I bought this game in Steam and when I started it a grey screen appeared. The sound was on, but no image at all. I tried several times, but it didn’t work.
The fix was to browse the files from the game:
And edit options.ini
The graphical driver can be DirectX or OpenGL but in my case that value was empty.
So I added DirectX, saved, and started the game and this time it worked properly.
I wanted to do a do-release-upgrade to Update from Ubuntu 25.04 to Ubuntu 25.10, but I had almost no space left on the device. I didn’t want to uninstall the snap utilities that were using most of the space after the OS.
I created a video to explain this situation and how to fix it easily.
Host OS: Ubuntu 22.04 LTS, 64 GB of RAM
Guest OS: Ubuntu 25.04, 12 GB of RAM
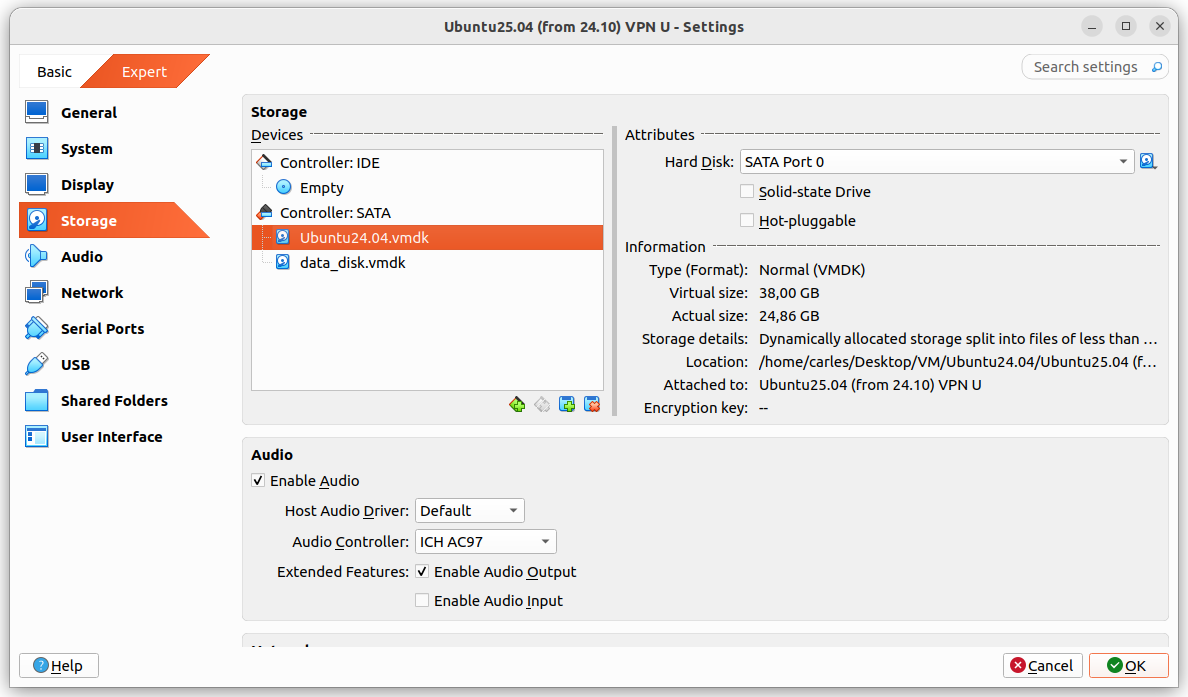
Guest drive: VMDK of 25GB, Dynamically allocated split in 2 GB files. Using 24.86GB
The problem was that I grow a disk with Virtual Box, from 25GB to 35GB and Virtual Box crashed.
It stayed in an error state, unable to access any configuration after I pressed Refresh, so I had to kill it and restart it.
I tried to expand to 36 and 37 GB with same results.
After restarting Virtual Box it shown the drive as 37 GB, so I guessed that the disk growing may have worked somehow and I tried to use the additional space from the guest VM.
I booted the guest VM with Ubuntu 25.04, sudo swapoff -a and deleted the swap partition with fdisk and I used resize2fs and growpart.
When the gues OS saw the 37GB I attempted the do-release-upgrade and it started to download packages.
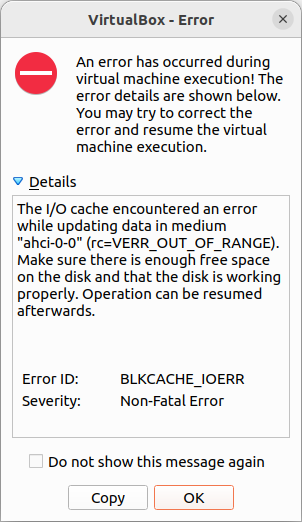
But at the point that the original 25GB were exceeded I got a recoverable IO cache error (rc=VERR_OUT_OF_RANGE).
From this point Ubuntu would be unable to complete to boot the guest VM.
I had data that I wanted to recover from the VM, so I tried to recover it, successfully.
Basically I booted with an Ubuntu 26.04 LTS live ISO, mounted the disk for read, enabled the network and scp my files to another computer.
scp, rsync, sftp… any of those will do the job.
I could also have created a new disk, attach to the guest VM, boot with Ubuntu Live, and copy from the damaged disk to the new one. Then shutdown, attach the new disk to another VM, and copy the data copied to the new disk to the healthy VM.
Or even I could have plugged an USB pendrive, telling VirtualBox to recognise those.
Claude AI hands on creating a Book e-Commerce and fixing errors, PHPStorm, PHP, Docker Desktop, MySQL in Windows
I’ll show the process of a creation of a web application for a e-Commerce book store.
The most important is to define a good requirements prompt. I created a file named docs/promptia.md
Set the quality to the max in youtube to be able to see the screen clearly.
It takes long time, so unless you want to see all the process in real time, use the chapters I added to skip to the parts you’re interested.
