FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# This will make sure printing in the Screen when running in detached mode
ENV PYTHONUNBUFFERED=1
RUN apt-get update -y && apt install -y sudo telnetd vim systemctl && apt-get clean
RUN adduser -gecos --disabled-password --shell /bin/bash telnet
RUN echo "telnet:telnet" | chpasswd
EXPOSE 23
CMD systemctl start inetd; while [ true ]; do sleep 60; done
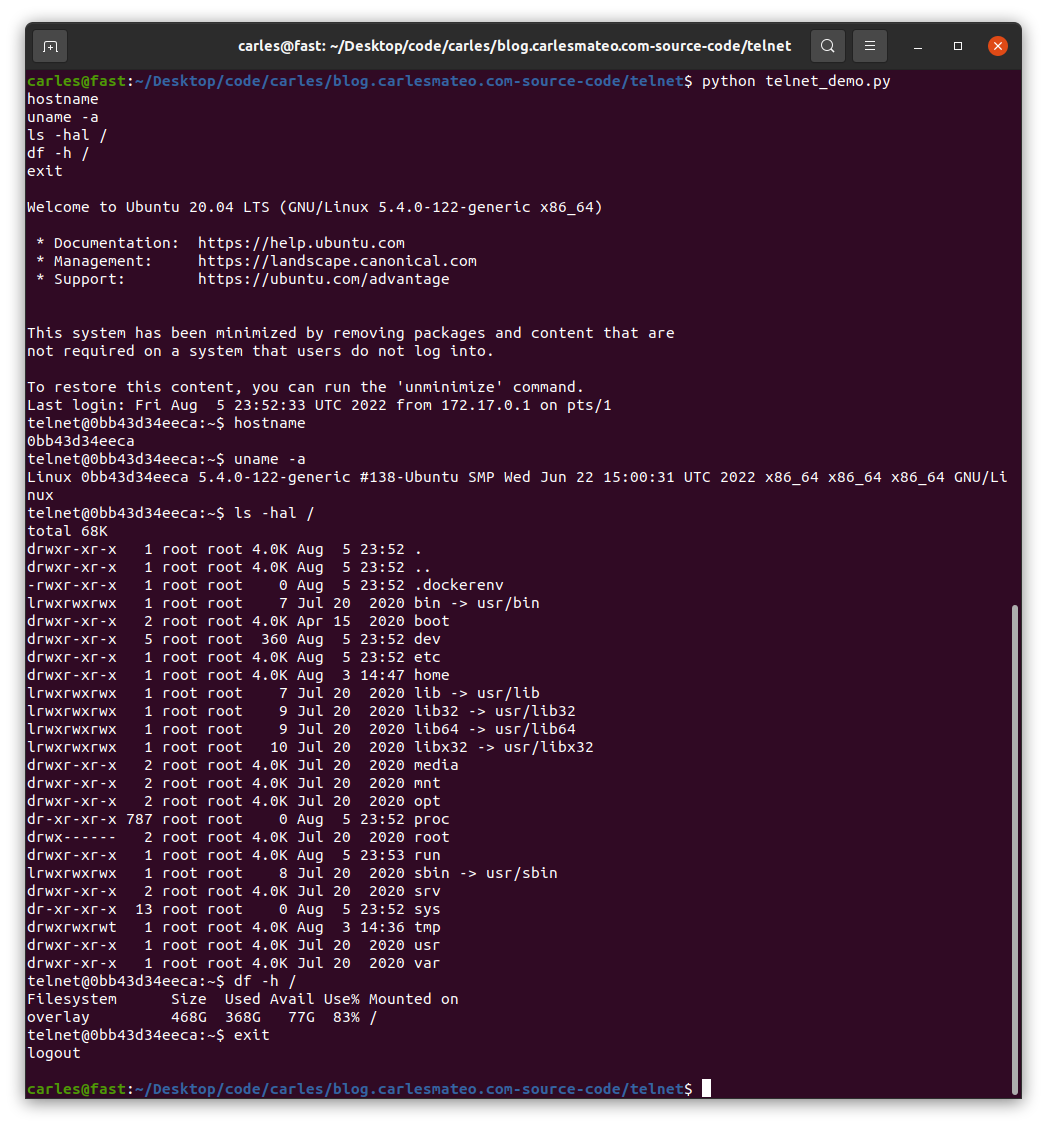
You can see that I use chpasswd command to change the password for the user telnet and set it to telnet. That deals with the complexity of setting the encrypted password.
