo -e "READ ${s_READ_PRE_COLOR}${i_IOSTAT_READ_UNIT} MB/s ${s_READ_POS_COLOR} (${i_IOSTAT_READ_KB} KB/s) Max: ${i_READ_MAX_MB} MB/s (${i_READ_MAX} KB/s) (${s_READ_MAX_DATE})"
echo -e "WRITE ${s_WRITE_PRE_COLOR}${i_IOSTAT_WRITE_UNIT} MB/s ${s_WRITE_POS_COLOR} (${i_IOSTAT_WRITE_KB} KB/s) Max: ${i_WRITE_MAX_MB} MB/s (${i_WRITE_MAX} KB/s) (${s_WRITE_MAX_DATE})"
if [ "$i_LOOP_TIMES" -gt 0 ]; then
i_LOOP_TIMES=$((i_LOOP_TIMES-1))
fi
done
This is a great new for scaling performance in the Data Centers. For routers, switches…
And this makes me think about all the Architects that are using Memcached and Redis in different Servers, in Networks of 1Gbps and makes me want to share with you what a nonsense, is often, that.
So the idea of having Memcache or Redis is just to cache the queries and unload the Database from those queries.
But 1Gbps is equivalent to 125MB (Megabytes) per second.
Local RAM Memory in Servers can perform at 24GB and more (24,000,000 Megabytes) per second, even more.
A PCIE NVMe drive at 3.5GB per second.
A local SSD drive without RAID 550 MB/s.
A SSD in the Cloud, varies a lot on the provider, number of drives, etc… but I’ve seen between 200 MB/s and 2.5GB/s aggregated in RAID.
In fact I have worked with Servers equipped with several IO Controllers, that were delivering 24GB/s of throughput writing or reading to HDD spinning drives.
If you’re in the Cloud. Instead of having 2 Load Balancers, 100 Front Web servers, with a cluster of 5 Redis with huge amount of RAM, and 1 MySQL Master and 1 Slave, all communicating at 1Gbps, probably you’ll get a better performance having the 2 LBs, and 11 Front Web with some more memory and having the Redis instance in the same machine and saving the money of that many small Front and from the 5 huge dedicated Redis.
The same applies if you’re using Docker or K8s.
Even if you just cache the queries to drive, speed will be better than sending everything through 1 Gbps.
This will matter for you if your site is really under heavy load. Most of the sites just query the MySQL Server using 1 Gbps lines, or 2 Gbps in bonding, and that’s enough.
First you have to understand that Python, Java and PHP are worlds completely different.
In Python you’ll probably use Flask, and listen to the port you want, inside Docker Container.
In PHP you’ll use a Frameworks like Laravel, or Symfony, or Catalonia Framework (my Framework) :) and a repo or many (as the idea is that the change in one microservice cannot break another it is recommended to have one git repo per Service) and split the requests with the API Gateway and Filters (so /billing/ goes to the right path in the right Server, is like rewriting URLs). You’ll rely in Software to split your microservices. Usually you’ll use Docker, but you have to add a Web Server and any other tools, as the source code is not packet with a Web Server and other Dependencies like it is in Java Spring Boot.
In Java you’ll use Spring Cloud and Spring Boot, and every Service will be auto-contained in its own JAR file, that includes Apache Tomcat and all other Dependencies and normally running inside a Docker. Tcp/Ip listening port will be set at start via command line, or through environment. You’ll have many git repositories, one per each Service.
Using many repos, one per Service, also allows to deploy only that repository and to have better security, with independent deployment tokens.
It is not unlikely that you’ll use one language for some of your Services and another for other, as well as a Database or another, as each Service is owner of their data.
In any case, you will be using CI/CD and your pipeline will be something like this:
Pull the latest code for the Service from the git repository
Compile the code (if needed)
Run the Unit and Integration Tests
Compile the service to an executable artifact (f.e. Java JAR with Tomcat server and other dependencies)
Generate a Machine image with your JAR deployed (for Java. Look at Spotify Docker Plugin to Docker build from Maven), or with Apache, PHP, other dependencies, and the code. Normally will be a Docker image. This image will be immutable. You will probably use Dockerhub.
Machine image will be started. Platform test are run.
If platform tests pass, the service is promoted to the next environment (for example Dev -> Test -> PreProd -> Prod), the exact same machine is started in the next environment and platform tests are repeated.
