Article created on: 1528997557 | 2018-06-14 18:32:15 IST
Recently a mentor of the UCC university came to visit me to my office, in order to do the following of one of the members of my Team, an intern.
Conversation was well, and then at some point he asked what courses could do the university teach to their students in order to be more prepared for working with us.
The Head of Business Development, that was in the meeting with me, mentioned something interesting:
– Make the publish their best code in github, bitbucket or similar git repository, and maintain it. It is like a CV.
He pointed that some of the students sent me their repository page, and they have not committed a thing for more than a year. And usually the code that I find there is less than a tic-tac-toe exercise.
– Obviously, to have git experience.
– Having contributed to an Open Source project
I exposed some things that would be helpful to have in the interns and grads that I hire:
– git experience
– Python programming
– C programming
– Unit Testing experience
– Networking experience, in particular iSCSI exports, tcpdump
– Programming Best practices, PEP-8 at least for Python
– Usage of Professional Tools like PyCharm, JetBrains IntelliJ, PHPStorm, Code Lion, Netbeans, Eclipse
– Linux experience. Many of them use Windows at home cause they also play video games. Really few programmers in real life use windows. So at least guys install Virtual Box or VMWare and run Linux in an Virtual Machine.
– Cloud experience. Using instances, CDNs, APIs, tools…
And as the talking advanced I gave him a hint of the Epic fail that all the universities are committing.
They teach git for a semester. They teach Python for one or two semester, the first year usually one, the second year another. And that’s it. Is gone.
When they exit the university they have not programmed in Python for 2 or 3 years, they have not used git, they have not used SQL for the same amount of time, etc…
My boss pointed that the best candidates do side projects in their spare time, and have that bright in their eyes. That sparkling in the eyes is what I call the eye of the tiger, the desire to improve, to learn. That spark.
I told the mentor of my intern that the big mistake is doing things in small parcels, isolated, one block and is gone. That the best way to proceed would be to:
Make the student start a project from the very beginning, from the first semester. Then keep making it bigger and better over time.
Let them improve it over time. Screw it in all the ways possible. Make them reach the limits of their initial architecture. Allow them to face having to redo the thing from the scratch. Allow them to do screw it, to break things, and to learn from their mistakes. Over and over.
Nobody becomes a great programmer coding average things for two semesters.
But let them realize where the problems are. Let them come back to their code of two or three months ago, before holidays, and realize how important is to make comments, to give proper names to the files and to the variables. Let them run that project over so many time, that at some point they have to change computer and they realize that what worked with windows Uppercases and Lowercase mixed files, does not work with Unix (case sensitive).
Let them grow.
Let them see their mistakes over the time.
Let them run the project for so long so they switch several times from Cloud provider, and discover the pros and the cons and the not-to-do, and things like run for your life before using sharing hostings that limit your CPU quota even that kills your MySql instances when they look at the email (true history, connecting to POP3 was raising the CPU and the provider was killing the MySQL instances, and so the queries) or that limits your queries per second, and then ask them to install a drupal and they will learn the hard way why Quality is always better than price and will make the right decisions when they work for somebody else or for their own Startup.
Even many of the supposedly Senior guys never learned from their mistakes, for example the Outsourcing guys, cause they work 6 months to a year in a project and then jump to another. Nobody explains the hell in maintenance and incidental they have left there. Nobody teach them.
Programming an small project for 6 months doesn’t make a master. Doing it for 5 years, growing it, learning from your mistakes and learning the YES and DO-NOT the hard way, the real way that works, cause makes you understand why something is better than other things, is the path.
That also remembers me why I love the MT Notation and many of the guys in Barcelona that saw it criticized the method, while my colleagues at Facebook and Dropbox actually told me that they use it, specially for Python and C/C++.
Allow them to thing about how to solve sorting a list of 1000 items by themselves. Let them think. The lazy will copy, but they will not grow.
Then let them implement a Bubble sort. Let them improve it, if they can. Allow them a week to try to improve that. Then make them sort 1,000,000 items so they see that is bloody slow. How can I improve that?. May I read the data from the drive at once, reading line by line was slow… let them think. Like if they were learning Martial Arts, and so discovering their strengths, that they have fast reflexes, allow them to grow.
Universities have to create good professional, not just machines of passing the exams. Real world demands talent, problem solving abilities, passion, ability to learn, and will to do the things well and to improve, and discipline.
After 5-6 years of programming on a daily basis, with an IDE, git, deploying to the Cloud as the basic, and growing a program and seeing the downsides of the solutions chosen, observing that the caveats where for a reason, learning that the Hardware is important, that is not the same to write to memory that to disk or to network, detecting the problems, redoing things, ending in a cul-de-sac, fixing, improving, learning, growing the project, growing himself/herself as a mind, as a programmer, as a thinker, as an expert, daily, even if it’s 30 minutes per day, then that person is prepared for some serious business.
Like piano, guitar, painting, writing… and any other activity, one require continue training in order to improve.
Students have to follow a journey in order to improve.
Let them start with Command Line, i.e. in C and files. Let’s do add later database support.
Deal with buffer overflow, file descriptor, locks and conversion types. Let them migrate to another language the entire project, using Git from the beginning.
Let them migrate again when they need to add Web support. Allow them to discover that instead of reloading all the page they can use Ajax/JSON. Let them deal with click-click that many common users do on the page buttons (so they submit twice the information). To discover SQL Injections. To use a Web Framework. To add Unit Testing. Add some improvement via Javascript Frameworks like responsive for mobiles.
Allow them to use a new Database, new Webserver or technology that is fashion and everybody on Twitter talks about, so it crashes in their face. And so they discover that they will not play or discover new technologies in actual project time in the Company of their future employers, cause shit happens, and impacts the Schedule, and the Company loses money. Universities: Teach them, let the students learn this for themselves, rather than screwing it up in several companies after university.
Here is my proposal for sorting much, much faster than quicksort.
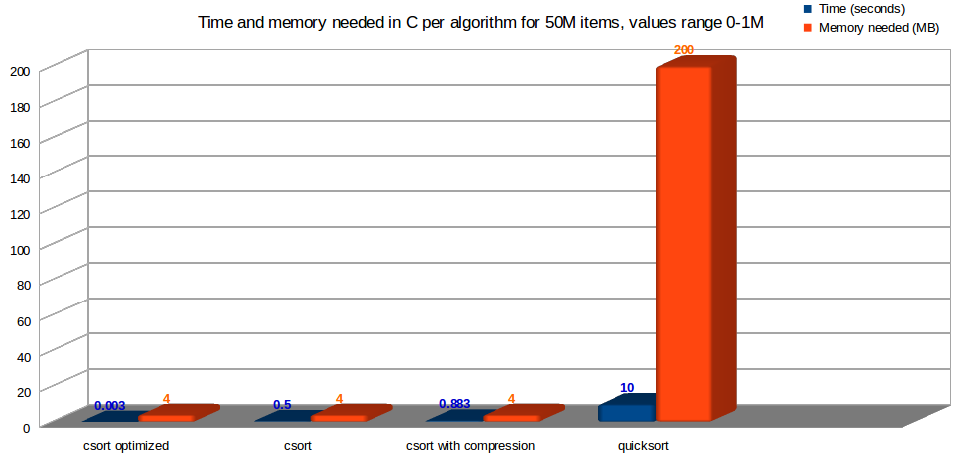
Time and memory consumption in C, for my algorithm csort, versus quicksort, with an universe of 50 Million registers, with values duplicated from 0 to 1,000,000. Less is better
All the algorithms must be checked with different universes of data and their utility is limited to some situations. I explain here the algorithm, show the logic behind code in C, in PHP and Java, the metricas, push the boundaries of the computer… and test against different sets of data looking for the big-O. I prove how much more perfomant it is and explain everything.
This article is complex, is intended for very Senior Engineers at huge companies that need to handle very big data.
The code is written in C to be sure that we compare everything in the same order of magnitude and to avoid optimizations from the compilers / precompilers / Just in Time engines that could bias the conclusions, and so knowing that we are playing fair, but there is a porting to PHP so everyone can understand the algorithm and there are some utilities written in PHP as well. I’ll also explain certain interesting things about PHP internal functions and how it handles memory, and other goodies about C. Finally the code is also available in Java, and is possible to observe how clearly my csort beats quicksort and how fast que JIT compiler performs. Perhaps you can be interested into reading my previous article performance of several languages.
We need a huge amount of data in order to be able to demonstrate the time differences clearly.
Some of the PHP tests and proves require you to have a decent computer with at least 16 GB of RAM. You can skip those or reduce the magnitude of the set of data, or simply use C.
Take this article as an intellectual entertainment, although I think you will discover this useful algorithm / technique of mine will allow you to sort much faster than quicksort in most of the cases I can imagine, and so you will have another tool in your set of resources for sorting fast and dealing with heavy data structures.
Problem
An initial intellectual problem description to enter into matter:
Having a set of 50,000,000 numbers, with values possible between 0 and 1,000,000:
Sort them and eliminate duplicates as fast as possible
To be fair and trustworthy the numbers will be generated and saved to disk, and the same set of numbers will be used for comparing between all the algorithms and tests and when checking with different languages.
Generating the numbers
For this test I created an array of numeric items.
I created a .txt file filled with the numbers, and then I load the same set of numbers for all the tests so all the numbers are always the same and results cannot be biased by a random set very lucky for the algorithm to sort.
I’ve generated several universes of tests, that you can download.
50 Million results, with values from 0 to 1M: carles_sort-50M.txt.zip [156 MB] (344 MB uncompressed)
Code in PHP to generate the random numbers and save to a file
If you prefer to generate a new set of numbers, you can do it by yourselves.
Please note: my computers have a lot of memory, but if you have few memory you can easily modify this program to save the values one by one and so saving memory by not having all the array in memory. Although I recommend you to generate big arrays and pass to a function while measuring the memory consumption to really understand how PHP manages passing Arrays to functions and memory. I found many Senior devs wrong about it.