File: build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="ubuntu_telnet"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
# If you don't want to use cache this is your line
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -it -p 23:23 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
When you run sudo ./build_docker.sh the image will be built. Then run it with:
sudo docker run -it -p 23:23 --name ubuntu_telnet ubuntu_telnet
If you get an error indicating that the port is in use, then your computer has already a process listening on the port 23, use another.
You will be able to stop the Container by pressing CTRL + C
import ipaddress
def check_ip(s_ip_or_net):
b_valid = True
try:
# The IP Addresses are expected to be passed without / even if it's /32 it would fail
# If it uses / so, the CIDR notation, check it as a Network, even if it's /32
if "/" in s_ip_or_net:
o_net = ipaddress.ip_network(s_ip_or_net)
else:
o_ip = ipaddress.ip_address(s_ip_or_net)
except ValueError:
b_valid = False
return b_valid
if __name__ == "__main__":
a_ips = ["127.0.0.2.4",
"127.0.0.0",
"192.168.0.0",
"192.168.0.1",
"192.168.0.1 ",
"192.168.0. 1",
"192.168.0.1/32",
"192.168.0.1 /32",
"192.168.0.0/32",
"192.0.2.0/255.255.255.0",
"0.0.0.0/31",
"0.0.0.0/32",
"0.0.0.0/33",
"1.2.3.4",
"1.2.3.4/24",
"1.2.3.0/24"]
for s_ip in a_ips:
b_success = check_ip(s_ip)
if b_success is True:
print(f"The IP Address or Network {s_ip} is valid")
else:
print(f"The IP Address or Network {s_ip} is not valid")
And the output is like this:
The IP Address or Network 127.0.0.2.4 is not valid
The IP Address or Network 127.0.0.0 is valid
The IP Address or Network 192.168.0.0 is valid
The IP Address or Network 192.168.0.1 is valid
The IP Address or Network 192.168.0.1 is not valid
The IP Address or Network 192.168.0. 1 is not valid
The IP Address or Network 192.168.0.1/32 is valid
The IP Address or Network 192.168.0.1 /32 is not valid
The IP Address or Network 192.168.0.0/32 is valid
The IP Address or Network 192.0.2.0/255.255.255.0 is valid
The IP Address or Network 0.0.0.0/31 is valid
The IP Address or Network 0.0.0.0/32 is valid
The IP Address or Network 0.0.0.0/33 is not valid
The IP Address or Network 1.2.3.4 is valid
The IP Address or Network 1.2.3.4/24 is not valid
The IP Address or Network 1.2.3.0/24 is valid
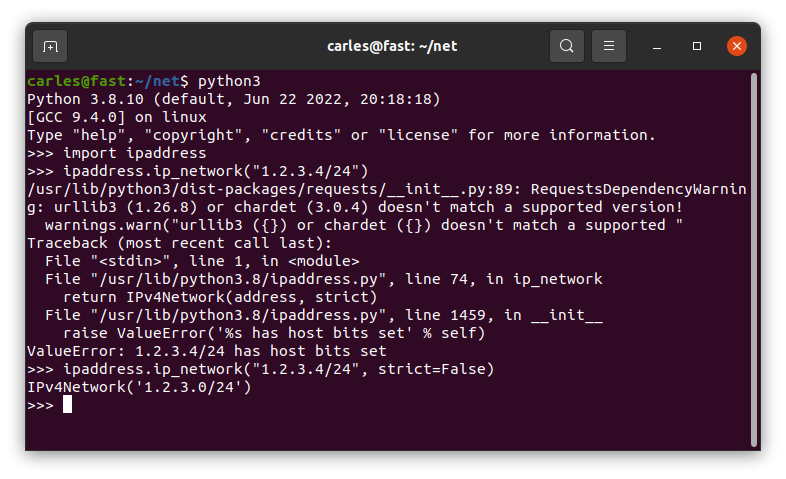
As you can read in the code comments, ipaddress.ip_address() will not validate an IP Address with the CIDR notation, even if it’s /32.
You should strip the /32 or use ipaddress.ip_network() instead.
As you can see 1.2.3.4/24 is returned as not valid.