Chapters in the youtube video:
00:00 Tell Claude to create a web app based on docs/promptia.md 18:29 Claude asks permission to run Powershell commands 19:02 Application created 19:37 Check in PHPStorm the promptia.md 19:51 Add to git and Commit with PHPStorm 20:27 Create and launch containers 20:50 Create the containers 20:54 Launch containers 21:10 Show in Docker Desktop 21:23 Display in logs entrypoint.sh 22:04 composer install 22:19 Error: missing composer require symfony/yaml 22:32 Asking Claude to fix the error 23:50 Destroy project to ensure it is build without errors (for later in Production) 24:28 Create destroy-project.bat 25:42 Re-creating the containers 25:52 Re-creating without cache 29:20 Containers launched in Docker Desktop 30:10 composer update 30:28 Checking engine container error in a .yaml in Claude Code 31:13 Error non-existent service “doctrine system cache pool” 31:34 Inside the engine container curl http://127.0.0.1 Http Error 500 31:44 composer dump-env dev 31:57 Error a non-empty secret is required Http Error 500 32:14 Showing Claude the error, so it fixes it 33:12 Check from the engine container curl http://127.0.0.1 33:42 Error could not find the driver 33:51 Asking Claud to fix the error 34:05 Finding the error in the logs 34:27 I ask Claude, to continue with the log entry, after it finishes 35:16 Claude fixes the first problem and starts analyzing the second 35:35 Claude finds and fixes the second problem (introduced by Claude before) 37:12 Creating the Database with the Command 37:32 A new curl, and a new error found (introduced by Claude before) 37:58 Requesting to Claude to fix the error 38:25 Claude fixes the error 38:30 The new website loads correctly 39:00 Viewing register form (needs work) 39:05 Request a script to enter to mysql via CLI 40:02 I open the new script login_to_mysql.sh in PHPStorm 40:23 Trying the CLI Command to init the Database Schema 40:39 Giving chmod +x from Docker (for commiting to the repo) 40:45 login_to_mysql.sh fails (due an error introduced by Claude before) 40:58 finding extension=pdo_mysql in php.ini on the container duplicated 41:10 Asking Claude to remove the error 41:37 Claude realizes the error 41:45 Logged to MySQL with the script 42:05 DESC orders; 42:18 Asking Claude a refactor or prices from DECIMAL to Integers 43:53 Ask next questions while Claude is still working 46:56 Update the Command to reflect the new field changes 48:00 Copy the ALTER TABLE 48:05 Execute in the MySQL in Docker Desktop 48:12 Schema updated in docs/scheme.md 48:18 Add a field “public_name” 48:58 Update MySQL with the ALTER
This video shows real example of my workflow, in real time, on how I programmed with Google Antigravity some new features, like adding discount coupons, for my commercial web project for quickly audio conversion https://audioconverter.carlesmateo.com/
I show some problems when working with Gemini 3 Flash, and how I instructed the IA to fix them.
If you are getting an error like this when you try to provision using rsync or running commands from SSH from a Docker Instance from a worker node in Jenkins, having your SSH Key as a variable in Jenkins, here is a way to solve it.
These are the kind of errors that you’ll be receiving:
Load key "ssh_yourserver": invalid format
web@myserver.carlesmateo.com: Permission denied (publickey).
rsync: connection unexpectedly closed (0 bytes received so far) [sender]
rsync error: unexplained error (code 255) at io.c(235) [sender=3.1.3]
script returned exit code 255
So this applies if you copied your .pem file as text and pasted in a variable in Jenkins.
You’ll find yourself with the load key invalid format error.
I would suggest to use tokens and Vault or Consul instead of pasting a SSH Key, but if you need to just solve this ASAP that’s the trick that you need.
First encode your key with base64 without any wrapping. This is done with this command:
Note that in this case I’m ignoring Strict Host Key Checking, which is not the preferred option for security, but you may want to use it depending on your strategy and characteristics of your Cloud Deployments.
Note also that I’m indicating as User Known Hosts File /dev/null. That is something you may want to have is you provision using Docker Containers that immediately destroyed after and Jenkins has not created the user properly and it is unable to write to ~home/.ssh/known_hosts
I mention the typical errors where engineers go crazy and spend more time fixing.
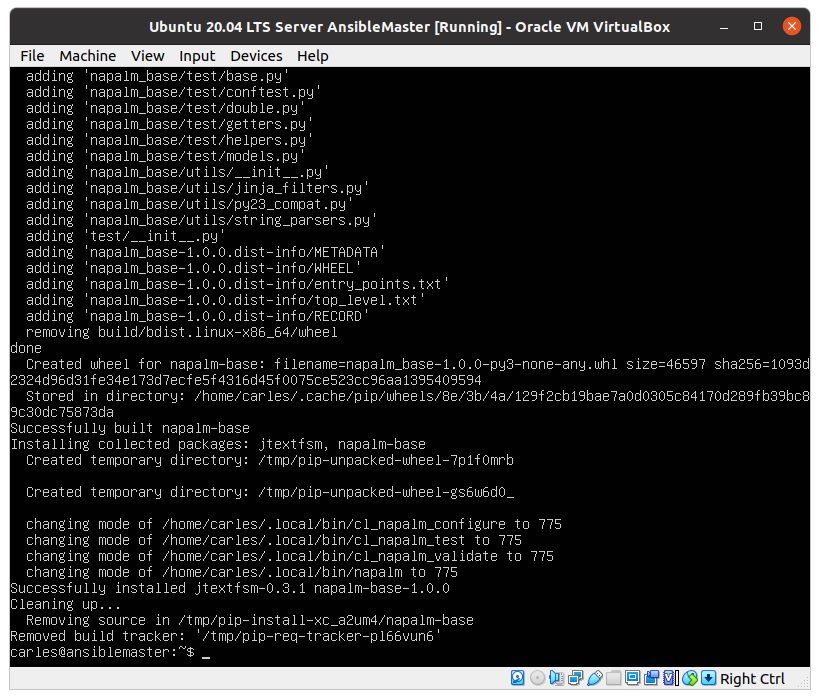
But he had problems installing napalm-base package.
Note that the package is no longer maintained.
He tried with the last one, and with the previous one (0.25.0), but he always got the error: ModuleNotFoundError: No module named ‘pip.req’
pip3 install napalm-base==0.25.0
Defaulting to user installation because normal site-packages is not writeable
Collecting napalm-base==0.25.0
Using cached napalm-base-0.25.0.tar.gz (35 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [6 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-gzd07xzq/napalm-base_aace1b03ac0e4045bbc85e27c788ebc1/setup.py", line 5, in <module>
from pip.req import parse_requirements
ModuleNotFoundError: No module named 'pip.req'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
TL;TR: The problem is that pip version 10, changed the structure for req.
There are several solutions that can be done to make it work, but the easiest way is to downgrade pip, and install the package. After pip can be upgraded again.