Before deploying to Production the new Service, I recommend running special Application Tests / Behavior-driven. By this I mean, to conduct tests that really test the functionality of everything, using a real browser and emulating the acts of a user (for example with BeHat, Cucumber or with JMeter). I recommend this specially because Microservices are end-points, independent of the implementation, but normally they are API that serve to a whole application. In an Application there are several components, often a change in the Front End can break the application. Imagine a change in Javascript Front End, that results in a call a bit different, for example, with an space before a name. Imagine that the Unit Tests for the Service do not test that, and that was not causing a problem in the old version of the Service and so it will crash when the new Service is deployed. Or another example, imagine that our Service for paying with Visa cards generates IDs for the Payment Gateway, and as a result of the new implementation the IDs generated are returned. With the mocked objects everything works, but when we deploy for real is when we are going to use the actual Bank Payment. This is also why is a good idea to have a PreProduction environment, with PreProduction versions of the actual Services we use (all banks or the GDS for flights/hotel reservation like Galileo or Amadeus have a Test, exactly like Production, Gateway)
If you work with Microsoft .NET, you’ll probably use Azure DevOps.
We IT Engineers, CTOs and Architects, serve the Business. We have to develop the most flexible approaches and enabling the business to release as fast as their need.
Take in count that Microservices is a tool, a pattern. We will use it to bring more flexibility and speed developing, resilience of the services, and speed and independence deploying. However this comes at a cost of complexity.
Microservices is more related to giving flexibility to the Business, and developing according to the Business Domains. Normally oriented to suite an API. If you have an API that is consumed by third party you will have things like independence of Services (if one is down the others will still function), gradual degradation, being able to scale the Services that have more load only, being able to deploy a new version of a Service which is independent of the rest of the Services, etc… the complexity in the technical solution comes from all this resilience, and flexibility.
If your Dev Team is up to 10 Developers or you are writing just a CRUD Web Application, a PoC, or you are an Startup with a critical Time to Market you probably you will not want to use Microservices approach. Is like killing flies with laser cannons. You can use typical Web services approach, do everything in one single Https request, have transactions, a single Database, etc…
But if your team is 100 Developer, like a big eCommerce, you’ll have multiple Teams between 5 and 10 Developers per Business Domain, and you need independence of each Service, having less interdependence. Each Service will own their own Data. That is normally around 5 to 7 tables. Each Service will serve a Business Domain. You’ll benefit from having different technologies for the different needs, however be careful to avoid having Teams with different knowledge that can have hardly rotation and difficult to continue projects when the only 2 or 3 Devs that know that technology leave. Typical benefit scenarios can be having MySql for the Billing Services, but having NoSQL Database for the image catalog, or to store logs of account activity. With Microservices, some services will be calling other Services, often asynchronously, using Queues or Streams, you’ll have Callbacks, Databases for reading, you’ll probably want to have gradual and gracefully failure of your applications, client load balancing, caches and read only databases/in-memory databases… This complexity is in order to protect one Service from the failure of others and to bring it the necessary speed under heavy load.
Here you can find a PDF Document of the typical resources I use for Microservice Projects.
Few months ago I encountered with a problem with RHEL installer and some of the M.2 drives.
I’ve productized my Product, to be released with M.2 booting SATA drives of 128GB.
The procedure for preparing the Servers (90 and 60 drives, Cold Storage) was based on the installation of RHEL in the M.2 128GB drive. Then the drives are cloned.
Few days before mass delivery the company request to change the booting M.2 drives for others of our own, 512 GB drives.
I’ve tested many different M.2 drives and all of them were slightly different.
Those 512 GB M.2 drives had one problem… Red Hat installer was failing with a python error.
We were running out of time, so I decided to clone directly from the 128GB M.2 working card, with everything installed, to the 512 GB card. Doing that is so easy as booting with a Rescue Linux USB disk, and then doing a dd from the 128GB drive to the 512GB drive.
Booting with a live USB system is important, as Filesystem should not be mounted to prevent corruption when cloning.
Then, the next operation would be booting the 512 GB drive and instructing Linux to claim the additional space.