You can pass the parameter strict=False and it will be returned as valid.
One interesting aspect is that I cover how the messages are delivered as byte sequence. I show this by sending Unicode characters
Files in the project
Dockerfile
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# This will make sure printing in the Screen when running in dettached mode
ENV PYTHONUNBUFFERED=1
ARG PATH_RABBIT_INSTALL=/tmp/rabbit_install/
ARG PATH_RABBIT_APP_PYTHON=/opt/rabbit_python/
RUN mkdir $PATH_RABBIT_INSTALL
COPY cloudsmith.sh $PATH_RABBIT_INSTALL
RUN chmod +x ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN apt-get update -y && apt install -y sudo python3 python3-pip mc htop less strace zip gzip lynx && apt-get clean
RUN ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN service rabbitmq-server start
RUN mkdir $PATH_RABBIT_APP_PYTHON
COPY requirements.txt $PATH_RABBIT_APP_PYTHON
WORKDIR $PATH_RABBIT_APP_PYTHON
RUN pwd
RUN pip install -r requirements.txt
COPY *.py $PATH_RABBIT_APP_PYTHON
COPY loop_send_get_messages.sh $PATH_RABBIT_APP_PYTHON
RUN chmod +x loop_send_get_messages.sh
CMD ./loop_send_get_messages.sh
cloudsmith.sh
#!/usr/bin/sh
# From: https://www.rabbitmq.com/install-debian.html#apt-cloudsmith
sudo apt-get update -y && apt-get install curl gnupg apt-transport-https -y
## Team RabbitMQ's main signing key
curl -1sLf "https://keys.openpgp.org/vks/v1/by-fingerprint/0A9AF2115F4687BD29803A206B73A36E6026DFCA" | sudo gpg --dearmor | sudo tee /usr/share/keyrings/com.rabbitmq.team.gpg > /dev/null
## Cloudsmith: modern Erlang repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/gpg.E495BB49CC4BBE5B.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg > /dev/null
## Cloudsmith: RabbitMQ repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/gpg.9F4587F226208342.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg > /dev/null
## Add apt repositories maintained by Team RabbitMQ
sudo tee /etc/apt/sources.list.d/rabbitmq.list <<EOF
## Provides modern Erlang/OTP releases
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
## Provides RabbitMQ
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
EOF
## Update package indices
sudo apt-get update -y
## Install Erlang packages
sudo apt-get install -y erlang-base \
erlang-asn1 erlang-crypto erlang-eldap erlang-ftp erlang-inets \
erlang-mnesia erlang-os-mon erlang-parsetools erlang-public-key \
erlang-runtime-tools erlang-snmp erlang-ssl \
erlang-syntax-tools erlang-tftp erlang-tools erlang-xmerl
## Install rabbitmq-server and its dependencies
sudo apt-get install rabbitmq-server -y --fix-missing
build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="rabbitmq"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -it --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
requirements.txt
pika
loop_send_get_messages.sh
#!/bin/bash
echo "Starting RabbitMQ"
service rabbitmq-server start
echo "Launching consumer in background which will be listening and executing the callback function"
python3 rabbitmq_getfrom.py &
while true; do
i_MESSAGES=$(( RANDOM % 10 ))
echo "Sending $i_MESSAGES messages"
for i_MESSAGE in $(seq 1 $i_MESSAGES); do
python3 rabbitmq_sendto.py
done
echo "Sleeping 5 seconds"
sleep 5
done
echo "Exiting loop"
A quick video, of 3 minutes, that shows you how it works.
