All the Operation Engineers and SREs that work with systems have found the situation of having a Server with the disk full of logs and needing to keep those logs, and at the same time needing the system to keep running.
This is an uncomfortable situation.
I remember when I was being interviewed in Facebook, in Menlo Park, for a SDM position in the SRE (Software Development Manager) back in 2013-2014. They asked me about a situation where they have the Server disk full, and they deleted a big log file from Apache, but the space didn’t come back. They told me that nobody ever was able to solve this.
I explained that what happened is that Apache still had the fd (file descriptor), and that he will try to write to end of that file, even if they removed the huge log file with rm command, from the system they will not get back any free space. I explained that the easiest solution was to stop apache. They agreed and asked me how we could do the same without restarting the Webserver and I said that manipulating the file descriptors under /proc. They told me what I was the first person to solve this.
How it works
Basically cmemgzip will read a file, as binary, and will load it completely in to Memory.
Then it will compress it also in Memory. Then it will release the memory used to keep the original, will validate write permissions on the folder, will check that the compressed file is smaller than the original, and will delete the original and, using the new space now available in disk, write the compressed and smaller version of the file in gzip format.
Since version 0.3 you can specify an amount of memory that you will use for the blocks of data read from the file, so you can limit greatly the memory usage and compress files much more bigger than the amount of memory.
If for whatever reason the gz version cannot be written to disk, you’ll be asked for another route.
I mentioned before about File Descriptors, and programs that may keep those files open.
So my advice here, is that if you have to compress Apache logs or logs from a multi-thread program, and disk is full, and several instances may be trying to write to the log file: to stop Apache service if you can, and then run cmemgzip. I want to add it the future to auto-release open fd, but this is delicate and requires a lot of time to make sure it will be reliable in all the circumstances and will obey the exact desires of the SRE realizing the operation, without unexpected undesired side effects. It can be implemented with a new parameter, so the SysAdmin will know what is requesting.
Get the source code
You can decompress it later with gzip/gunzip.
So about cmemgzip you can git clone the project from here:
The program is written in Python 3, and I gave it License MIT, so you can use it and the Open Source really with Freedom.
Do you want to test in other platforms?
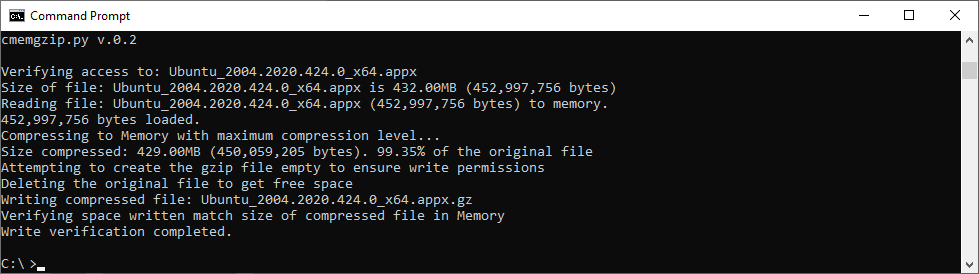
This is a version 0.3.
I have only tested it in:
Ubuntu 20.04 LTS Linux for x64
Ubuntu 20.04 LTS 64 bits under Raspberry Pi 4 (ARM Processors)
Windows 10 Professional x64
Mac OS X
CentOS
It should work in all the platforms supporting Python, but if you want to contribute testing for other platforms, like Windows 32 bit, Solaris or BSD, let me know.
Alternative solutions
You can create a ramdisk and compress it to there. Then delete the original and move the compressed file from ramdisk to the hard drive, and unload the ramdrive Kernel Module. However we find very often with this problems in Docker containers or in instances that don’t have the Kernel module installed. Is much more easier to run cmemgzip.
Another strategy you can do for the future is to have a folder based on ZFS and compression. Again, ZFS should be installed on the system, and this doesn’t happen with Docker containers.
cmemgzip is designed to work when there is no free space, if there is free space, you should use gzip command.
In a real emergency when you don’t have enough RAM, neither disk space, neither the possibility to send the log files to another server to be compressed there, you could stop using the swap, and fdisk the swap partition to be a ext4 Linux format, format it, mount is, and use the space to compress the files. And after moving the files compressed to the original folder, fdisk the old swap partition to change type to Swap again, and enable swap again (swapon).
Memory requirements
As you can imagine, the weak point of cmemgzip, is that, if the file is completely loaded into memory and then compressed, the requirements of free memory on the Server/Instance/VM are at least the sum of the size of the file plus the sum of the size of the file compressed. You guess right. That’s true.
If there is not enough memory for loading the file in memory, the program is interrupted gracefully.
I decided to keep it simple, but this can be an option for the future.
So if your VM has 2GB of Available Memory, you will be able to use cmemgzip in uncompressed log files around 1.7GB.
In version 0.3 I implemented the ability to load chunks of the original file, and compress into memory, so I would be able use less memory. But then the compression is less efficient and initial tests point that I’ll have to keep a separate file for each compressed chunk. So I will need to created a uncompress tool as well, when now is completely compatible with gzip/gunzip, zcat, the file extractor from Ubuntu, etc…
For a big Server with a logfile of 40TB, around 300GB of RAM should be sufficient (the Servers I use have 768 GB of RAM normally).
Honestly, nowadays we find ourselves more frequently with VMs or Instances in the Cloud with small drives (10 to 15GB) and enough Available RAM, rather than Servers with huge mount points. This kind of instances, which means scaling horizontally, makes more difficult to have NFS Servers were we can move those logs, for security.
So cmemgzip covers very well some specific cases, while is not useful for all the scenarios.
I think it’s safe to say it covers 95% of the scenarios I’ve found in the past 7 years.
cmemgzip will not help you if you run out inodes.
Usage
Usage is very simple, and I kept it very verbose as the nature of the work is Operations, Engineers need to know what is going on.
I return error level/exit code 0 if everything goes well or 1 on errors.
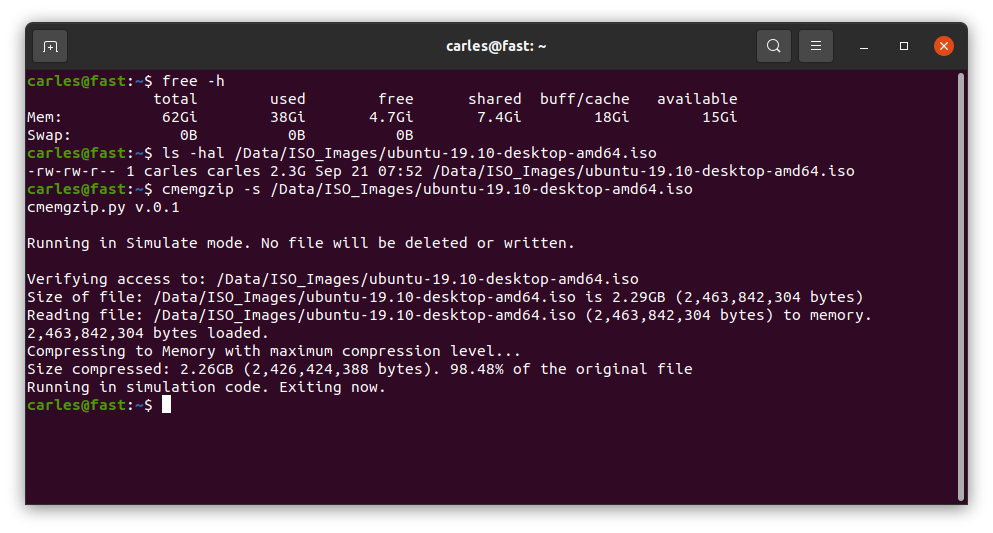
./cmemgzip.py /home/carles/test_extract/SherlockHolmes.txt
cmemgzip.py v.0.1
Verifying access to: /home/carles/test_extract/SherlockHolmes.txt
Size of file: /home/carles/test_extract/SherlockHolmes.txt is 553KB (567,291 bytes)
Reading file: /home/carles/test_extract/SherlockHolmes.txt (567,291 bytes) to memory.