<?php
/**
* Created by : carles.mateo
* Creation Date: 2015-05-22 18:36
*/
error_reporting(E_ALL);
// To avoid raising warnings from HHVM
date_default_timezone_set('Europe/Andorra');
// This freezes the server, using more than 35 GB RAM
//define('i_NUM_VALUES', 500000000);
// 50M uses ~ 10 GB RAM
define('i_NUM_VALUES', 50000000);
define('i_MAX_NUMBER', 500000000);
function get_random_values() {
$st_values = null;
$s_values_filename = 'carles_sort.txt';
if (file_exists($s_values_filename)) {
print_with_datetime("Reading values...");
$st_values = file($s_values_filename);
print_with_datetime("Ensuring numeric values...");
foreach($st_values as $i_key=>$s_value) {
$i_value = intval($s_value);
$st_values[$i_key] = $i_value;
}
} else {
print_with_datetime("Generating values...");
$st_values = generate_random_values();
print_with_datetime("Writing values to disk...");
save_values_to_disk($s_values_filename, $st_values);
print_with_datetime("Finished writing values to disk");
}
return $st_values;
}
function generate_random_values() {
$i_num_values = i_NUM_VALUES;
$i_max_number = i_MAX_NUMBER;
$st_values = array();
for($i_counter = 0; $i_counter<$i_num_values; $i_counter++) {
$i_random = rand(0, $i_max_number);
$st_values[] = $i_random;
}
return $st_values;
}
function save_values_to_disk($s_values_filename, $st_values) {
$i_counter = 0;
$o_file = fopen($s_values_filename, 'w');
foreach ($st_values as $i_key => $s_value) {
$i_counter++;
fwrite($o_file, $s_value.PHP_EOL);
if (($i_counter % 100000) == 0) {
// every 100K numbers we show a status message
$f_advance_percent = ($i_counter / $i_max_values)*100;
print_with_datetime("Item num: $i_counter ($f_advance_percent%) value: $s_value written to disk");
}
}
fclose($o_file);
}
function get_datetime() {
return date('Y-m-d H:i:s');
}
function print_with_datetime($s_string) {
echo get_datetime().' '.$s_string."\n";
}
print_with_datetime('Starting number generator...');
$st_test_array = get_random_values();
First comments about this code:
Obviously to generate an array from 50M items in PHP you need enough of RAM. In PHP this takes ~9GB, in C you need much less: just 50M * 4 bytes per item = 200 MB, although as my program is multipurpose and use several arrays you will realistic be needing >2 GB RAM.
Playing with memory_get_usage() ayou will discover that returning a big array from the function to the main code does not work by copying it to the stack, and that by passing the array to the function by value (not specifying by reference), does not copy the values neither. A pointer alike is passed unless the data passed is modified. It used a technique called copy-on-write. Other modern languages use similar techniques as well to save memory. So it is not true that “A copy of the original $array is created within the function scope“. As PHP.net section PHP at the Core: A Hacker’s guide defines “PHP is a dynamic, loosely typed language, that uses copy-on-write and reference counting.“
This forced conversion to int is because when PHP reads the values from the disk it reads them as String (and it puts a jump of line at the end as well). We convert to make sure we use PHP integer values.
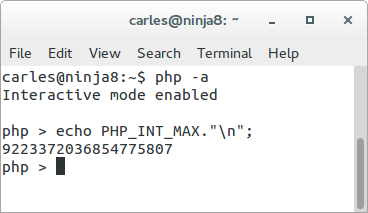
To know the max value of an Integer in your platform do:
echo PHP_INT_MAX;
For a 64 bits is: 9223372036854775807
I limited the number of registers sorted in this tests to 50,000,000 because it makes PHP use 12.6GB of RAM, and my computer has 32 GB. I tried with 500,000,000 but the Linux computer started to swap like crazy and had to kill the process by ssh (yes, the keyboard and mouse were irresponsible, I had to login via ssh from another computer and kill the process). Although 500M is a reasonably number for the code in C or Java.
So the fourth conclusion is that for working with big Data Structures PHP is not recommended because it uses a lot of RAM. You can use it if its flexibility brings you more value than performance and memory consumption.
Everything that you do can do in PHP will be much much much faster if done in C.
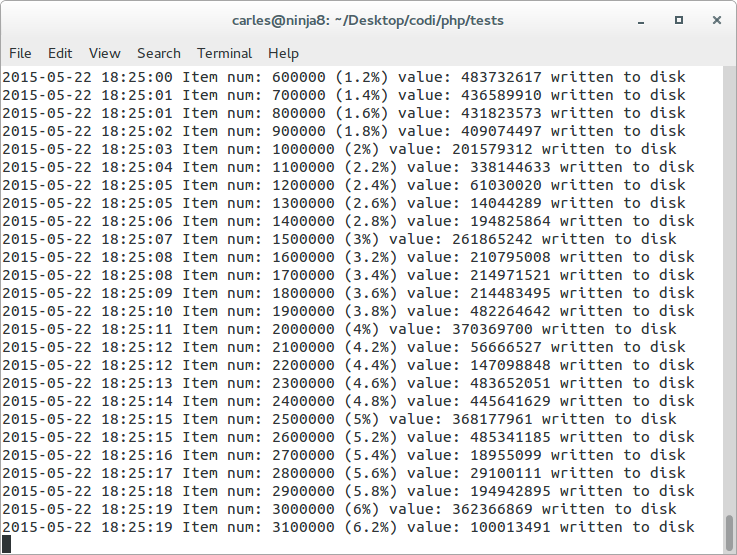
Sample status of the advance of the process of writing to disk from PHP (that is slow) 50M values from ranges 0 to 500M
My solution 1: simple csort
I’ve developed several implementations, with several utility. This is the first case.
Please take a look at this table of the cost of sorting an Array by using different algorithms from http://bigocheatsheet.com/ :
It is interesting to see the complexity of each algorithm in all the cases.
So Quicksort has a complexity of O(n log(n)) for the best case, and O(n^2) for the worst.
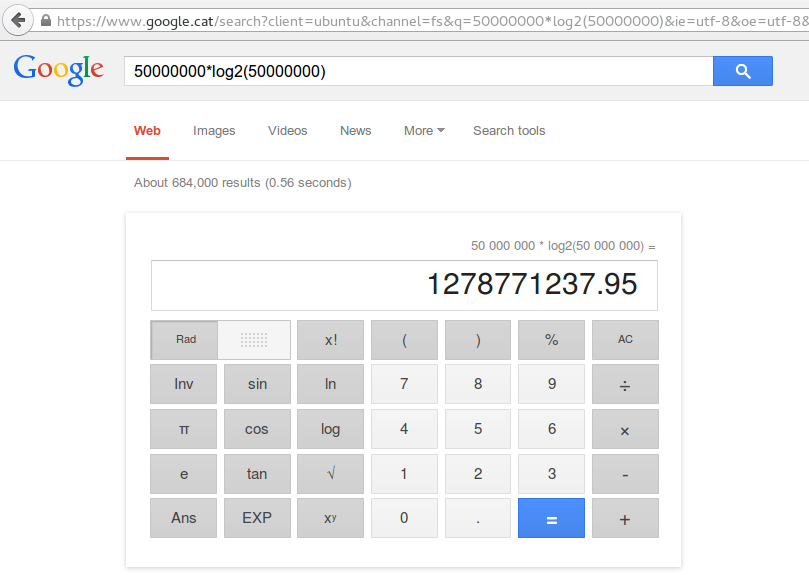
For a 50 Million Array, so n=50M, then 50M * log2(50M) = 1,278,771,237.95 ~ 1.28 Billion
My algorithm approach is this: having the unsorted array loaded into the array st_values, I do a main loop like this (remember that we want to sort and remove duplicates):
So, I copy to the destination array st_values_sorted the values, assigning the value as the index of the Array st_values_sorted.
With this:
We are sure we will have no duplicates, as if the value is duplicated n times it will be simply reassigned to the same position n times, and so having only it one time as st_values_sorted[n] in the final array.
We have an array, that has as index, the same value. So even, if in a foreach loop you would get the values assorted, they’re sorted by their key (hash index numeric value).
Finally, if you want to generate a sorted sequential array or a linked list, we do:
// Resort for a creating a ordered list
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > -1 ) {
// If the value existed
st_values_sorted_renum[l_counter_hit] = st_values_sorted[l_counter];
l_counter_hit++;
}
}
The magic of this:
In the first loop, we read each item of the array just one time. So O(n)
In the second loop, if we really want to generate a sorted list, we simply loop the sorted and deduplicated Array by index, as seen in the code before, from the initial possible value (0) to the maximum value we can have (in this sample m=1M)
So we loop, for 1,000,001 items
So in total we do n+m cycles
The cost in the Best and in the Worst case is O(n)
This is fucking awesome faster than quicksort For quicksort time complexity is: Best O(n log n). Worst O(n^2)
After quicksort you would have to delete duplicates also, adding some cost (in the case of PHP unique() function is really costly)
An optimization is that we can also associate the index, in the process of loading the values from disk, so we save the first loop (step 1) and so we save O(n).
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
exit(EXIT_FAILURE);
}
st_values[l_number] = l_number;
l_counter++;
if (l_counter > l_max_values -1) break;
}
And we will have the Array sorted (by key) without any sort. That’s why I say… The fastest sort… is no sorting at all!.
This is the recommended way of using the algorithm because it saves a lot of memory, so, instead of having and Array of 50M for loading the data to sort, and another of 1M to hold the csorted data, we will have only the 1M Array. We will be adding the data using csort and eliminating duplicates and sorting on the way.
If in the process of loading the have all the values sorted, we will not do the first loop O(n), so our cost will be O(m) where m<n
Finally, if our array is sorted (by index) there is no need to do the second loop to produce a sorted list, as the array is sorted by key. But if we need to do it, the cost is m, otherwise we have no cost at all, it was sorted and deduplicated when loaded from disk!
Even doing both loops, this is awesome faster than quicksort (even without deduplicating), for the universes tested:
50M items, possible values 0-1M
50M items, possible values 0-50M
50M items, possible values 0-500M
The same proportions with less items
Comparing the performance for the first case
Notes:
Please note the code has been compiled with -O0 to disable optimizations for what I think is a bug I found in gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2. that manifests in the csort with compression. With the parameter -O2 the times for the sorting are half and better (0.1 seconds for csort basic, around 4.7 for quicksort).