If you don’t have pandas installed you’ll have to install it and lxml, otherwise you’ll get an error:
File "/home/carles/Desktop/code/carles/blog.carlesmateo.com-source-code/venv/lib/python3.8/site-packages/pandas/io/html.py", line 872, in _parser_dispatch
raise ImportError("lxml not found, please install it")
ImportError: lxml not found, please install it
You can install both from PyCharm or from command line with:
pip install pandas
pip install lxml
And here the source code:
import pandas as pd
if __name__ == "__main__":
# Do not truncate the data when printing
pd.set_option('display.max_colwidth', None)
# Do not truncate due to length of all the columns
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.width', 2000)
# pd.set_option('display.float_format', '{:20,.2f}'.format)
o_pd_my_movies = pd.read_html("https://blog.carlesmateo.com/movies-i-saw/")
print(len(o_pd_my_movies))
print(o_pd_my_movies[0])
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y vim python3-pip && \
apt install -y net-tools mc vim htop less strace zip gzip lynx && \
apt install -y apache2 mysql-server ntpdate libapache2-mod-php7.4 mysql-server php7.4-mysql php-dev libmcrypt-dev php-pear && \
apt install -y git && apt autoremove && apt clean && \
pip3 install pytest
RUN a2enmod rewrite
RUN echo "Europe/Ireland" | tee /etc/timezone
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
ENV APACHE_PID_FILE /var/run/apache2/apache2.pid
ENV APACHE_RUN_DIR /var/run/apache2
ENV APACHE_LOCK_DIR /var/lock/apache2
ENV APACHE_LOG_DIR /var/log/apache2
COPY phpinfo.php /var/www/html/
RUN service apache2 restart
EXPOSE 80
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
File: phpinfo.php
<html>
<?php
// Show all information, defaults to INFO_ALL
phpinfo();
// Show just the module information.
// phpinfo(8) yields identical results.
phpinfo(INFO_MODULES);
?>
</html>
File: build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="lampp"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -p 80:80 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
echo
echo "If you want to debug do:"
echo "docker exec -i -t ${s_DOCKER_IMAGE_NAME} /bin/bash"
But he had problems installing napalm-base package.
Note that the package is no longer maintained.
He tried with the last one, and with the previous one (0.25.0), but he always got the error: ModuleNotFoundError: No module named ‘pip.req’
pip3 install napalm-base==0.25.0
Defaulting to user installation because normal site-packages is not writeable
Collecting napalm-base==0.25.0
Using cached napalm-base-0.25.0.tar.gz (35 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [6 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-gzd07xzq/napalm-base_aace1b03ac0e4045bbc85e27c788ebc1/setup.py", line 5, in <module>
from pip.req import parse_requirements
ModuleNotFoundError: No module named 'pip.req'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
TL;TR: The problem is that pip version 10, changed the structure for req.
There are several solutions that can be done to make it work, but the easiest way is to downgrade pip, and install the package. After pip can be upgraded again.
Recently a colleague was asking me for advice on their design of error handling in a Python application.
They were catching an error and raising an Exception, inside the except part of a method, to be catch outside the method.
And at some point a simple logic got really messy and unnecessarily complicated. Also troubleshooting and debugging an error was painful because they were only getting a Custom Exception and not context.
I explained to my colleague that I believed that the person that created that Exception chain of catch came from Java background and why I think they choose that path, and why I think in Python it’s a bad idea.
In Java, functions and methods can only return one object.
I programmed a lot in Java in my career, and it was a pain having to create value objects, and having to create all kind of objects for the return. Is it a good thing that types are strongly verified by the language? Yes. It worked? Yes. It made me invest much more time than necessary? Also yes.
Having the possibility to return only one object makes it mandatory having a way to return when there was an error. Otherwise you would need to encapsulate an error code and error description fields in each object, which is contrary to the nature of the object.
For example, a class Persona. Doesn’t make any sense having an attribute inside the class Persona to register if an operation related to this object went wrong.
For example, if we are in a class Spaceship that has a method GetPersonaInCommand() and there is a problem in that method, doesn’t make any sense to return an empty Persona object with attributes idError, errorDescription. Probably the Constructor or Persona will require at least a name or Id to build the object…. so in this case, makes sense that the method raises an Exception so the calling code catches it and knows that something went wrong or when there is no data to return.
This will force to write Custom Exceptions, but it’s a solution.
Another solution is creating a generic response object which could be an Object with these attributes:
idError
errorDescription
an Object which is the response, in our example Persona or null
I created this kind of approach for my Cassandra libraries to easily work with Cassandra from Java and from PHP, and for Cassandra Universal Driver (a http/s gateway created in year 2014).
Why this in not necessary in Python
Python allows you to return multiple values, so I encourage you tor return a boolean for indicating the success of the operation, and the object/value you’re interested.
You can see it easily if you take a look to FileUtils class from my OpenSource libraries carleslibs.