567,291 bytes loaded.
Compressing to Memory with maximum compression level…
Size compressed: 204KB (209,733 bytes). 36.97% of the original file
Attempting to create the gzip file empty to ensure write permissions
Deleting the original file to get free space
Writing compressed file /home/carles/test_extract/SherlockHolmes.txt.gz
Verifying space written match size of compressed file in Memory
Write verification completed.
You can also simulate, without actually delete or write to disk, just in order to know what will be the
Installation
There are no third party libraries to install. I only use the standard ones: os, sys, gzip
So clone it with git in your preferred folder and just create a symbolic link with your favorite name:
If you use ZFS with spinning drives and you share iSCSI, you will need to use a SLOG device for ZIL otherwise you’ll see your iSCSI connections interrupted.
What is a ZIL?
ZIL: Acronym for ZFS Intended Log. Logs synchronous operations to disk
SLOG: Acronym for (S)eperate (LOG) Device
In ZFS Data is first written and stored in-memory, then it’s flushed to drives. This can take 10 seconds normally, a bit more in certain occasions.
So without SLOG it can happen that if a power loss occurs, you may loss the last 10 seconds of Data submitted.
The SLOG device brings security that if there is a power loss, after remounting the pool, the information in the SLOG, acknowledged to iSCSI clients, is not lost and flushed to the Hard drives conforming the pool. Basically this device keeps the writings that come from network and flushes to the Hard drives and then clears this data from the SLOG.
The SLOG also allows ZFS to sort how the transactions will be written, to do in a more efficient way.
Normally I’m describing configurations with a fast device for SLOG ZIL, like one or a pair of NVMe drive or SAS SSD, most commonly in mirror a pool of 12 HDD drives or more SAS preferentially, maybe SATA, with 14TB or more each.
As the SLOG device will persist your Data if there is a power off, and submit to the pool the accepted transactions, it is clear that you cannot spare yourself from having a SLOG ZIL device (or better a mirror). It is needed to bring security when remotely writing.
But what happens if we have a kind of business where we don’t care about that the last 10 seconds writings may be lost? (ZFS will never get corrupted due to its kinda journal system), just because we are filling a Server the fastest possible, migrating from another, or because we are running workouts that can be retaken is some data is lost… do we really need to have the speed constrain of an SSD?. Examples are a Hadoop node, or a SETI@Home client. Tasks will be resumed if something failed.
Or maybe you fill your servers with sync=always, so writing it’s safe, and then you use them only for read, or for a Statics Internet Caches (CDNs like Akamai, Cloudfare…) or you use it for storing Backups, write once read many. You don’t really need the constraint speed of a ZIL running at 800 MB/s.
Let me put in another way, we have 2 NIC 100Gbps, in bonding, so 200Gbps (equivalent to (25GB/s Gigabytes per second), 90 HDD drives that can work in parallel up to 250 MB/s each (22.5GB/s) and our Server has a pair or SAS SSD ZIL in mirror, that writes at 900 MB/s (Megabytes per second, so 0.9 GB/s), so our bottleneck or constraint is the SLOG ZIL.
Adding one RAMDISK, or better two RAMDISKs in mirror, we can get to much more highers speeds. I cannot tell you how much, but in my tests with regular configurations (8D+3P) I was achieving more than 2 GB (Gigabytes) per second sustained of Data to the pool. Take in count that the speed writing to the pool does not only depend on the speed on the ZIL, and the speed of the HDD spinning drives (slow, between 100 and 250 MB/s), but also about the config of the pool (number of vdevs, distributions of data and parity drives) and the throughput of your IOC (Input Output Controller), and the number of them.
Live real scenarios use to be more in the line of having 2x10GbpE cards, combined in bonding making 20Gbps, so being able to transmit 2.5GB/s. So to get the max speed of our Network this Ramdrive will do it. Also NVMe devices used as ZIL will do it.
The problem with the NVMe is that they are connected to the PCI Express bus, and so they are not hot swap. If one dies, you cannot replace without stopping the Server.
The problem with the SSD is that they are not made for writing, they will die, so you need at least a mirror and for heavy IO I strongly recommend you to go with Enterprise grade SAS SSD drives. Those are made to last.
SSD Enterprise grade are double price versus one common SSD, but that peace of mind and extra lasting is worth it. And you don’t need a very big device, only has to hold 10 seconds of Data at max speed. So if you can ingest Data through the Network at 20 Gbps (2.5GB/s) you only need approximately 25 GB of space of the SLOG. 50 GB if you want to be more than safe.
Also you can use partitions instead of complete devices for the SLOG (like for the ZFS pool, where you can add complete drives, or partitions).
If you write locally, and you have 4 IOC’s capable of delivering 8 GB/s each, and you write to a Dataset to the pool, and not to a ZVOL which are slow by nature, you can get astonishing combined speed writing to the drives. If you are migrating a Server to another new, where you can resume if power goes down, then it’s safe to disable sync (set async) while this process runs, and turn sync on when going live to production. If you use async you don’t need to use a SLOG.
4 IOC’s able to deliver 8 GB/s are enough to provide sustained speed to 90 HDD SAS drives. 90x200MB/s=18GB/s required at max speed or 90x250MB/s=22.5GB/s.
The HDD drives provide different speeds in the inner and in the outer areas of the drive, so normally those drives up to 8TB perform between 100 and 200 MB/s, and the drives from 10TB SAS to 14TB SAS perform between 145 and 250 MB/s. I cannot tell about the 16 TB as I’ve not tested them.
The instructions to set a Ramdrive and to assign to a pool are like this:
#!/usr/bin/env bash
RAM_GB=1
RAM_DRIVE_SIZE_IN_BYTES=$((RAM_GB*1048576))
if [[ $(id -u) -ne 0 ]] ; then
echo "Please run as root"
exit 1
fi
modprobe brd rd_nr=1 rd_size=${RAM_DRIVE_SIZE_IN_BYTES} max_part=0
echo "Use it like: zpool add carlespool log ram0"
If you created more than one Ramdisk you can add a mirror for the slog to the pool with:
You can partition the Ramdrive and add a partition but we want to add the whole ram device.
Obviously you cannot put other things to that Ramdisk (like the Metadata) as you need persistence for that.
In any case, please, avoid JBODs loaded of big HDD drives with low bandwidth micro SATA like 3Gbps per channel to the Server, and RAID. The bandwidth is too low. Your rebuilds will take forever.
