Many times it could be very convenient to have a compressed filesystem, so a system that compresses data in Real Time.
This not only reduces the space used, but increases the IO performance. Or better explained, if you have to write to disk 1GB log file, and it takes 5 seconds, you have a 200MB/s performance. But if you have to write 1GB file, and it takes 0.5 seconds you have 2000MB/s or 2GB/s. However the trick in here is that you really only wrote 100MB, cause the Data was compressed before being written to the disk.
This also works for reading. 100MB are Read, from Disk, and then uncompressed in the memory (using chunks, not everything is loaded at once), assuming same speed for Reading and Writing (that’s usual for sequential access on SAS drives) we have been reading from disk for 0.5 seconds instead of 5. Let’s imagine we have 0.2 seconds of CPU time, used for decompressing. That’s it: 0.7 seconds versus 5 seconds.
So assuming you have installed ZFS in your Desktop computer those instructions will allow you to create a ZFS filesystem, compressed, and mount it.
ZFS can create pools using disks, partitions or other block devices, like regular files or loop devices.
# Create the File that will hold the Filesystem, 1GB
root@xeon:/home/carles# dd if=/dev/zero of=/home/carles/compressedfile.000 bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.621923 s, 1.7 GB/s
# Create the pool
zpool create compressedpool /home/carles/compressedfile.000
# See the result
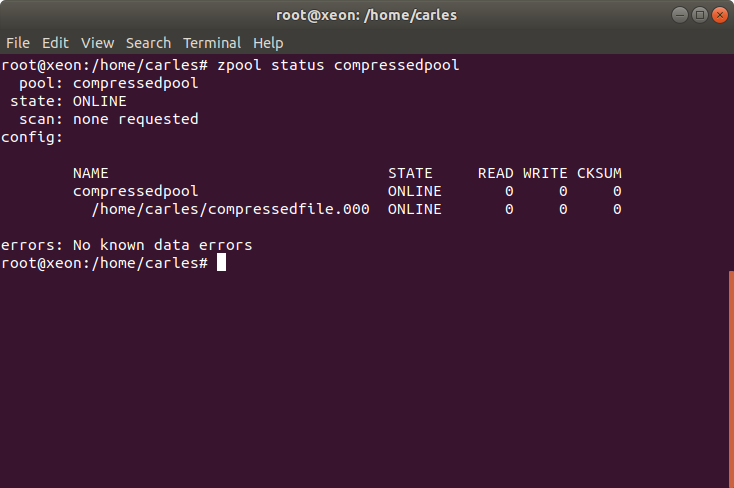
# If you don’t have automount set, then set the mountpoint
zpool set compressedpool mountpoint=/compressedpool
# Set the compression. LZ4 is fast and well balanced
zfs set compression=lz4 compressedpool
# Push some very compressible 1GB file. Don’t use just 0s as this is optimized :)
# Myself I copied real logs
ls -al --block-size=M *.log
-rw------- 1 carles carles 1329M Sep 26 14:34 messages.log
root@xeon:/home/carles# cp messages.log /compressedpool/
Even if the pool only had 1GB we managed to copy 1.33 GB file.
Then we check and only 142MB are being used for real, thanks to the compression.
root@xeon:/home/carles# zfs list
NAME USED AVAIL REFER MOUNTPOINT
compressedpool 142M 738M 141M /compressedpool
root@xeon:/home/carles# df /compressedpool
Filesystem 1K-blocks Used Available Use% Mounted on
compressedpool 899584 144000 755584 17% /compressedpool
By default ZFS will only import the pools that are based on drives, so in order to import your pool based on files after you reboot or did zfs export compressedpool, you must specify the directory:
zpool import -d /home/carles compressedpool
You can also create a pool using several files from different hard drives. That way you can create mirror, RAIDZ1, RAIDZ2 or RAIDZ3 and not losing any data in that pool based on drives in case you loss a physical drive.
If you use one file in several hard drive, you are aggregating the bandwidth.
You can also do this in your instances or VMs. Create one file of 1GB and creating the pool for compressed logs or compressed core dumps. If later you need more space you can add another file to he pool. You don’t need to use any redundancy, just creating a pool with mountpoint /var/log or /var/core and grow as you need.
Logs and core dumps can be greatly compressed, for example a core dump of 54MB will be around 645KB if you compress it using a tool like bzip2. Using the compression from ZFS, you can choose different algorithms of compression, so expect a massive reduction of space and huge space savings for logs and core dumps.