Here is the procedure for doing it (note, the OS installed in the M.2 was CentOS in this case):
Determine the device that needs to be operated on (this will usually be the boot drive); in this example it is /dev/sdae
Extend the desired LVM partition (lvextend command)
# pvdisplay /dev/sdbm: open failed: No medium found /dev/sdbn: open failed: No medium found /dev/sdbj: open failed: No medium found /dev/sdbk: open failed: No medium found /dev/sdbl: open failed: No medium found --- Physical volume --- PV Name /dev/sdae2 VG Name centos_4602c PV Size 118.24 GiB / not usable 3.00 MiB Allocatable yes (but full) PE Size 4.00 MiB Total PE 30269 Free PE 0 Allocated PE 30269 PV UUID yvHO6t-cYHM-CCCm-2hOO-mJWf-6NUI-zgxzwc
# pvresize /dev/sdae2 /dev/sdbm: open failed: No medium found /dev/sdbn: open failed: No medium found /dev/sdbj: open failed: No medium found /dev/sdbk: open failed: No medium found /dev/sdbl: open failed: No medium found Physical volume "/dev/sdae2" changed 1 physical volume(s) resized or updated / 0 physical volume(s) not resized
# pvdisplay /dev/sdbm: open failed: No medium found /dev/sdbn: open failed: No medium found /dev/sdbj: open failed: No medium found /dev/sdbk: open failed: No medium found /dev/sdbl: open failed: No medium found --- Physical volume --- PV Name /dev/sdae2 VG Name centos_4602c PV Size <475.84 GiB / not usable 3.25 MiB Allocatable yes PE Size 4.00 MiB Total PE 121813 Free PE 91544 Allocated PE 30269 PV UUID yvHO6t-cYHM-CCCm-2hOO-mJWf-6NUI-zgxzwc
# vgdisplay --- Volume group --- VG Name centos_4602c System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 6 VG Access read/write VG Status resizable MAX LV 0 Cur LV 3 Open LV 3 Max PV 0 Cur PV 2 Act PV 2 VG Size <475.93 GiB PE Size 4.00 MiB Total PE 121838 Alloc PE / Size 30269 / <118.24 GiB Free PE / Size 91569 / 357.69 GiB VG UUID ORcp2t-ntwQ-CNSX-NeXL-Udd9-htt9-kLfvRc
# lvextend -l +91569 /dev/centos_4602c/root Size of logical volume centos_4602c/root changed from 50.00 GiB (12800 extents) to <407.69 GiB (104369 extents). Logical volume centos_4602c/root successfully resized.
Extend the xfs file system to use the extended space
The xfs file system for the root partition will need to be extended to use the extra space; this is done using the xfs_grow command as shown below.
This is the history it happen to me some time ago, and so the commands I used to troubleshot. The purpose is to share knowledge in a interactive way. There are some hidden gems that you’ll acquire if you have the patience to go over all the document and read it all…
I had qualified Intel Xeon single processor platform to run my DRAID (ZFS Declustered RAID) project for my employer.
The platforms I qualified were:
1) single processor for Cold Storage (SAS Spinning drives): 4U60, newest models 4602
2) for multiprocessor: the 4U90 (90 Spinning drives) and Flash: All-Flash-Arrays.
The amounts of RAM I was using for my tests range for 64GB to 384GB.
Somebody in the company, at executive level, assembled an experimental config that was totally new for us and wanted to try by their own. It was the 4602 with multiprocessor and 32GB of RAM.
When they were unable to make it work at the expected speed, they required me to troubleshot and to make it work.
The 4602 single processor had two IOC (Input Output Controller, LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ), while the 4602 double processor had four IOC, so given that each of those IOC can perform at peaks of 6GB/s, with a maximum total of 24 GB/s, the performance when reading/writing from all the drives should be better.
But this Server was returning double times for Rebuilding, respect the single processor version, which didn’t make any sense.
I had to check everything. There was the commands I ran:
Check the upgrade of the CPU:
htop
lscpu
Changing the Zoning.
Those Servers use SAS drives dual ported, which means that two different computers can be connected to the same drive and operate at the same time. Is up to you to make sure you don’t introduce corruption. Those systems are used mainly for HA (High Availability).
Those Systems allow to be configured in different zoning modes. That’s the way on how each of the two servers (Controllers) see the disk. In one zoning each Controller sees only 30 drives, in another each IOC sees all the drives (for redundancy but performance constrained to 1 IOC Speed).
The config I set is each IOC will see 15 drives, so each one of the 4 IOC will have 6GB/s for 15 drives. Given that these spinning drives perform in the outtermost part of the cylinder at 265MB/s, that means that at maximum speed one IOC will be using 3.97 GB/s, will say 4GB/s. Plenty of bandwidth.
Note: Spinning drives have different performance depending on how close you’re to the cylinder. In the innermost part it goes under 145 MB/s, and if you read all of those drive sequentially with dd it will return an average speed of 145 MB/s.
