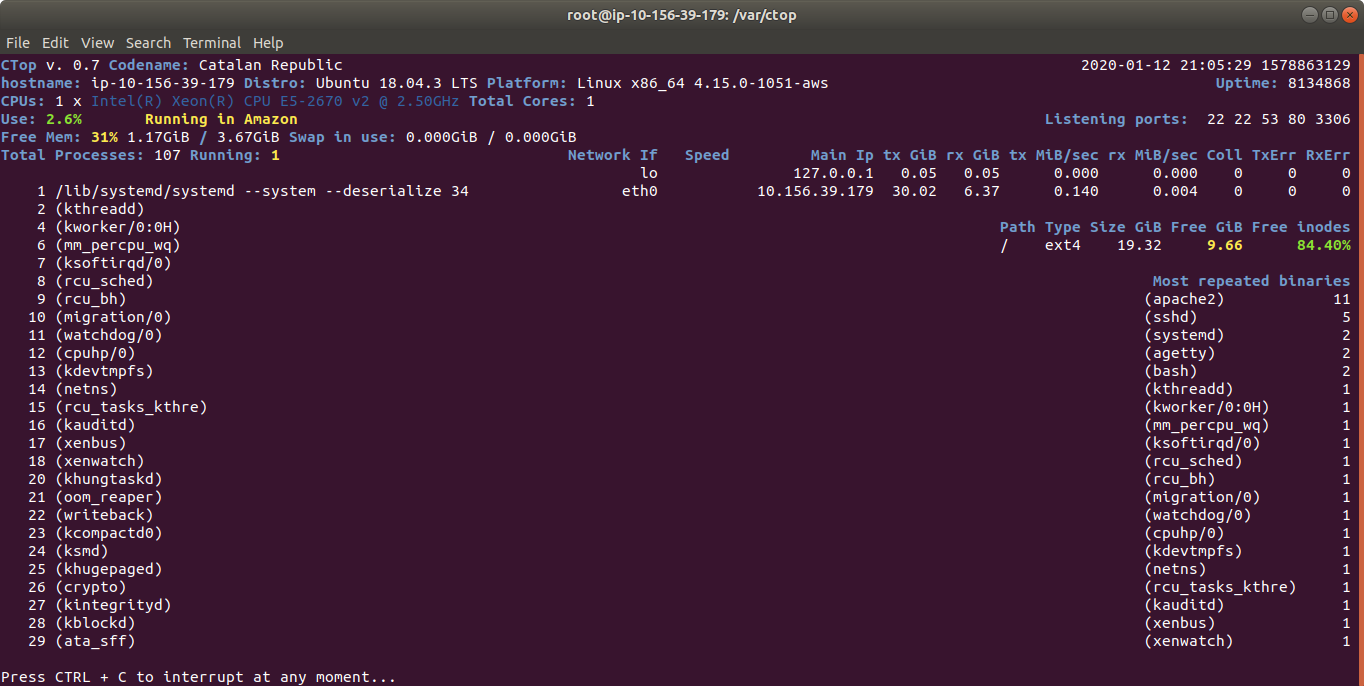
So this is a super simple example on how quickly you can create nice solutions with my package carleslibs.
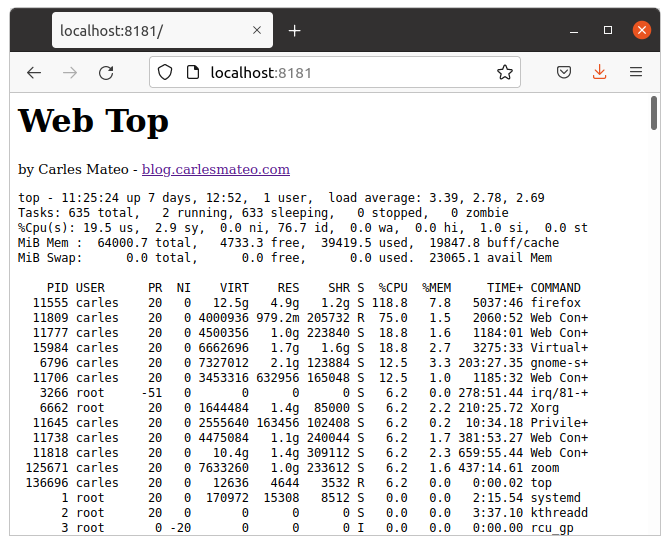
In this example I use Python 3 incorporated Web Server and carleslibs, to execute top and display in the browser.