With ZFS you’ll resilver (rebuild) only the actual data, not the whole drive.
I came with this solution when one of my 4U60 Servers had two slots broken. You’ll not use this in Production, as SLOG loses its function, but I managed to use one $40K USD broken Server and to demonstrate that the Speed of the SLOG device (ZFS Intented Log or ZIL device) sets the constraints for the writing speed.
The ZFS DRAID config I was using required 60 drives, basically 58 14TB Spinning drives and 2 SSD for the SLOG ZIL. As I only had 58 slots I came with this idea.
This trick can be very useful if you have a box full of Spinning drives, and when sharing by iSCSI zvols you get disconnected in the iSCSI Initiator side. This is typical when ZFS has only Spinning drives and it has no SLOG drives (dedicated fast devices for the ZIL, ZFS INTENDED LOG)
Create a single Ramdrive of 10GB of RAM:
modprobe brd rd_nr=1 rd_size=10485760 max_part=0
Confirm ram0 device exists now:
ls /dev/ram*
Confirm that the pool is imported:
zpool list
Add to the pool:
zpool add carles-N58-C3-D16-P2-S4 log ram0
In the case that you want to have two ram devices as SLOG devices, in mirror.
It is interesting to know that you can work with partitions instead of drives. So for this test we could have partitioned ram0 with 2 partitions and make it work in mirror. You’ll see how much faster the iSCSI communication goes over the network. The writing speed of the ZIL SLOG device is the constrain for ingesting Data from the Network to the Server.
Creating a partition bigger than 2TiB
Master Boot Record (MBR) based partitioning is limited to 2TiB however GUID Partition Table (GPT) has a limit of 8 ZiB.
That’s something very simply, but make you lose time if you’re partitioning big iSCSI Shares, or ZFS Zvols, so here is the trick:
[root@CTRLA-18 ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.6 (Maipo)
[root@CTRLA-18 ~]# parted /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
GNU Parted 3.1
Using /dev/zd0
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
Warning: The existing disk label on /dev/zd0 will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? y
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
(parted) mkpart primary 0GB 58.9TB
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 58.9TB 58.9TB primary
(parted) quit
Information: You may need to update /etc/fstab.
[root@CTRLA-18 ~]# mkfs
mkfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
[root@CTRLA-18 ~]# mkfs.ext4 /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
mke2fs 1.42.9 (28-Dec-2013)
....
[root@CTRLA-18 ~]# mount /dev/zvol/N58-C19-D2-P1-S1/vol54854gb /Data
[root@CTRLA-18 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 50G 2.5G 48G 5% /
devtmpfs 126G 0 126G 0% /dev
tmpfs 126G 0 126G 0% /dev/shm
tmpfs 126G 1.1G 125G 1% /run
tmpfs 126G 0 126G 0% /sys/fs/cgroup
/dev/sdp1 1014M 151M 864M 15% /boot
/dev/mapper/rhel-home 65G 33M 65G 1% /home
logs 49G 349M 48G 1% /logs
mysql 9.7G 128K 9.7G 1% /mysql
tmpfs 26G 0 26G 0% /run/user/0
/dev/zd0 54T 20K 51T 1% /Data
ZFS is unable to use a disk
Some times, after creating many pools ZFS may be unable to create a new pool using a drive that is perfectly fine. In this situation, the ideal is wipe the first areas of it, or all of it if you want. If it’s an SSD that is very fast:
dd if=/dev/zero of=/dev/sdc bs=1M status=progress
The status=progress will show a nice progress bar.
Filling a half Petabyte pool as fast as possible
To fill a 60 drives pool composed by 10TB or 14TB spinning drives, so more than half PB, in order to test with real data, you can use this trick:
First, write to the Dataset directly, that’s way much more faster than using zvols.
Secondly, disable the ZIL, set sync=disabled.
Third, use a file in memory to avoid the paytime of reading the file from disk.
Fourth, increase the recordsize to 1M for faster filling (in my experience).
You can use this script of mine that does everything for you, normally you would like to run it inside an screen session, and create a Dataset called Data. The script will mount it in /Data (zfs set mountpoint=/data YOURPOOL/Data):
#!/usr/bin/env bash
# Created by Carles Mateo
FILE_ORIGINAL="/run/urandom.1GB"
FILE_PATTERN="/Data/urandom.1GB-clone."
# POOL="N56-C5-D8-P3-S1"
POOL="N58-C3-D16-P3-S1"
# The starting number, if you interrupt the filling process, you can update it just by updating this number to match the last partially written file
i_COPYING_INITIAL_NUMBER=1
# For 75% of 10TB (3x(16+3)+1 has 421TiB, so 75% of 421TiB or 431,104GiB is 323,328) use 323328
# i_COPYING_FINAL_NUMBER=323328
# For 75% of 10TB, 5x(8+3)+1 ZFS sees 352TiB, so 75% use 270336
# For 75% of 14TB, 3x(16+3)+1, use 453120
i_COPYING_FINAL_NUMBER=453120
# Creating an array that will hold the speed of the latest 1 minute
a_i_LATEST_SPEEDS=(0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0)
i_POINTER_SPEEDS=0
i_COUNTER_SPEEDS=-1
i_ITEMS_KEPT_SPEEDS=60
i_AVG_SPEED=0
i_FILES_TO_BE_COPIED=$((i_COPYING_FINAL_NUMBER-i_COPYING_INITIAL_NUMBER))
get_average_speed () {
# Calculates the Average Speed
i_AVG_SPEED=0
for i_index in {0..59..1}
do
i_SPEED=$((a_i_LATEST_SPEEDS[i_index]))
i_AVG_SPEED=$((i_AVG_SPEED + i_SPEED))
done
i_AVG_SPEED=$((i_AVG_SPEED/((i_COUNTER_SPEEDS)+1)))
}
echo "Bash version ${BASH_VERSION}..."
echo "Disabling sync in the pool $POOL for faster speed"
zfs set sync=disabled $POOL
echo "Maximizing performance with recordsize"
zfs set recordsize=1M ${POOL}
zfs set recordsize=1M ${POOL}/Data
echo "Mounting the Dataset Data"
zfs set mountpoint=/Data ${POOL}/Data
zfs mount ${POOL}/Data
echo "Checking if file ${FILE_ORIGINAL} exists..."
if [[ -f ${FILE_ORIGINAL} ]]; then
ls -al ${FILE_ORIGINAL}
sha1sum ${FILE_ORIGINAL}
else
echo "Generating file..."
dd if=/dev/urandom of=${FILE_ORIGINAL} bs=1M count=1024 status=progress
fi
echo "Starting filling process..."