With this command you can sive live how it performs and the average read speed in real time. Use skip to jump to that position (relative to bs) in the drive, so you can test directly the speed at the innermost close to the cylinder part of t.
dd if=/dev/sda of=/dev/null bs=1M status=progress
I saw that the zoning was not right one, so I set it correctly:
The sleeps after rebooting the expanders are recommended. Rebooting the Operating System too, to avoid problems with some Software as the expanders changed live.
If you have ZFS pools or workloads stop them and export the pool before messing with the expanders.
In order to check to which drives is connected each IOC:
I do this for all the drives at the same time and with iostat:
iostat -y 1 1
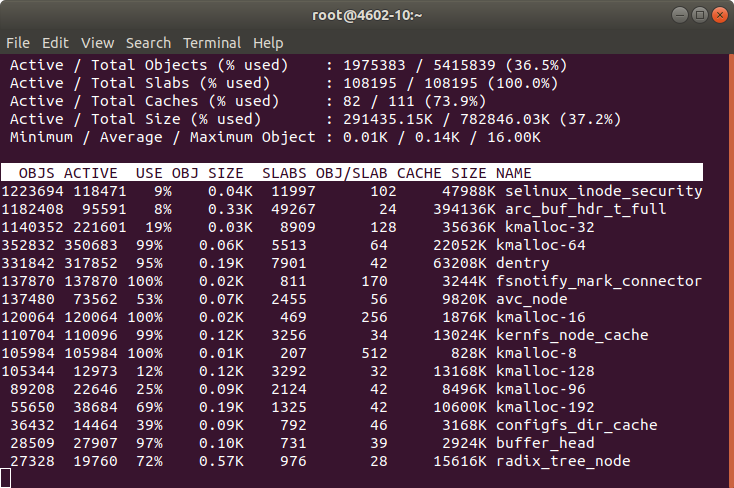
I check the status of the memory with:
slabtop
free
htop
I checked the memory and htop during a Rebuild. Memory was more than enough. However CPU usage was higher than expected.
The red bars in the image correspond to kernel processes, in this case is the DRAID Rebuild. I see that the load is higher than the usual with a single processor.
I capture all the parameters from ZFS with:
zfs get all
All this information is logged into my forensics document, so later can be checked by my Team or I can share with other Architects or other members of the company. I started this methodology after I knew how Google do their SRE forensics / postmortem documents. Also for myself is useful for the future to have a log of the commands I executed and a verbose output of the results.
I install the smp_utils
yum install smp_utils
Check things:
ls -al /dev/bsg/
total 0drwxr-xr-x. 2 root root 3020 May 22 10:16 .
drwxr-xr-x. 20 root root 8680 May 22 10:16 ..
crw-------. 1 root root 248, 76 May 22 10:00 1:0:0:0
crw-------. 1 root root 248, 126 May 22 10:00 10:0:0:0
crw-------. 1 root root 248, 127 May 22 10:00 10:0:1:0
crw-------. 1 root root 248, 136 May 22 10:00 10:0:10:0
crw-------. 1 root root 248, 137 May 22 10:00 10:0:11:0
crw-------. 1 root root 248, 138 May 22 10:00 10:0:12:0
crw-------. 1 root root 248, 139 May 22 10:00 10:0:13:0
[...]
There are some errors, and I check with the Hardware Team, which pass a battery of tests on the machine and say that the machine passes. They tell me that if the errors counted were in order of millions then it would be a problem, but having few of them is usual.
My colleagues previously reported that the memory was performing well, and the CPU too. They told me that the speed was exactly double respect a platform with one single CPU of the same kind.
Even if they told me that, I ran cmips tests to make sure.
git clone https://github.com/cmips/cmips_bin
It scored 16,000. The performance was Ok in general terms but the problem is that I didn’t have a baseline for that processor in single processor, so I cannot make sure that the memory bandwidth was Ok. The performance was less that an Amazon c3.8xlarge. The system I was testing is a two processor system, but each CPU is cheap, around USD $400.
Still my gut feeling was telling me that this double processor server should score more.
lscpu
[root@DRAID-1135-14TB-2CPU ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2299.951
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4199.73
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts spec_ctrl intel_stibp
I check the memory configuration with:
dmidecode -t memory
I examined the results, I see that the processor can only operate the DDR4 ECC 2400 Memory at 2133 and… I see something!. This Controller before was a single processor with 2 Memory Sticks of 16GB each, dual rank.