To use arrays of 500M, so using more than 2GB of ram you should pass the parameter -mcmodel=medium to gcc or the compiler will return an error “relocation truncated to fit: R_X86_64_32S against .bss”
Computer used is Intel(R) Core(TM) i7-4770S CPU @ 3.10GHz, as computers nowadays use turbo, times vary a bit from test to test, so tests are done many times and an average value is provided
Please understand how your language pass the parameters in functions before trying to port this code to another language (passing a pure by value string of 50M items to a function would not be a good idea, even worst for the case of recursive functions)
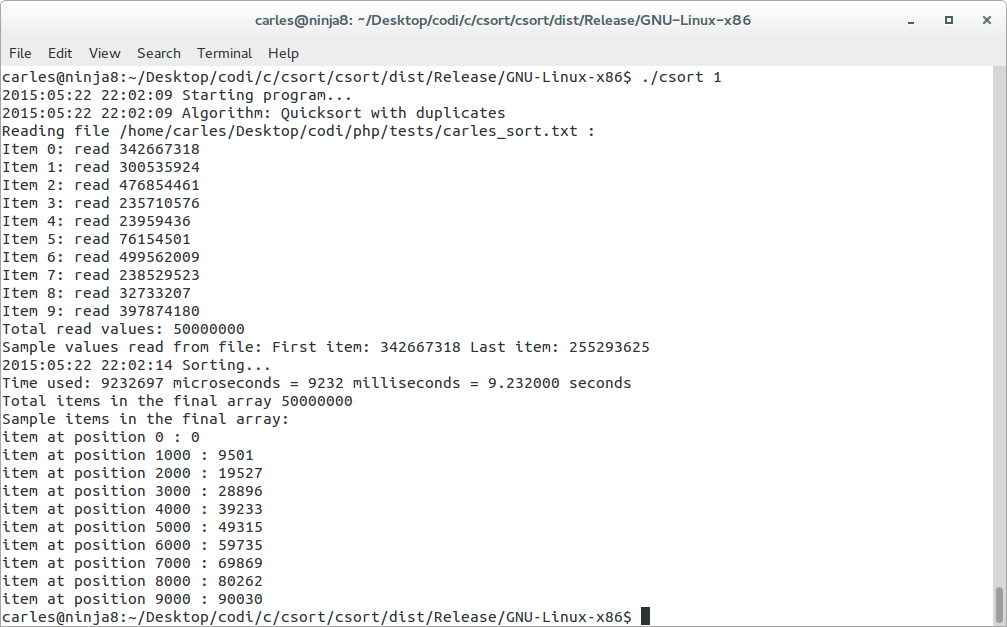
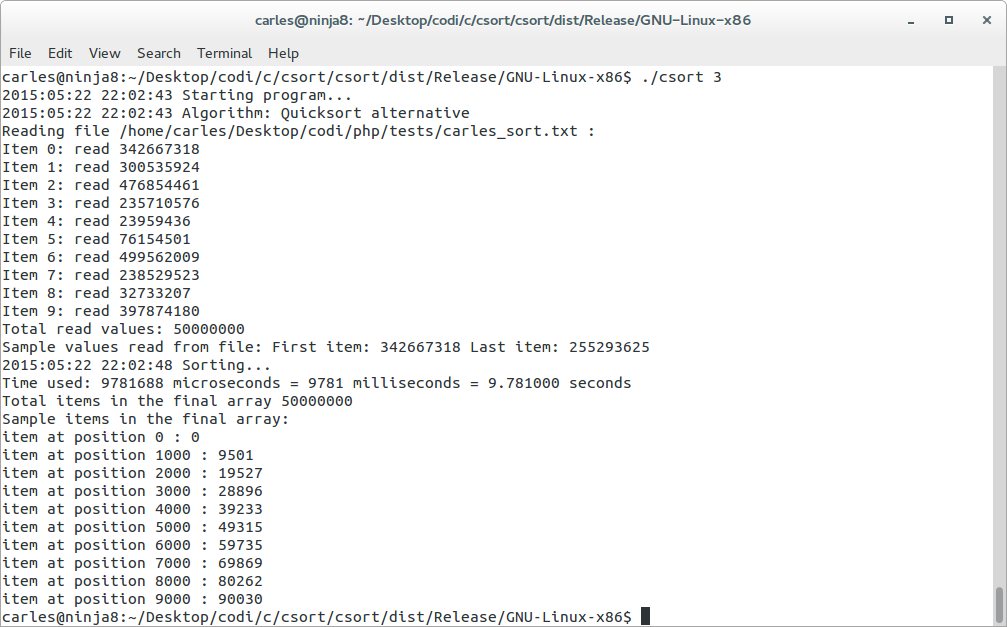
As you can see in the C code below, I have used two quicksort algorithms, both quicksort take between 8.7 and 10 seconds. (the second algorithm is a bit slower)
This time does not change, no matter if the random numbers were for ranges 0-1M, 0-50M or 0-500M.
My implementation of the quicksort with removing duplicates take just a bit more as I use the same base of the csort for removing the duplicates.
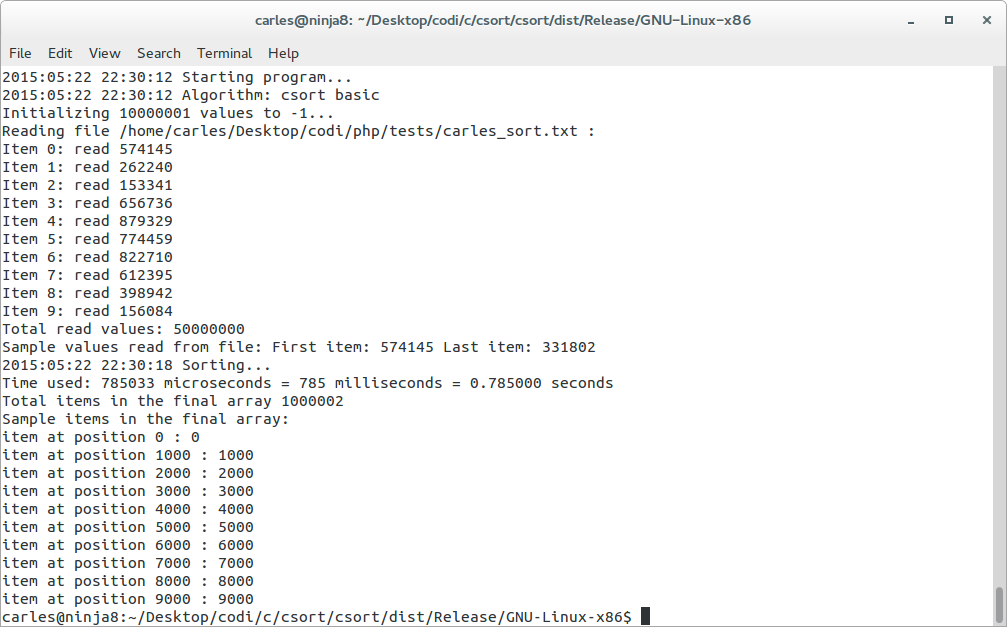
With the csort basic, doing the two loops (so no optimizing on load) the time for sorting with removing duplicates and generating a final array like a list, depends on the maximum possible value:
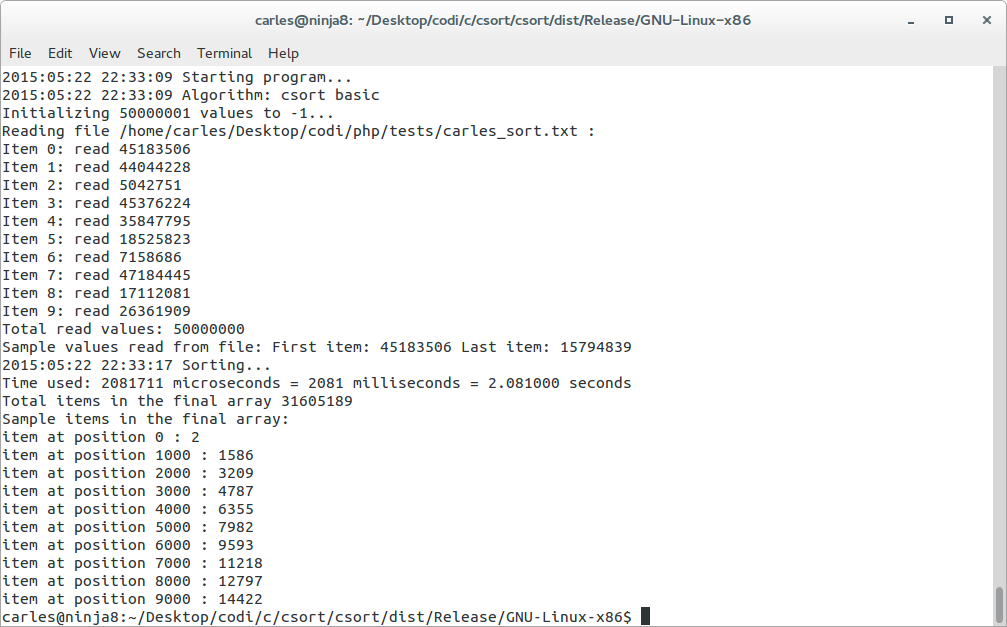
Universe of 50M items, random values between 0-1M, time: 0.5 to 0.7 seconds
Here csort basic invoked from command line. Firefox was opened and heavily full of tabs, so it was a bit slower but it takes 785 ms
Launching csort basic from the netbeans IDE, Release config but -O0, and firewox removed, takes 554 milliseconds / 0.554 seconds
Universe of 50M items, random values between 0-50M, 1.7-2 seconds
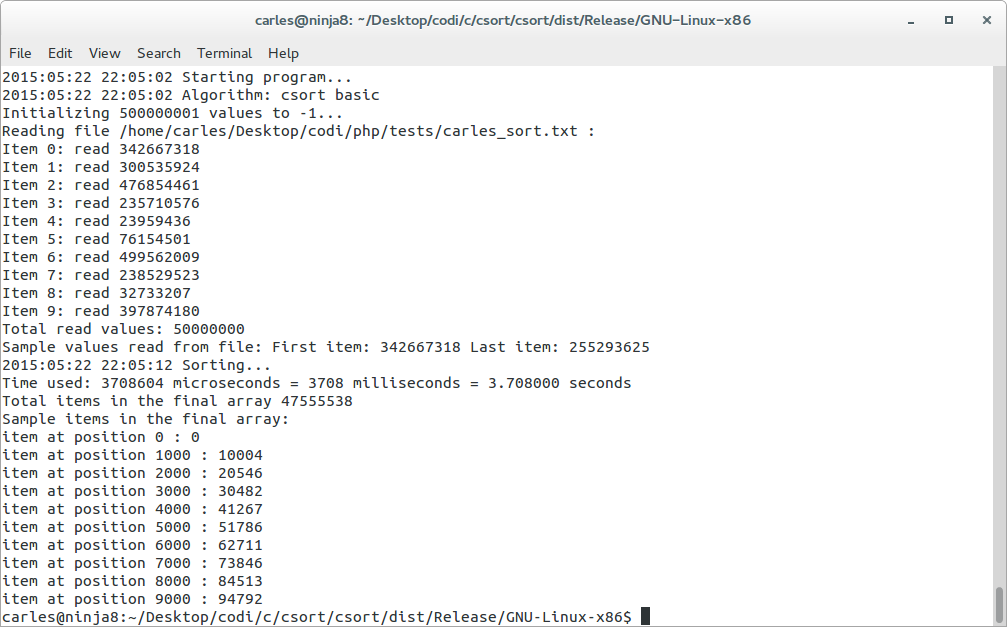
Universe of 50M items, random values between 0-500M, 3.7 seconds
Advantages of csort (for its purpose, so for the universes compatible, so if the range of values m is smaller or not many times bigger than the number of items n):
Is super-fast
It saves a lot of memory
Can be used to remove duplicates or to keep duplicates
It is possible to use it with hybrid universes (see additional optimizations) and have significant performance gains respect using a single sorting algorithm
It is very easy to understand and to implement
Disadvantages of csort basic:
It is intended for the universe of max(m) < n. If max(m) (maximum value of the number of random values) is much much higher than n (the number of items), then the sorted by key array will use more memory (bigger array), even if it has few values. (* see csort with compression bellow and Additional optimizations sections)
In certain border edge cases where n is many more times smaller than the difference between min(m) and max(m) the algorithm could be slower than quicksort. (this is if data does not accomplish max(m) < n)
The sorted array uses memory. Other algorithms, starting from an initial array, do not need additional arrays in order to sort. Although we can generate a final linked list and remove the arrays from memory during the process we are using that memory. But this was supposing we have an original array not sorted, but actually we don’t need to have an starting array, just csort the Data as you get it to the destination Array, and then you save memory because an Array of 1M takes less memory than an Array of 50M. (See My solution 2: optimized when reading)
My solution 2: optimized when reading
This is basically csort, but using the read from disk process to assign the right index, not only save CPU but a lot of memory.
