TLTR: I’m undergoing a Maintenance on all my sites.
The main reason was that I was getting unexpected API Exceptions on the AWS SDK for Python (boto3), so I connected to the AWS Console to get more information.
Then I saw a message indicating that they will stop EC2-Classic today 30th of October. (Please read the Update on the Postmortem analysis as I understood incorrectly that banner message)
I already started migrating my Services, some I move to other providers like Digital Ocean. Other I had plant to keep in Amazon.
EOL (End of Life) was scheduled for 2022 August, so when I saw the message from Amazon the evening of the 29th, I decided to migrate my EC2-Classic Public Ip’s and Compute to VPC. Trying to deploy from an AMI, Amazon APIs were returning many internal errors, and as I figured out where their failures would be I was able get instances being launch without being Terminated immediately without an explanation. Still I had many problems with the Internet Gateway, VPC NAT, etc… after hours fighting with their errors, and their console, that is more a bunch of pages to manage Infrastructure rather than a user/developer friendly Cloud Tool I decided that I had enough.
After 11 years using Amazon AWS, including a trip to Dublin to be hired as Manager for Cloud Watch, and giving them the idea to add AutoScaling (I was told the project was too easy for me and that I would get bored in a year or too so I was not hired), I decided to move my Services to Google Cloud and to Digital Ocean.
I’m very polite and I saw that when I told to one Manager that the User Interface was terrible he didn’t like, but I have to speak up and say that tools for developers cannot be cold as your evil girlfriend. Cannot be API alike, stand alone pages to manage infinite parts of Architecture. Web providing services for developers cannot be created like in cold SysAdmin style. If the infrastructure is hard to manage and internally you use APIs, build nice Wizards in Javascript. I was leading a Team of Developers with infinite less resources than Amazon or Google and we wrote a Multi-Cloud product, with nice, and clever, and easy to use Wizards, and they were infinitely more better that those giant CSPs. We won a prize at European level at that time. But it was 2013.
I’ve migrated everything, moved all the data, statics, VMs… but I’m completing the adjustments for certain services like Cassandra nodes, web sites, bootstrapping some of my sites based of my PHP Catalonia Framework, adding Firewall rules to GCP, doing changes for Ansible provisioning, deploying the Server scripts from IaC, Docker, etc…
This year I was invited to speak at the PHP Conference at Berlin 2014.
It was really nice, but I had to decline as I was working hard in a Start up, and I hadn’t the required time in order to prepare the nice conference I wanted and that people deserves.
However, having time, I decided to write an article about what I would had speak at the conference.
I will cover improving performance in a single server, and Scaling out multi-Server architecture, focusing on the needs of growing and Start up projects. Many of those techniques can be used to improve performance with other languages, not just with PHP.
Many of my friends are very good Developing, but know nothing about Architecture and Scaling. Hope this approach the two worlds, Development ad Operatings, into a DevOps bridge.
Improving performance on a single server
Hosting
Choose a good hosting. And if you can afford it choose a dedicated server.
Shared hostings are really bad. Some of them kill your http and mysql instances if you reach certain CPU use (really few), while others share the same hardware between 100+ users serving your pages sloooooow. Others cap the amount of queries that your MySql will handle per hour at so ridiculous few amount that even Drupal or WordPress are unable to complete a request in development.
Other ISP (Internet Service Providers) have poor Internet bandwidth, and so you web will load slow to users.
Some companies invest hundreds of thousands in developing a web, and then spend 20 € a year in the hosting. Less than the cost of a dinner.
You can use a decent dedicated server from 50 to 99 €/month and you will celebrate this decision every day.
Take in count that virtualization wastes between 20% and 30% of the CPU power. And if there are several virtual machines the loss will be more because you loss the benefits of the CPU caching for optimizing parallel instructions execution and prediction. Also if the hypervisor host allows to allocate more RAM than physically available and at some point it swaps, the performance of all the VM’s will be much worst.
If you have a VM and it swaps, in most providers the swap goes over the network so there is an additional bottleneck and performance penalty.
To compare the performance of dedicated servers and instances from different Cloud Providers you can take a look at my project cmips.net
Improve your Server
If your Sever has few RAM, add more. And if your project is running slow and you can afford a better Server, do it.
Using SSD disk will incredibly improve the performance on I/O operations and on swap operations. (but please, do backups and keep them in another place)
If you use a CMS like ezpublish with http_cache enabled probably you will prefer to have a Server with faster cores, rather tan a Server with one or more CPU’s plenty of cores, but slower cores, and that last for a longer time to render the page to the http cache.
That may seem obvious but often companies invest 320 hours in optimizing the code 2%, at a cost of let’s say 50 €/h * 320 hours = 16.000 €, while hiring a better Server would had bring between a 20% to 1000% improvement at a cost of additional 50€/month only or at the cost of 100 € of increasing the RAM memory.
The point here is that the hardware is cheap, while the time of the Engineers is expensive. And good Engineers are really hard to find.
And you probably, as a CEO or PO, prefer to use the talent to warranty a nice time to market for your project, or adding more features, rather than wasting this time in refactorizing.
Even with the most optimal code in the universe, if your project is successful at certain point you’ll have to scale. So adding more Servers. To save a Server now at the cost of slowing the business has not any sense.
Upgrade you PHP version
Many projects still use PHP 5.3, and 5.4.
Latest versions of PHP bring more and more performance. If you use old versions of PHP you can have a Quick Win by just upgrading to the last PHP version.
Use OpCache (or other cache accelerator)
OpCache is shipped with PHP 5.5 by default now, so it is the recommended option. It is though to substitute APC.
To activate OpCache edit php.ini and add:
Linux/Unix:
zend_extension=/path/to/opcache.so
Windows:
zend_extension=C:\path\to\php_opcache.dll
It will greatly improve your PHP performance.
Ensure that OpCache in Production has the optimal config for Production, that will be different from Development Environment.
Note: If you plan to use it with XDebug in Development environments, load OpCache before XDebug.
Disable Profiling and xdebug in Production
In Production disable the profiling, xdebug, and if you use a Framework ensure the Development/Debug features are disabled in Production.
Ensure your logs are not full of warnings
Check that Production logs are not full of warnings.
I’ve seen systems were every seconds 200 warnings were written to logs, the same all the time, and that obviously was slowing down the system.
Typical warnings like this can be easily fixed:
Message: date() [function.date]: It is not safe to rely on the system’s timezone settings. You are required to use the date.timezone setting or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected ‘UTC’ for ‘8.0/no DST’ instead
Profile in Development
To detect where your slow code is, profile it in Development to see where it is spent the most CPU/time.
Check the slow-queries if you use MySql.
Cache html to disk
Imagine you have a sort of craigslist and you are displaying all the categories, and the number of new messages in this landing page. To do that you are performing many queries to the database, SELECT COUNTs, etc… every time a user visits your page. That certainly will overload your database with actually few concurrent visitors.
Instead of querying the Database all the time, do cache the generated page for a while.
This can be achieved by checking if the cache html file exists, and checking the TTL, and generating a new page if needed.