I see that now I have the same number of sticks in that machine, but I have two CPU!. So 2 Memory sticks in total, for 2 CPU.
That’s no good. The memory must be in pairs and in the right slots to get the maximum performance.
1 memory module for 1 CPU doesn’t allow to have Dual Channel and probably is affecting the performance. Many Servers will not even boot if you add an odd number of memory sticks per CPU.
And many Servers can operate at full speed only if all the banks are filled.
I request to the Engineers in Silicon Valley to add 4 modules in the right slots. They did, and I repeated the tests and the performance was doubled then.
After some days I had some time with the machine, I repeated the test and I got a CMIPS Score of around 20,000.
Multiprocessor world is far more complicated than single processor. Some times things can work not as expected, and not be evident, for example cache pipeline can act diferent for a program working in multiprocessor and single processor. Or the QPI could be saturated.
After this I shared my forensics document with as many Engineers as I could, so they could learn how I did to troubleshot the problem, and what was the origin of it, and I asked them to do the same so we can track their steps and progress if something needs to be troubleshoot.
After proper intensive testing the Server was qualified. Lesson here is that changes cannot be commited quickly, need their time.
Nothing new, zombie computers, hackers, pirates, networks of computers… trying to abuse the system and to hack into it. Why? There could be many reasons, from storing pirate movies, trying to use your Server for sending Spam, try to phishing or to host Ransomware pages…
Most of those guys doesn’t know that is almost impossible to Spam from Amazon. Few emails per hour can come out from the Server unless you explicitly requests that update and configure everything.
But I thought it was a great opportunity to force myself to update the Operating System, core tools, versions of PHP and MySql.
Forensics / Postmortem of the incident
The task was divided in two parts:
Understanding the origin of the attack
Blocking the offending Ip addresses or disabling XMLRPC
Making the VM boot again (problems with Amazon AWS)
I didn’t know why it was not booting so.
Upgrading the OS
I disabled the access to the site while I was working using Amazon Web Services Firewall. Basically I turned access to my ip only. Example: 8.8.8.8/32
I changed 0.0.0.0/0 so the world wide mask to my_Ip/3
That way the logs were reflecting only what I was doing from my Ip.
Dealing with Snapshots and Volumes in AWS
Well the first thing was doing an Snapshot.
After, I tried to boot the original Blog Server (so I don’t stop offering service) but no way, the Server appeared to be dead.
So then I attached the Volume to a new Server with the same base OS, in order to extract (dump) the database. Later I would attach the same Volume to a new Server with the most recent OS and base Software.
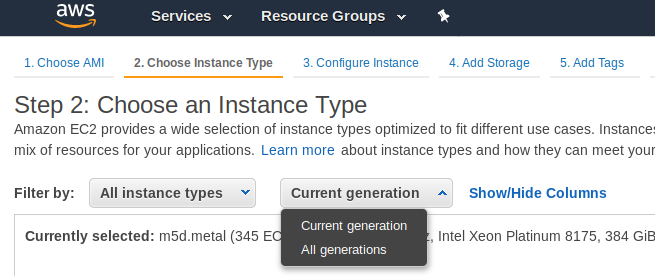
Something that is a bit annoying is that the new Instances, the new generation instances, run only in VPC, not in Amazon EC2 Classic. But my static Ip addresses are created for Amazon EC2 Classic, so I could not use them in new generation instances.
I choose the option to see all the All the generations.
Upgrading the system base Software had its own challenges too.
Upgrading the OS / Base Software
My approach was to install an Ubuntu 18.04 LTS, and install the base Software clean, and add any modification I may need.
I wanted to have all the supported packages and a recent version of PHP 7 and the latest Software pieces link Apache or MySQL.
Config files that before were working stopped working as the new Apache version requires the files or symlinks under /etc/apache2/sites-enabled/ to end with .conf extension.
Also some directives changed, so some websites will not able to work properly.
Those projects using my Catalonia Framework were affected, although I have this very well documented to make it easy to work with both versions of Apache Http Server, so it was a very straightforward change.
From the previous version I had to change my www.cataloniaframework.com.conf file and enable:
<Directory /www/www.cataloniaframework.com> Options Indexes FollowSymLinks MultiViews AllowOverride All Order allow,deny allow from all </Directory>
Then Open the ports for the Web Server (443 and 80).
sudo ufw allow in "Apache Full"
Then service apache restart
Catalonia Framework Web Site, which is also created with Catalonia Framework itself once restored
MySQL
The problem was to use the most updated version of the Database. I could use one of the backups I keep, from last week, but I wanted more fresh data.