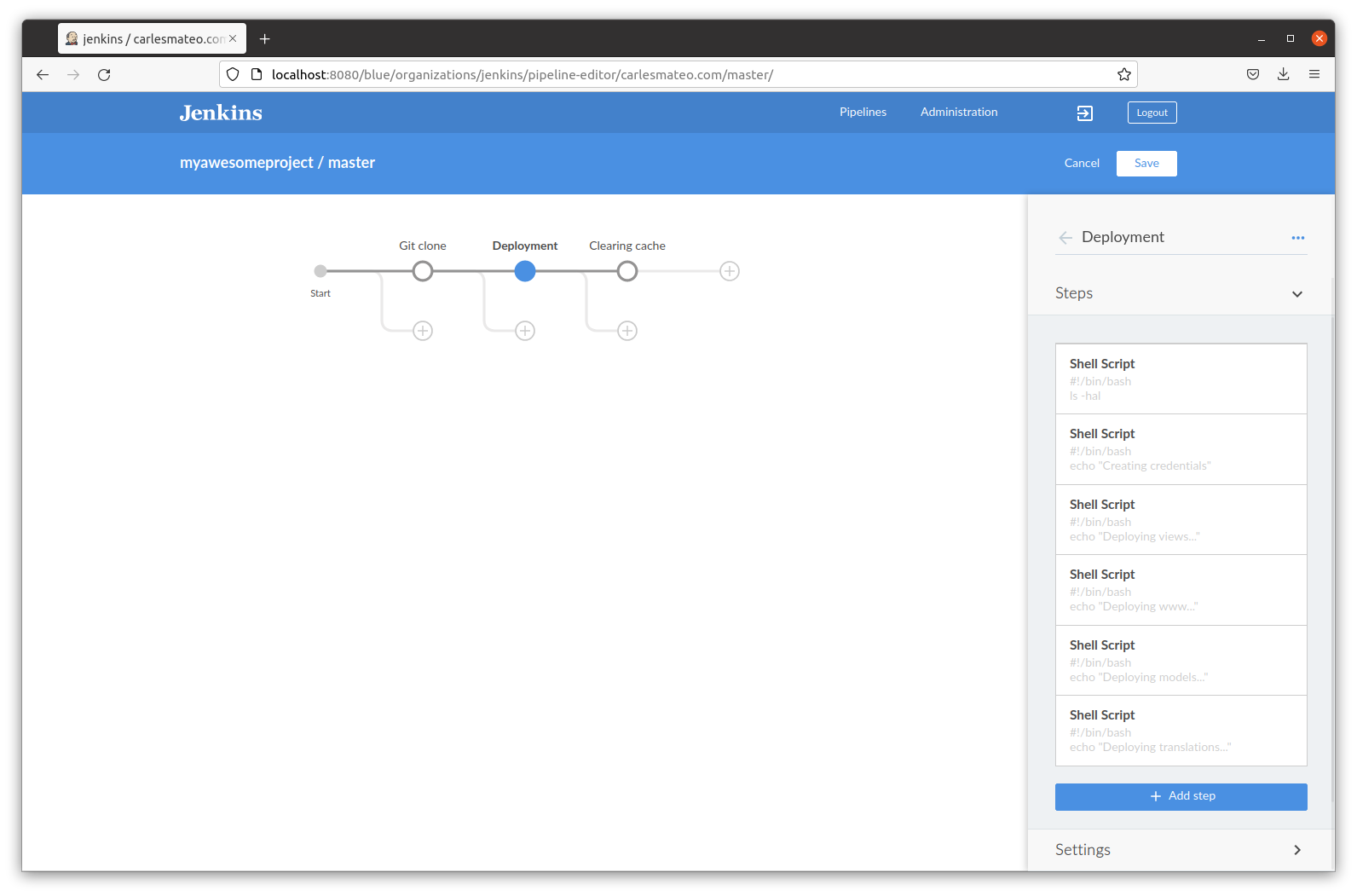
So here I explain how to solve a problem that was happening to a friend.
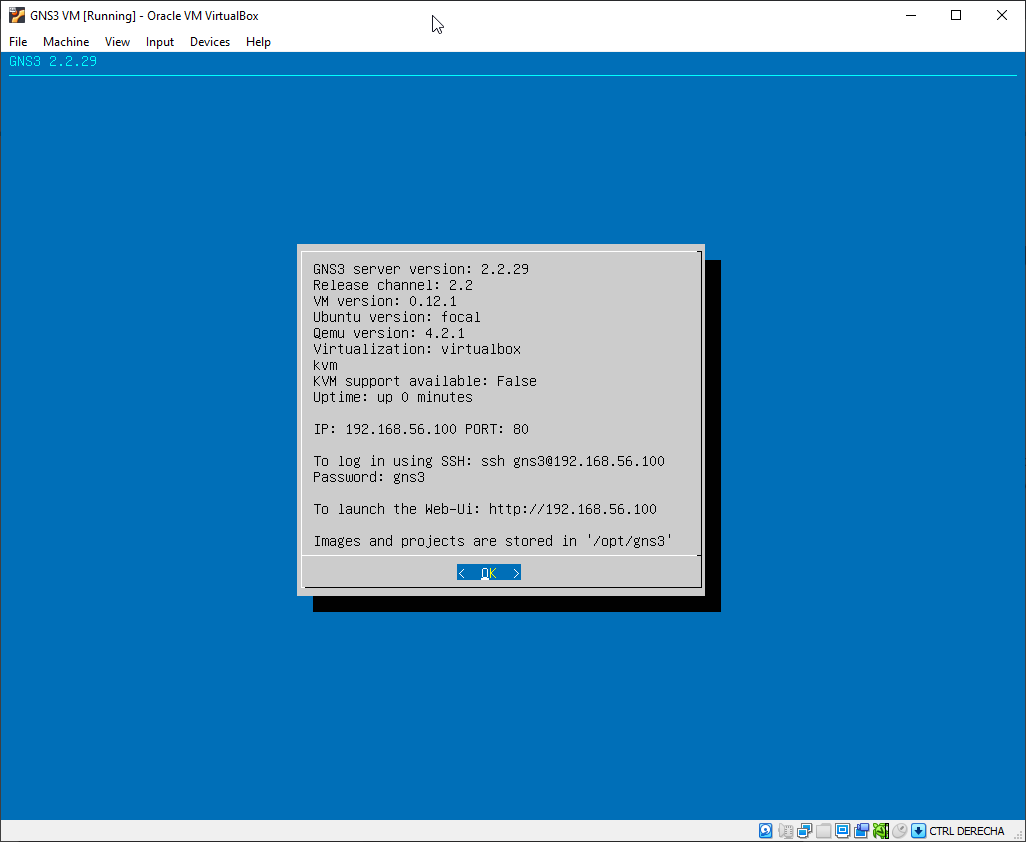
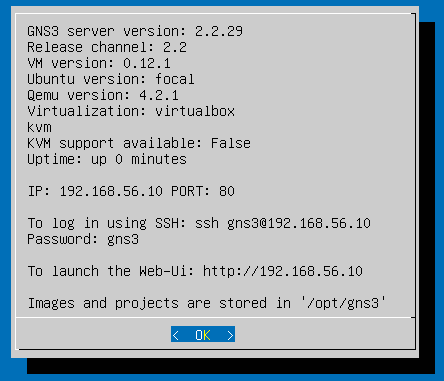
He uses GNS3 for the university, and after installing the latest version, which in this case is 2.2.29, it stopped working.
He had it configured to use the local Server and VirtualBox in Windows 10.