The method get_file_size_in_bytes(self, s_file) for example:
def get_file_size_in_bytes(self, s_file):
b_success = False
i_file_size = 0
try:
# This will help with Unit Testing by raisin IOError Exception
self.test_helper()
i_file_size = os.path.getsize(s_file)
b_success = True
except IOError:
b_success = False
return b_success, i_file_size
It will always return a boolean value to indicate success or failure of the operation and an integer for the size of the file.
The calling code will do something like this:
o_fileutils = FileUtils()
b_success, i_bytes = o_fileutils.get_file_size_in_bytes("profile.png")
if b_succes is False:
print("Error! The file does not exist or cannot be accessed!")
exit(1)
if i_bytes < 1024:
print("The profile picture should be at least 1KB")
exit(1)
print("Profile picture exists and is", i_bytes, " bytes in length!")
The fact that Python can return multiple variables makes super easy dealing with error handling without having to take the road of Custom Exceptions.
And it is Ok if you want to follow this path, but in my opinion, for most of the developers up to Senior levels, it only over complicates the logic of your code and the amount of try/excepts you have to have everywhere.
If you use PHP you can mix different types in an Array, so you can always return an Array with a boolean, or an i_id_error, and your object or data of whatever type it’s.
Getting back to my carleslibs Open Source package, it is super easy to Unit Test these methods.
In my opinion, this level of simplicity, brings only advantages. Including Software Development speed, which is good for the business.
