I have read a lot of wrong recommendations about the use of Swap and Swappiness so I want to bring some light about it.
The first to say is that every project is different, so it is not possible to make a general rule. However in most of the cases we want systems to operate as fast and efficiently as possible.
So this suggestions try to covert 99% of the cases.
By default Linux will try to be as efficient as possible. So for example, it will use Free Memory to keep IO efficient by keeping in Memory cache and buffers.
That means that if you are using files often, Linux will keep that information cached in RAM.
The swappiness Kernel setting defines what tradeoff will take Linux between keeping buffers with Free Memory and using the available Swap Memory.
# sysctl vm.swappiness vm.swappiness = 60
The default value is 60 and more or less means that when RAM memory gets to 60%, swap will start to be used.
And so we can find Servers with 256GB of RAM, that when they start to use more than 153 GB of RAM, they start to swap.
Let’s analyze the output of free -h:
carles@vbi78g:~/Desktop/Software/checkswap$ free -h
total used free shared buff/cache available
Mem: 2.9Gi 1.6Gi 148Mi 77Mi 1.2Gi 1.1Gi
Swap: 2.0Gi 27Mi 2.0GiSo from this VM that has 2.9GB of RAM Memory, 1.6GB are used by applications.
The are 148MB that can immediately used by Applications, and there are 1.2GB in buffers/cache. Does that means that we can only use 148MB (plus swap)?. No, that mean that Linux tried to optimize io speed by keeping 1.2GB of RAM memory in buffers. But this is the best effort of Linux to have performance, for real applications will be also able to use 1.1GB that corresponds to the available field.
About swap, from 2GB, only 27MB have been used.
As vm.swappiness is set to 60, more RAM will be swapped out to swap, even if we have lots available.
As I said every case is different. If we are talking about a Desktop that has NVMe drives, the impact will be low. But if we are talking about a Server that is a hypervisor running VMs and has high usage on CPU and has the swap partition or the swap in a file, that could lead to huge problems. If there is a physical Server with a single spinning drive (or logical unit through RAID), and one partition is for Swap, and the other for mountpoints, and a process is heavily reading/writing to a partition mounted (an elastic search, or a telegraf, prometheus…), and the System tries to swap, then they will be competing for the magnetic head of disk, slowing down everything.