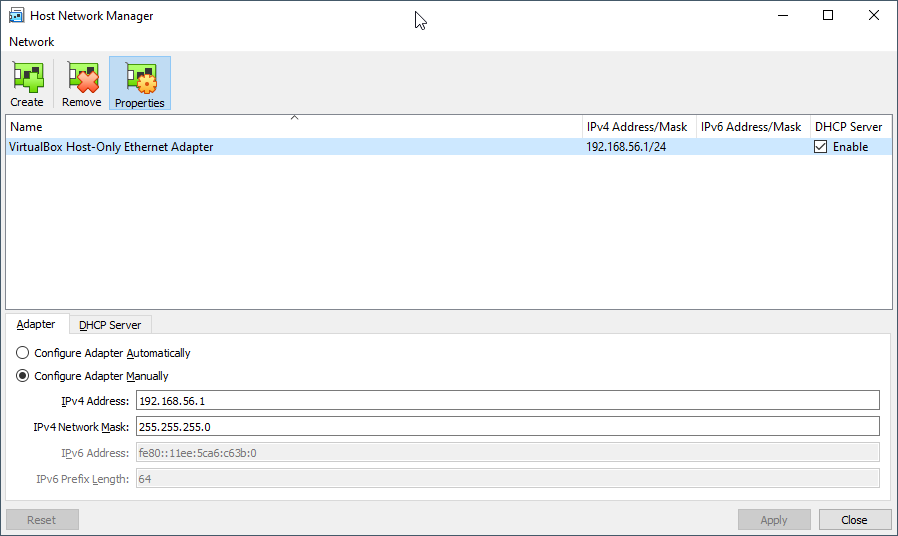
The first thing to check and to fix is the Ip address for Host Only.
If you use Linux or Mac, only certain Ip ranges can be used, or you’ll have to edit a config file inside /etc/vbox
So the first thing is to set an Ip Address in VirtualBox VM that will make you worry free.
So start VirtualBox VM directly, and when the VM boots, use the text menu application to Configure to a valid Ip from the range defined for Host Only.
You can check this in VirtualBox in File > Host Network Manager
In my initial test I picket this Ip for the VM:
192.168.56.100
But using 192.168.56.100 can bring problems as the default DHCP Server is defined with this Ip, so I switched to:
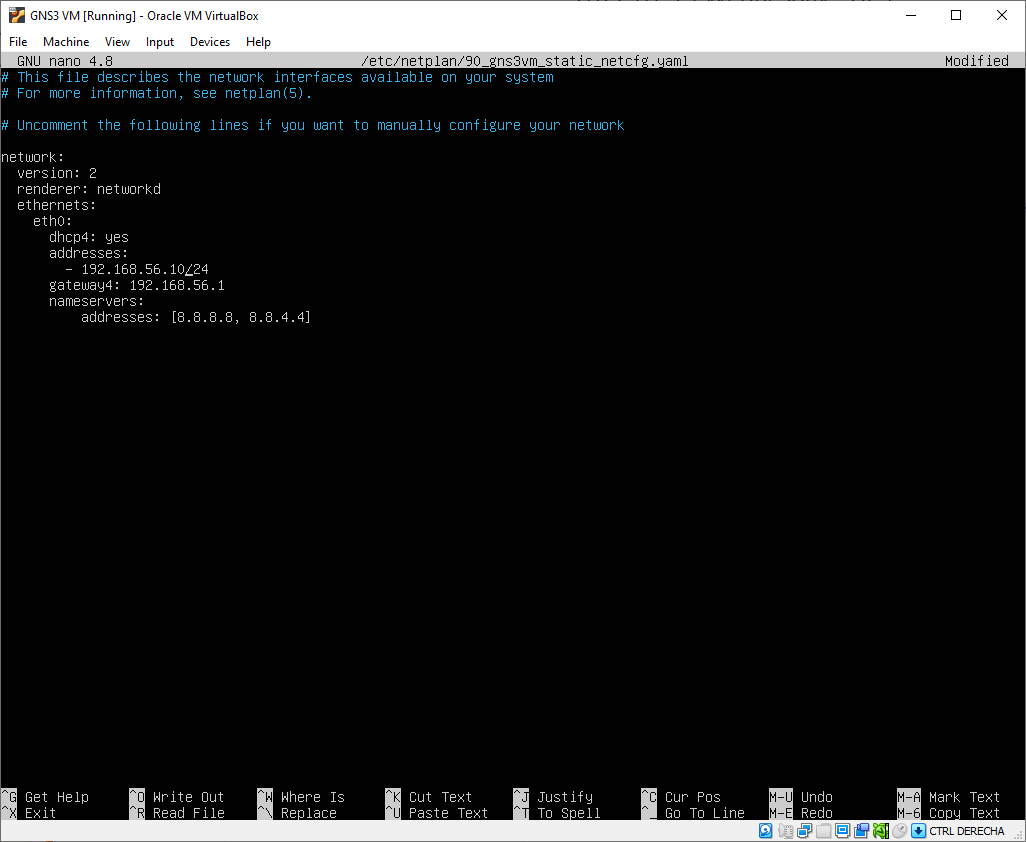
192.168.56.10
Press CTRL + X to save and exit.
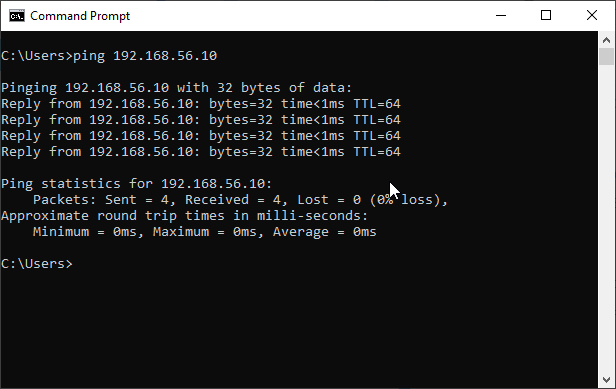
The VM will reboot automatically. Wait until it has booted and ping 192.168.56.10 from the Command Prompt.
Now, open a Windows Command Prompt or a Linux/Mac Terminal in you computer and ping the Ip:
You should also be able to see the web interface going to:
http://192.168.56.10
If it works then power off the VM, as we will start it automatically when running GNS3 main program (not from VirtualBox).
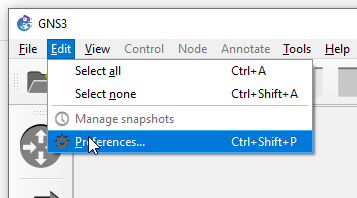
Now launch GNS3 program. Wait 30 seconds until it initializes and go to Edit > Preferences
Make sure you have the configuration like this:
Pay special attention to the Port for the GNS3 VM.
It seems like the main problem of my friend was that he was using a previous version, and he updated, and the settings from the previous version were kept. In his previous version he had configured the port 3080, but the new GNS 3 Server version 2.2.29 in the VM was using port 80, as you saw in my previous screenshots. So GNS3 was unable to connect to the VM.
After fixing this, restart GNS3, stop the VM if was not automatically stopped, and start GNS3 again.
After one minute approx connecting, you’ll see it working fine.
I’m not talking about the wonderful things, like how big can the Integers be, but about the bizarre things that may ruin your day.
