This is a mechanism I invented and I’ve been using for decades, to migrate or clone my Linux Desktops to other physical servers.
This script is focused on doing the job for Ubuntu but I was doing this already 30 years ago, for X Window as I was responsible of the Linux platform of a ISP (Internet Service Provider). So, it is compatible with any Linux Desktop or Server.
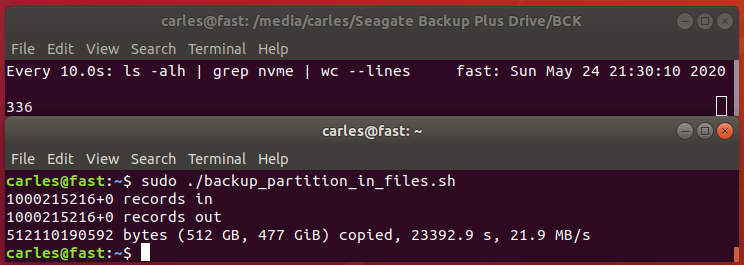
It has the advantage that is a very lightweight backup. You don’t need to backup /etc or /var as long as you install a new OS and restore the folders that you did backup. You can backup and restore Wine (Windows Emulator) programs completely and to/from VMs and Instances as well.
It’s based on user/s rather than machine.
And it does backup using the Timestamp, so you keep all the different version, modified over time. You can fusion the backups in the same folder if you prefer avoiding time versions and keep only the latest backup. If that’s your case, then replace s_PATH_BACKUP_NOW=”${s_PATH_BACKUP}${s_DATETIME}/” by s_PATH_BACKUP_NOW=”${s_PATH_BACKUP}” for instance. You can also add a folder for machine if you prefer it, for example if you use the same userid across several Desktops/Servers.
I offer you a much simplified version of my scripts, but they can highly serve your needs.
#!/usr/bin/env bash
# Author: Carles Mateo
# Last Update: 2022-10-23 10:48 Irish Time
# User we want to backup data for
s_USER="carles"
# Target PATH for the Backups
s_PATH_BACKUP="/home/${s_USER}/Desktop/Bck/"
s_DATE=$(date +"%Y-%m-%d")
s_DATETIME=$(date +"%Y-%m-%d-%H-%M-%S")
s_PATH_BACKUP_NOW="${s_PATH_BACKUP}${s_DATETIME}/"
echo "Creating path $s_PATH_BACKUP and $s_PATH_BACKUP_NOW"
mkdir $s_PATH_BACKUP
mkdir $s_PATH_BACKUP_NOW
s_PATH_KEY="/home/${s_USER}/Desktop/keys/2007-01-07-cloud23.pem"
s_DOCKER_IMG_JENKINS_EXPORT=${s_DATE}-jenkins-base.tar
s_DOCKER_IMG_JENKINS_BLUEOCEAN2_EXPORT=${s_DATE}-jenkins-blueocean2.tar
s_PGP_FILE=${s_DATETIME}-pgp.zip
# Version the PGP files
echo "Compressing the PGP files as ${s_PGP_FILE}"
zip -r ${s_PATH_BACKUP_NOW}${s_PGP_FILE} /home/${s_USER}/Desktop/PGP/*
# Copy to BCK folder, or ZFS or to an external drive Locally as defined in: s_PATH_BACKUP_NOW
echo "Copying Data to ${s_PATH_BACKUP_NOW}/Data"
rsync -a --exclude={} --acls --xattrs --owner --group --times --stats --human-readable --progress -z "/home/${s_USER}/Desktop/data/" "${s_PATH_BACKUP_NOW}data/"
rsync -a --exclude={'Desktop','Downloads','.local/share/Trash/','.local/lib/python2.7/','.local/lib/python3.6/','.local/lib/python3.8/','.local/lib/python3.10/','.cache/JetBrains/'} --acls --xattrs --owner --group --times --stats --human-readable --progress -z "/home/${s_USER}/" "${s_PATH_BACKUP_NOW}home/${s_USER}/"
rsync -a --exclude={} --acls --xattrs --owner --group --times --stats --human-readable --progress -z "/home/${s_USER}/Desktop/code/" "${s_PATH_BACKUP_NOW}code/"
echo "Showing backup dir ${s_PATH_BACKUP_NOW}"
ls -hal ${s_PATH_BACKUP_NOW}
df -h /
See how I exclude certain folders like the Desktop or Downloads with –exclude.
It relies on the very useful rsync program. It also relies on zip to compress entire folders (PGP Keys on the example).
If you use the second part, to compress Docker Images (Jenkins in this example), you will run it as sudo and you will need also gzip.
# continuation... sudo running required.
# Save Docker Images
echo "Saving Docker Jenkins /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_EXPORT}"
sudo docker save jenkins:base --output /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_EXPORT}
echo "Saving Docker Jenkins /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_BLUEOCEAN2_EXPORT}"
sudo docker save jenkins:base --output /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_BLUEOCEAN2_EXPORT}
echo "Setting permissions"
sudo chown ${s_USER}.${s_USER} /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_EXPORT}
sudo chown ${s_USER}.${s_USER} /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_BLUEOCEAN2_EXPORT}
echo "Compressing /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_EXPORT}"
gzip /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_EXPORT}
gzip /home/${s_USER}/Desktop/Docker_Images/${s_DOCKER_IMG_JENKINS_BLUEOCEAN2_EXPORT}
rsync -a --exclude={} --acls --xattrs --owner --group --times --stats --human-readable --progress -z "/home/${s_USER}/Desktop/Docker_Images/" "${s_PATH_BACKUP_NOW}Docker_Images/"
There is a final part, if you want to backup to a remote Server/s using ssh:
# continuation... to copy to a remote Server.
s_PATH_REMOTE="bck7@cloubbck11.carlesmateo.com:/Bck/Desktop/${s_USER}/data/"
# Copy to the other Server
rsync -e "ssh -i $s_PATH_KEY" -a --exclude={} --acls --xattrs --owner --group --times --stats --human-readable --progress -z "/home/${s_USER}/Desktop/data/" ${s_PATH_REMOTE}
I recommend you to use the same methodology in all your Desktops, like for example, having a data/ folder in the Desktop for each user.
You can use Erasure Code to split the Backups in blocks and store a piece in different Cloud Providers.
Also you can store your Backups long-term, with services like Amazon Glacier.
Other ideas are storing certain files in git and in Hadoop HDFS.
If you want you can CRC your files before copying to another device or server.
You will use tools like: sha512sum or md5sum.