If you take a look on how the process of swapping memory pages from the memory to disk, you will understand that applications may need certain pages before being able to run, so in many cases we get to lock situations, that force everything to wait.
In my career I found Servers that temporarily stopped responding to ping. After a while ping came back, I was able to ssh and uptime showed that the Server did not reboot.
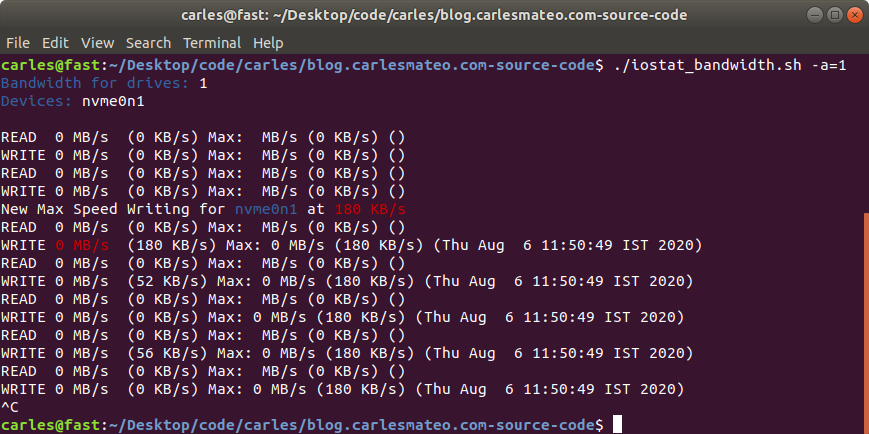
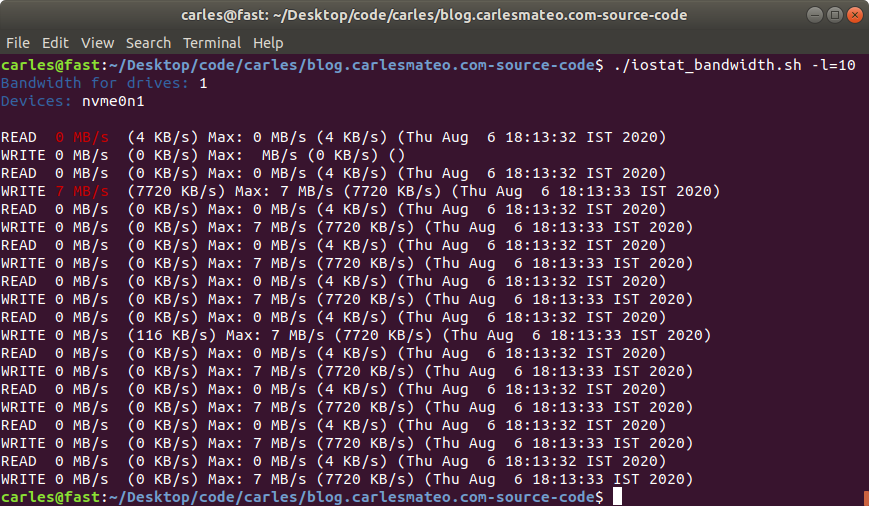
I troubleshooted that, and I saw a combination of high CPU usage spikes and Swap usage.
Using iostat and iotop I monitored what was speed of transference of only 1 MB/second!!.
I even did swapoff and it took one hour to free 4 GB swap partition!.
I also saw swap partition being in a spinning disk, and in another partition of the same spinning drive, having a swapfile. Magnetic spinning drives can only access one are of the drive at the same time, so that situation, using swap is very bad.
And I have seen situations were the swap or swapfile was mounted in a block device shared via network with the Server (like iSCSI or NFS), causing terrible performance when swapping.
So you have to adapt the strategy according to the project.
My preferred strategy for Compute Nodes and NoSQL Databases is to not use swap at all. In other cases, like MySQL Databases I may set swappiness to preferably to 1 or to 10.
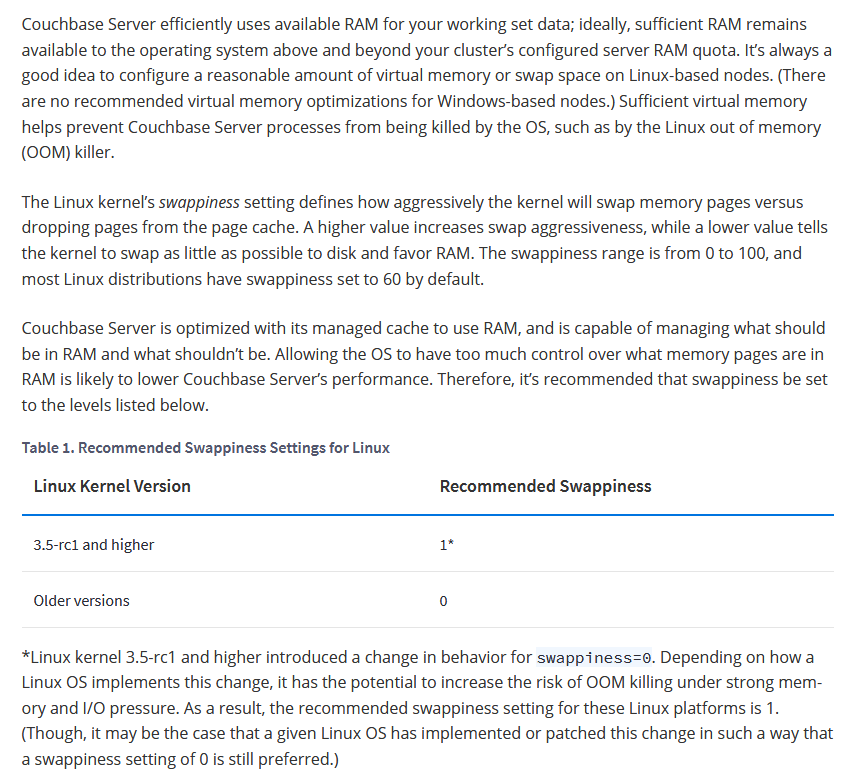
I quote here the recommendations from couchbase docs:
The Linux kernel’s swappiness setting defines how aggressively the kernel will swap memory pages versus dropping pages from the page cache. A higher value increases swap aggressiveness, while a lower value tells the kernel to swap as little as possible to disk and favor RAM. The swappiness range is from 0 to 100, and most Linux distributions have swappiness set to 60 by default.