echo "We are going to copy ${i_FILES_TO_BE_COPIED} , starting from: ${i_COPYING_INITIAL_NUMBER} to: ${i_COPYING_FINAL_NUMBER}"
for ((i_NUMBER=${i_COPYING_INITIAL_NUMBER}; i_NUMBER<=${i_COPYING_FINAL_NUMBER}; i_NUMBER++));
do
s_datetime_ini=$(($(date +%s%N)/1000000))
DATE_NOW=`date '+%Y-%m-%d_%H-%M-%S'`
echo "${DATE_NOW} Copying ${FILE_ORIGINAL} to ${FILE_PATTERN}${i_NUMBER}"
cp ${FILE_ORIGINAL} ${FILE_PATTERN}${i_NUMBER}
s_datetime_end=$(($(date +%s%N)/1000000))
MILLISECONDS=$(expr "$s_datetime_end" - "$s_datetime_ini")
if [[ ${MILLISECONDS} -lt 1 ]]; then
BANDWIDTH_MBS="Unknown (too fast)"
# That sould not happen, but if did, we don't account crazy speeds
else
BANDWIDTH_MBS=$((1000*1024/MILLISECONDS))
# Make sure the Array space has been allocated
if [[ ${i_POINTER_SPEEDS} -gt ${i_COUNTER_SPEEDS} ]]; then
# Add item to the Array the first times only
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
i_COUNTER_SPEEDS=$((i_COUNTER_SPEEDS+1))
else
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
fi
i_POINTER_SPEEDS=$((i_POINTER_SPEEDS+1))
if [[ ${i_POINTER_SPEEDS} -ge ${i_ITEMS_KEPT_SPEEDS} ]]; then
i_POINTER_SPEEDS=0
fi
get_average_speed
fi
i_FILES_TO_BE_COPIED=$((i_FILES_TO_BE_COPIED-1))
i_REMAINING_TIME=$((1024*i_FILES_TO_BE_COPIED/i_AVG_SPEED))
i_REMAINING_HOURS=$((i_REMAINING_TIME/3600))
echo "File cloned in ${MILLISECONDS} milliseconds at ${BANDWIDTH_MBS} MB/s"
echo "Avg. Speed: ${i_AVG_SPEED} MB/s Remaining Files: ${i_FILES_TO_BE_COPIED} Remaining seconds: ${i_REMAINING_TIME} s. (${i_REMAINING_HOURS} h.)"
done
echo "Enabling sync=always"
zfs set sync=always ${POOL}
echo "Setting back recordsize to 128K"
zfs set recordsize=128K ${POOL}
zfs set recordsize=128K ${POOL}/Data
echo "Unmounting /Data"
zfs set mountpoint=none ${POOL}/Data
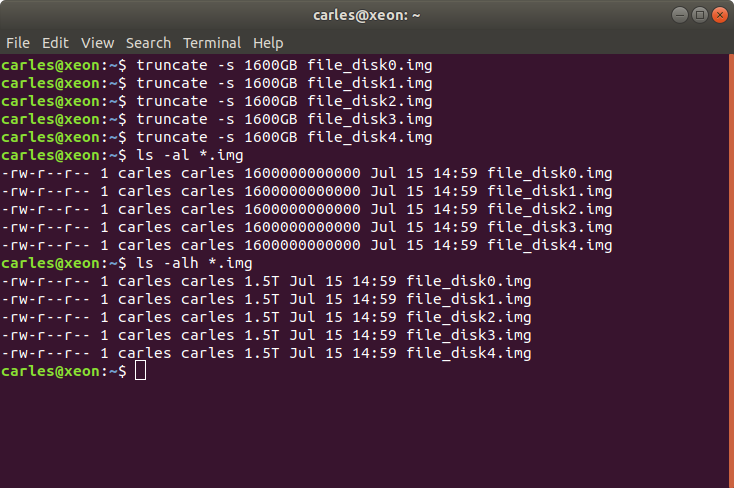
Creating a Sparse file that you can partition or create a loopback on it
I know, your laptop has 512GB of M.2 SSD or NVMe, so that’s it.
Well, you can create a sparse file much more bigger than your capacity, and use 0 bytes of it at all.
For example:
truncate -s 1600GB file_disk0.img
If the files are stored in / then you can add a loop device:
sudo losetup -f /file_disk0.img
I do with the 5 I created.
Then you can check that they exist with:
lsblk
or
cat /proc/partitions
The loop devices will appear under /dev/ now.
For some tests I did this in a Virtual Box Virtual Machine:
I encountered that Server, Xeon, 128 GB of RAM, with those 58 Spinning drives 10 TB and 2 SSD of 2 TB each, where I was testing the latest version of my Software.
Monitoring long term tests, data validation, checking for memory leaks… I notice the Server is using 70 GB of RAM. Only 5.5 GB are used for buffers according to the usual tools (top, htop, free, cat /proc/meminfo, ps aux…) and no programs are eating that amount, so where is the RAM?. The rest of the Servers are working well, including models: same mode, 4U60 with 64 GB of RAM, 4U90 with 128 GB and All-Flash-Array with 256 GB of RAM, only using around 8 GB of RAM even under load. iSCSI sharings being used, with I/O, iSCSI initiators trying to connect and getting rejected, several requests for second, disk pulling, and that usual stuff. And this is the only unit using so many memory, so what?. I checked some modules to see memory consumption, but nothing clear. Ok, after a bit of investigation one member of the Team said “Oh, while you was on holidays we created a Ramdisk and filled it for some validations, we deleted that already but never rebooted the Server”. Ok. The easy solution would be to reboot, but that would had hidden a memory leak it that was the cause. No, I had to find the real cause.
I requested assistance of one my colleagues, specialist, Kernel Engineer. He confirmed that processes were not taking that memory, and ask me to try to drop the cache.
So I did:
sync
echo 3 > /proc/sys/vm/drop_caches
Then the memory usage drop to 11.4 GB and kept like that while I maintain sustained the load.
That’s more normal taking in count that we have 16 Volumes shared and one host is attempting to connect to Volumes that do not exist any more like crazy, Services and Cronjobs run in background and we conduct tests degrading the pool, removing drives, etc..
After tests concluded memory dropped to 2 GB, which is what we use when we’re not under load.
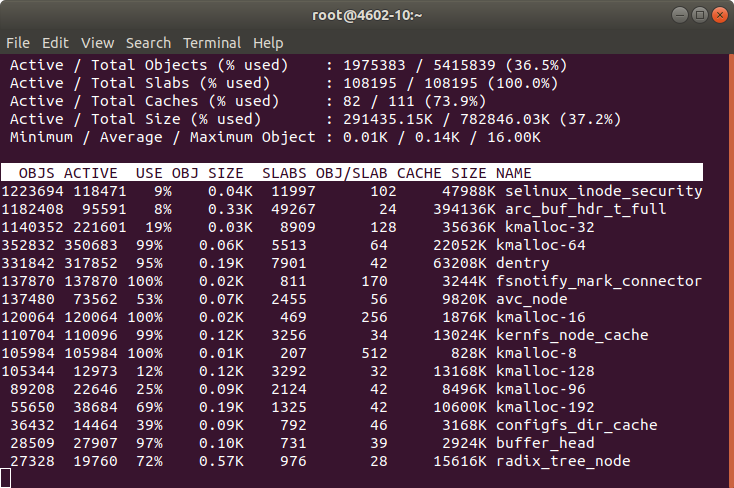
Note: In order to know about the memory being used by Kernel slab cache in real time you can use command:
This year I was invited to speak at the PHP Conference at Berlin 2014.
It was really nice, but I had to decline as I was working hard in a Start up, and I hadn’t the required time in order to prepare the nice conference I wanted and that people deserves.