A simple sample would be:
<?php
// Cache pages for 5 minutes
$i_cache_TTL = 300;
$b_generate_cache = false;
$s_cache_file = '/tmp/index.cache.html';
if (file_exists($s_cache_file)) {
// Get creation date
$i_file_timestamp = filemtime($s_cache_file);
$i_time_now = microtime(true);
if ($i_time_now > ($i_file_timestamp + $i_cache_TTL)) {
$b_generate_cache = true;
} else {
// Up to date, get from the disk
$o_fh = fopen($s_cache_file, "rb");
$s_html = stream_get_contents($o_fh);
fclose($o_fh);
// If the file was empty something went wrong (disk full?), so don't use it
if (strlen($s_html) == 0) {
$b_generate_cache = true;
} else {
// Print the page and exit
echo $s_html;
exit();
}
}
} else {
$b_generate_cache = true;
}
ob_start();
// Render your page normally here
// ....
$s_html = ob_get_clean();
if ($b_generate_cache == true) {
// Create the file with fresh contents
$o_fp = fopen($s_cache_file, 'w');
if (fwrite($o_fp, $s_html) === false) {
// Error. Impossible to write to disk
// throw new Exception('CacheCantWrite');
}
fclose($o_fp);
}
// Send the page to the browser
echo $s_html;
This sample is simple, and works for many cases, but presents problems.
Imagine for example that the page takes 5 seconds to be generated with a single request, and you have high traffic in that page, let’s say 500 requests per second.
What will happen when the cache expires is that the first user will trigger the cache generation, and the second, and the third…. so all of the 500 requests * 5 seconds will be hitting the database to generate the cache, but… if creating the page per one requests takes 5 seconds, doing this 2,500 times will not last 5 seconds… so your process will enter in a vicious state where the first queries have not ended after minutes, and more and more queries are being added to the queue until:
a) Apache runs out of childs/processes, per configuration
b) Mysql runs out of connections, per configuration
c) Linux runs out of memory, and processes crashes/are killed
Not to mention the users or the API client, waiting infinitely for the http request to complete, and other processes reading a partial file (size bigger than 0 but incomplete).
Different strategies can be used to prevent that, like:
a) using semaphores to lock access to the cache generation (only one process at time)
b) using a .lock file to indicate that the file is being generated, and so next requests serving from the cache until the cache generation process ends the task, also writing to a buffer like acachefile.buffer (to prevent incomplete content being read) and finally when is complete renaming to the final name and removing the .lock
c) using memcached, or similar, to keep an index in memory of what pages are being generated now, and why not, keeping the cached files there instead of a filesystem
d) using crons to generate the cache files, so they run hourly and you ensure only one process generates the cache files
If you use crons, a cheap way to generate the .html content is that the crons curls/wget your webpage. I don’t recommend this as has some problems, like if that web request fails for any reason, you’ll have cached an error instead of content.
I prefer preparing my projects to being able of rendering the content being invoked from HTTP/S or from command line. But if you use curl because is cheap and easy and time to market is important for your project, then be sure that you check that your backend code writes an Status OK in the HTML that the cron can check to ensure that the content has been properly generated. (some crons only check for http status, like 200, but if your database or a xml gateway you use fails you will likely get a 200 and won’t detect that you’re caching pages with “error I can’t connect to the database” instead)
Many Frameworks have their own cache implementation that prevent corruption that could come by several processes writing to the same file at the same time, or from PHP dying in the middle of the render.
You can see a more complex MVC implementation, with Views, from my Framework Catalonia here:
By serving .html files instead of executing PHP with logic and performing queries to the database you will be able to serve hundreds of thousands requests per day with a single machine and really fast -that’s important for SEO also-.
I’ve done this in several Start ups with wonderful results, and my Framework Catalonia also incorporates this functionality very easily to use.
Note: This is only one of the techniques to save the load of the Database Servers. Many more come later.
Cache languages to disk
If you have an application that is multi-language, or if your point for the Strings (sections, pages, campaigns..) to be edited by Marketing is the Database, there is no need to query it all the time.
Simply provide a tool to “generate language files”.
Your languages files can be Javascript files loaded by the page, or can be PHP files generated.
For example, the file common_footer_en.php could be generated reading from Database and be like that:
<php
/* Autogenerated English translations file common_footer_en.php
on 2014-08-10 02:22 from the database */
$st_translations['seconds'] = 'seconds';
$st_translations['Time'] = 'Time';
$st_translations['Vars used'] = 'Vars used in these templates';
$st_translations['Total Var replacements'] = 'Total replaced';
$st_translations['Exec time'] = 'Execution time';
$st_translations['Cached controller'] = 'Cached controller';
So the PHP file is going to be generated when someone at your organization updates the languages, and your code is including it normally like with any other PHP file.
Use the Crons
You can set cron jobs to do many operations, like map reduce, counting in the database or effectively deleting the data that the user selected to delete.
Imagine that you have classified portal, and you want to display the number of announces for that category. You can have a table NUM_ANNOUNCES to store the number of announces, and update it hourly. Then your database will only do the counting once per hour, and your application will be reading the number from the table NUM_ANNOUNCES.
The Cron can also be used to make expire old announces. That way you can avoid a user having to wait for that clean up taking process when you have a http request to PHP.
A cron file can be invoked by:
php -f cron.php
By:
./cron.php
If you give permissions of execution with chmod +x and set the first line in cron.php as:
#!/usr/bin/env php
Or you can do a trick, that is emulate a http request from bash, by invoking a url with curl or with wget. Set the .htaccess so the folder for the cron tasks can only be executed from localhost for adding security.
This last trick has the inconvenient that the calling has the same problems as any http requests: restarting Apache will kill the process, the connection can be closed by timed out (e.g. if process is taking more seconds than the max. execution time, etc…)
Use Ramdisk for PHP files
With Linux is very easy to setup a RamDisk.
You can setup a RamDisk and rsync all your web .PHP files at system boot time, and when deploying changes, and config Apache to use the Ramdisk folder for the website.
That way for every request to the web, PHP files will be served from RAM directly, saving the slow disk access. Even with OpCache active, is a great improvement.
At these times were one Gigabyte of memory is really cheap there is a huge difference from reading files from disk, and getting them from memory. (Reading and writing to RAM memory is many many many times faster than magnetic disks, and many times faster than SSD disks)
Also .js, .css, images… can be served from a Ram disk folder, depending on how big your web is.
Ramdisk for /tmp
If your project does operations on disk, like resizing images, compressing files, reading/writing large CSV files, etcetera you can greatly improve the performance by setting the /tmp folder to a Ramdisk.
If your PHP project receives file uploads they will also benefit (a bit) from storing the temporal files to RAM instead to the disk.
Use Cache Lite
Cache Lite is a Pear extension that allows you to keep data in a local cache of the Web Server.
You can cache .html pages, or you can cache Queries and their result.
<?php
require_once "Cache/Lite.php";
$options = array(
'cacheDir' => '/tmp/',
'lifeTime' => 7200,
'pearErrorMode' => CACHE_LITE_ERROR_DIE
);
$cache = new Cache_Lite($options);
if ($data = $cache->get('id_of_the_page')) {
// Cache hit !
// Content is in $data
echo $data;
} else {
// No valid cache found (you have to make and save the page)
$data = '<html><head><title>test</title></head><body><p>this is a test</p></body></html>';
echo $data;
$cache->save($data);
}
It is nice that Cache Lite handles the TTL and keeps the info stored in different sub-directories in order to keep a decent performance. (As you may know many files in the same directory slows the access much).
Use HHVM (HipHop Virtual Machine) from Facebook
Facebook Engineers are always trying to optimize what is run on the Servers.
Faster code means, less machines. Even 1% of CPU use improvement means a lot of Servers less. Less Servers to maintain, less money wasted, less space on the Data Centers…
So they created the HHVM HipHop Virtual Machine that is able to run PHP code, much much faster than PHP. And is compatible with most of the Frameworks and Open Source projects.
They also created the Hack language that is an improved PHP, with type hinting.
So you can use HHVM to make your code run faster with the same Server and without investing a single penny.
Use C extensions
You can create and use your own C extensions.
C extensions will bring really fast execution. Just to get the idea:
I built a PHP extension to compare the performance from calculating the Bernoulli number with PHP and with the .so extension created in C.
In my Core i7 times were:
PHP:
Computed in 13.872583150864 s
PHP calling the C compiled extension:
Computed in 0.038495063781738 s
That’s 360.37 times faster using the C extension. Not bad.
Use Zephir
Zephir is a an Open Source language, very similar to PHP, that allows to create and maintain easily extensions for PHP.
Use Phalcon
Phalcon is a Web MVC Framework implemented as C extension, so it offers a high performance.
Check if you’re using the correct Engine for MySql
Many Developers create the tables and never worry about that. And many are using MyIsam by default. It was the by default Engine prior to MySql 5.5.
While MyIsam can bring good performance in some certain cases, my recommendation is to use InnoDb.
Normally you’ll have a gain in performance with MyIsam if you’ve a table were you only write or only read, but in all the other cases InnoDb is expected to be much more performant and safe.
MyIsam tables also get corruption from time to time and need manually fixing and writing to disks are not so reliable than InnoDb.
As MyIsam uses table-locking for updates and deletes to any existing row, it is easy to see that if you’re in a web environment with multiple users, blocking the table -so the other operations have to wait- will make things be slow.
If you have to use Joins clearly you will benefit from using InnoDb also.
Use InMemory Engine from MySql
MySql has a very powerful Engine called InMemory.
The InMemory Engine will store things in RAM and loss the data when MySql is restarted.
However is very fast and very easy to use.
Imagine that you have a travel application that constantly looks at which country belongs the city specified by user. A Quickwin would be to INSERT all this data in the InMemory Engine of MySql when it is started, and do just one change in your code: to use that Table.
Really easy. Quick improvement.
Use curl asynchronously
If your PHP has to communicate with other systems using curl, you can do the http/s call, and instead of waiting for a response let your PHP do more things in the meantime, and then check the results.
You can also call to multiple curl calls in parallel, and so avoid doing one by one in serial.
Guess that you have a query that returns 1000 results. Then you add one by one to an array.
Probably you’re going to have substantial gain if you keep in the database a single row, with the array serialized.
So an array like:
$st_places = Array(‘Barcelona’, ‘Dublin’, ‘Edinburgh’, ‘San Francisco’, ‘London’, ‘Berlin’, ‘Andorra la Vella’, ‘Prats de Lluçanès’);
Would be serialized to an string like:
a:8:{i:0;s:9:”Barcelona”;i:1;s:6:”Dublin”;i:2;s:9:”Edinburgh”;i:3;s:13:”San Francisco”;i:4;s:6:”London”;i:5;s:6:”Berlin”;i:6;s:16:”Andorra la Vella”;i:7;s:19:”Prats de Lluçanès”;}
This can be easily stored as String and unserialized later back to an array.
Note: In Internet we have a lot of encodings, Hebrew, Japanese… languages. Be careful with encodings when serializing, using JSon, XML, storing in databases without UTF support, etc…
Use Memcached to store common things
Memcached is a NoSql database in memory that can run in cluster.
The idea is to keep things there, in order to offload the load of the database. And as everything is in RAM it really runs fast.
You can use Memcached to cache Queries and their results also.
For example:
You have query SELECT * FROM translations WHERE section=’MAIN’.
Then you look if that String exists as key in the Memcached, and if it exists you fetch the results (that are serialized) and you avoid the query. If it doesn’t exist, you do normally the query to the database, serialize the array and store it in the Memcached with a TTL (Time to Live) using the Query (String) as primary key. For security you may prefer to hash the query with MD5 or SHA-1 and use the hash as key instead of using it plain.
When the TTL is reached the validity of the data would have expired and so it’s time to reinsert the contents in the next query.
Be careful, I’ve seen projects that were caching private data from users without isolating the key properly, so other users were getting the info from other users.
For example, if the key used was ‘Name’ and the value ‘Carles Mateo’ obviously the next user that fetch the key ‘Name’ would get my name and not theirs.
If you store private data of users in Memcache, it is a nice idea to append the owner of that info to the hash. E.g. using key: 10701577-FFADCEDBCCDFFFA10C
Where ‘10701577’ would be the user_id of the owner of the info, and ‘FFADCEDBCCDFFFA10C’ a hash of the query.
Before I suggested that you can keep a table of counting for the announces in a classified portal. This number can be stored in the Memcached instead.
You can store also common things, like translations, or cities like in the example before, rate of change for a currency exchanging website…
The most common way to store things there is serialized or Json encoded.
Be aware of the memory limits of Memcached and contrl the cache hitting ratio to avoid inserting data, and losing it constantly because is used few and Memcached has few memory.
Use jQuery for Production (small file) and minimized files for js
Use the Production jQuery library in Production, I mean do not use the bigger file Development jQuery library for Production.
There are product that eliminate all the necessary spaces in .js and .css files, and so are served much faster. These process is called minify.
It is important to know that in many emerging markets in the world, like Brazil, they have slow DSL lines. Many 512 Kbit/secons, and even modem connections!.
Activate compression in the Server
If you send large text files, or Jsons, you’ll benefit from activating the compression at the Server.
It consumes some CPU, but many times it brings an important improvement in speed serving the pages to the users.
Use a CDN
You can use a Content Delivery Network to offload your Servers from sending plain texts, html, images, videos, js, css…
You can delegate this to the CDN, they have very speedy Internet lines and Servers, so your Servers can concentrate into doing only BackEnd operations.
Please take attention to the documentation, a common mistake is to send Cache Headers to the CDN servers, while they’ll use this headers to set the cache TTL and ignore their web configuration parameters. (For example s-maxage, like: Cache-Control: public, s-maxage=600)
You can take a look at any website by telneting to the port 80 and doing the request manually or easily by using lynx:
lynx -mime_header http://blog.carlesmateo.com | less
Do you need a Framework?
If you’re processing only BackEnd petitions, like in the video games industry, serving API’s, RESTful, etc… you probably don’t need a Framework.
The Frameworks are generic and use much more resources than you’re really need for a fast reply.
Many times using a heavy Framework has a cost of factor times, compared to use simply PHP.
Save database connections until really needed
Many Frameworks create a connection to the Database Server by default. But certain parts of your code application do not require to connect to the database.
For example, validating the data from a form. If there are missing fields, the PHP will not operate with the Database, just return an error via JSon or refreshing the page, informing that the required field is missing.
If a not logged user is requesting the dashboard page, there is no need to open a connection to the database (unless you want to write the access try to an error log in the database).
In fact opening connections by default makes easier for attackers to do DoS attacks.
With a Singleton pattern you can easily implement a Db class that handles this transparently for you.
Scaling out / Multi Server Environment
Memcached session
When you have several Web Servers you’ll need something more flexible than the default PHP handler (that stores to a file in the Web Server).
The most common is to store the Session, serialized, in a Memcached Cluster.
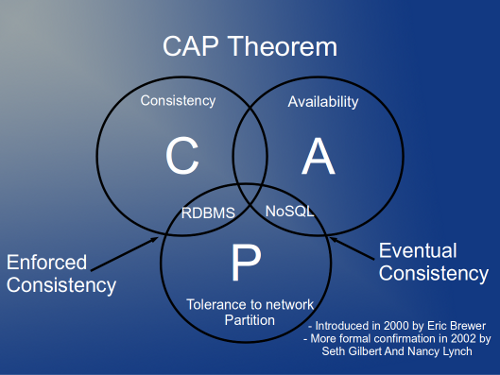
Use Cassandra
Apache Cassandra is a NoSql database that allows to Scale out very easily.
The main advantage is that scales linearly. If you have 4 nodes and add 4 more, your performance will be doubled. It has no single point of failure, is also resilient to node failures, it replicates the data among the nodes, splits the load over the nodes automatically and support distributed datacenter architectures.
A easy way to split the load is to have a MySql primary Server, that handles the writes, and MySql secondary (or Slave) Servers handling the reads.
Every write sent to the Master is replicated into the Slaves. Then your application reads from the slaves.
You have to tell your code to do the writes to database to the primary Server, and the reads to the secondaries. You can have a Load Balancer so your code always ask the Load Balancer for the reads and it makes the connection to the less used server.
Do Database sharding
To shard the data consist into splitting the data according to a criteria.
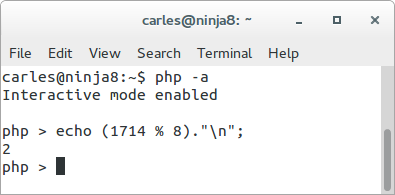
For example, imagine we have 8 MySql Servers, named mysql0 to mysql7. If we want to insert or read data for user 1714, then the Server will be chosen from dividing the user_id, so 1714, between the number of Servers, and getting the MOD.
So 1714 % 8 gives 2. This means that the MySql Server to use is the mysql2.
For the user_id 16: 16 & 8 gives 0, so we would use mysql0. And so.
You can shard according to the email, or other fields as well. And you can have the same master and secondaries for the shards also.
When doing sharding in MySql you cannot do joins to data in other Servers. (but you can replicate all the data from the several shards in one big server in house, in your offices, and so query it and join if you need that for marketing purposes).
I always use my own sharding, but there is a very nice product from CodeFutures called dbshards. It handles the traffics transparently. I used it when in a video games Start up with very satisfying result.
Use Cassandra assync queries
Cassandra support asynchronous queries. That means you can send the query to the Server, and instead of waiting, do other jobs. And check for the result later, when is finished.
Consider using Hadoop + HBASE
A Cluster alternative to Cassandra.
Use a Load Balancer
You can put a Load Balancer or a Reverse Proxy in front of your Web Servers. The Load Balancer knows the state of the Web Servers, so it will remove a Web Server from the Array if it stops responding and everything will continue being served to the users transparently.
There are many ways to do Load Balancing: Round Robin, based on the load on the Web Servers, on the number of connections to each Web Server, by cookie…
To use a Cookie based Load Balancer is a very easy way to split the load for WordPress and Drupal Servers.
Imagine you have 10 Web Servers. In the .htaccess they set a rule to set a Cookie like:
SERVER_ID=WEB01
That was in the case of the first Web Server.
Second Server would have in the .htaccess to set a Cookie like:
SERVER_ID=WEB02
Etcetera
When for first time an user connects to the Load Balancer it sends the user to one of the 10 Web Servers. Then the Web Server sends its cookie to the browser of the Client. E.g. WEB07
After that, in the next requests from the client it will be redirected to the server by the Load Balancer to the Server that set the Cookie, so in this example WEB07.
The nice thing of this way of splitting the traffic is that you don’t have to change your code, nor handling the Sessions different.
If you use two Load Balancers you can have a heartbeat process in them and a Virtual Ip, and so in case your main Load Balancer become irresponsible the Virtual Ip will be mapping to the second Load Balancer in milliseconds. That provides HA.
Use http accelerators
Nginx, varnish, squid… to serve static content and offload the PHP Web Servers.
Auto-Scale in the Cloud
If you use the Cloud you can easily set Auto-Scaling for different parts of your core.
A quick win is to Scale the Web Servers.
As in the Cloud you pay per hour using a computer, you will benefit from cost reduction in you stop using the servers when you don’t need them, and you add more Servers when more users are coming to your sites.
Video game companies are a good example of hours of plenty use and valleys with few users, although as users come from all the planet it is most and most diluted.
Actually the Performance of the Google Cloud to Scale without any precedent is great.
Opposite to other Clouds that are based on instances, Google Cloud offers the platform, that will spawn your code across so many servers as needed, transparently to you. It’s a black box.
Schedule operations with RabbitMQ
Or other Queue Manager.
The idea is to send the jobs to the Queue Manager, the PHP will continue working, and the jobs will be performed asynchronously and notify the end.
RabbitMQ is cool also because it can work in cluster and HA.
Use GlusterFs for NAS
GlusterFs (and other products) allow you to have a Distributed File System, that splits the load and the data across the Servers, and resist node failures.
If you have to have a shared folder for the user’s uploads, for example for the profile pictures, to have the PHP and general files locally in the Servers and the Shared folder in a GlusterFs is a nice option.
Avoid NFS for PHP files and config files
As told before try to have the PHP files in a RAM disk, or in the local disk (Linux caches well and also OpCache), and try to not write code that reads files from disk for determining config setup.
I remember a Start up incubator that had a very nice Server, but the PHP files were read from a mounted NFS folder.
That meant that on every request, the Server had to go over the network to fetch the files.
Sadly for the project’s performance the PHP was reading a file called ENVIRONMENT that contained “PROD” or “DEVEL”. And this was done in every single request.
Even worst, I discovered that the switch connecting the Web Server and the NFS Server was a cheap 10 Mbit one. So all the traffic was going at 10 Mbit/s. Nice bottleneck.
Improve your network architecture
You can use 10 GbE (10 Gigabit Ethernet) to connect the Servers. The Web Servers to the Databases, Memcached Cluster, Load Balancers, Storage, etc…
You will need 10 GbE cards and 10 GbE switchs supporting bonding.
Use bonding to aggregate 10 + 10 so having 20 Gigabit.
You can also use Fibre Channel, for example 10 Gb and aggregate them, like 10 + 10 so 20 Gbit for the connection between the Servers and the Storage.
The performance improvements that your infrastructure will experiment are amazing.
We architects, developers and start ups are facing new challenges.
We have now to create applications that have to scale and scale at world-wide level.
That puts over the table big and exciting challenges.
To allow that increasing level of scaling, we designed and architect tools and techniques and tricks, but fortunately now there are great products born to scale out and to deal with this problems: like NoSql databases like Cassandra, MongoDb, Riak, Hadoop’s Hbase, Couchbase or CouchDb, NoSql in-Memory like Memcached or Redis, big data solutions like Hadoop, distributed files systems like Hadoop’s HDFS, GlusterFs, Lustre, etc…
In this article I will cover the first steps to develop with Cassandra, under the Developer point of view.
As a first view you may be interested in Cassandra because:
Is a Database with no single point of failure
Where all the Database Servers work in Peer to Peer over Tcp/Ip
Fault-tolerance. You can set replication factor, and the data will be sharded and replicated over different servers and so being resilient to node failures
Because the Cassandra Cluster splits and balances the work across the Cluster automatically
Because you can scale by just adding more nodes to the Cluster, that’s scaling horizontally, and it’s linear. If you double the number of servers, you double the performance
Because you can have cool configurations like multi-datacenter and multi-rack and have the replication done automatically
You can have several small, cheap, commodity servers, with big SATA disks with better result than one very big, very expensive, and unable-to-scale-more server with SSD or SAS expensive disks.
It has the CQL language -Cassandra Query Language-, that is close to SQL
Ability to send querys in async mode (the CPU can do other things while waiting for the query to return the results)
Cassandra is based in key/value philosophy but with columns. It supports multiple columns. That’s cool, as theoretically it supports 2 GB per column (at practical level is not recommended to go with data so big, specially in multi-user environments).
I will not lie to you: It is another paradigm, and comes with a lot of knowledge to acquire, but it is necessary and a price worth to pay for being able of scaling at nowadays required levels.
Cassandra only offers native drivers for: Java, .NET, C++ and Python 2.7. The rest of solutions are contributed, sadly most of them are outdated and unmantained.
Cassandra has no PHP driver officially, but has some contributed solutions.
By myself I created several solutions: CQLSÍ uses cqlsh to perform queries and interfaces without needing Thrift, and Cassandra Universal Driver is a Web Gateway that I wrote in Python that allows you to query Cassandra from any language, and recently I contributed to a PHP driver that speaks the Cassandra binary protocol (v1) directly using Tcp/Ip sockets.
That’s the best solution for me by now, as it is the fastest and it doesn’t need any third party library nor Thrift neither.
KeySpace is the equivalent to a database in MySQL.
<?php
require_once 'Cassandra/Cassandra.php';
$o_cassandra = new Cassandra();
$s_server_host = '127.0.0.1'; // Localhost
$i_server_port = 9042;
$s_server_username = ''; // We don't use username
$s_server_password = ''; // We don't use password
$s_server_keyspace = ''; // We don't have created it yet
$o_cassandra->connect($s_server_host, $s_server_username, $s_server_password, $s_server_keyspace, $i_server_port);
// Create a Keyspace with Replication factor 1, that's for a single server
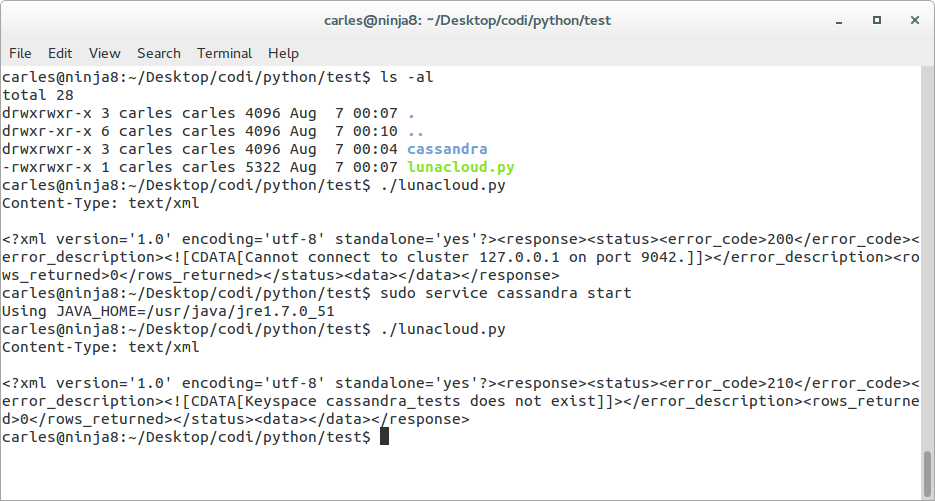
$s_cql = "CREATE KEYSPACE cassandra_tests WITH REPLICATION = { 'class': 'SimpleStrategy', 'replication_factor': 1 };";
$st_results = $o_cassandra->query($s_cql);
We can run it from web or from command line by using:
If we don’t plan to insert UTF-8 strings, we can use VARCHAR instead of TEXT type.
Do an insert
In this sample we create an Array of 100 elements, we serialize it, and then we store it.
<?php
require_once 'Cassandra/Cassandra.php';
// Note this code uses the MT notation http://blog.carlesmateo.com/maria-teresa-notation-for-php/
$i_start_time = microtime(true);
$o_cassandra = new Cassandra();
$s_server_host = '127.0.0.1'; // Localhost
$i_server_port = 9042;
$s_server_username = ''; // We don't have username
$s_server_password = ''; // We don't have password
$s_server_keyspace = 'cassandra_tests';
$o_cassandra->connect($s_server_host, $s_server_username, $s_server_password, $s_server_keyspace, $i_server_port);
$s_time = strval(time()).strval(rand(0,9999));
$s_date_time = date('Y-m-d H:i:s');
// An array to hold a emails
$st_data_emails = Array();
for ($i_bucle=0; $i_bucle<100; $i_bucle++) {
// Add a new email
$st_data_emails[] = Array('datetime' => $s_date_time,
'id_email' => $s_time);
}
// Serialize the Array
$s_data_emails = serialize($st_data_emails);
$s_cql = "INSERT INTO carles_test_table (s_thekey, s_column1, s_column2)
VALUES ('first_sample', '$s_data_emails', 'Some other data');";
$st_results = $o_cassandra->query($s_cql);
$o_cassandra->close();
print_r($st_results);
$i_finish_time = microtime(true);
$i_execution_time = $i_finish_time-$i_start_time;
echo 'Execution time: '.$i_execution_time."\n";
echo "\n";
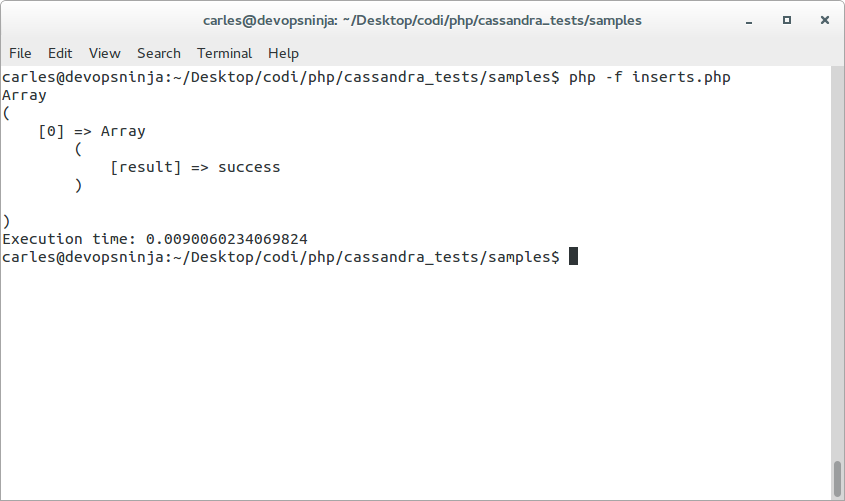
This insert took Execution time: 0.0091850757598877 seconds executed from CLI (Command line).
If the INSERT works well you’ll have a [result] => ‘success’ in the resulting array.
Do some inserts
Here we do 9000 inserts.
<?php
require_once 'Cassandra/Cassandra.php';
// Note this code uses the MT notation http://blog.carlesmateo.com/maria-teresa-notation-for-php/
$i_start_time = microtime(true);
$o_cassandra = new Cassandra();
$s_server_host = '127.0.0.1'; // Localhost
$i_server_port = 9042;
$s_server_username = ''; // We don't have username
$s_server_password = ''; // We don't have password
$s_server_keyspace = 'cassandra_tests';
$o_cassandra->connect($s_server_host, $s_server_username, $s_server_password, $s_server_keyspace, $i_server_port);
$s_date_time = date('Y-m-d H:i:s');
for ($i_bucle=0; $i_bucle<9000; $i_bucle++) {
// Add a sample text, let's use time for example
$s_time = strval(time());
$s_cql = "INSERT INTO carles_test_table (s_thekey, s_column1, s_column2)
VALUES ('$i_bucle', '$s_time', 'http://blog.carlesmateo.com');";
// Launch the query
$st_results = $o_cassandra->query($s_cql);
}
$o_cassandra->close();
$i_finish_time = microtime(true);
$i_execution_time = $i_finish_time-$i_start_time;
echo 'Execution time: '.$i_execution_time."\n";
echo "\n";
Those 9,000 INSERTs takes 6.49 seconds in my test virtual machine, executed from CLI (Command line).
Do a Select
<?php
require_once 'Cassandra/Cassandra.php';
// Note this code uses the MT notation http://blog.carlesmateo.com/maria-teresa-notation-for-php/
$i_start_time = microtime(true);
$o_cassandra = new Cassandra();
$s_server_host = '127.0.0.1'; // Localhost
$i_server_port = 9042;
$s_server_username = ''; // We don't have username
$s_server_password = ''; // We don't have password
$s_server_keyspace = 'cassandra_tests';
$o_cassandra->connect($s_server_host, $s_server_username, $s_server_password, $s_server_keyspace, $i_server_port);
$s_cql = "SELECT * FROM carles_test_table LIMIT 10;";
// Launch the query
$st_results = $o_cassandra->query($s_cql);
echo 'Printing 10 rows:'."\n";
print_r($st_results);
$o_cassandra->close();
$i_finish_time = microtime(true);
$i_execution_time = $i_finish_time-$i_start_time;
echo 'Execution time: '.$i_execution_time."\n";
echo "\n";
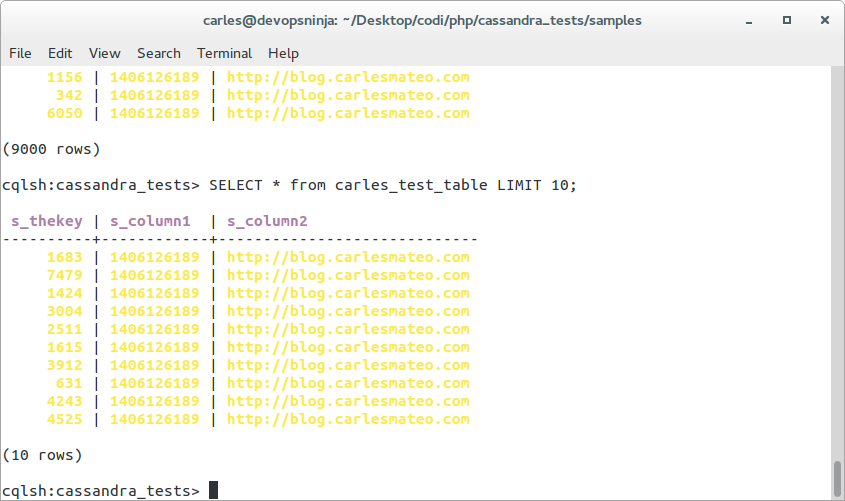
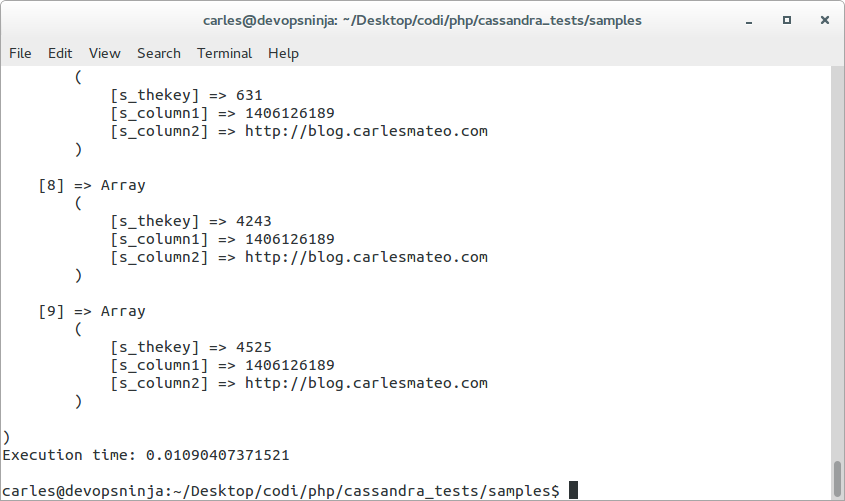
Printing 10 rows passing the query with LIMIT:
$s_cql = "SELECT * FROM carles_test_table LIMIT 10;";
echoing as array with print_r takes Execution time: 0.01090407371521 seconds (the cost of printing is high).
If you don’t print the rows, it takes only Execution time: 0.00714111328125 seconds.
Selecting 9,000 rows, if you don’t print them, takes Execution time: 0.18086194992065.
Java
The official driver for Java works very well.
The only initial difficulties may be to create the libraries required with Maven and to deal with the different Cassandra native data types.
To make that travel easy, I describe what you have to do to generate the libraries and provide you with a Db Class made by me that will abstract you from dealing with Data types and provide a simple ArrayList with the field names and all the data as String.
Datastax provides the pom.xml for maven so you’ll create you jar files. Then you can copy those jar file to Libraries folder of any project you want to use Cassandra with.
My Db class:
/*
* By Carles Mateo blog.carlesmateo.com
* You can use this code freely, or modify it.
*/
package server;
import java.util.ArrayList;
import java.util.List;
import com.datastax.driver.core.*;
/**
* @author carles_mateo
*/
public class Db {
public String[] s_cassandra_hosts = null;
public String s_database = "cchat";
public Cluster o_cluster = null;
public Session o_session = null;
Db() {
// The Constructor
this.s_cassandra_hosts = new String[10];
String s_cassandra_server = "127.0.0.1";
this.s_cassandra_hosts[0] = s_cassandra_server;
this.o_cluster = Cluster.builder()
.addContactPoints(s_cassandra_hosts[0]) // More than 1 separated by comas
.build();
this.o_session = this.o_cluster.connect(s_database); // This is the KeySpace
}
public static String escapeApostrophes(String s_cql) {
String s_cql_replaced = s_cql.replaceAll("'", "''");
return s_cql_replaced;
}
public void close() {
// Destructor calles by the garbagge collector
this.o_session.close();
this.o_cluster.close();
}
public ArrayList query(String s_cql) {
ResultSet rows = null;
rows = this.o_session.execute(s_cql);
ArrayList st_results = new ArrayList();
List<String> st_column_names = new ArrayList<String>();
List<String> st_column_types = new ArrayList<String>();
ColumnDefinitions o_cdef = rows.getColumnDefinitions();
int i_num_columns = o_cdef.size();
for (int i_columns = 0; i_columns < i_num_columns; i_columns++) {
st_column_names.add(o_cdef.getName(i_columns));
st_column_types.add(o_cdef.getType(i_columns).toString());
}
st_results.add(st_column_names);
for (Row o_row : rows) {
List<String> st_data = new ArrayList<String>();
for (int i_column=0; i_column<i_num_columns; i_column++) {
if (st_column_types.get(i_column).equals("varchar") || st_column_types.get(i_column).equals("text")) {
st_data.add(o_row.getString(i_column));
} else if (st_column_types.get(i_column).equals("timeuuid")) {
st_data.add(o_row.getUUID(i_column).toString());
} else if (st_column_types.get(i_column).equals("integer")) {
st_data.add(String.valueOf(o_row.getInt(i_column)));
}
// TODO: Implement other data types
}
st_results.add(st_data);
}
return st_results;
}
public static String getFieldFromRow(ArrayList st_results, int i_row, String s_fieldname) {
List<String> st_column_names = (List)st_results.get(0);
boolean b_column_found = false;
int i_column_pos = 0;
for (String s_column_name : st_column_names) {
if (s_column_name.equals(s_fieldname)) {
b_column_found = true;
break;
}
i_column_pos++;
}
if (b_column_found == false) {
return null;
}
int i_num_columns = st_results.size();
List<String> st_data = (List)st_results.get(i_row);
String s_data = st_data.get(i_column_pos);
return s_data;
}
}
Python 2.7
There is no currently driver for Python 3. I requested Datastax and they told me that they are working in a new driver for Python 3.
The problem is the same as with Java, the different data types are hard to deal with.
So I created a function convert_to_string that converts known data types to String, and so later we will only deal with Strings.
In this sample, the results of the query are rendered in xml or in html.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# Use with Python 2.7+
__author__ = 'Carles Mateo'
__blog__ = 'http://blog.carlesmateo.com'
import sys
from cassandra import ConsistencyLevel
from cassandra.cluster import Cluster
from cassandra.query import SimpleStatement
s_row_separator = u"||*||"
s_end_of_row = u"//*//"
s_data = u""
b_error = 0
i_error_code = 0
s_html_output = u""
b_use_keyspace = 1 # By default use keyspace
b_use_user_and_password = 1 # Not implemented yet
def return_success(i_counter, s_data, s_format = 'html'):
i_error_code = 0
s_error_description = 'Data returned Ok'
return_response(i_error_code, s_error_description, i_counter, s_data, s_format)
return
def return_error(i_error_code, s_error_description, s_format = 'html'):
i_counter = 0
s_data = ''
return_response(i_error_code, s_error_description, i_counter, s_data, s_format)
return
def return_response(i_error_code, s_error_description, i_counter, s_data, s_format = 'html'):
if s_format == 'xml':
print ("Content-Type: text/xml")
print ("")
s_html_output = u"<?xml version='1.0' encoding='utf-8' standalone='yes'?>"
s_html_output = s_html_output + '<response>' \
'<status>' \
'<error_code>' + str(i_error_code) + '</error_code>' \
'<error_description>' + '<![CDATA[' + s_error_description + ']]>' + '</error_description>' \
'<rows_returned>' + str(i_counter) + '</rows_returned>' \
'</status>' \
'<data>' + s_data + '</data>' \
'</response>'
else:
print("Content-Type: text/html; charset=utf-8")
print("")
s_html_output = str(i_error_code)
s_html_output = s_html_output + '\n' + s_error_description + '\n'
s_html_output = s_html_output + str(i_counter) + '\n'
s_html_output = s_html_output + s_data + '\n'
print(s_html_output.encode('utf-8'))
sys.exit()
return
def convert_to_string(s_input):
# Convert other data types to string
s_output = s_input
try:
if value is not None:
if isinstance(s_input, unicode):
# string unicode, do nothing
return s_output
if isinstance(s_input, (int, float, bool, set, list, tuple, dict)):
# Convert to string
s_output = str(s_input)
return s_output
# This is another type, try to convert
s_output = str(input)
return s_output
else:
# is none
s_output = ""
return s_output
except Exception as e:
# Were unable to convert to str, will return as empty string
s_output = ""
return s_output
def convert_to_utf8(s_input):
return s_input.encode('utf-8')
# ********************
# Start of the program
# ********************
s_format = 'xml' # how you want this sample program to output
s_cql = 'SELECT * FROM test_table;'
s_cluster = '127.0.0.1'
s_port = "9042" # default port
i_port = int(s_port)
b_use_keyspace = 1
s_keyspace = 'cassandra_tests'
if s_keyspace == '':
b_use_keyspace = 0
s_user = ''
s_password = ''
if s_user == '' or s_password == '':
b_use_user_and_password = 0
try:
cluster = Cluster([s_cluster], i_port)
session = cluster.connect()
except Exception as e:
return_error(200, 'Cannot connect to cluster ' + s_cluster + ' on port ' + s_port + '.' + e.message, s_format)
if (b_use_keyspace == 1):
try:
session.set_keyspace(s_keyspace)
except:
return_error(210, 'Keyspace ' + s_keyspace + ' does not exist', s_format)
try:
o_results = session.execute_async(s_cql)
except Exception as e:
return_error(300, 'Error executing query. ' + e.message, s_format)
try:
rows = o_results.result()
except Exception as e:
return_error(310, 'Query returned result error. ' + e.message, s_format)
# Query returned values
i_counter = 0
try:
if rows is not None:
for row in rows:
i_counter = i_counter + 1
if i_counter == 1 and s_format == 'html':
# first row is row titles
for key, value in vars(row).iteritems():
s_data = s_data + key + s_row_separator
s_data = s_data + s_end_of_row
if s_format == 'xml':
s_data = s_data + ''
for key, value in vars(row).iteritems():
# Convert to string numbers or other types
s_value = convert_to_string(value)
if s_format == 'xml':
s_data = s_data + '<' + key + '>' + '<![CDATA[' + s_value + ']]>' + ''
else:
s_data = s_data + s_value
s_data = s_data + s_row_separator
if s_format == 'xml':
s_data = s_data + ''
else:
s_data = s_data + s_end_of_row
except Exception as e:
# No iterable data
return_success(i_counter, s_data, s_format)
# Just print the data
return_success(i_counter, s_data, s_format)
If you did not create the namespace like in the samples before, change those lines to:
As mentioned above if you use a language Tcp/Ip enabled very new, or very old like ASP or ColdFusion, or from Unix command line and you want to use it with Cassandra, you can use my solution http://www.cassandradriver.com/.
It is basically a Web Gateway able to speak XML, JSon or CSV alike. It relies on the official Datastax’s python driver.
It is not so fast as a native driver, but it works pretty well and allows you to split your architecture in interesting ways, like intermediate layers to restrict even more security (For example WebServers may query the gateway, that will enstrict tome permissions instead of having direct access to the Cassandra Cluster. That can also be used to perform real-time map-reduce operations on the amount of data returned by the Cassandras, so freeing the webservers from that task and saving CPU).
Tip: If you use Cassandra for Development only, you can limit the amount of memory used by editing the file /etc/cassandra/cassandra-env.sh and hardcoding:
# limit the memory for development environment
# --------------------------------------------
system_memory_in_mb="512"
system_cpu_cores="1"
# --------------------------------------------
Just before the line:
# set max heap size based on the following
That way Cassandra will believe your system memory is 512 MB and reserve only 256 MB for its use.
The first one was between people not knowing about IT and those knowing, but we’re living another between IT guys being unable to Scale and those being able to Scale well.
Few years ago I was working all the time with Relational Databases. Designing cool relational Schemas for amazing projects. I had work for years with Oracle, Microsoft Sql Server, Informix, Dbase, Trees, Xml, and in the last times with PostgreSql and MySql.
I was doing a lot of improvements to MySql installations to allow Scaling and Scaling more, to bring more reliability, to improve performance, to allow more sessions… in definitive to fit the needs of the businesses in a challenging world that demanded more and more avility to handle more and more users.
Master Master, Master with secondaries for read, cluster of memcached or redis to use as cache, database sharding, Ip’s fail over, load balancers, additional indexes, InMemory engines, Ramdisks… everything that could help to match an increase on the load volumes.
I used commercial products like Code Futures dbshards, I created my own database sharding solution, in order to split the data to severl MySql servers, etc..
Artisan’s setup and a lot of studying and testing, everything to Scale to the needs of the companies, to handle more and more traffic, more and more users…
And I was proud of my level. Since I was able of suceed where few were able.
But now that is not needed anymore.
Basically the NoSql systems were born to deal with the actual problems.
NoSql servers -take in mind that the term comprises a lot of different solutions- were born to:
Work in cluster
Split the load among the cluster
Work in cheap commodity servers (or small cloud instances)
Resistance to failure: Allow the destruction of some nodes without data loss
Work with nodes at distant-location datacenters
There are many different NoSql Softwares like: Cassandra, Hadoop, MongoDb, Riak, Neo4J, Redis…
And they do auto-sharding of the data, distribute the data across the network to fit the replication factor set, support load balancing, and in the case of Cassandra Scaling horizontally is so easy like adding more nodes to the Cassandra Cluster.
So yes, believe it. That’s why I write this article. So you can improve your projects and save tons of money.
Databases like Cassandra allow you to Scale so easily like adding new nodes. It is a peer to peer cluster with no single point of failure. All the nodes know the status of the other nodes and they distribute the load.
You can query all the time the same server, but it will be splitting the load among the other servers.
NoSql like hadoop allows you to create a large filesystem in cluster, with as-big-as-all-the-cluster files, but the best quality of HDFS is that it balances the load, and replicates the blocks of data among different servers, so if you loss nodes of the cluster and you have enough replication factor you’ll not loss data. I know companies in Barcelona with 500+ TB in HDFS and companies in the States with thousands of nodes.
So unlike most people believes, NoSql is not about how the information is stored in the database: Schemaless. (* take a look at Graph NoSql databases for relations in NoSql)
NoSql has not an Schema in the traditional sense of Relational Databases, but it has aggregation, columns, supercolumns, or documents depending on the solution, and the design has impact on the performance, but the principal virtue of the NoSql systems is that they were born to work in cluster, to distribute the load, to be resilent to errors and to Scale.
I’ve seen many Startups suffering problems of overloaded MySql databases, but it happens that nothing of this will happen with NoSql like Cassandra, or MongoDb.
Before they were scaling vertically the MySql server, so adding more Ram, adding more CPU, having better disks, until it was impossible to upgrade more. And if sharding was not possible due to joins, the project was in serious trouble.
But with NoSql you can have, instead of an expensive very powerful server, 5 really cheap servers, and it could be faster, cheaper, resilent to errors, with a better uptime. And if you want to Scale simply add more cheap servers.
The most important of this article has been said, so you can start to look at NoSql solutions.
For bonus, I add a list of NoSql’s and the kind of Data Model that they have:
Supports a REST API through HTTP and Protocol Buffers for basic PUT, GET, POST, and DELETE. MapReduce with native Javascript and Erlang. In multi-datacenter replication, one cluster acts as a “primary cluster”.
AT&T, AOL, Ask.com, Best Buy, Boeing, Bump, Braintree, Comcast, DataPipe, Gilt Group, UK National Health Services (NHS), OpenX, Rovio, Symantec, TBS, The Weather Channel, WorkDay, Voxer, Yahoo! Japan, Yandex
I can’t miss to mention hadoop, that is a NoSql that does not match the categories of Data Storage up, because is a Framework for the distributed processing of large data sets across clusters, so a monster, being able to do many many things and to distribute loads across its nodes. The most well-known components are HDFS, the distributed filesystem, and Map-Reduce: a simple to develop YARN-based system for parallel processing of large data sets across the clusters. All the big companies like Netflix, Amazon, Yahoo, etc… are using Hadoop. Often synomym when talking about BigData.
Hadoop is a world itself, and the many projects surrounding, but is worth, because allow incredible possibilities to distribute loads and to Scale.
Hadoop has a single point of failure in the namenode, that stores the name of the files of the HDFS in RAM, but solutions like MapR have overcome this.
Don’t get me wrong. Relational databases are wonderful, very useful, support transactions, stored procedures, have been tested for years, focused on consistency, and are very reliable.
Simply they don’t allow to Scale according to our current needs, while NoSql opens a wonderful world of easy, nearly infinite, Scaling.
As you see Open Source is ruling the world. :)
Companies are still sleeping and not supporting NoSql. I’m particularly disappointed with Open Source CMS that are still based on Relational Models, and are very hard to Scale. Drupal, WordPress, Joomla… and e-Commerces like Magento, osCommerce… and plugins for the CMS mentioned (uberkart, woocommerce, virtuemart…) need to be ported to NoSql urgently. (Although some partial support exists in some solutions, it is not fully supported)
That’s why I’ve started to create a very simple Open Source CMS based on NoSql. To help companies and bloggers that can’t Scale more their sites.