Couchbase Server is optimized with its managed cache to use RAM, and is capable of managing what should be in RAM and what shouldn’t be. Allowing the OS to have too much control over what memory pages are in RAM is likely to lower Couchbase Server’s performance. Therefore, it’s recommended that swappiness be set to the levels listed below.
https://docs.couchbase.com/server/current/install/install-swap-space.html
Another theme, is when you log to a Server and you see all the Swap memory in use.
Linux may have moved the pages that were less used, and that may be Ok for some cases, for example a Cron Service that waits and runs every 24 hours. It is safe to swap that (as long as the swap IO is decent).
When Kernel Swaps it may generate locks.
But if we log to a Server and all the Swap is in use, how can we know that the Swap has been quiet there?.
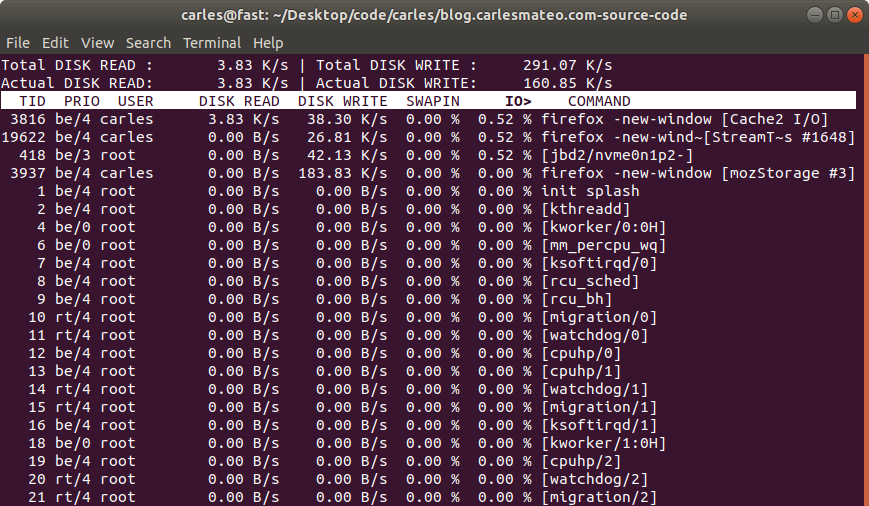
Well, you can use iostat or iotop or you can:
cat /proc/vmstatThis file contains a lot of values related to Memory, we will focus on:
pswpin 508992338 pswpout 280871088
In https://superuser.com/questions/785447/what-is-the-exact-difference-between-the-parameters-pgpgin-pswpin-and-pswpou you can find very interesting description of those values. I paste here an excerpt:
Paging refers to writing portions, termed pages, of a process’ memory to disk.
Swapping, strictly speaking, refers to writing the entire process, not just part, to disk.