However, having time, I decided to write an article about what I would had speak at the conference.
I will cover improving performance in a single server, and Scaling out multi-Server architecture, focusing on the needs of growing and Start up projects. Many of those techniques can be used to improve performance with other languages, not just with PHP.
Many of my friends are very good Developing, but know nothing about Architecture and Scaling. Hope this approach the two worlds, Development ad Operatings, into a DevOps bridge.
Improving performance on a single server
Hosting
Choose a good hosting. And if you can afford it choose a dedicated server.
Shared hostings are really bad. Some of them kill your http and mysql instances if you reach certain CPU use (really few), while others share the same hardware between 100+ users serving your pages sloooooow. Others cap the amount of queries that your MySql will handle per hour at so ridiculous few amount that even Drupal or WordPress are unable to complete a request in development.
Other ISP (Internet Service Providers) have poor Internet bandwidth, and so you web will load slow to users.
Some companies invest hundreds of thousands in developing a web, and then spend 20 € a year in the hosting. Less than the cost of a dinner.
You can use a decent dedicated server from 50 to 99 €/month and you will celebrate this decision every day.
Take in count that virtualization wastes between 20% and 30% of the CPU power. And if there are several virtual machines the loss will be more because you loss the benefits of the CPU caching for optimizing parallel instructions execution and prediction. Also if the hypervisor host allows to allocate more RAM than physically available and at some point it swaps, the performance of all the VM’s will be much worst.
If you have a VM and it swaps, in most providers the swap goes over the network so there is an additional bottleneck and performance penalty.
To compare the performance of dedicated servers and instances from different Cloud Providers you can take a look at my project cmips.net
Improve your Server
If your Sever has few RAM, add more. And if your project is running slow and you can afford a better Server, do it.
Using SSD disk will incredibly improve the performance on I/O operations and on swap operations. (but please, do backups and keep them in another place)
If you use a CMS like ezpublish with http_cache enabled probably you will prefer to have a Server with faster cores, rather tan a Server with one or more CPU’s plenty of cores, but slower cores, and that last for a longer time to render the page to the http cache.
That may seem obvious but often companies invest 320 hours in optimizing the code 2%, at a cost of let’s say 50 €/h * 320 hours = 16.000 €, while hiring a better Server would had bring between a 20% to 1000% improvement at a cost of additional 50€/month only or at the cost of 100 € of increasing the RAM memory.
The point here is that the hardware is cheap, while the time of the Engineers is expensive. And good Engineers are really hard to find.
And you probably, as a CEO or PO, prefer to use the talent to warranty a nice time to market for your project, or adding more features, rather than wasting this time in refactorizing.
Even with the most optimal code in the universe, if your project is successful at certain point you’ll have to scale. So adding more Servers. To save a Server now at the cost of slowing the business has not any sense.
Upgrade you PHP version
Many projects still use PHP 5.3, and 5.4.
Latest versions of PHP bring more and more performance. If you use old versions of PHP you can have a Quick Win by just upgrading to the last PHP version.
Use OpCache (or other cache accelerator)
OpCache is shipped with PHP 5.5 by default now, so it is the recommended option. It is though to substitute APC.
To activate OpCache edit php.ini and add:
Linux/Unix:
zend_extension=/path/to/opcache.so
Windows:
zend_extension=C:\path\to\php_opcache.dll
It will greatly improve your PHP performance.
Ensure that OpCache in Production has the optimal config for Production, that will be different from Development Environment.
Note: If you plan to use it with XDebug in Development environments, load OpCache before XDebug.
Disable Profiling and xdebug in Production
In Production disable the profiling, xdebug, and if you use a Framework ensure the Development/Debug features are disabled in Production.
Ensure your logs are not full of warnings
Check that Production logs are not full of warnings.
I’ve seen systems were every seconds 200 warnings were written to logs, the same all the time, and that obviously was slowing down the system.
Typical warnings like this can be easily fixed:
Message: date() [function.date]: It is not safe to rely on the system’s timezone settings. You are required to use the date.timezone setting or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected ‘UTC’ for ‘8.0/no DST’ instead
Profile in Development
To detect where your slow code is, profile it in Development to see where it is spent the most CPU/time.
Check the slow-queries if you use MySql.
Cache html to disk
Imagine you have a sort of craigslist and you are displaying all the categories, and the number of new messages in this landing page. To do that you are performing many queries to the database, SELECT COUNTs, etc… every time a user visits your page. That certainly will overload your database with actually few concurrent visitors.
Instead of querying the Database all the time, do cache the generated page for a while.
This can be achieved by checking if the cache html file exists, and checking the TTL, and generating a new page if needed.
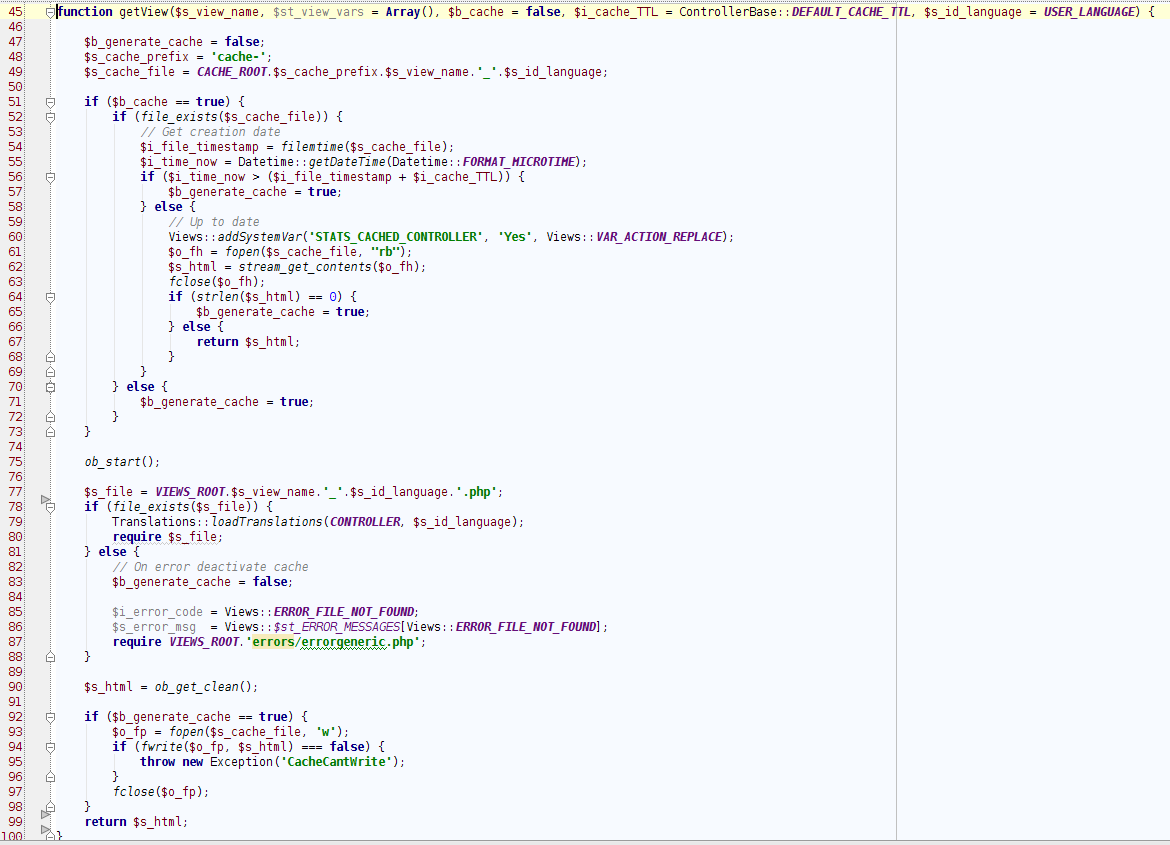
A simple sample would be:
<?php
// Cache pages for 5 minutes
$i_cache_TTL = 300;
$b_generate_cache = false;
$s_cache_file = '/tmp/index.cache.html';
if (file_exists($s_cache_file)) {
// Get creation date
$i_file_timestamp = filemtime($s_cache_file);
$i_time_now = microtime(true);
if ($i_time_now > ($i_file_timestamp + $i_cache_TTL)) {
$b_generate_cache = true;
} else {
// Up to date, get from the disk
$o_fh = fopen($s_cache_file, "rb");
$s_html = stream_get_contents($o_fh);
fclose($o_fh);
// If the file was empty something went wrong (disk full?), so don't use it
if (strlen($s_html) == 0) {
$b_generate_cache = true;
} else {
// Print the page and exit
echo $s_html;
exit();
}
}
} else {
$b_generate_cache = true;
}
ob_start();
// Render your page normally here
// ....