That way the complexity is totally reduced as data is sorted (by index) and deduplicated when loading, with no cost.
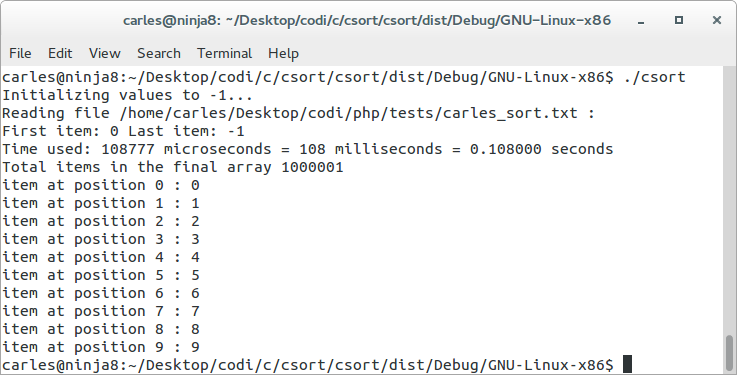
In the case of the optimized read, with an universe of 50M items, ranges 0-1M, it takes the astonishing time of.. 3 ms! So 0.003 seconds.
Probably this represents better the idea of beating quicksort: csort 0.003 seconds vs ~10 seconds quicksort.
My solution 3: supporting linked data
Image we have a numeric array with unique values, for example id, and another String array with the names.
So, it assigns the index, as the other versions of csort, but instead of assigned the same value as the index, it is assigned the number of times that this value is found.
From this Array it is possible to get the original linked list sorted easily:
{0,0,0,3,5,5,5,7,10,15,21,100000}
Now, take the first universe of data 50M items, with ranges 0-1M, and you get that you have compressed an originally unsorted array of 50M items into a sorted array of 1M items (1,000,001 to be exact) and you can still access by index. So a compression of 50 to 1, for this universe of numbers. (As you are thinking that won’t compress, but use more space, if the range of numbers is bigger than the number of items.)
If your values repeat a lot, and you have a huge set of items to sort, like in Big Data, this algorithm is wonderful and have huge memory savings and amazing speedy random access to data.
The idea, as mentioned before, is to do not load the data into an Array, and then sort, but to assigning using csort when reading data from disk. That way instead of having an Array of 50M and another of 1M, we would have only a single Array of 1M.
This is the relation of times for the universe 50M, 0-1M:
csort basic: 0.553 seconds
Please note: this sample including the time to generate a array like a list: st_values_sorted_renum, so the time just to create the csorted array is ~3ms less
csort opt read: 0.003 seconds
csort with compression and duplicates support: 0.883 seconds
But awesome news are that the csort with compression can be implemented on the load time, like csort opt read.
Additional improvements
1) Using overlay to save Memory and run even faster
Ideally min(m) and max(m) should be calculated.
Imagine that you have a universe of data composed by id driver licenses. Guess that those numbers range from 140,000,000 to 190,000,000.
There is no need have create an array of 190M items. Just create an array of 50M, (max(m) – min(m)) and save an overlay to a variable.
l_overlay = 140000000;
Then simply do your loops from 0 to max(m) – l_overlay and when you’re building the final linked list or the sequentially ordered final array add l_overlay to each value.
You will save memory and increase speed.
2) Hybrid universes / spaces
Guess you have a hybrid universe, composed by let’s say 75% of your values in the range of 0-1M and 25% of your values being frontier values, f.e. between 35M and 900M.
// Last value covered by the csort
long l_last_frontier = 1000000;
long l_counter_unsorted_array = 0;
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
exit(EXIT_FAILURE);
}
if (l_number > l_last_frontier) {
st_values_unsorted[l_counter_unsorted_array] = l_number;
l_counter_unsorted_array++;
} else {
st_values[l_number] = l_number;
}
l_counter++;
if (l_counter > l_max_values -1) break;
}
You can then sort the 25% with another algorithm and merge the csorted array (it goes first) and the 25% (bigger values, go later), now sorted Array, and you’ll have benefit from a 75% super-fast sorting.
3) Hybrid sort big-O
For my tests, as long as you have memory, you can csort up to n * 10, and have significant time saving respect Quicksort. So if you have a really huge universe you can implement a hybrid algorithm that sorts up to m = n * 10 (l_last_frontier = n * 10) and use another algorithm to sort the rest >m. Finally just add the sorted second block to the sorted from first block results.
4) Hybrid sorting, with undetermined n and m
If you don’t know how long will be your space, like in a mapreduce, or the max value, you can also use the hybrid approach and define an array big enough, like 10M. If your arrays are based on long int, so using 4 bytes per position, it will take only 38 Mbytes of RAM. Peanuts. (Use the l_last_frontier seen in the point before just in case you have bigger values)
When you’re loading the data, and csorting using csort opt read, keep a variable with the max and min values found, so you’ll not have to parse all the 10M, just from min-max in order to generate a final sorted, deduplicated, list or array.
It’s up to you to fine tune and adjust the size for the minimum memory consumption and maximum efficiency according to the nature of your data.
5) Using less memory
If you have stored the data to sort in a Collection, you can reduce an item one by one, so you will save memory for huge amounts of Data. So, you can add that item to csort resulting array, and eliminate from the Collection/LinkedList source. One by one. That way you’ll save memory. With the sample of 50M registers with 1M different random values, it passes from 400MB* of RAM to 4MB of RAM in C. (* I’m calculating here a Linked List structure of 2 Long Data-type, one for the value and another for next item, in C. In other languages gain can be even more spectacular)
csort and Big Data
With the progression of Big Data we are finding ourselves with seas of data. Those universe of data tend to have a much bigger number of registers (n) than the range of values (m).
For example, in the case of devices monitoring temperatures every second, we will have 3,600 rows per hour, 86,400 rows per day, 31,536,000 per year while the range of values read will be a very stable subset, like from 19.0 to 24.0 C. In this example, multiplying the float value per 10 to work always with Integers, we would be working with a subset of 190-240, so m would be 51 if optimized, or 0-240 if not. If we want to get the unique temperatures for the past year, csort will generate just an Array of 51 items, crushing any ordering algorithm in space and time.
The bigger the Data is, the faster csort will perform compared to other sorting algorithms.
The complete code in C
This is the complete source code. It supports all the cases and you can invoke it from command line with a parameter for the case number you want to test.
/*
* File: main.c
* Author: Carles Mateo
*
* Created on 2015-05-14 16:45
*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/time.h>
#include <string.h>
/*
* Change does values for your tests, and recompile it
*/
#define l_MAX_ITEMS 50000000
#define l_MAX_VALUE 1000000
static int const i_ALGORITHM_QUICKSORT = 1;
static int const i_ALGORITHM_QUICKSORT_UNIQUE = 2;
static int const i_ALGORITHM_QUICKSORT2 = 3;
static int const i_ALGORITHM_CSORT_BASIC = 7;
static int const i_ALGORITHM_CSORT_OPT1 = 8;
static int const i_ALGORITHM_CSORT_COMP = 9;
#define s_HELP "CSort by Carles Mateo\n"\
"=====================\n"\
"\n"\
"This demonstrates a sort algorithm faster than quicksort,\n"\
"as proposed in the article.\n"\
"Please read the complete article at:\n"\
"http://blog.carlesmateo.com\n"\
"\n"\
"Please invoke the program with one of these parameters:\n"\
"\n"\
"--help or without parameters for this help message\n"\
"1 To test using quicksort\n"\
" Only sorts, does not deletes duplicates\n"\
"2 To test using quicksort and removing duplicates\n"\
"3 To test using another implementation of quicksort\n"\
" Only sorts, does not deletes duplicates\n"\
"7 To test using csort (basic example, sorts and deletes duplicates)\n"\
"8 To test using csort, improvement with indexes assigned when reading\n"\
" Use to watch the time saving from basic csort\n"\
"9 To test using csort, with indexes assigned when reading and counting\n"\
" the number of coincidences (compressed output array)\n"\
"\n"\
"Please, make sure that the file carles_sort.txt is present in the\n"\
"current directory.\n"\
"\n"
// Allocate in the BSS segment, which is a part of the heap
static long st_values[l_MAX_ITEMS];
// Only max value is required
static long st_values_sorted[l_MAX_VALUE];
static long st_values_sorted_renum[l_MAX_VALUE];
int init_values(long l_max_values);
void quicksort(long x[l_MAX_ITEMS], long first, long last);
void quicksort2(long arr[], long beg, long end);
void swap(long *a, long *b);
void printwdt(char s_string[]);
int init_values(long l_max_values) {
long l_counter = 0;
for (l_counter = 0; l_counter < l_max_values; l_counter++) {
// Init to -1
st_values[l_counter] = -1;
}
}
int init_values_sorted(long l_max_values, long l_num) {
long l_counter = 0;
for (l_counter = 0; l_counter < l_max_values; l_counter++) {
// Init to -1
st_values_sorted[l_counter] = l_num;
}
}
// Quicksort modified from original sample from http://www.cquestions.com/2008/01/c-program-for-quick-sort.html
void quicksort(long x[l_MAX_ITEMS], long first, long last){
long pivot,j,temp,i;
if (first<last) {
pivot=first;
i=first;
j=last;
while(i<j){
while(x[i]<=x[pivot]&&i<last)
i++;
while(x[j]>x[pivot])
j--;
if(i<j){
temp=x[i];
x[i]=x[j];
x[j]=temp;
}
}
temp=x[pivot];
x[pivot]=x[j];
x[j]=temp;
quicksort(x,first,j-1);
quicksort(x,j+1,last);
}
}
// Modified by Carles Mateo to use long based on http://alienryderflex.com/quicksort/
void quicksort2(long arr[], long beg, long end)
{
if (end > beg + 1)
{
long piv = arr[beg], l = beg + 1, r = end;
while (l < r)
{
if (arr[l] <= piv)
l++;
else
swap(&arr[l], &arr[--r]);
}
swap(&arr[--l], &arr[beg]);
quicksort2(arr, beg, l);
quicksort2(arr, r, end);
}
}
void swap(long *a, long *b)
{
long t=*a; *a=*b; *b=t;
}
/* print with date and time
*/
void printwdt(char s_string[]) {
time_t timer;
char buffer[26];
struct tm* tm_info;
time(&timer);
tm_info = localtime(&timer);
strftime(buffer, 26, "%Y-%m-%d %H:%M:%S", tm_info);
printf("%s %s\n", buffer, s_string);
}
int main(int argc, char** argv) {
char s_filename[] = "carles_sort.txt";
long l_max_values = l_MAX_ITEMS;
long l_max_values_sorted = l_MAX_VALUE;
char s_ch;
FILE *o_fp;
long l_counter=0;
long l_counter_hit=0;
long l_number;
int b_exit = 0;
int i_fitems_read = 0;
int i_algorithm = 0;
// Small counter for printing some final results
int i_counter=0;
// temp value for the final print
long l_value=0;
// Used for counting the number of results on optimized array
long l_total_items_sorted = 0;
long l_max_range;
long l_items_found = 0;
if (argc < 2) {
printf(s_HELP);
exit(EXIT_SUCCESS);
}
printwdt("Starting program...");
if (strcmp(argv[1], "1") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT;
printwdt("Algorithm: Quicksort with duplicates");
} else if (strcmp(argv[1], "2") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT_UNIQUE;
printwdt("Algorithm: Quicksort removing duplicates");
} else if (strcmp(argv[1], "3") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT2;
printwdt("Algorithm: Quicksort alternative");
} else if (strcmp(argv[1], "7") == 0) {
i_algorithm = i_ALGORITHM_CSORT_BASIC;
printwdt("Algorithm: csort basic");
} else if (strcmp(argv[1], "8") == 0) {
i_algorithm = i_ALGORITHM_CSORT_OPT1;
printwdt("Algorithm: csort optimized read");
} else if (strcmp(argv[1], "9") == 0) {
i_algorithm = i_ALGORITHM_CSORT_COMP;
printwdt("Algorithm: csort compress");
}
if (i_algorithm == 0) {
printf(s_HELP);
exit(EXIT_SUCCESS);
}
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT2) {
// Use this if you want to make tests with partial data to find the end of the values
//printf("Initializing %li values to -1...\n", l_max_values);
//init_values(l_max_values);
}
if (i_algorithm == i_ALGORITHM_CSORT_BASIC || i_algorithm == i_ALGORITHM_CSORT_OPT1 || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
// We init to -1 as it could happen that some indexes have not a value,
// and we want to know what's the case.
printf("Initializing %li values to -1...\n", l_max_values_sorted + 1);
init_values_sorted(l_max_values_sorted + 1, -1);
}
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
printf("Initializing %li values_sorted to 0...\n", l_max_values_sorted + 1);
init_values_sorted(l_max_values_sorted + 1, 0);
}
o_fp = fopen(s_filename,"r"); // read mode
if( o_fp == NULL ) {
printf("File %s not found or I/O error.\n", s_filename);
perror("Error while opening the file.\n");
exit(EXIT_FAILURE);
}
printf("Reading file %s :\n", s_filename);
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
perror("File ended before reading all the items.\n");
exit(EXIT_FAILURE);
}
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE ||
i_algorithm == i_ALGORITHM_QUICKSORT2 ||
i_algorithm == i_ALGORITHM_CSORT_BASIC || i_algorithm == i_ALGORITHM_CSORT_COMP) {
st_values[l_counter] = l_number;
}
if (i_algorithm == i_ALGORITHM_CSORT_OPT1) {
st_values[l_number] = l_number;
l_total_items_sorted++;
}
if (l_counter < 10) {
// Echo the reads from the first 10 items, for debugging
printf("Item %li: read %li\n", l_counter, l_number);
}
l_counter++;
if (l_counter > l_max_values -1) break;
}
printf("Total read values: %li\n", l_counter);
printf("Sample values read from file: First item: %li Last item: %li\n", st_values[0], st_values[l_max_values -1]);
fclose(o_fp);
printwdt("Sorting...");
struct timeval time;
gettimeofday(&time, NULL); //This actually returns a struct that has microsecond precision.
long l_microsec_ini = ((unsigned long long)time.tv_sec * 1000000) + time.tv_usec;
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
quicksort(st_values, 0, l_MAX_ITEMS-1);
l_counter_hit = l_MAX_ITEMS;
}
if (i_algorithm == i_ALGORITHM_QUICKSORT2) {
quicksort2(st_values, 0, l_MAX_ITEMS-1);
l_counter_hit = l_MAX_ITEMS;
}
if (i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
printwdt("Removing duplicates...");
l_counter_hit = 0;
long l_last_known_value = -1;
for (l_counter=0; l_counter < l_max_values; l_counter++) {
if (l_last_known_value != st_values[l_counter]) {
l_last_known_value = st_values[l_counter];
st_values_sorted_renum[l_counter_hit] = st_values[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_BASIC) {
// Shrink and set the index
for (l_counter=0; l_counter < l_max_values; l_counter++) {
st_values_sorted[st_values[l_counter]] = st_values[l_counter];
}
// Resort for forearch
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > -1 ) {
st_values_sorted_renum[l_counter_hit] = st_values_sorted[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_OPT1) {
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values[l_counter] > -1 ) {
st_values_sorted_renum[l_counter_hit] = st_values[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
for (l_counter=0; l_counter < l_max_values; l_counter++) {
l_value = st_values[l_counter];
st_values_sorted[l_value] = st_values_sorted[l_value] + 1;
}
l_counter_hit = l_max_values_sorted + 1;
}
struct timeval time_end;
gettimeofday(&time_end, NULL); //This actually returns a struct that has microsecond precision.
long l_microsec_end = ((unsigned long long)time_end.tv_sec * 1000000) + time_end.tv_usec;
long l_microsec_total = l_microsec_end - l_microsec_ini;
long l_milliseconds_total = l_microsec_total / 1000;
double f_seconds = (double)l_milliseconds_total / 1000;
printf("Time used: %li microseconds = %li milliseconds = %f seconds \n", l_microsec_total, l_milliseconds_total, f_seconds);
printf("Total items in the final array %li\n", l_counter_hit);
printf("Sample items in the final array:\n");
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
l_max_range = l_max_values_sorted + 1;
l_counter_hit = 0;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > 0) {
l_counter_hit++;
l_items_found = l_items_found + st_values_sorted[l_counter];
}
}
printf("A final array of %li significant items, contains sorted lossless %li\n", l_counter_hit, l_items_found);
} else {
for (i_counter=0; i_counter<10000; i_counter=i_counter+1000) {
/* if (st_values_sorted[i_counter] > -1) {
// If you enjoy looking at values being printed or want to debug :)
printf("item at position %i : %li\n", i_counter, st_values_sorted[i_counter]);
}*/
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT2) {
l_value = st_values[i_counter];
} else {
l_value = st_values_sorted_renum[i_counter];
}
printf("item at position %i : %li\n", i_counter, l_value);
}
}
return (EXIT_SUCCESS);
}
My solution in PHP
As told before I have implemented my algorithm in PHP, and it outperforms by much the PHP native functions (PHP sort() is a quicksort algorithm written in C, and unique() ). I explain everything below for the PHP lovers, is the same than in C, but with special considerations for PHP language. Even in PHP the efficiency of the algorithm is clearly demonstrated.
Warning, do not attempt to run the PHP code as is in your machine unless you have at least 16 GB of RAM. If you have 8 GB RAM you should reduce the scope to avoid your computer to hang up or swap very badly.
Printing of datetime is done by those functions:
function get_datetime() {
return date('Y-m-d H:i:s');
}
function print_with_datetime($s_string) {
echo get_datetime().' '.$s_string."\n";
}
So once we have our numbers generated we do a sort($st_test_values);
And we calculate the time elapsed with microtime for profiling:
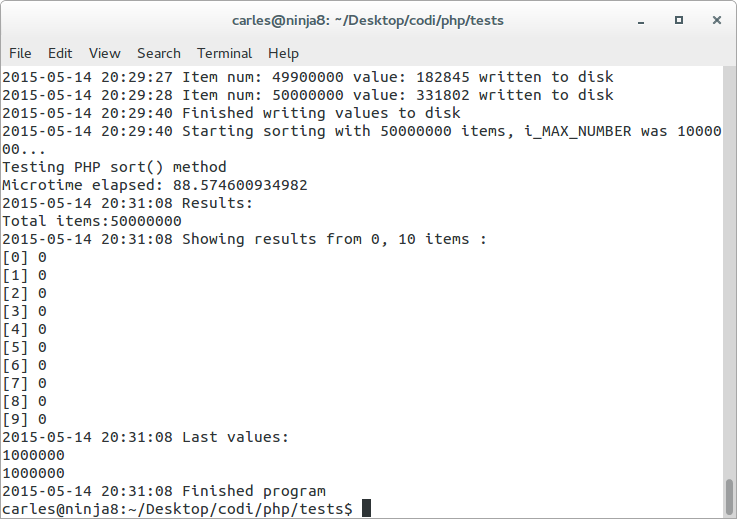
In this case we did a PHP sort(), and we didn’t even remove the duplicates and it takes 88.5 seconds.
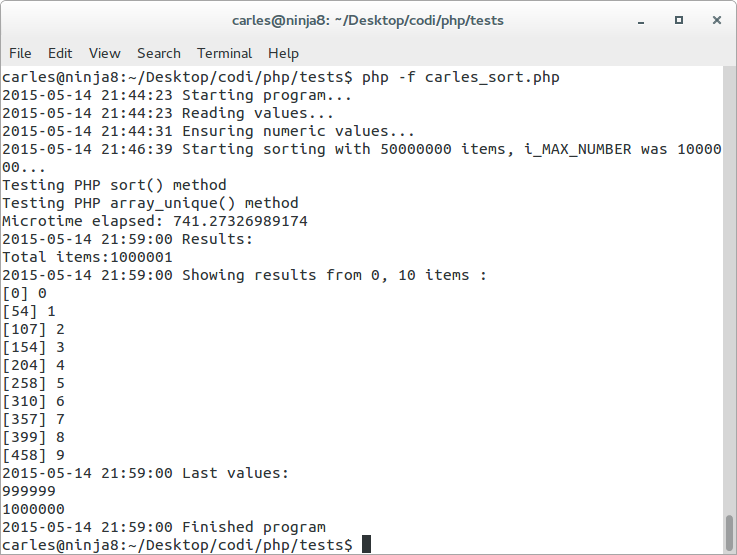
If we do a sort() and array_unique() to get the unique results sorted it takes: 741.27 seconds
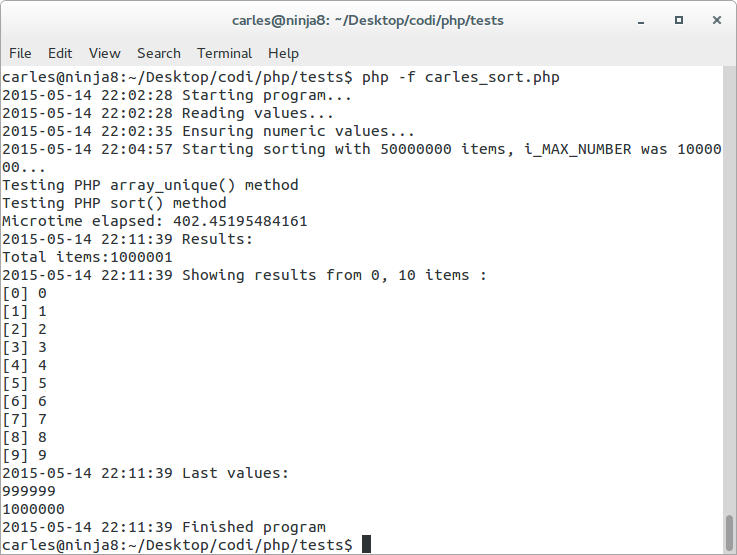
We do the opposite array_unique() and sort() and the result is: 402.45 seconds
It takes a lot.
Please note that sorting and doing array_unique takes more time than doing in the opposite order.
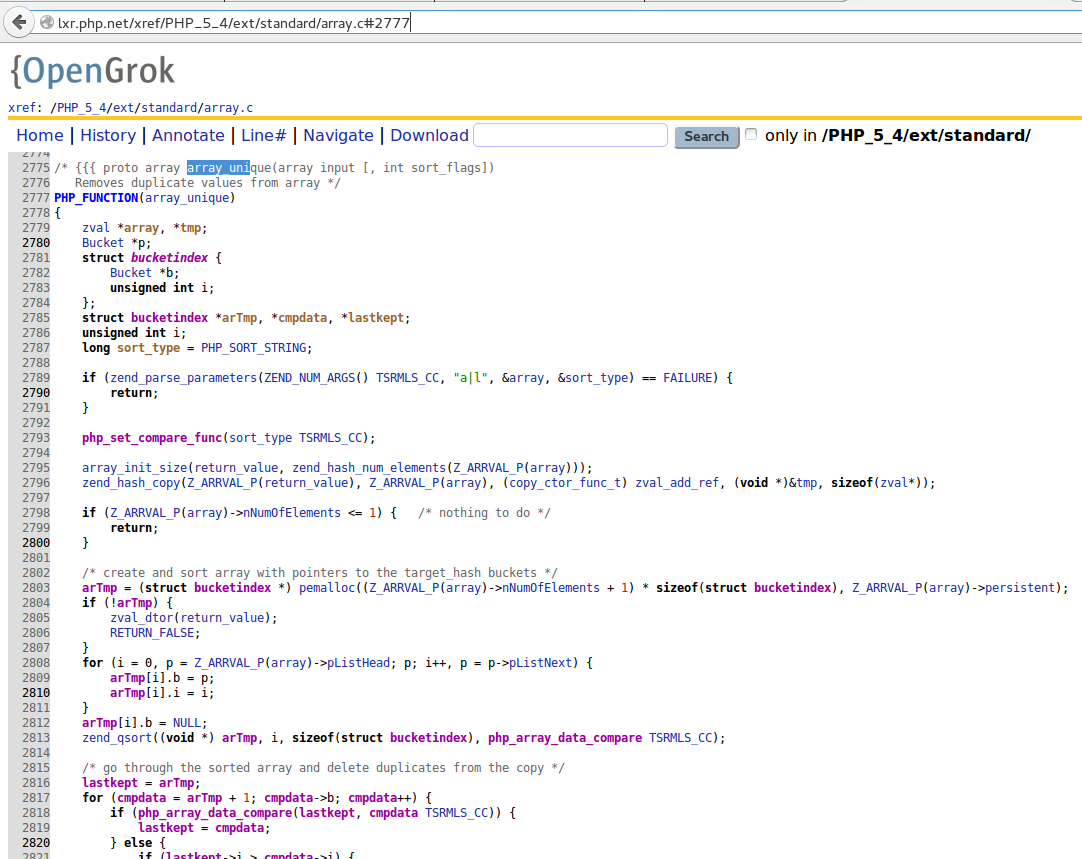
This is curious as one may thing that removing duplicates and sorting could be much faster than sorting and removing duplicates, but just sorting takes 88 seconds. I found the explanation looking at the source Source Code of PHP array_unique. Internally it sorts the array (zend_qsort line 2813) for removing the duplicates.
So well, we were sorting twice, and sorting a sorted array. This is the worst case for quicksort, so that explains the slowlyness.
Then it enters what I engined. PHP works with arrays, that can have a numeric index. So my point is: the fastest way to sort an array is… not sorting it at all.
We know that the range of values we have is much smaller than the number of registers:
We have values between 0 and 1,000,000
We have 50,000,000 of registers
PHP sort() function is written in C, so it should be fastest than any thing we program in PHP. Should be…. really?.
Knowing that the values are 0-1M and the registers are 50M, and knowing the number of operations that a quick sort will do, I figured another way to improve this.
So, the only think I’m doing is looping the 50M array and in a new array $st_result_array setting the key to the same value, than the integer value. So if the original $st_test_array[0] is equal to 574145, then I set st_result_array[574145] = 574145. Easy.
Think about it.
With this we achieve three objectives:
You eliminate duplicates. With 50M items, with values ranged from 0 to 1M you’ll set a value many times. No problem, it will use it’s index.
We have the key assigned, matching the value, so you can reference every single value
It’s amazingly faster. Much more than any sorting even in C
If you do a var_export or var_dump or print_r or a foreach you will notice that the first item of the array has key 574145 and value 574145, the second 262240, the third 153341, the fourth 656736 and the fifth 879329. They are not ordered in the way that one will think about an ordered array parsed with foreach(), but the thing is: do we need to sort it?. Not really. Every key is a hash that PHP will access very quickly. So we can do something like this to get the results ordered:
In this code we create a new array, with the values sorted in the sense that a foreach will return them sorted. But instead of recurring 50M registers, we only go to the max value (as values and indexes are the same, the max value also shows the max index), because we now don’t have 50M registers as we eliminated the duplicates, but 1M. And in an universe of 50M values from a range 0-1M, many are duplicates.
Even doing this second step still makes this sorting algorithm written in PHP, much more efficient than the quicksort written in C.
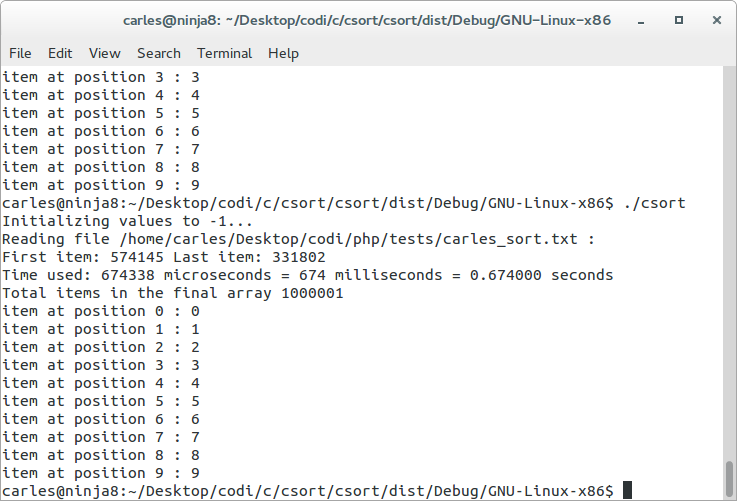
I ported the code to C, with the same data file, and it takes 0.674 seconds (674 milliseconds) and it uses only ~1 GB of RAM.
Take in consideration that if the data is directly loaded assigning the right index, so doing like in the next code, it will be blazing fast:
o_fp = fopen(s_filename,"r"); // read mode
if( o_fp == NULL ) {
printf("File %s not found or I/O error.\n", s_filename);
perror("Error while opening the file.\n");
exit(EXIT_FAILURE);
}
printf("Reading file %s :\n", s_filename);
while( 1 ) {
fscanf(o_fp, "%li", &l_number);
// The key is here ;)
st_values[l_number] = l_number;
l_counter++;
if (l_counter > l_max_values -1) break;
}
printf("First item: %li Last item: %li\n", st_values[0], st_values[l_counter-1]);
fclose(o_fp);
So if we only resort in another array to have the values sorted eliminating the non existing values (half the tasks we do in the previous program), it takes and order of milliseconds.
Using csort opt read with a busy computer (firefox using 16 GB RAM and many tabs) it takes 108 ms, with a idle computer 3 ms
Now imagine you don’t want to eliminate the duplicates.
You can create an memory optimized array where the index is the number, and the value represents the number of apparitions in the original file:
$st_example = Array( 0 => 1,
3 => 5,
4 => 1);
That would mean that the original sorted array, in form of list would be:
{0, 3, 3, 3, 3, 3, 4}
For the case of C, where the arrays have static size, a value of 0 would indicate there is no presence of that number in the orderer list so:
Even in the case of the resulting C array, it will be much smaller than the original 50M Array, as will have only the size corresponding to the max value. In our sample 1M.
In PHP you can get an Array alike the csort compressed by using a function called array_count_values(). It will not have the non existing items = 0, so it would not generate st_example[1] = 0 neither st_example[2] = 0, but it would generate the others.
So conditions for the algorithm to work blazing fast:
The max number (max(m)) must be ideally lower than the number of registers (this is true for languages like C or Java. Languages like PHP grow dynamically the Array size and work as Array Hash, so it’s not necessary as we can have st_sorted[0] and st_sorted[1000000] and the array size will be only 2 items. In this case we can use less memory than the csort algorithm and be faster using foreach() instead as for() from 0 to 1M)
The most numbers that are repeated, the faster that will work the algorithm
Key conclusions and Advantages:
If you directly load the values form disk assigning the value as a key as well, you’ll save one loop per item (n=50M in this universe) and make it faster (having only to parse count(m), in PHP it doesn’t have to be 0-m).
The fastest way to sort it, is no sorting at all. You can have the values stored per key, even if a foreach doesn’t start by 0,1,2… simply accessing the value index you need will be super-fast.
Source code in PHP
<?php
/**
* User: Carles Mateo
* Date: 2015-04-05 14:19
*/
error_reporting(E_ALL);
// To avoid raising warnings from HHVM
date_default_timezone_set('Europe/Andorra');
// This freezes the server, using more than 35 GB RAM
//define('i_NUM_VALUES', 500000000);
// 50M uses ~ 10 GB RAM
define('i_NUM_VALUES', 50000000);
define('i_MAX_NUMBER', 1000000);
define('i_EXIT_SUCCESS', 0);
define('i_EXIT_ERROR', 1);
abstract class CsortDemo {
const i_ALGORITHM_QUICKSORT = 1;
const i_ALGORITHM_PHP_QSORT = 4;
const i_ALGORITHM_PHP_ARRAY_FLIP = 5;
const i_ALGORITHM_PHP_ARRAY_UNIQUE = 6;
const i_ALGORITHM_CSORT_BASIC = 7;
const i_ALGORITHM_CSORT_OPT1 = 8;
public static function displayHelp() {
$s_help = <<<EOT
CSort.php by Carles Mateo
=========================
This demonstrates a sort algorithm faster than quicksort,
as proposed in the article.
Please read the complete article at:
http://blog.carlesmateo.com
Please invoke the program with one of these parameters:
--help or without parameters for this help message
1 To test using a quicksort algorithm written in PHP
4 To test using PHP sort() (is a quicksort algorithm)
5 To test using PHP array_flip()
6 To test using PHP unique() (is a quicksort algorithm)
7 To test using csort (basic example, sorts and deletes duplicates)
8 To test using csort, improvement with indexes assigned when reading
Use to watch the time saving from basic csort
9 To test using csort, with indexes assigned when reading and counting
the number of coincidences (compressed output array)
Please, make sure that the file carles_sort.txt is present in the
current directory.
EOT;
echo $s_help;
}
public static function get_random_values($i_algorithm) {
$st_values = Array();
$i_value = 0;
$s_values_filename = 'carles_sort.txt';
if (file_exists($s_values_filename)) {
self::print_with_datetime("Reading values...");
if ($i_algorithm == CsortDemo::i_ALGORITHM_CSORT_OPT1) {
$o_fp = fopen($s_values_filename, 'r');
if ($o_fp) {
while($s_line = fgets($o_fp) !== false) {
$i_value = intval($s_line);
$st_values[$i_value] = $i_value;
}
}
} else {
$st_values = file($s_values_filename);
self::print_with_datetime("Ensuring numeric values...");
foreach($st_values as $i_key=>$s_value) {
$i_value = intval($s_value);
$st_values[$i_key] = $i_value;
}
}
} else {
self::print_with_datetime("Generating values...");
$st_values = self::generate_random_values();
self::print_with_datetime("Writing values to disk...");
self::save_values_to_disk($s_values_filename, $st_values);
self::print_with_datetime("Finished writing values to disk");
}
return $st_values;
}
public static function save_values_to_disk($s_values_filename, $st_values) {
$i_counter = 0;
$f_advance_percent = 0;
$i_max_values = 0;
$i_max_values = count($st_values);
$o_file = fopen($s_values_filename, 'w');
foreach ($st_values as $i_key => $s_value) {
$i_counter++;
fwrite($o_file, $s_value.PHP_EOL);
if (($i_counter % 100000) == 0) {
// every 100K numbers we show a status message
$f_advance_percent = ($i_counter / $i_max_values)*100;
self::print_with_datetime("Item num: $i_counter ($f_advance_percent%) value: $s_value written to disk");
}
}
fclose($o_file);
}
public static function generate_random_values() {
$i_num_values = i_NUM_VALUES;
$i_max_number = i_MAX_NUMBER;
$st_values = array();
for($i_counter = 0; $i_counter<$i_num_values; $i_counter++) {
$i_random = rand(0, $i_max_number);
$st_values[] = $i_random;
}
return $st_values;
}
public static function get_datetime() {
return date('Y-m-d H:i:s');
}
public static function print_with_datetime($s_string) {
echo self::get_datetime().' '.$s_string."\n";
}
public static function print_algorithm_type($s_algorithm) {
echo "Testing $s_algorithm\n";
}
public static function print_results($st_values, $i_initial_pos_to_display, $i_number_of_results_to_display) {
self::print_with_datetime("Showing results from $i_initial_pos_to_display, $i_number_of_results_to_display items :");
$i_counter = 0;
$i_counter_found = 0;
for($i_counter=0; ($i_counter_found<$i_number_of_results_to_display && (($i_counter + $i_initial_pos_to_display) < i_MAX_NUMBER)); $i_counter++) {
$i_pos = $i_initial_pos_to_display + $i_counter;
if (isset($st_values[$i_pos])) {
echo '['.$i_pos.'] '.$st_values[$i_pos]."\n";
$i_counter_found++;
}
}
}
// Found on the web
public static function quicksort( $array ) {
if( count( $array ) < 2 ) {
return $array;
}
$left = $right = array( );
reset( $array );
$pivot_key = key( $array );
$pivot = array_shift( $array );
foreach( $array as $k => $v ) {
if( $v < $pivot )
$left[$k] = $v;
else
$right[$k] = $v;
}
return array_merge(self::quicksort($left), array($pivot_key => $pivot), self::quicksort($right));
}
public static function csort_basic($st_test_array) {
// Note that even if we do not explicit to PHP to pass array by reference it does it,
// and we do not use more memory unless we try to write to original array
$s_algorithm = 'Carles_sort_basic';
echo "Testing $s_algorithm\n";
$st_result_array = Array();
$st_result_array2 = Array();
$i_min_value_pos = null;
$i_max_value = null;
$i_max_value_pos = null;
$i_temp_value = null;
$i_loop_counter = 0;
$i_num_items = count($st_test_array);
$i_initial_pos = 0;
$i_ending_pos = $i_num_items;
for($i_pos = $i_initial_pos; $i_pos < $i_ending_pos; $i_pos++) {
$i_loop_counter++;
$i_value = $st_test_array[$i_pos];
$st_result_array[$i_value] = $i_value;
// If you want to debug a bit
//var_export($st_result_array); sleep(3);
// If you want to debug...