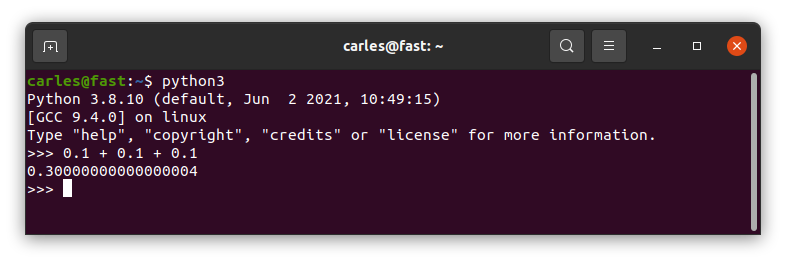
What sums 0.1 + 0.1 + 0.1 in Python?
0.3?
Wrong answer.
A bit of humor
Well, to be honest the computer was wrong. They way programming languages handle the Floats tend to be less than ideal.
Floats
Maybe you know JavaScript and its famous NaN (Not a number).
You are probably sure that Python is much more exact than that…
…well, until you do a big operation with Floats, like:
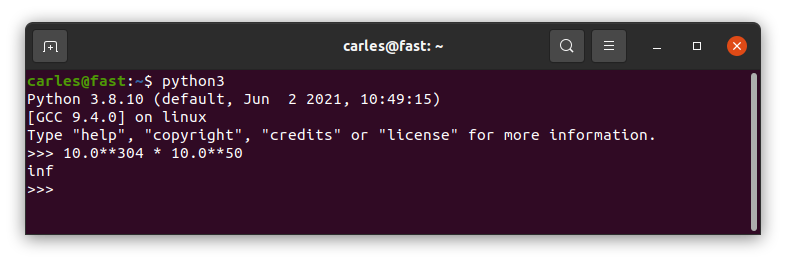
10.0**304 * 10.0**50
and
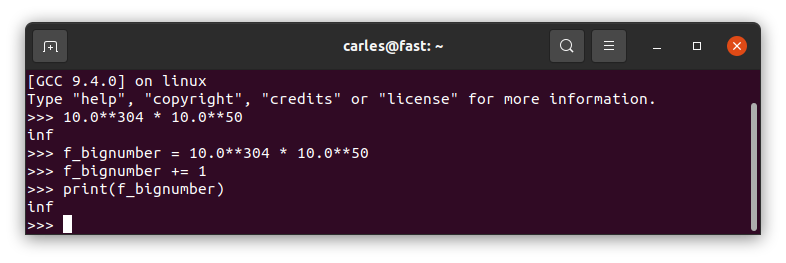
It returns infinite
I see your infinite and I add one :)
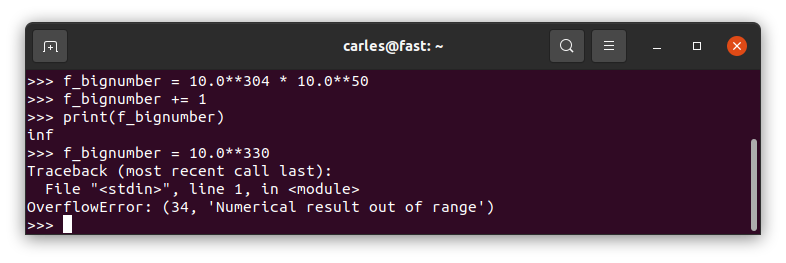
However If we try to define a number too big directly it will return OverflowError:
Please note Integers are handled in a much more robust cooler way:
Negative floats
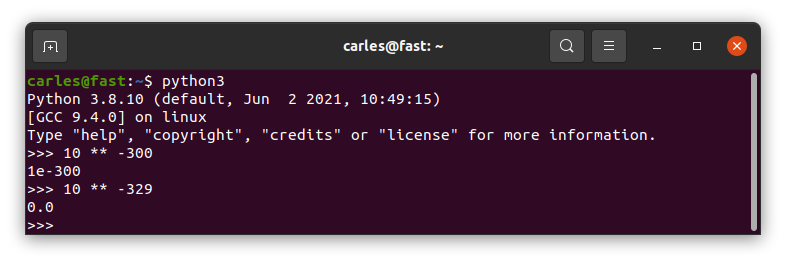
Ok. What happens if we define a number with a negative power, like 10 ** -300 ?
And if we go somewhere a bit more far? Like 10 ** -329
It returns 0.0
Ups!
I mention in my books why is better to work with Integers, and in fact most of the eCommerces, banks and APIs work with Integers. For example, if the amount in USD 10.00 they send multiplied by 100, so they will send 1000. All the actor know that they have to divide by 2.
Breaking the language innocently
I mentioned always that I use the MT Notation, the prefix notation I invented, inspired by the Hungarian Notation and by an amazing C++ programmer I worked with in Volkswagen and in la caixa (now caixabank), that passed away many years ago.
Well, that system of prefixes will name a variable with a prefix for its type.
It’s very useful and also prevents the next weird thing from Python.
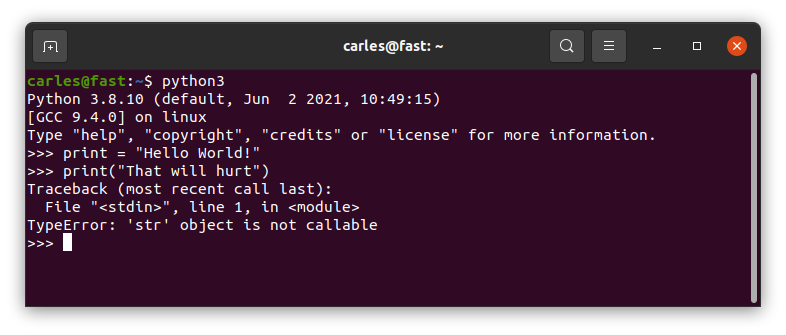
Imagine a Junior wants to print a String and they put in a variable. And unfortunately they call this variable print. Well…
print = "Hello World!"
print("That will hurt")
Observe the output of this and try not to scream:
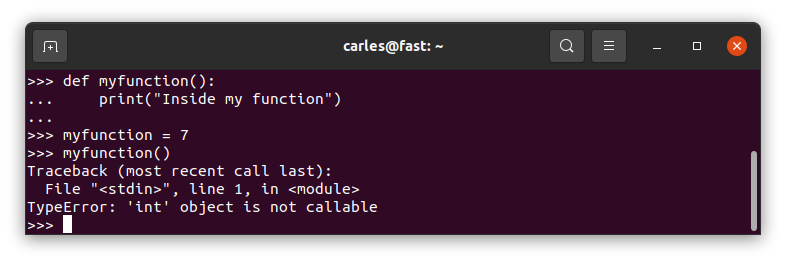
Variables and Functions named equally
Well, most of languages are able to differentiate a function, with its parenthesis, from a variable.