$s_html = ob_get_clean();
if ($b_generate_cache == true) {
// Create the file with fresh contents
$o_fp = fopen($s_cache_file, 'w');
if (fwrite($o_fp, $s_html) === false) {
// Error. Impossible to write to disk
// throw new Exception('CacheCantWrite');
}
fclose($o_fp);
}
// Send the page to the browser
echo $s_html;
This sample is simple, and works for many cases, but presents problems.
Imagine for example that the page takes 5 seconds to be generated with a single request, and you have high traffic in that page, let’s say 500 requests per second.
What will happen when the cache expires is that the first user will trigger the cache generation, and the second, and the third…. so all of the 500 requests * 5 seconds will be hitting the database to generate the cache, but… if creating the page per one requests takes 5 seconds, doing this 2,500 times will not last 5 seconds… so your process will enter in a vicious state where the first queries have not ended after minutes, and more and more queries are being added to the queue until:
a) Apache runs out of childs/processes, per configuration
b) Mysql runs out of connections, per configuration
c) Linux runs out of memory, and processes crashes/are killed
Not to mention the users or the API client, waiting infinitely for the http request to complete, and other processes reading a partial file (size bigger than 0 but incomplete).
Different strategies can be used to prevent that, like:
a) using semaphores to lock access to the cache generation (only one process at time)
b) using a .lock file to indicate that the file is being generated, and so next requests serving from the cache until the cache generation process ends the task, also writing to a buffer like acachefile.buffer (to prevent incomplete content being read) and finally when is complete renaming to the final name and removing the .lock
c) using memcached, or similar, to keep an index in memory of what pages are being generated now, and why not, keeping the cached files there instead of a filesystem
d) using crons to generate the cache files, so they run hourly and you ensure only one process generates the cache files
If you use crons, a cheap way to generate the .html content is that the crons curls/wget your webpage. I don’t recommend this as has some problems, like if that web request fails for any reason, you’ll have cached an error instead of content.
I prefer preparing my projects to being able of rendering the content being invoked from HTTP/S or from command line. But if you use curl because is cheap and easy and time to market is important for your project, then be sure that you check that your backend code writes an Status OK in the HTML that the cron can check to ensure that the content has been properly generated. (some crons only check for http status, like 200, but if your database or a xml gateway you use fails you will likely get a 200 and won’t detect that you’re caching pages with “error I can’t connect to the database” instead)
Many Frameworks have their own cache implementation that prevent corruption that could come by several processes writing to the same file at the same time, or from PHP dying in the middle of the render.
You can see a more complex MVC implementation, with Views, from my Framework Catalonia here:
By serving .html files instead of executing PHP with logic and performing queries to the database you will be able to serve hundreds of thousands requests per day with a single machine and really fast -that’s important for SEO also-.
I’ve done this in several Start ups with wonderful results, and my Framework Catalonia also incorporates this functionality very easily to use.
Note: This is only one of the techniques to save the load of the Database Servers. Many more come later.
Cache languages to disk
If you have an application that is multi-language, or if your point for the Strings (sections, pages, campaigns..) to be edited by Marketing is the Database, there is no need to query it all the time.
Simply provide a tool to “generate language files”.
Your languages files can be Javascript files loaded by the page, or can be PHP files generated.
For example, the file common_footer_en.php could be generated reading from Database and be like that:
<php
/* Autogenerated English translations file common_footer_en.php
on 2014-08-10 02:22 from the database */
$st_translations['seconds'] = 'seconds';
$st_translations['Time'] = 'Time';
$st_translations['Vars used'] = 'Vars used in these templates';
$st_translations['Total Var replacements'] = 'Total replaced';
$st_translations['Exec time'] = 'Execution time';
$st_translations['Cached controller'] = 'Cached controller';
So the PHP file is going to be generated when someone at your organization updates the languages, and your code is including it normally like with any other PHP file.
Use the Crons
You can set cron jobs to do many operations, like map reduce, counting in the database or effectively deleting the data that the user selected to delete.
Imagine that you have classified portal, and you want to display the number of announces for that category. You can have a table NUM_ANNOUNCES to store the number of announces, and update it hourly. Then your database will only do the counting once per hour, and your application will be reading the number from the table NUM_ANNOUNCES.
The Cron can also be used to make expire old announces. That way you can avoid a user having to wait for that clean up taking process when you have a http request to PHP.
A cron file can be invoked by:
php -f cron.php
By:
./cron.php
If you give permissions of execution with chmod +x and set the first line in cron.php as:
#!/usr/bin/env php
Or you can do a trick, that is emulate a http request from bash, by invoking a url with curl or with wget. Set the .htaccess so the folder for the cron tasks can only be executed from localhost for adding security.
This last trick has the inconvenient that the calling has the same problems as any http requests: restarting Apache will kill the process, the connection can be closed by timed out (e.g. if process is taking more seconds than the max. execution time, etc…)
Use Ramdisk for PHP files
With Linux is very easy to setup a RamDisk.
You can setup a RamDisk and rsync all your web .PHP files at system boot time, and when deploying changes, and config Apache to use the Ramdisk folder for the website.
That way for every request to the web, PHP files will be served from RAM directly, saving the slow disk access. Even with OpCache active, is a great improvement.
At these times were one Gigabyte of memory is really cheap there is a huge difference from reading files from disk, and getting them from memory. (Reading and writing to RAM memory is many many many times faster than magnetic disks, and many times faster than SSD disks)
Also .js, .css, images… can be served from a Ram disk folder, depending on how big your web is.
Ramdisk for /tmp
If your project does operations on disk, like resizing images, compressing files, reading/writing large CSV files, etcetera you can greatly improve the performance by setting the /tmp folder to a Ramdisk.
