cmemgzip Python tool to compress files in memory when there is no free space on the disk
Rationale
All the Operation Engineers and SREs that work with systems have found the situation of having a Server with the disk full of logs and needing to keep those logs, and at the same time needing the system to keep running.
This is an uncomfortable situation.
I remember when I was being interviewed in Facebook, in Menlo Park, for a SDM position in the SRE (Software Development Manager) back in 2013-2014. They asked me about a situation where they have the Server disk full, and they deleted a big log file from Apache, but the space didn’t come back. They told me that nobody ever was able to solve this.
I explained that what happened is that Apache still had the fd (file descriptor), and that he will try to write to end of that file, even if they removed the huge log file with rm command, from the system they will not get back any free space. I explained that the easiest solution was to stop apache. They agreed and asked me how we could do the same without restarting the Webserver and I said that manipulating the file descriptors under /proc. They told me what I was the first person to solve this.
How it works
Basically cmemgzip will read a file, as binary, and will load it completely in to Memory.
Then it will compress it also in Memory. Then it will release the memory used to keep the original, will validate write permissions on the folder, will check that the compressed file is smaller than the original, and will delete the original and, using the new space now available in disk, write the compressed and smaller version of the file in gzip format.
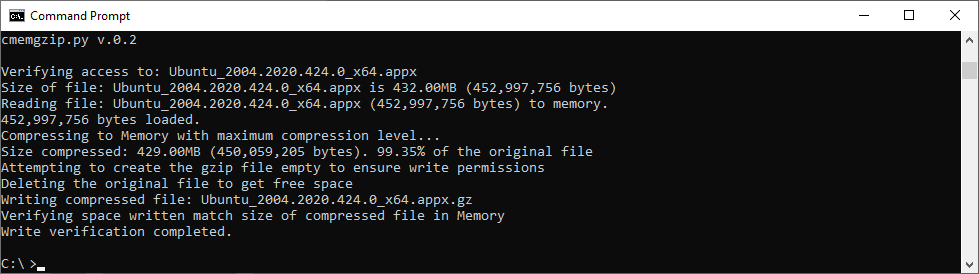
Since version 0.3 you can specify an amount of memory that you will use for the blocks of data read from the file, so you can limit greatly the memory usage and compress files much more bigger than the amount of memory.
If for whatever reason the gz version cannot be written to disk, you’ll be asked for another route.
I mentioned before about File Descriptors, and programs that may keep those files open.
So my advice here, is that if you have to compress Apache logs or logs from a multi-thread program, and disk is full, and several instances may be trying to write to the log file: to stop Apache service if you can, and then run cmemgzip. I want to add it the future to auto-release open fd, but this is delicate and requires a lot of time to make sure it will be reliable in all the circumstances and will obey the exact desires of the SRE realizing the operation, without unexpected undesired side effects. It can be implemented with a new parameter, so the SysAdmin will know what is requesting.
Get the source code
You can decompress it later with gzip/gunzip.
So about cmemgzip you can git clone the project from here:
https://gitlab.com/carles.mateo/cmemgzip
git clone https://gitlab.com/carles.mateo/cmemgzipThe README.md is very clear:
https://gitlab.com/carles.mateo/cmemgzip/-/blob/master/README.md
The program is written in Python 3, and I gave it License MIT, so you can use it and the Open Source really with Freedom.
Do you want to test in other platforms?
This is a version 0.3.
I have only tested it in:
- Ubuntu 20.04 LTS Linux for x64
- Ubuntu 20.04 LTS 64 bits under Raspberry Pi 4 (ARM Processors)
- Windows 10 Professional x64
- Mac OS X
- CentOS
It should work in all the platforms supporting Python, but if you want to contribute testing for other platforms, like Windows 32 bit, Solaris or BSD, let me know.
Alternative solutions
You can create a ramdisk and compress it to there. Then delete the original and move the compressed file from ramdisk to the hard drive, and unload the ramdrive Kernel Module. However we find very often with this problems in Docker containers or in instances that don’t have the Kernel module installed. Is much more easier to run cmemgzip.
Another strategy you can do for the future is to have a folder based on ZFS and compression. Again, ZFS should be installed on the system, and this doesn’t happen with Docker containers.
cmemgzip is designed to work when there is no free space, if there is free space, you should use gzip command.
In a real emergency when you don’t have enough RAM, neither disk space, neither the possibility to send the log files to another server to be compressed there, you could stop using the swap, and fdisk the swap partition to be a ext4 Linux format, format it, mount is, and use the space to compress the files. And after moving the files compressed to the original folder, fdisk the old swap partition to change type to Swap again, and enable swap again (swapon).
Memory requirements
As you can imagine, the weak point of cmemgzip, is that, if the file is completely loaded into memory and then compressed, the requirements of free memory on the Server/Instance/VM are at least the sum of the size of the file plus the sum of the size of the file compressed. You guess right. That’s true.
If there is not enough memory for loading the file in memory, the program is interrupted gracefully.
I decided to keep it simple, but this can be an option for the future.
So if your VM has 2GB of Available Memory, you will be able to use cmemgzip in uncompressed log files around 1.7GB.
In version 0.3 I implemented the ability to load chunks of the original file, and compress into memory, so I would be able use less memory. But then the compression is less efficient and initial tests point that I’ll have to keep a separate file for each compressed chunk. So I will need to created a uncompress tool as well, when now is completely compatible with gzip/gunzip, zcat, the file extractor from Ubuntu, etc…
For a big Server with a logfile of 40TB, around 300GB of RAM should be sufficient (the Servers I use have 768 GB of RAM normally).
Honestly, nowadays we find ourselves more frequently with VMs or Instances in the Cloud with small drives (10 to 15GB) and enough Available RAM, rather than Servers with huge mount points. This kind of instances, which means scaling horizontally, makes more difficult to have NFS Servers were we can move those logs, for security.
So cmemgzip covers very well some specific cases, while is not useful for all the scenarios.
I think it’s safe to say it covers 95% of the scenarios I’ve found in the past 7 years.
cmemgzip will not help you if you run out inodes.
Usage
Usage is very simple, and I kept it very verbose as the nature of the work is Operations, Engineers need to know what is going on.
I return error level/exit code 0 if everything goes well or 1 on errors.
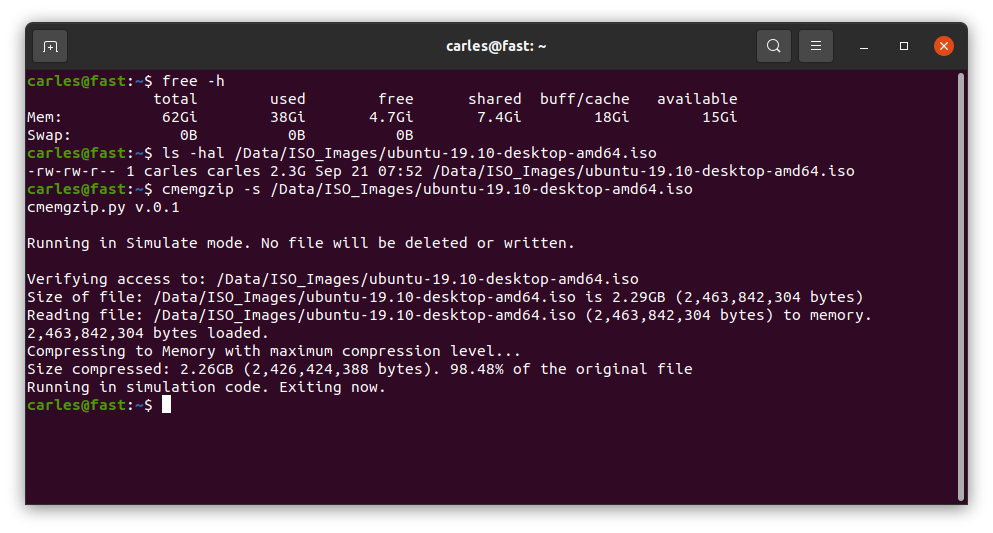
./cmemgzip.py /home/carles/test_extract/SherlockHolmes.txt cmemgzip.py v.0.1 Verifying access to: /home/carles/test_extract/SherlockHolmes.txt Size of file: /home/carles/test_extract/SherlockHolmes.txt is 553KB (567,291 bytes) Reading file: /home/carles/test_extract/SherlockHolmes.txt (567,291 bytes) to memory. 567,291 bytes loaded. Compressing to Memory with maximum compression level… Size compressed: 204KB (209,733 bytes). 36.97% of the original file Attempting to create the gzip file empty to ensure write permissions Deleting the original file to get free space Writing compressed file /home/carles/test_extract/SherlockHolmes.txt.gz Verifying space written match size of compressed file in Memory Write verification completed.
You can also simulate, without actually delete or write to disk, just in order to know what will be the
Installation
There are no third party libraries to install. I only use the standard ones: os, sys, gzip
So clone it with git in your preferred folder and just create a symbolic link with your favorite name:
sudo ln --symbolic /home/carles/code/cmemgzip/cmemgzip.py /usr/bin/cmemgzip
I like to create the link without the .py extension.
This way you can invoke the program from anywhere by just typing: cmemgzip
Rules for writing a Comment