The way Python does it hurts my coder heart:
Another good reason to use MT Notation for the variables, and for taking seriously doing Unit Testing and giving a chance to using getters and setters and class Constructor for implementing limits and sanitation.
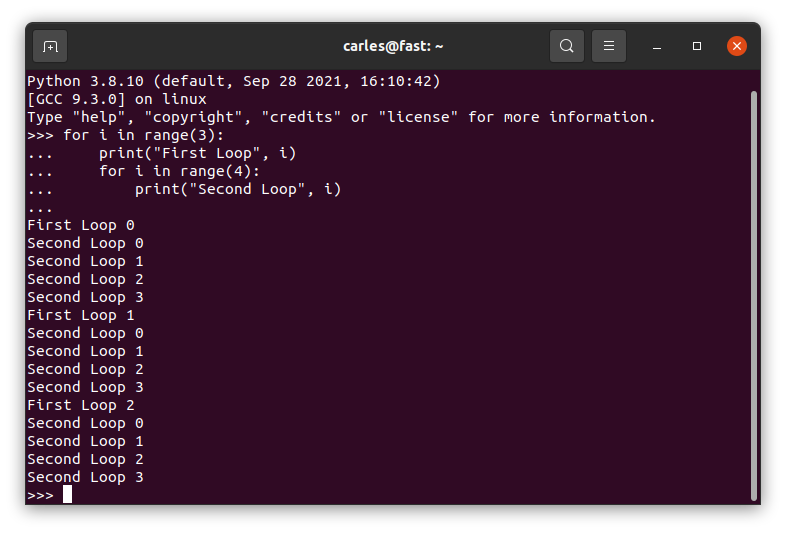
Nested Loops
This will work in Python, it doesn’t work in other languages (but please never do it).
for i in range(3):
print("First Loop", i)
for i in range(4):
print("Second Loop", i)
The code will not crash by overwriting i used in the first loop, but the new i will mask the first variable.
And please, name variables properly.
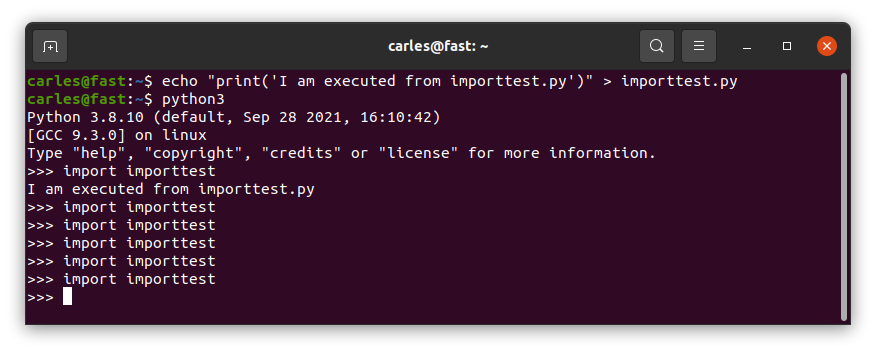
Import… once?
Imports are imported only once. Even if different files imported do import the same file.
So don’t have code in the middle of them, outside functions/classes, unless you’re really know what you’re doing.
Define functions first, and execute code after if __name__ == “__main__”:
Take a look at this code:
def first_function():
print("Inside first function")
second_function()
first_function()
def second_function():
print("Inside second function")
Well, this will crash as Python executes the code from top to bottom, and when it gets to first_function() it will attempt to call second_function() which has not been read by Python yet. This example will throw an error.
You’ll get an error like:
Inside first function
Traceback (most recent call last):
File "/home/carles/Desktop/code/carles/python_combat_guide/src/structure_dont_do_this.py", line 14, in <module>
first_function()
File "/home/carles/Desktop/code/carles/python_combat_guide/src/structure_dont_do_this.py", line 12, in first_function
second_function()
NameError: name 'second_function' is not defined
Process finished with exit code 1
Add your code at the bottom always, under:
if __name__ == "__main__":
first_function()
The code inside this if will only be executed if you directly call this code as main file, but will not be executed if you import this file from another one.
You don’t have this problem with classes in Python, as they are defined first, completely read, and then you instantiate or use them. To avoid messing and creating bugs, have the imports always on the top of your file.
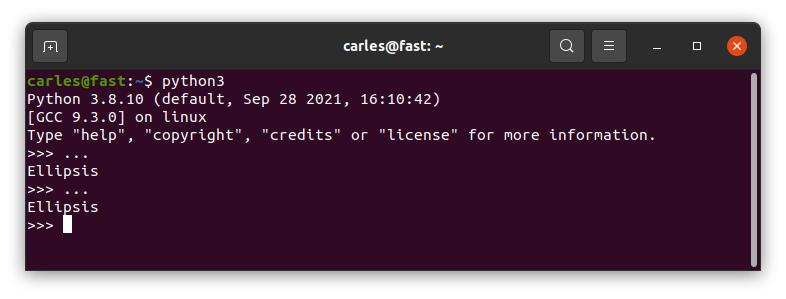
…Ellipsis
Today is Halloween and one of my colleagues asked me help to improve his Automation project.
I found something weird in his code.
He had something like that.
class Router:
def router_get_info(self):
...
def get_help_command(self):
return "help"
So I asked why you use … (dot dot dot) on that empty method?.
He told me that when he don’t want to implement code he just put that.
Well, dot dot dot is Ellipsis.
And what is Ellipsis?.
Ellipsis is an object that may appear in slice notation.
In Python all the methods, functions, if, while …. require to have an instruction at least.
So the instruction my colleague was looking for is pass.
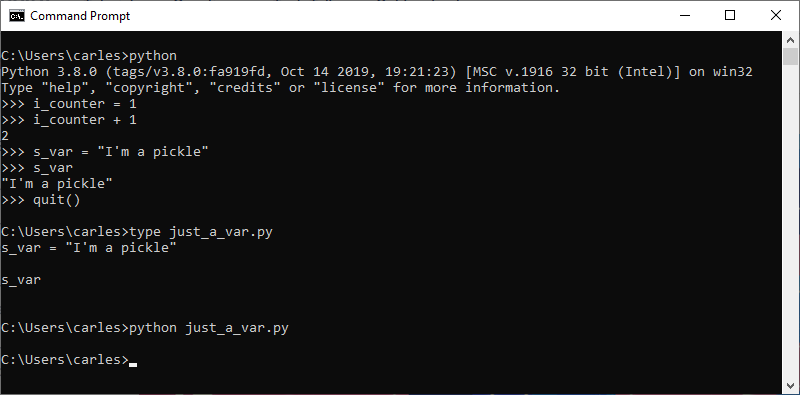
Just a variable?