In Linux, true swapping is exceedingly rare, but the terms paging and swapping often are used interchangeably.
page-out: The system’s free memory is less than a threshold “lotsfree” and unnused / least used pages are moved to the swap area.
page-in: One process which is running requested for a page that is not in the current memory (page-fault), it’s pages are being brought back to memory.
swap-out: System is thrashing and has deactivated a process and it’s memory pages are moved into the swap area.
swap-in: A deactivated process is back to work and it’s pages are being brought into the memory.
Values from /proc/vmstat:
pgpgin, pgpgout – number of pages that are read from disk and written to memory, you usually don’t need to care that much about these numbers
pswpin, pswpout – you may want to track these numbers per time (via some monitoring like prometheus), if there are spikes it means system is heavily swapping and you have a problem.
In this actual example that means that since the start of the Server there has been 508992338 Page Swap In (with 4K memory pages this is 1,941 GB, so almost 2 TB transferred) and for Page Swat Out (with 4K memory pages this is 1,071 GB, so 1 TB of transferred). I’m talking about a Server that had a 4GB swap partition in a spinning disk and a 12 GB swapfile in another ext4 partition of the same spinning disk.
The 16 GB of swap were in use and iotop showed only two sources of IO, one being 2 VMs writing, another was a journaling process writing to the mountpoint where the swapfile was. That was an spinning drive (underlying hardware was raid, for simplicity I refer