Requisites:
Having Python3 and have installed carleslibs 1.0.1 or superior.
pip3 install carleslibs
Having this running in a Linux with top installed. All of them come with top, as long as I know.
This is the 84 lines code for WebTop:
from http.server import BaseHTTPRequestHandler, HTTPServer
from carleslibs.subprocessutils import SubProcessUtils
from carleslibs.datetimeutils import DateTimeUtils
class Top():
def __init__(self, o_subprocess):
self.o_subprocess = o_subprocess
def get_top(self):
a_domains_offline = []
s_command = "/usr/bin/top -n 1 -b"
i_code, s_stdout, s_stderr = self.o_subprocess.execute_command_for_output(s_command, b_shell=True, b_convert_to_ascii=True)
return i_code, s_stdout, s_stderr
class WebServer(BaseHTTPRequestHandler):
def do_GET(self):
o_subprocess = SubProcessUtils()
self.o_top = Top(o_subprocess)
self.o_datetime = DateTimeUtils()
self.i_max_domains_offline = 0
self.send_response(200)
self.send_header("Content-type", "text/html")
self.end_headers()
WebTop.log(self.path)
if self.path == "/favicon.ico":
return
s_html = "<html><body>"
s_html = s_html + "<h1>Web Top</h1>"
s_html = s_html + '<small>by Carles Mateo - <a href="https://blog.carlesmateo.com">blog.carlesmateo.com</a></small>'
i_code, s_stdout, s_stderr = self.o_top.get_top()
if i_code != 0:
s_html = s_html + "Error Code: " + str(i_code) + "</br>"
s_html = s_html + "Message: " + s_stderr + "</br>"
else:
s_html = s_html + "<pre>"
s_html = s_html + s_stdout
s_html = s_html + "</pre>"
s_html = s_html + "</body>"
s_html = s_html + "</html>"
by_html = bytes(s_html, encoding="utf-8")
self.wfile.write(by_html)
class WebTop():
o_datetime = DateTimeUtils()