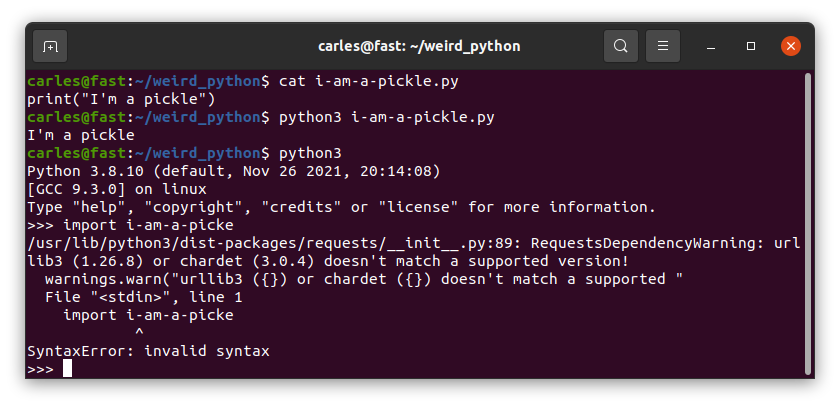
In Python you can have just a var, without anything else, like no operation with it, no call, nothing.
This makes it easy to commit an error and not detecting it.
As you see we can have just s_var variable in a line, which is a String, and this does not raises an error.
If we do from python interpreter interactively, it will print the String “I’m a pickle” (famous phrase from Rick and Morty).
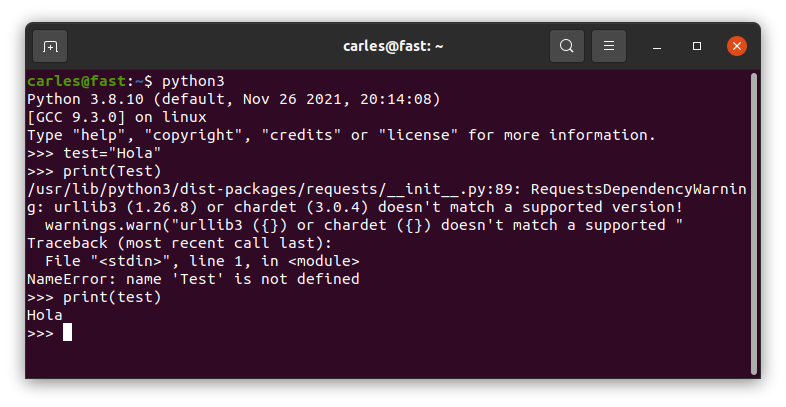
Variables are case sensitive
So you can define true false none … as they are different from True False None
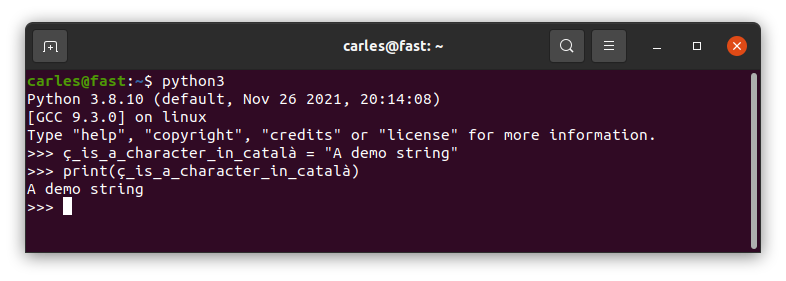
Variables in Unicode
Python3 accepts variables in Unicode.
I would completely discourage you to use variables with accents or other characters different from a-z 0-9 and _
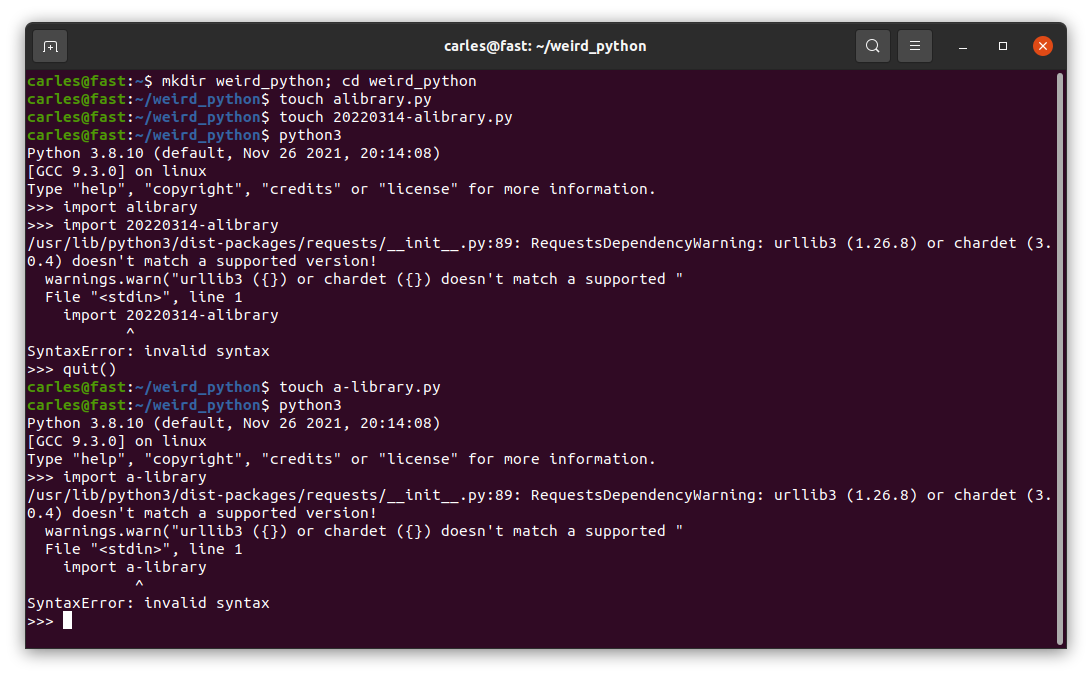
Python files with these names yes, but kaboom if you import them
So you can create Python files with dash or beginning with numbers, like 20220314_programming_class.py and execute them, but you cannot import them.
RYYFTK RODRIGUEZ,LEELA,FRY, FUTURAMA, 1999
A Tuple of a String is not a Tuple, it’s a String
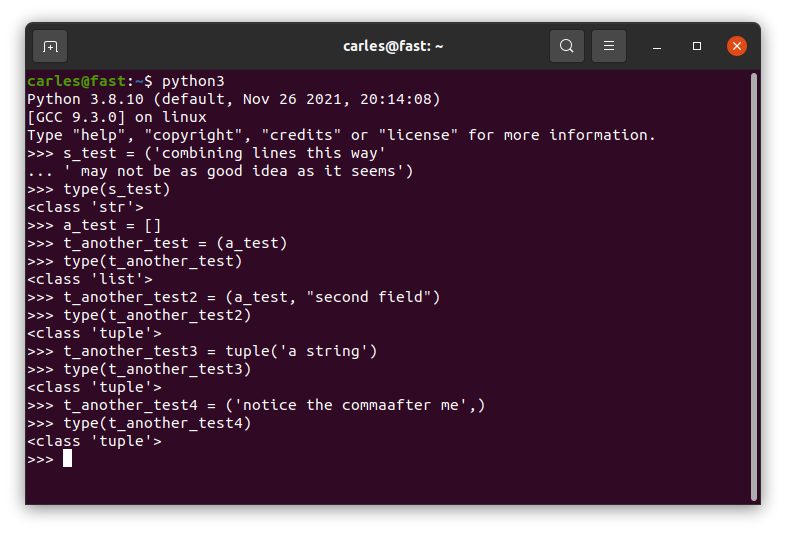
This can be very messy and confusing. Normally you define a tuple with parenthesis, although you can use tuple() too.