to one single drive. I checked that both spinning drives were healthy and fast). I saw small variations in the size of the Swap, so I decided to monitor the changes in pswpin and pswpout in /proc/vmstat to see how much was transferred from/to swap.
I saw then how many pages were being transferred!.
I wrote a small Python program to track those changes:
https://gitlab.com/carles.mateo/checkswap
This little program works in Python 2 and Python 3, and will show the evolution of pswpin and pswpout in /proc/vmstat and will offer the average for last 5 minutes and keep the max value detected as well.
As those values show the page swaps since the start of the Server, my little program, makes the adjustments to show the Page Swaps per second.
A cheap way to reproduce collapse by using swap is using VirtualBox: install an Ubuntu 20.04 LTS in there, with 2 GB of less of memory, and one single core. Ping that VM from elsewhere.
Then you may run a little program like this in order to force it to swap:
#!/usr/bin/env python3
a_items = []
i_total = 0
# Add zeros if your VM has more memory
for i in range(0, 10000000):
i_total = i_total + i
a_items.append(i_total)And checkswap will show you the spikes:
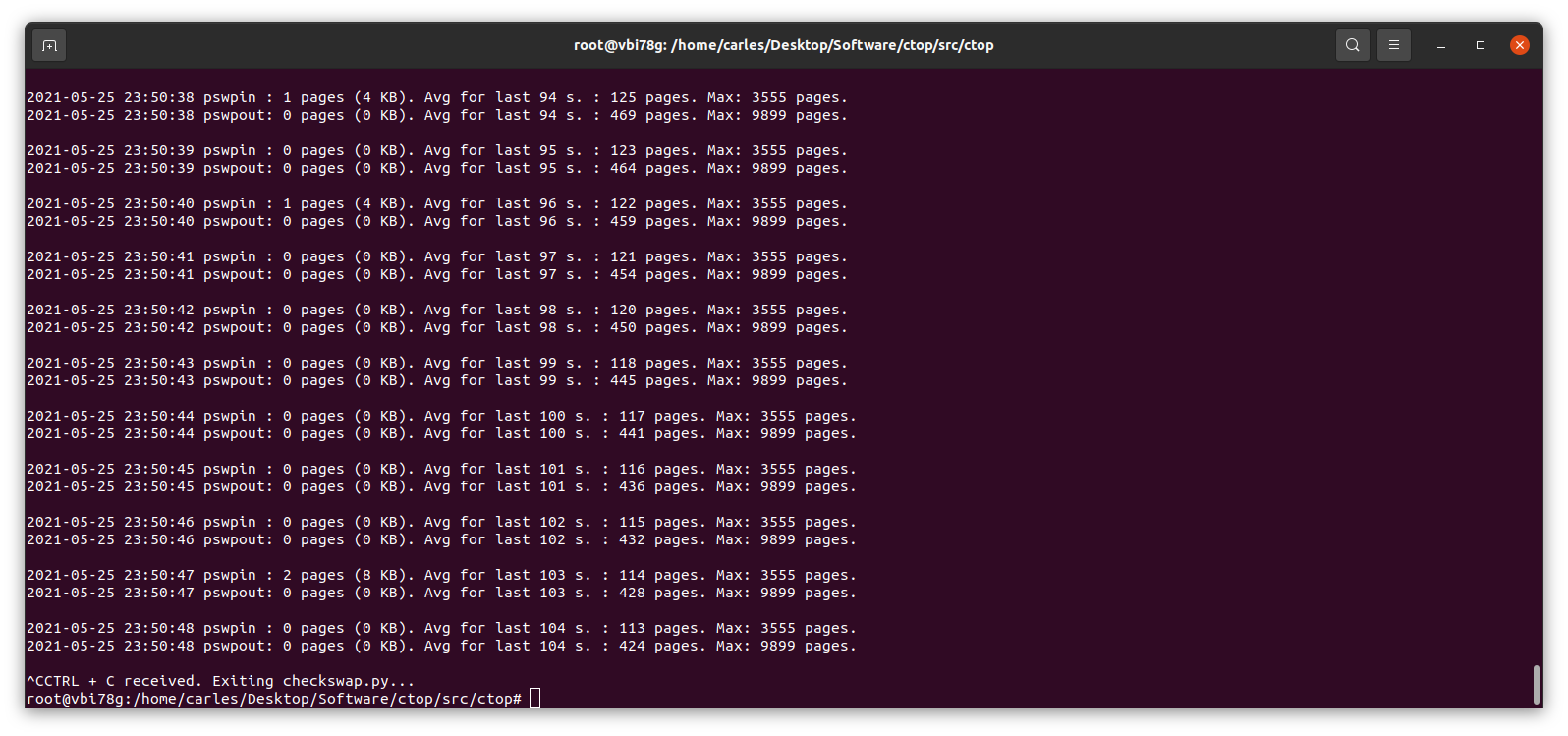
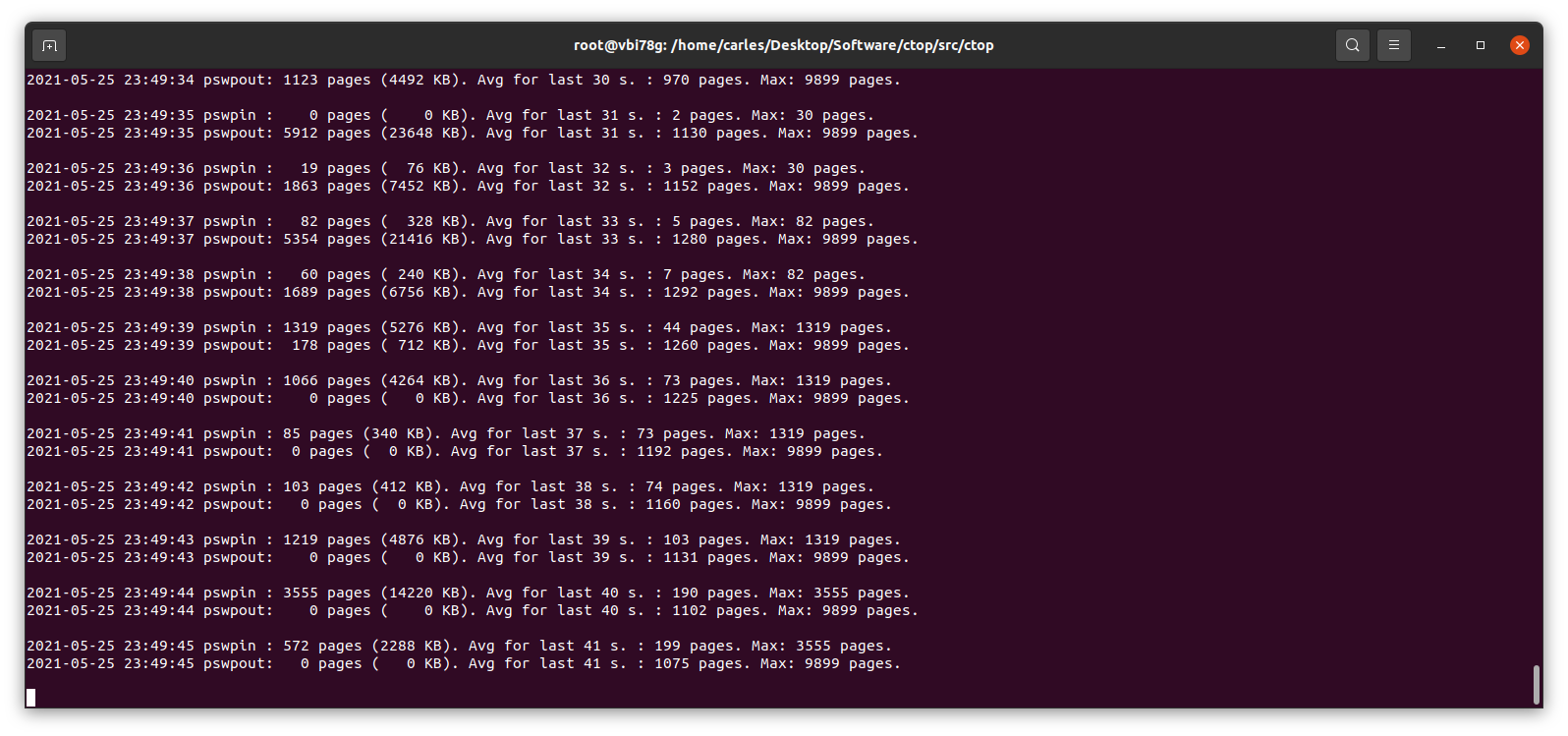
Many voices are discordant. Some say swappiness default value of 60 is good, as Linux will use the RAM memory to optimize the IO. In my experience, I’ve seen Hypervisors Servers running Virtual Machines that fit on the available physical RAM and were doing pure CPU calculations, no IO, and the Hypervisor was swapping just because it had swappiness to 60. Also having swap on spinning drives, mixing swap partition and swapfile, and that slowing down everything. In a case like that it would be much better not using Swap at all.