@staticmethod
def log(s_text):
s_datetime = WebTop.o_datetime.get_datetime()
print(s_datetime, s_text)
if __name__ == "__main__":
o_webserver = HTTPServer(("localhost", 80), WebServer)
WebTop.log("Server started")
try:
o_webserver.serve_forever()
except KeyboardInterrupt:
pass
o_webserver.server_close()
WebTop.log("Server stopped")
Just run the code and go to localhost with your favorite browser.
If you get an error like this it means that another process is listening on port 80. Just use another like 8080, 8181, etc…
Traceback (most recent call last):
File "/home/carles/Desktop/code/carles/json-realm-live/web_top.py", line 74, in <module>
o_webserver = HTTPServer(("localhost", 80), WebServer)
File "/usr/lib/python3.8/socketserver.py", line 452, in __init__
self.server_bind()
File "/usr/lib/python3.8/http/server.py", line 138, in server_bind
socketserver.TCPServer.server_bind(self)
File "/usr/lib/python3.8/socketserver.py", line 466, in server_bind
self.socket.bind(self.server_address)
PermissionError: [Errno 13] Permission denied
And you will see the requests coming:
2021-10-09 10:47:46 Server started 127.0.0.1 - - [13/Oct/2021 10:47:48] "GET / HTTP/1.1" 200 - 2021-10-09 10:47:48 / 127.0.0.1 - - [13/Oct/2021 11:25:24] "GET / HTTP/1.1" 200 - 2021-10-09 11:25:24 /
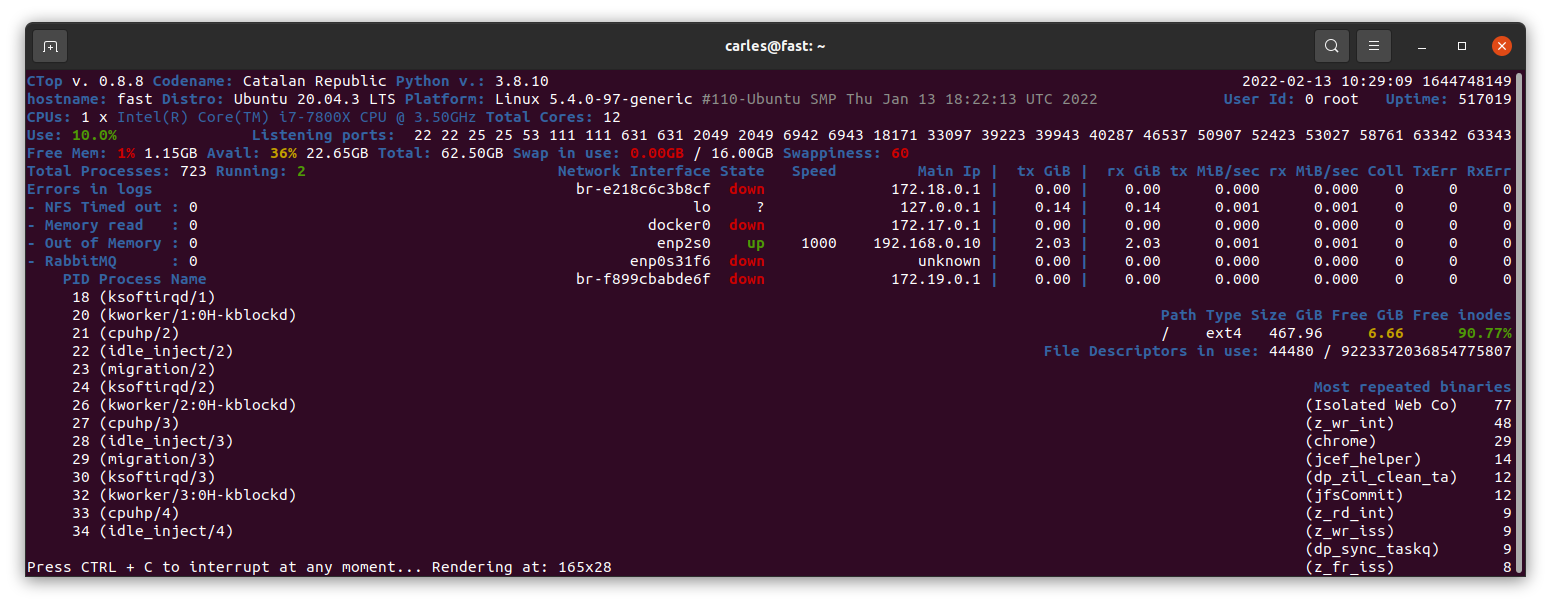
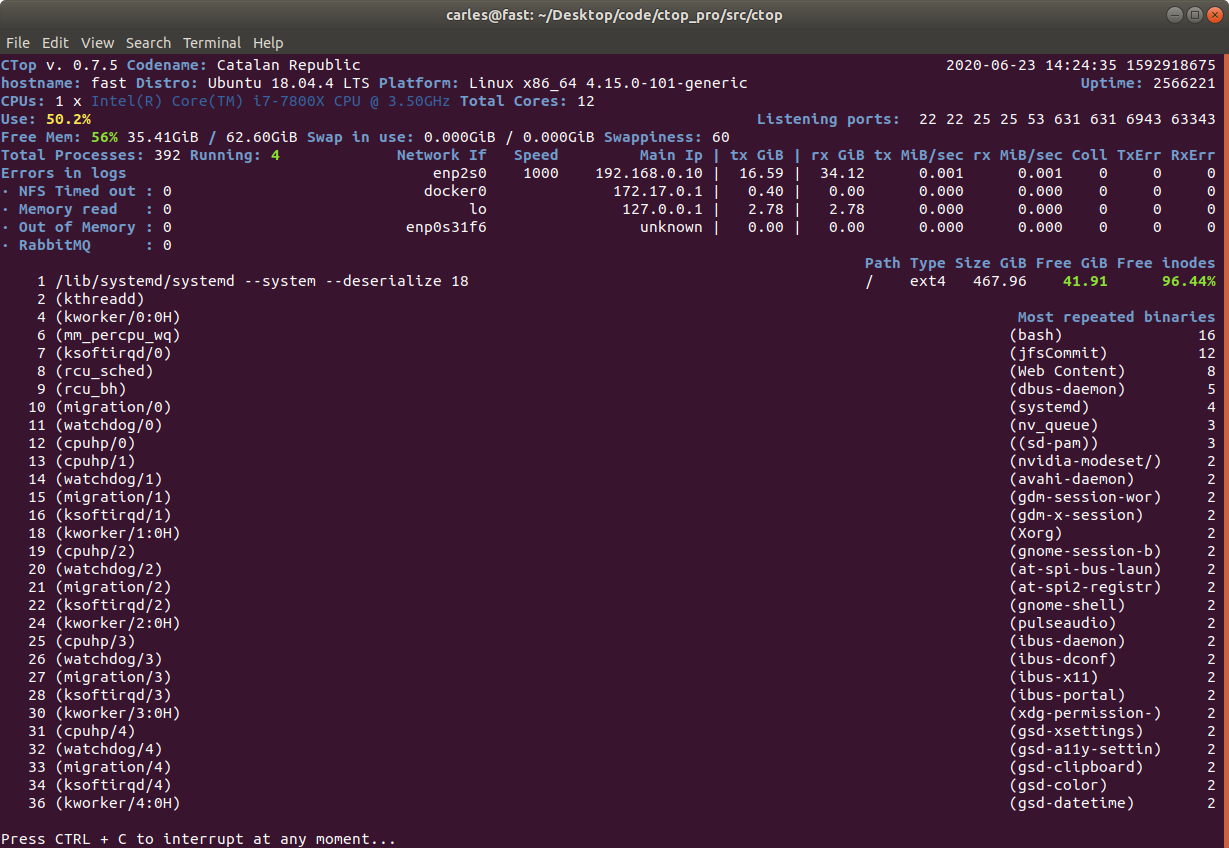
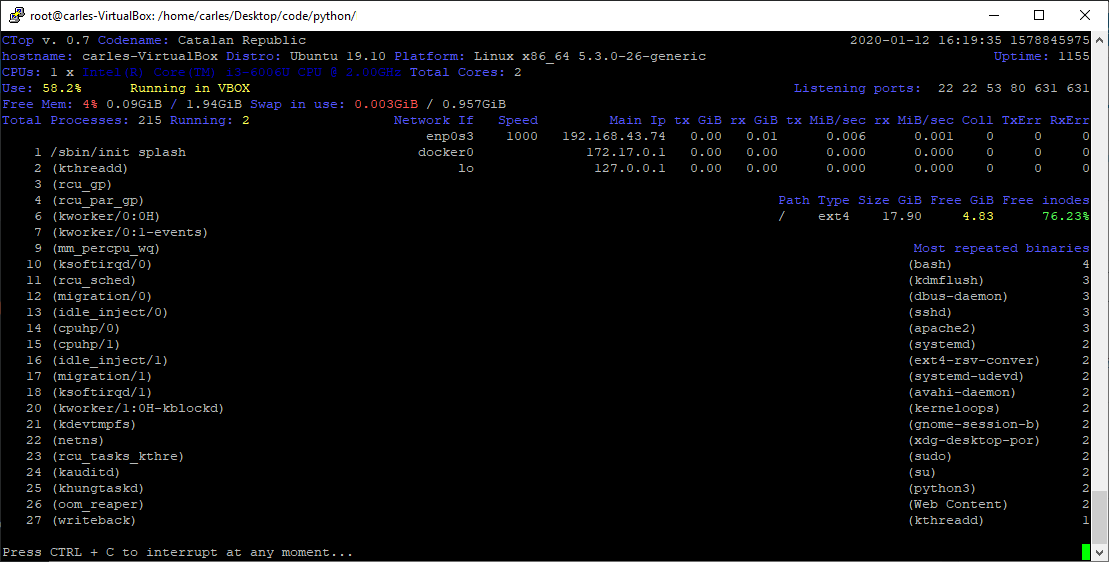
So instead of using top, you can use ctop.py :)
Just replace the command by:
s_command = "ctop.py -b -n=1 --rows=30 --columns=200"
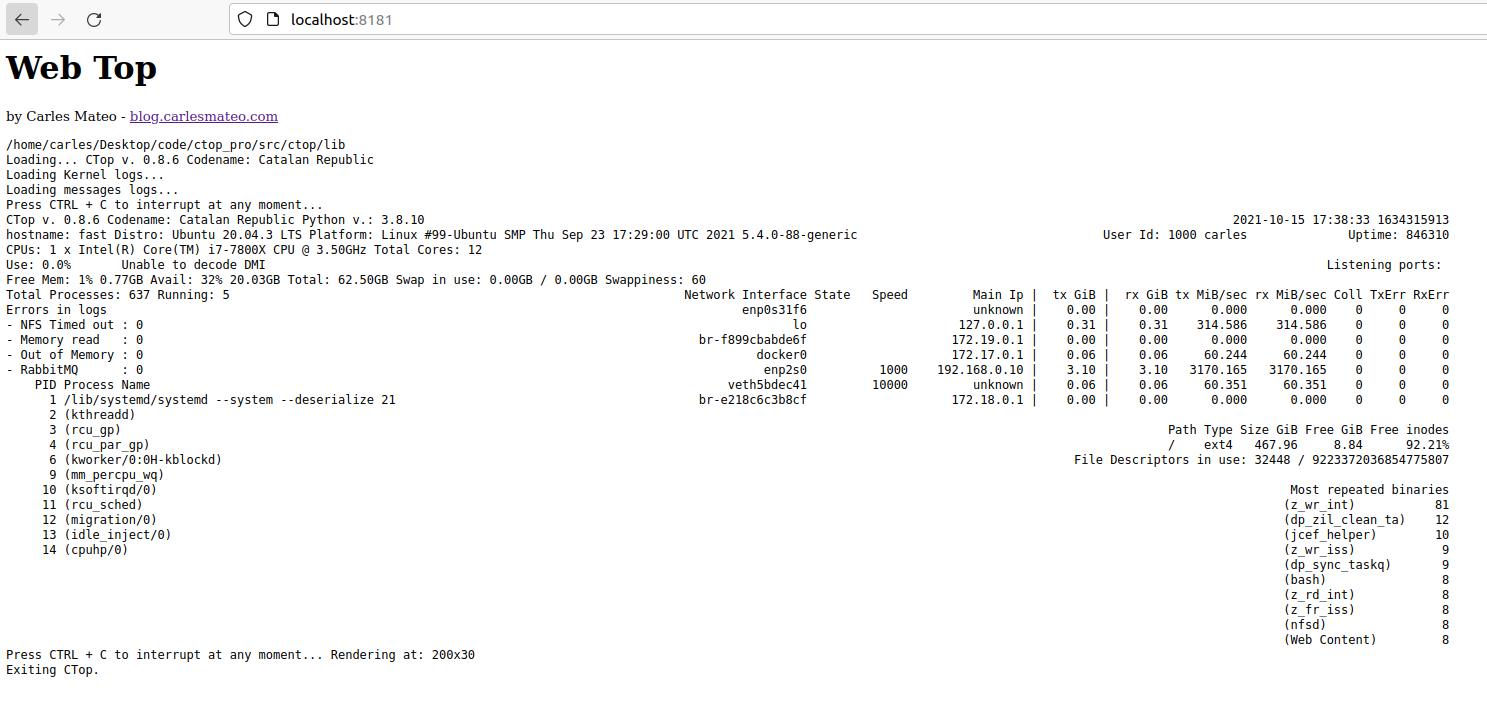
You can also create a Dockerfile very easily and run this in a Container.