I’m not advocating for not using Custom Exceptions or to not develop a Exceptions Raising strategy if you need it and you know what you’re doing. I’m just suggesting why I think most of the developments in Python do not really need this and only over complicates the development. There are situations where raising exceptions will be a perfectly useful or even the best approach, there are many scenarios, but I think that in most of cases, using raise inside except will only multiply the time of the development and slow down the speed of bringing new features to the business, over complicating Unit Test as well, and be a real pain for the Junior and Intermediate developers.
The Constructor
Obviously, as the Constructor doesn’t return any value, it is perfectly fine to raise an exception in there, or just to use try/except in the code that is instancing the objects.
This is a document previous to a live code review session.
It has the information to prepare for the upcoming code review session, where I plan to share the lessons learned, decision I took, mistakes I did, refactors I had to overcome, and tentatively we will refactor code in order to add some Unit Testing.
History
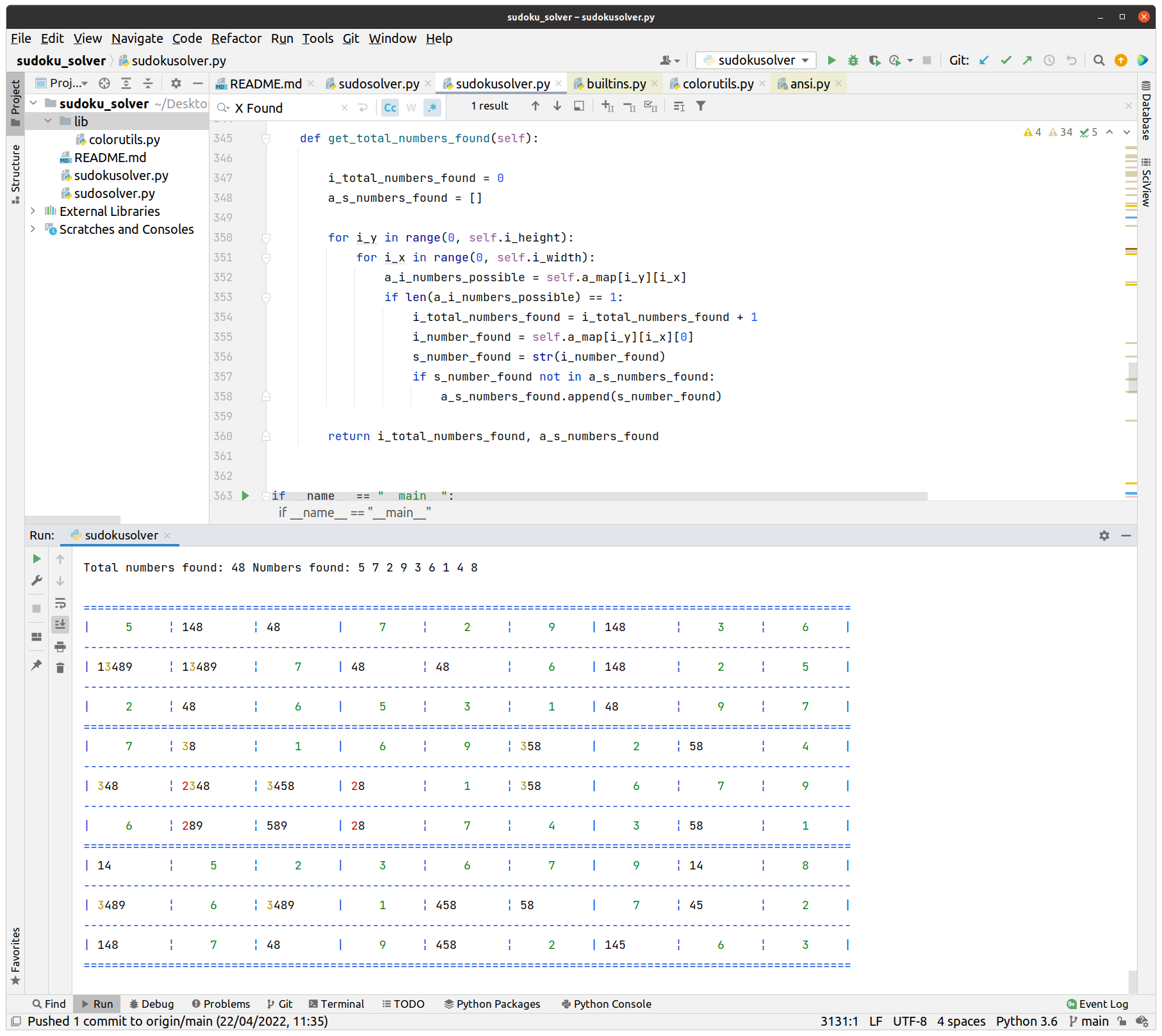
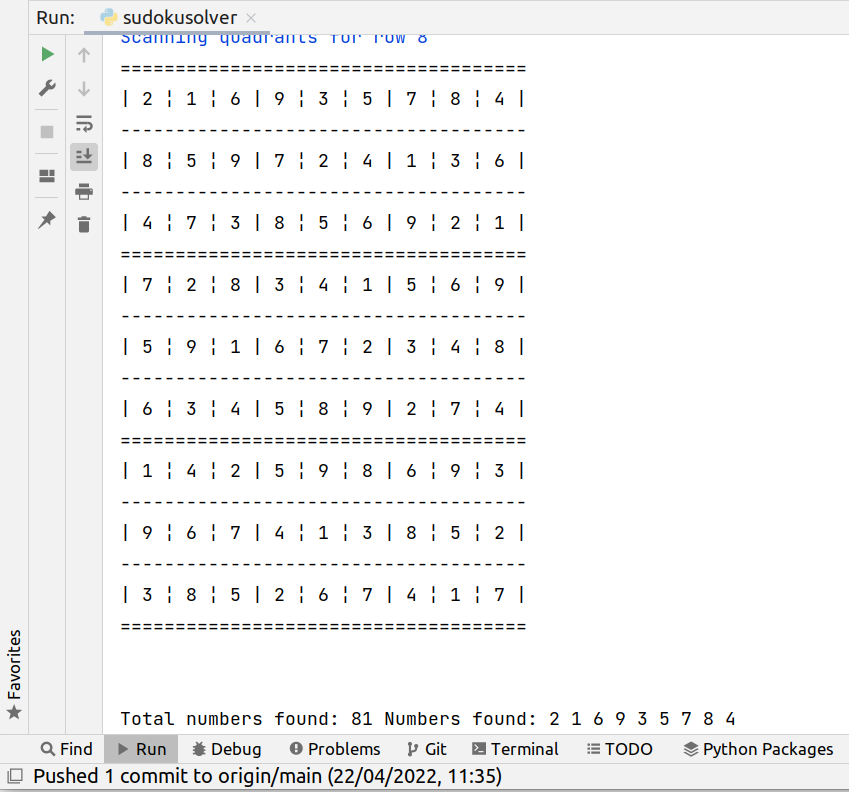
I used to play sudoku with my family, so from time to time I do by myself.
Once I found a sudoku that was impossible and it happened that it was a typo from the newspaper, so, when I found another impossible sudoku I wanted to know if it was me, or if there was a typo or similar, so I decided to write a Sudoku Solver that will solve the sudoku for me.