If your PHP project receives file uploads they will also benefit (a bit) from storing the temporal files to RAM instead to the disk.
Use Cache Lite
Cache Lite is a Pear extension that allows you to keep data in a local cache of the Web Server.
You can cache .html pages, or you can cache Queries and their result.
<?php
require_once "Cache/Lite.php";
$options = array(
'cacheDir' => '/tmp/',
'lifeTime' => 7200,
'pearErrorMode' => CACHE_LITE_ERROR_DIE
);
$cache = new Cache_Lite($options);
if ($data = $cache->get('id_of_the_page')) {
// Cache hit !
// Content is in $data
echo $data;
} else {
// No valid cache found (you have to make and save the page)
$data = '<html><head><title>test</title></head><body><p>this is a test</p></body></html>';
echo $data;
$cache->save($data);
}
It is nice that Cache Lite handles the TTL and keeps the info stored in different sub-directories in order to keep a decent performance. (As you may know many files in the same directory slows the access much).
Use HHVM (HipHop Virtual Machine) from Facebook
Facebook Engineers are always trying to optimize what is run on the Servers.
Faster code means, less machines. Even 1% of CPU use improvement means a lot of Servers less. Less Servers to maintain, less money wasted, less space on the Data Centers…
So they created the HHVM HipHop Virtual Machine that is able to run PHP code, much much faster than PHP. And is compatible with most of the Frameworks and Open Source projects.
They also created the Hack language that is an improved PHP, with type hinting.
So you can use HHVM to make your code run faster with the same Server and without investing a single penny.
Use C extensions
You can create and use your own C extensions.
C extensions will bring really fast execution. Just to get the idea:
I built a PHP extension to compare the performance from calculating the Bernoulli number with PHP and with the .so extension created in C.
In my Core i7 times were:
PHP:
Computed in 13.872583150864 s
PHP calling the C compiled extension:
Computed in 0.038495063781738 s
That’s 360.37 times faster using the C extension. Not bad.
Use Zephir
Zephir is a an Open Source language, very similar to PHP, that allows to create and maintain easily extensions for PHP.
Use Phalcon
Phalcon is a Web MVC Framework implemented as C extension, so it offers a high performance.
Check if you’re using the correct Engine for MySql
Many Developers create the tables and never worry about that. And many are using MyIsam by default. It was the by default Engine prior to MySql 5.5.
While MyIsam can bring good performance in some certain cases, my recommendation is to use InnoDb.
Normally you’ll have a gain in performance with MyIsam if you’ve a table were you only write or only read, but in all the other cases InnoDb is expected to be much more performant and safe.
MyIsam tables also get corruption from time to time and need manually fixing and writing to disks are not so reliable than InnoDb.
As MyIsam uses table-locking for updates and deletes to any existing row, it is easy to see that if you’re in a web environment with multiple users, blocking the table -so the other operations have to wait- will make things be slow.
If you have to use Joins clearly you will benefit from using InnoDb also.
Use InMemory Engine from MySql
MySql has a very powerful Engine called InMemory.
The InMemory Engine will store things in RAM and loss the data when MySql is restarted.
However is very fast and very easy to use.
Imagine that you have a travel application that constantly looks at which country belongs the city specified by user. A Quickwin would be to INSERT all this data in the InMemory Engine of MySql when it is started, and do just one change in your code: to use that Table.
Really easy. Quick improvement.
Use curl asynchronously
If your PHP has to communicate with other systems using curl, you can do the http/s call, and instead of waiting for a response let your PHP do more things in the meantime, and then check the results.
You can also call to multiple curl calls in parallel, and so avoid doing one by one in serial.
Guess that you have a query that returns 1000 results. Then you add one by one to an array.
Probably you’re going to have substantial gain if you keep in the database a single row, with the array serialized.
So an array like:
$st_places = Array(‘Barcelona’, ‘Dublin’, ‘Edinburgh’, ‘San Francisco’, ‘London’, ‘Berlin’, ‘Andorra la Vella’, ‘Prats de Lluçanès’);
Would be serialized to an string like:
a:8:{i:0;s:9:”Barcelona”;i:1;s:6:”Dublin”;i:2;s:9:”Edinburgh”;i:3;s:13:”San Francisco”;i:4;s:6:”London”;i:5;s:6:”Berlin”;i:6;s:16:”Andorra la Vella”;i:7;s:19:”Prats de Lluçanès”;}
This can be easily stored as String and unserialized later back to an array.
Note: In Internet we have a lot of encodings, Hebrew, Japanese… languages. Be careful with encodings when serializing, using JSon, XML, storing in databases without UTF support, etc…
Use Memcached to store common things
Memcached is a NoSql database in memory that can run in cluster.
The idea is to keep things there, in order to offload the load of the database. And as everything is in RAM it really runs fast.
You can use Memcached to cache Queries and their results also.
For example:
You have query SELECT * FROM translations WHERE section=’MAIN’.
Then you look if that String exists as key in the Memcached, and if it exists you fetch the results (that are serialized) and you avoid the query. If it doesn’t exist, you do normally the query to the database, serialize the array and store it in the Memcached with a TTL (Time to Live) using the Query (String) as primary key. For security you may prefer to hash the query with MD5 or SHA-1 and use the hash as key instead of using it plain.
When the TTL is reached the validity of the data would have expired and so it’s time to reinsert the contents in the next query.
Be careful, I’ve seen projects that were caching private data from users without isolating the key properly, so other users were getting the info from other users.
For example, if the key used was ‘Name’ and the value ‘Carles Mateo’ obviously the next user that fetch the key ‘Name’ would get my name and not theirs.
If you store private data of users in Memcache, it is a nice idea to append the owner of that info to the hash. E.g. using key: 10701577-FFADCEDBCCDFFFA10C
Where ‘10701577’ would be the user_id of the owner of the info, and ‘FFADCEDBCCDFFFA10C’ a hash of the query.
Before I suggested that you can keep a table of counting for the announces in a classified portal. This number can be stored in the Memcached instead.
You can store also common things, like translations, or cities like in the example before, rate of change for a currency exchanging website…
The most common way to store things there is serialized or Json encoded.
Be aware of the memory limits of Memcached and contrl the cache hitting ratio to avoid inserting data, and losing it constantly because is used few and Memcached has few memory.
Use jQuery for Production (small file) and minimized files for js
Use the Production jQuery library in Production, I mean do not use the bigger file Development jQuery library for Production.
There are product that eliminate all the necessary spaces in .js and .css files, and so are served much faster. These process is called minify.
It is important to know that in many emerging markets in the world, like Brazil, they have slow DSL lines. Many 512 Kbit/secons, and even modem connections!.
Activate compression in the Server
If you send large text files, or Jsons, you’ll benefit from activating the compression at the Server.
It consumes some CPU, but many times it brings an important improvement in speed serving the pages to the users.
Use a CDN
You can use a Content Delivery Network to offload your Servers from sending plain texts, html, images, videos, js, css…
You can delegate this to the CDN, they have very speedy Internet lines and Servers, so your Servers can concentrate into doing only BackEnd operations.