I had the .db files and it should had been very straightforward to copy to /var/lib/mysql/ … if they were the same version. But they weren’t. So I launched an instance with the same base Software as the old previous machine had, installed mysql-server, stopped it, copied the .db files, started it, and then I made a dump with mysqldump –all-databases > 2019-04-29-all-databases.sql
Note, I copied the .db files using the mythical mc, which is a clone from Norton Commander.
Then I stopped that instance and I detached that volume and attached it to the new Blog Instance.
I did a Backup of my original /var/lib/mysql/ files for the purpose of faster restoring if something went wrong.
I mounted it under /mnt/blog_old and did mysql -u root -p < /mnt/blog_old/home/ubuntu/2019-04-29-all-databases.sql
That worked well I had restored the blog. But as I was watching the /var/log/mysql/error.log I noticed some columns were not where they should be. That’s because inadvertently I overwritten the MySql table as well, which in MySQL 5.7 has different structure than in MySQL 5.5. So I screwed. As I previewed this possibility I restored from the backup in seconds.
So basically then I edited my .sql files and removed all that was for the mysql database.
I started MySql, and run the mysql import procedure again. It worked, but I had to recreate the users for all the Databases and Grant them permissions.
GRANT ALL PRIVILEGES ON db_mysqlproxycache.* TO 'wp_dbuser_mysqlproxy'@'localhost' IDENTIFIED BY 'XWy$&{yS@qlC|<¡!?;:-ç';
PHP7
Some modules in my blogs where returning errors in /var/log/apache2/mysite-error.log so I checked that it was due to lack of support of latest PHP versions, and so I patched manually the code or I just disabled the offending plugin.
WordPress
As seen checking the /var/log/apache2/blog.carlesmateo.com-error.log some URLs where not located by WordPress.
For example:
The requested URL /wordpress/wp-json/ was not found on this server
I had to activate modrewrite and then restart Apache.
a2enmod rewrite; service apache2 restart
Making the site more secure
Checking at the logs of Apache, /var/log/apache2/blog.carlesmateo.com-access.log I checked for Ip’s accessing Admin areas, I looked for 404 Errors pointing to intents to exploit any unsafe WP Plugin, I checked for POST protocol as well.
I added to the Ubuntu Uncomplicated Firewall (UFW) the offending Ip’s and patched the xmlrpc.php file to exit always.
I encountered that Server, Xeon, 128 GB of RAM, with those 58 Spinning drives 10 TB and 2 SSD of 2 TB each, where I was testing the latest version of my Software.
Monitoring long term tests, data validation, checking for memory leaks… I notice the Server is using 70 GB of RAM. Only 5.5 GB are used for buffers according to the usual tools (top, htop, free, cat /proc/meminfo, ps aux…) and no programs are eating that amount, so where is the RAM?. The rest of the Servers are working well, including models: same mode, 4U60 with 64 GB of RAM, 4U90 with 128 GB and All-Flash-Array with 256 GB of RAM, only using around 8 GB of RAM even under load. iSCSI sharings being used, with I/O, iSCSI initiators trying to connect and getting rejected, several requests for second, disk pulling, and that usual stuff. And this is the only unit using so many memory, so what?. I checked some modules to see memory consumption, but nothing clear. Ok, after a bit of investigation one member of the Team said “Oh, while you was on holidays we created a Ramdisk and filled it for some validations, we deleted that already but never rebooted the Server”. Ok. The easy solution would be to reboot, but that would had hidden a memory leak it that was the cause. No, I had to find the real cause.
I requested assistance of one my colleagues, specialist, Kernel Engineer. He confirmed that processes were not taking that memory, and ask me to try to drop the cache.
So I did:
sync
echo 3 > /proc/sys/vm/drop_caches
Then the memory usage drop to 11.4 GB and kept like that while I maintain sustained the load.
That’s more normal taking in count that we have 16 Volumes shared and one host is attempting to connect to Volumes that do not exist any more like crazy, Services and Cronjobs run in background and we conduct tests degrading the pool, removing drives, etc..
After tests concluded memory dropped to 2 GB, which is what we use when we’re not under load.
Note: In order to know about the memory being used by Kernel slab cache in real time you can use command: