We’re experiencing another digital breach.
The first one was between people not knowing about IT and those knowing, but we’re living another between IT guys being unable to Scale and those being able to Scale well.
Few years ago I was working all the time with Relational Databases. Designing cool relational Schemas for amazing projects. I had work for years with Oracle, Microsoft Sql Server, Informix, Dbase, Trees, Xml, and in the last times with PostgreSql and MySql.
I was doing a lot of improvements to MySql installations to allow Scaling and Scaling more, to bring more reliability, to improve performance, to allow more sessions… in definitive to fit the needs of the businesses in a challenging world that demanded more and more avility to handle more and more users.
Master Master, Master with secondaries for read, cluster of memcached or redis to use as cache, database sharding, Ip’s fail over, load balancers, additional indexes, InMemory engines, Ramdisks… everything that could help to match an increase on the load volumes.
I used commercial products like Code Futures dbshards, I created my own database sharding solution, in order to split the data to severl MySql servers, etc..
Artisan’s setup and a lot of studying and testing, everything to Scale to the needs of the companies, to handle more and more traffic, more and more users…
And I was proud of my level. Since I was able of suceed where few were able.
But now that is not needed anymore.
Basically the NoSql systems were born to deal with the actual problems.
NoSql servers -take in mind that the term comprises a lot of different solutions- were born to:
- Work in cluster
- Split the load among the cluster
- Work in cheap commodity servers (or small cloud instances)
- Resistance to failure: Allow the destruction of some nodes without data loss
- Work with nodes at distant-location datacenters
There are many different NoSql Softwares like: Cassandra, Hadoop, MongoDb, Riak, Neo4J, Redis…
And they do auto-sharding of the data, distribute the data across the network to fit the replication factor set, support load balancing, and in the case of Cassandra Scaling horizontally is so easy like adding more nodes to the Cassandra Cluster.
So yes, believe it. That’s why I write this article. So you can improve your projects and save tons of money.
Databases like Cassandra allow you to Scale so easily like adding new nodes. It is a peer to peer cluster with no single point of failure. All the nodes know the status of the other nodes and they distribute the load.
You can query all the time the same server, but it will be splitting the load among the other servers.
NoSql like hadoop allows you to create a large filesystem in cluster, with as-big-as-all-the-cluster files, but the best quality of HDFS is that it balances the load, and replicates the blocks of data among different servers, so if you loss nodes of the cluster and you have enough replication factor you’ll not loss data. I know companies in Barcelona with 500+ TB in HDFS and companies in the States with thousands of nodes.
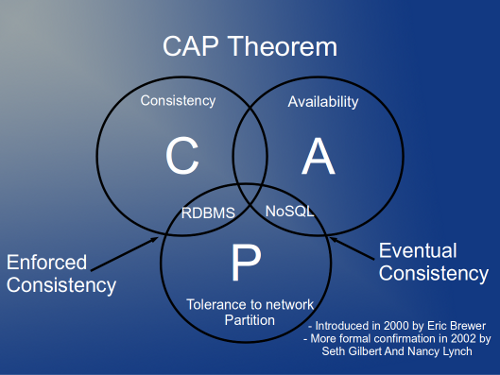
So unlike most people believes, NoSql is not about how the information is stored in the database: Schemaless. (* take a look at Graph NoSql databases for relations in NoSql)
NoSql has not an Schema in the traditional sense of Relational Databases, but it has aggregation, columns, supercolumns, or documents depending on the solution, and the design has impact on the performance, but the principal virtue of the NoSql systems is that they were born to work in cluster, to distribute the load, to be resilent to errors and to Scale.
I’ve seen many Startups suffering problems of overloaded MySql databases, but it happens that nothing of this will happen with NoSql like Cassandra, or MongoDb.
Before they were scaling vertically the MySql server, so adding more Ram, adding more CPU, having better disks, until it was impossible to upgrade more. And if sharding was not possible due to joins, the project was in serious trouble.
But with NoSql you can have, instead of an expensive very powerful server, 5 really cheap servers, and it could be faster, cheaper, resilent to errors, with a better uptime. And if you want to Scale simply add more cheap servers.
The most important of this article has been said, so you can start to look at NoSql solutions.
For bonus, I add a list of NoSql’s and the kind of Data Model that they have:
| Database name |
Type of data model |
Extra info |
Companies using it |
| Memcached |
Key-Value |
Storage is in Memory, so it is used mainly as cache |
Companies I’ve worked for: ECManaged, privalia.
Other well known companies:
LiveJournal, Wikipedia, Flickr, Bebo, Twitter, Typepad, Yellowbot, Youtube, Digg, WordPress.com, Craigslist, Mixi |
| Redis |
Key-Value |
Work in cluster. Can be used in memory or persistant |
Companies I’ve worked for: Atrapalo, ECManaged
Other well known companies: Twitter, Instagram, Github, Engine Yard, Craiglist, guardian.co.uk, blizzard, digg, flickr, stackoverflow, tweetdeck |
| Riak |
Key-Value |
Supports a REST API through HTTP and Protocol Buffers for basic PUT, GET, POST, and DELETE. MapReduce with native Javascript and Erlang. In multi-datacenter replication, one cluster acts as a “primary cluster”. |
AT&T, AOL, Ask.com, Best Buy, Boeing, Bump, Braintree, Comcast, DataPipe, Gilt Group, UK National Health Services (NHS), OpenX, Rovio, Symantec, TBS, The Weather Channel, WorkDay, Voxer, Yahoo! Japan, Yandex |
| BerkeleyDB |
Key-Value |
|
|
| LevelDB |
Key-Value |
|
|
| Project Voldemort |
Key-Value |
|
LinkedIn |
| Google BigTable |
Key-Value |
|
|
| Amazon DynamoDB |
Key-Value |
|
DynamoDB from Amazon, run in their AWS Cloud solution. See info on wikipedia |
|
| Cassandra |
Column-Family |
My favourite Db-alike. You can download my CQLSÍ wrapper for PHP :) |
NetFlix, Spotify, Facebok used it until 2010, Instagram, Rackspace, Rockyou, Zoho, Soundcloud, Hailo, ComCast, Hulu |
| HBase |
Column-Family |
Provides BigTable-like, SQL alike, support on the Hadoop core |
|
| Hypertable |
Column-Family |
|
|
| Amazon SimpleDB |
Column-Family |
|
|
|
| MongoDB |
Document Databases |
Written in C++, JSON-style documents, default stores to RAM until flush, high performance but dangerous for data integrity. Supports Map-Reduce |
|
| CouchDB |
Document Databases |
|
|
| OrientDb |
Document Databases |
|
|
| RavenDB |
Document Databases |
|
|
| Terrastore |
Document Databases |
(legacy) |
|
|
| Infinite Graph |
Graph Databases |
|
|
| HyperGraph DB |
Graph Databases |
|
|
| FlockDB |
Graph Databases |
|
|
| Neo4J |
Graph Databases |
|
|
| OrientDB |
Graph Databases |
|
|
Bonus for PHP Developers: A kind of lightweight key-value store very simple component useful for one-server PHP projects are: APC (datastore capability), and Cache Lite (part of PEAR).
I can’t miss to mention hadoop, that is a NoSql that does not match the categories of Data Storage up, because is a Framework for the distributed processing of large data sets across clusters, so a monster, being able to do many many things and to distribute loads across its nodes. The most well-known components are HDFS, the distributed filesystem, and Map-Reduce: a simple to develop YARN-based system for parallel processing of large data sets across the clusters. All the big companies like Netflix, Amazon, Yahoo, etc… are using Hadoop. Often synomym when talking about BigData.
Hadoop is a world itself, and the many projects surrounding, but is worth, because allow incredible possibilities to distribute loads and to Scale.
Hadoop has a single point of failure in the namenode, that stores the name of the files of the HDFS in RAM, but solutions like MapR have overcome this.
Don’t get me wrong. Relational databases are wonderful, very useful, support transactions, stored procedures, have been tested for years, focused on consistency, and are very reliable.
Simply they don’t allow to Scale according to our current needs, while NoSql opens a wonderful world of easy, nearly infinite, Scaling.
As you see Open Source is ruling the world. :)
Companies are still sleeping and not supporting NoSql. I’m particularly disappointed with Open Source CMS that are still based on Relational Models, and are very hard to Scale. Drupal, WordPress, Joomla… and e-Commerces like Magento, osCommerce… and plugins for the CMS mentioned (uberkart, woocommerce, virtuemart…) need to be ported to NoSql urgently. (Although some partial support exists in some solutions, it is not fully supported)
That’s why I’ve started to create a very simple Open Source CMS based on NoSql. To help companies and bloggers that can’t Scale more their sites.