Please take attention to the documentation, a common mistake is to send Cache Headers to the CDN servers, while they’ll use this headers to set the cache TTL and ignore their web configuration parameters. (For example s-maxage, like: Cache-Control: public, s-maxage=600)
You can take a look at any website by telneting to the port 80 and doing the request manually or easily by using lynx:
lynx -mime_header http://blog.carlesmateo.com | less
Do you need a Framework?
If you’re processing only BackEnd petitions, like in the video games industry, serving API’s, RESTful, etc… you probably don’t need a Framework.
The Frameworks are generic and use much more resources than you’re really need for a fast reply.
Many times using a heavy Framework has a cost of factor times, compared to use simply PHP.
Save database connections until really needed
Many Frameworks create a connection to the Database Server by default. But certain parts of your code application do not require to connect to the database.
For example, validating the data from a form. If there are missing fields, the PHP will not operate with the Database, just return an error via JSon or refreshing the page, informing that the required field is missing.
If a not logged user is requesting the dashboard page, there is no need to open a connection to the database (unless you want to write the access try to an error log in the database).
In fact opening connections by default makes easier for attackers to do DoS attacks.
With a Singleton pattern you can easily implement a Db class that handles this transparently for you.
Scaling out / Multi Server Environment
Memcached session
When you have several Web Servers you’ll need something more flexible than the default PHP handler (that stores to a file in the Web Server).
The most common is to store the Session, serialized, in a Memcached Cluster.
Use Cassandra
Apache Cassandra is a NoSql database that allows to Scale out very easily.
The main advantage is that scales linearly. If you have 4 nodes and add 4 more, your performance will be doubled. It has no single point of failure, is also resilient to node failures, it replicates the data among the nodes, splits the load over the nodes automatically and support distributed datacenter architectures.
A easy way to split the load is to have a MySql primary Server, that handles the writes, and MySql secondary (or Slave) Servers handling the reads.
Every write sent to the Master is replicated into the Slaves. Then your application reads from the slaves.
You have to tell your code to do the writes to database to the primary Server, and the reads to the secondaries. You can have a Load Balancer so your code always ask the Load Balancer for the reads and it makes the connection to the less used server.
Do Database sharding
To shard the data consist into splitting the data according to a criteria.
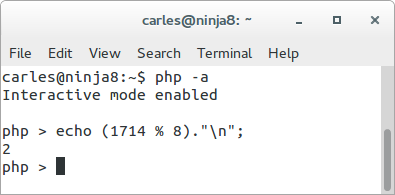
For example, imagine we have 8 MySql Servers, named mysql0 to mysql7. If we want to insert or read data for user 1714, then the Server will be chosen from dividing the user_id, so 1714, between the number of Servers, and getting the MOD.
So 1714 % 8 gives 2. This means that the MySql Server to use is the mysql2.
For the user_id 16: 16 & 8 gives 0, so we would use mysql0. And so.
You can shard according to the email, or other fields as well. And you can have the same master and secondaries for the shards also.
When doing sharding in MySql you cannot do joins to data in other Servers. (but you can replicate all the data from the several shards in one big server in house, in your offices, and so query it and join if you need that for marketing purposes).
I always use my own sharding, but there is a very nice product from CodeFutures called dbshards. It handles the traffics transparently. I used it when in a video games Start up with very satisfying result.
Use Cassandra assync queries
Cassandra support asynchronous queries. That means you can send the query to the Server, and instead of waiting, do other jobs. And check for the result later, when is finished.
Consider using Hadoop + HBASE
A Cluster alternative to Cassandra.
Use a Load Balancer
You can put a Load Balancer or a Reverse Proxy in front of your Web Servers. The Load Balancer knows the state of the Web Servers, so it will remove a Web Server from the Array if it stops responding and everything will continue being served to the users transparently.
There are many ways to do Load Balancing: Round Robin, based on the load on the Web Servers, on the number of connections to each Web Server, by cookie…
To use a Cookie based Load Balancer is a very easy way to split the load for WordPress and Drupal Servers.
Imagine you have 10 Web Servers. In the .htaccess they set a rule to set a Cookie like:
SERVER_ID=WEB01
That was in the case of the first Web Server.
Second Server would have in the .htaccess to set a Cookie like:
SERVER_ID=WEB02
Etcetera
When for first time an user connects to the Load Balancer it sends the user to one of the 10 Web Servers. Then the Web Server sends its cookie to the browser of the Client. E.g. WEB07
After that, in the next requests from the client it will be redirected to the server by the Load Balancer to the Server that set the Cookie, so in this example WEB07.
The nice thing of this way of splitting the traffic is that you don’t have to change your code, nor handling the Sessions different.
If you use two Load Balancers you can have a heartbeat process in them and a Virtual Ip, and so in case your main Load Balancer become irresponsible the Virtual Ip will be mapping to the second Load Balancer in milliseconds. That provides HA.
Use http accelerators
Nginx, varnish, squid… to serve static content and offload the PHP Web Servers.
Auto-Scale in the Cloud
If you use the Cloud you can easily set Auto-Scaling for different parts of your core.
A quick win is to Scale the Web Servers.
As in the Cloud you pay per hour using a computer, you will benefit from cost reduction in you stop using the servers when you don’t need them, and you add more Servers when more users are coming to your sites.
Video game companies are a good example of hours of plenty use and valleys with few users, although as users come from all the planet it is most and most diluted.
Actually the Performance of the Google Cloud to Scale without any precedent is great.
Opposite to other Clouds that are based on instances, Google Cloud offers the platform, that will spawn your code across so many servers as needed, transparently to you. It’s a black box.
Schedule operations with RabbitMQ
Or other Queue Manager.
The idea is to send the jobs to the Queue Manager, the PHP will continue working, and the jobs will be performed asynchronously and notify the end.
RabbitMQ is cool also because it can work in cluster and HA.
Use GlusterFs for NAS
GlusterFs (and other products) allow you to have a Distributed File System, that splits the load and the data across the Servers, and resist node failures.
If you have to have a shared folder for the user’s uploads, for example for the profile pictures, to have the PHP and general files locally in the Servers and the Shared folder in a GlusterFs is a nice option.
Avoid NFS for PHP files and config files
As told before try to have the PHP files in a RAM disk, or in the local disk (Linux caches well and also OpCache), and try to not write code that reads files from disk for determining config setup.
I remember a Start up incubator that had a very nice Server, but the PHP files were read from a mounted NFS folder.
That meant that on every request, the Server had to go over the network to fetch the files.
Sadly for the project’s performance the PHP was reading a file called ENVIRONMENT that contained “PROD” or “DEVEL”. And this was done in every single request.
Even worst, I discovered that the switch connecting the Web Server and the NFS Server was a cheap 10 Mbit one. So all the traffic was going at 10 Mbit/s. Nice bottleneck.
Improve your network architecture
You can use 10 GbE (10 Gigabit Ethernet) to connect the Servers. The Web Servers to the Databases, Memcached Cluster, Load Balancers, Storage, etc…
You will need 10 GbE cards and 10 GbE switchs supporting bonding.
Use bonding to aggregate 10 + 10 so having 20 Gigabit.
You can also use Fibre Channel, for example 10 Gb and aggregate them, like 10 + 10 so 20 Gbit for the connection between the Servers and the Storage.
The performance improvements that your infrastructure will experiment are amazing.