Parenthesis are the way we normally build tuples. But if we do:
print(type('this is a String'))
You get that this is a String, I mean
<class 'str'>
If you want to get a tuple of a String you can add a comma after the first String, which is weird. You can also do tuple("this is a String")
I think the definition of a tuple should be consistent and idempotent, no matter if you use one or more parameters. Probably as parenthesis are used for other tasks, like invoking functions or methods, or separating arithmetic operations, that reuse of the signs () for multiple purposes is what caused a different behavior depending on if there is one or more parameters the mayhem IMO.
See some example cases.
Python simplifies the jump of line \n platform independent and some times it’s messy
If you come from a C background you will expect text file in different platforms: Linux, Mac OS X (changes from old to new versions), Windows… to be represented different. In some cases this is an ASCii code 10 (LF), in others 13 (CR), and in other two characters: 13 and immediately after 10.
Python simplifies the Enter character by naming it \n like in C.
So, platform independent, whenever you read a text file you will get \n for any ASCii 10 [LF] or 13 [CR]. [CR] will be converted to [10] in Linux.
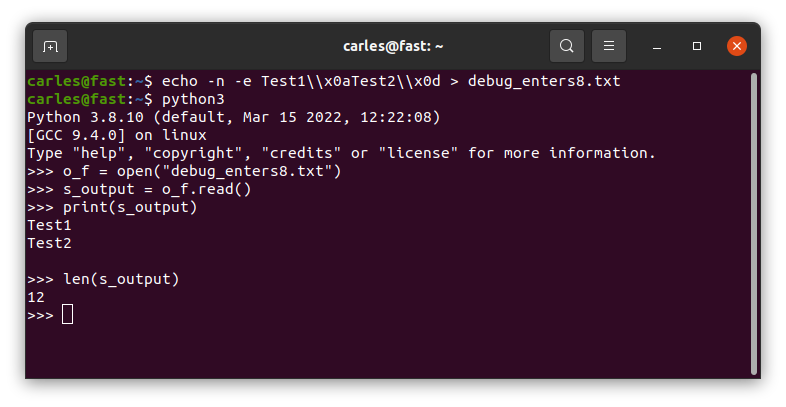
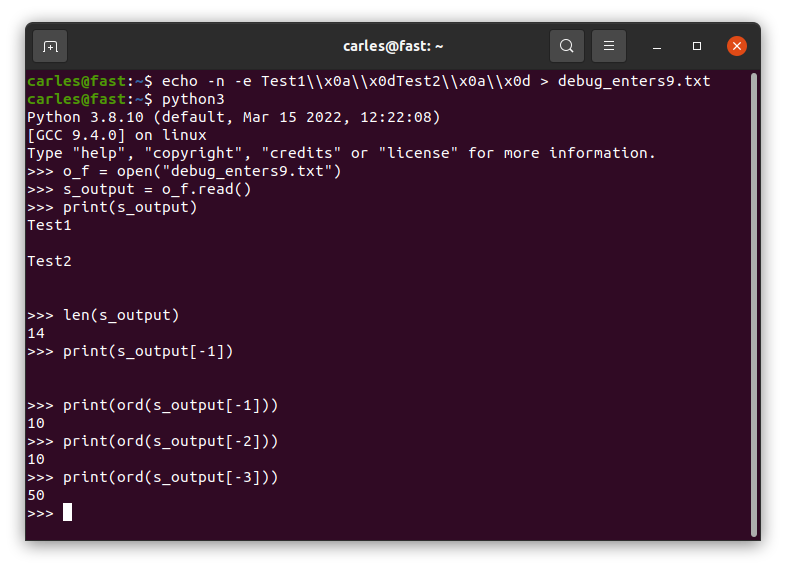
If you read a file in a Linux system, where enters are represented by 10, which was generated in a Windows system, so it has [CR][LF] instead of [LF] at the end of each line, you’ll get a \n too, but two times.
And if you do len(“\n”) to know the len of that String, this returns 1 in all the platform.
To read the [LF] and [CR] (represented by \r) you need to open the file as binary. By default Python opens the files as text.
You can check this by writting [LF] and [CR] in Linux and see how Python seamlessly reads the file as it was [LF].
A file generated by Windows will get \n\n:
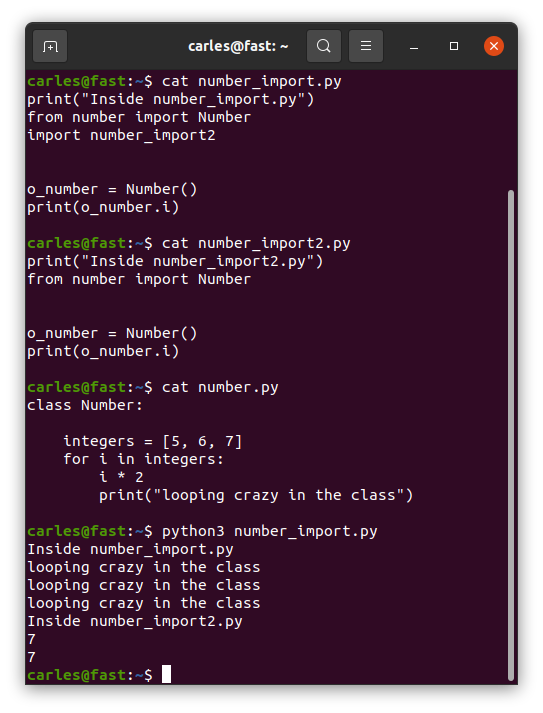
Random code when the class is imported
In a procedural file, the code that is outside a function, will be executed when it is imported. But if this file is imported again it will not be re-executed.
Things are more messy if you import a class file. Inside the body of the class, in the space you would reserve for static variables definition, you can have random code. And this code will be only executed on the first import, not on subsequent.
Disclaimer: the pictures from Futurama are from their respective owners.
If that fails is very probably that creating a new configuration, for a new user, will make things right.
Update 2022-01-05: Take in count that you will be copying the Windows registry when doing this. I use this trick to clone applications that are no longer downloadable from the Internet. I clone wine to dedicated Virtual Machines. You may need different Virtual Machines for different programs if windows registry is different for them.