In most cases the price of Swapping to disk is much more higher than the advantage than a buffer for IO brings. And in the case of a swapfile, well, it’s also a file, so my suspect is that the swapfile is also buffered. Nothing I recommend, honestly.
My program https://gitlab.com/carles.mateo/checkswap may help you to demonstrate how much damage the swapping is doing in terms of IO. Combine it with iostat and iotop --only to see how much bandwidth is wasted writing and reading from/to swap.
You may run checkswap from a screen session and launch it with tee so results are logged. For example:
python3 checkswap.py | tee 2021-05-27-2107-checkswap.logIf you want to automatically add the datetime you can use:
python3 checkswap.py | tee `date +%Y-%m-%d-%H%M`-checkswap.log
Press CTRL + a and then d, in order to leave the screen session and return to regular Bash.
Type screen -r to resume your session if this was the only screen session running in background.
An interesting reflection from help Ubuntu:
The “diminishing returns” means that if you need more swap space than twice your RAM size, you’d better add more RAM as Hard Disk Drive (HDD) access is about 10³ slower then RAM access, so something that would take 1 second, suddenly takes more then 15 minutes! And still more then a minute on a fast Solid State Drive (SSD)…
https://help.ubuntu.com/community/SwapFaq
Do you have a swap history that you want to share?.