//if ($i_loop_counter % 1000 == 0) {
//echo "Loop: $i_loop_counter i_pos: $i_pos Value: $i_value\n";
//print_results($st_test_array, 0, 10);
//print_results($st_test_array, $i_num_items - 2, 2);
//}
}
// Return in the way of a foreach sorted Array
$i_max_value = max($st_result_array);
for($i_pos = 0; $i_pos <= $i_max_value; $i_pos++) {
if (isset($st_result_array[$i_pos])) {
$st_result_array2[] = $i_pos;
}
}
return $st_result_array2;
}
}
// Checking parameters
if (count($argv) < 2) {
// Display help and exit
CsortDemo::displayHelp();
exit(i_EXIT_SUCCESS);
}
$i_algorithm = intval($argv[1]);
CsortDemo::print_with_datetime('Starting program...');
$st_test_array = CsortDemo::get_random_values($i_algorithm);
$i_num_items = count($st_test_array);
CsortDemo::print_with_datetime("Starting sorting with $i_num_items items, i_MAX_NUMBER was ".i_MAX_NUMBER);
$i_loop_counter = 0;
$i_initial_pos = 0;
$i_ending_pos = $i_num_items - 1;
$i_min_value = i_MAX_NUMBER * 2; // A high number for the tests
$i_min_value_pos = null;
$i_max_value = null;
$i_max_value_pos = null;
$i_temp_value = null;
$b_changes_done = false;
$b_exit = false;
// TODO Test array_count_values
$f_microtime_ini = microtime(true);
if ($i_algorithm == CsortDemo::i_ALGORITHM_QUICKSORT) {
$s_algorithm = 'Quicksort written in PHP';
CsortDemo::print_algorithm_type($s_algorithm);
CsortDemo::quicksort($st_test_array);
}
if ($i_algorithm == CsortDemo::i_ALGORITHM_CSORT_BASIC) {
$st_test_array = CsortDemo::csort_basic($st_test_array);
}
if ($i_algorithm == CsortDemo::i_ALGORITHM_PHP_QSORT) {
CsortDemo::print_algorithm_type('PHP sort() method');
sort($st_test_array);
}
if ($i_algorithm == CsortDemo::i_ALGORITHM_PHP_ARRAY_FLIP) {
CsortDemo::print_algorithm_type('PHP array_flip() method');
$st_test_array = array_flip($st_test_array);
}
if ($i_algorithm == CsortDemo::i_ALGORITHM_PHP_ARRAY_UNIQUE) {
CsortDemo::print_algorithm_type('PHP array_unique() method');
$st_test_array = array_unique($st_test_array);
}
$f_microtime_end = microtime(true);
$f_microtime_resulting = $f_microtime_end - $f_microtime_ini;
echo "Microtime elapsed: $f_microtime_resulting\n";
CsortDemo::print_with_datetime('Results:');
//print_r($st_test_array);
$i_total_items = count($st_test_array);
echo 'Total items:'.$i_total_items."\n";
CsortDemo::print_results($st_test_array, 0, 10);
$i_last_number = array_pop($st_test_array);
$i_last_number1 = array_pop($st_test_array);
CSortDemo::print_with_datetime('Last values:');
echo $i_last_number1."\n";
echo $i_last_number."\n";
CsortDemo::print_with_datetime('Finished program');
PHP under HHVM
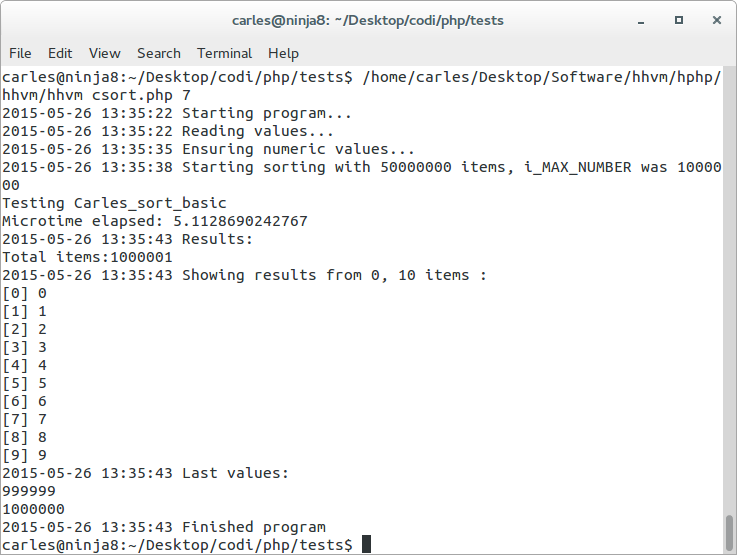
Additionally I executed the csort.php in the Facebook’s Hip Hop Virtual Machine, version 3.4.0-dev, and as expected everything is much faster than with PHP standard.
For example:
Using PHP sort() 88-104 seconds, using HHVM PHP sort() 15.8 seconds
Using csort basic from PHP 34 to 40 seconds, using csort basic from HHVM 3.4 to 5.13 seconds
The version of PHP used for these tests was:
PHP 5.5.9-1ubuntu4.9 (cli) (built: Apr 17 2015 11:44:57)
Copyright (c) 1997-2014 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2014 Zend Technologies
with Zend OPcache v7.0.3, Copyright (c) 1999-2014, by Zend Technologies
Must also mention that some operations like initializing the arrays, are super-fast with HHVM.
The solution in Java
The code has been executed with Oracle’s JDK 1.7.
I love Just In Time compilers. They are amazingly fast.
For this case, the results with Java, for the universe of 50M items, range 0-1M of values:
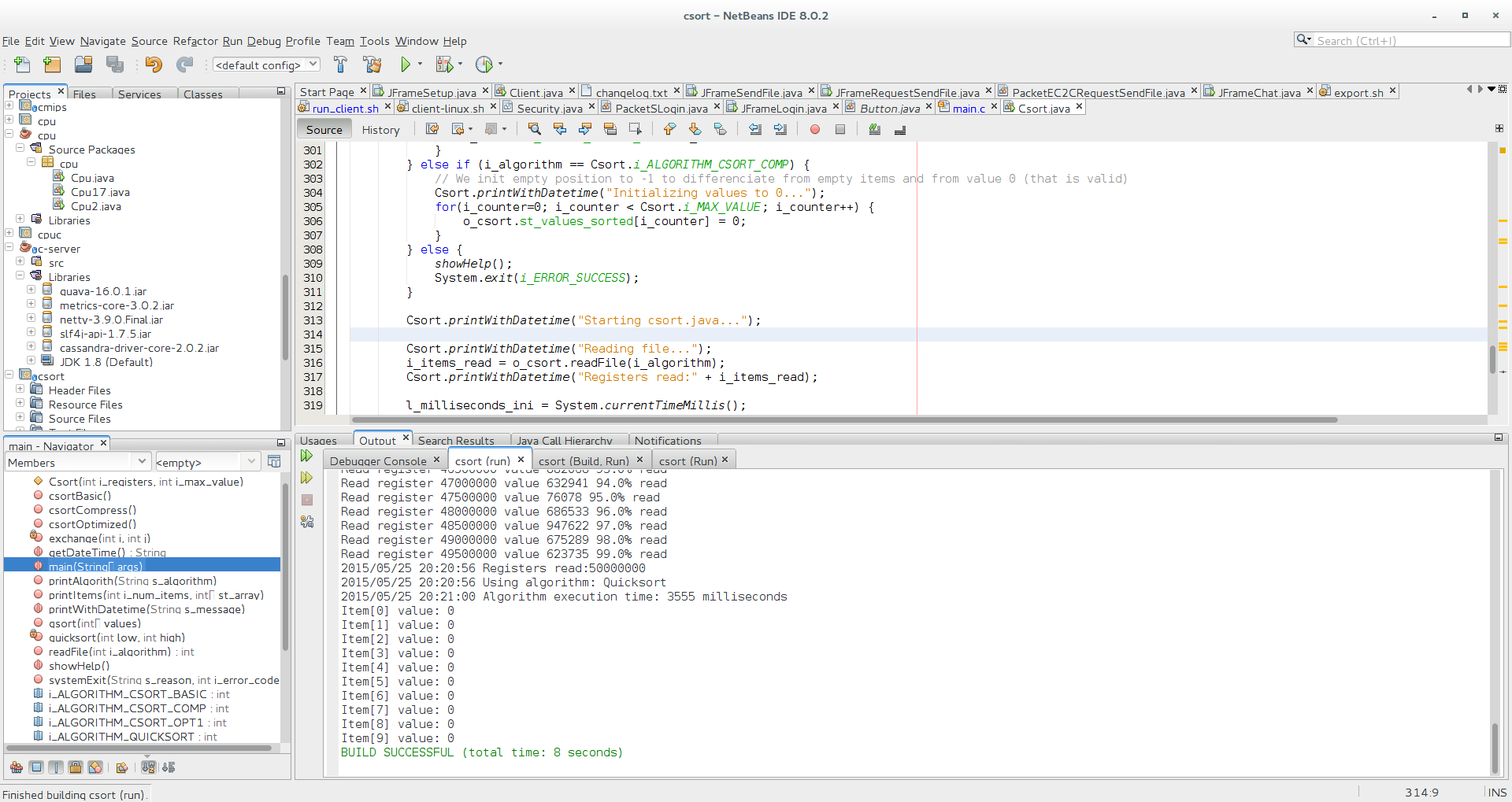
quicksort in Java: 3555 ms =3.555 seconds versus ~10 seconds in C Important: In C I had to disable -O2 optimization for what it looks like a bug in gcc (only detected in csort with compression). With -O2 times were around 4.7 seconds
csort.java basic: 26 ms to 120 ms = 0.026 seconds versus 0.5 seconds csort in C
csort.java opt read: 2-3 ms = 0.002-0.003 seconds versus 3 ms = 0.003 seconds in C
csort.java with compression and duplicates support: 160 ms = 0.16 seconds versus 0.272-0.277 segons in C
The execution on those languages (Java and C) is so fast that it’s hard to measure accurately as any random execution of Ubuntu in background will increase a bit the time.
Quicksort in Java, 3555 ms = 3.555 seconds
Csort basic with Java, 26 milliseconds
Csort read opt with Java, 5 milliseconds
The code in Java:
/*
* This code, except quicksort implementation, is written by Carles Mateo,
* and published as Open Source.
*/
package csort;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
*
* @author carles
*/
public class Csort {
public static final int i_MAX_REGISTERS = 50000000;
public static final int i_MAX_VALUE = 1000000;
public static final String s_FILE = "/home/carles/Desktop/codi/php/tests/carles_sort.txt";
public static final int i_ERROR_SUCCESS = 0;
public static final int i_ERROR_FAILURE = 1;
public static final int i_ALGORITHM_QUICKSORT = 1;
public static final int i_ALGORITHM_CSORT_BASIC = 7;
public static final int i_ALGORITHM_CSORT_OPT1 = 8;
public static final int i_ALGORITHM_CSORT_COMP = 9;
// Original values read
public int[] st_values;
// Our Csorted array
public int[] st_values_sorted;
// To resort as a alike list array
public int[] st_values_sorted_renum;
// For quicksort
private int[] numbers;
private int number;
public void systemExit(String s_reason, int i_error_code) {
printWithDatetime("Exiting to system, cause: " + s_reason);
System.exit(i_error_code);
}
public static String getDateTime() {
DateFormat o_dateformat = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
Date o_date = new Date();
return o_dateformat.format(o_date);
}
public static void printWithDatetime(String s_message) {
System.out.println(getDateTime() + " " + s_message);
}
public void printAlgorith(String s_algorithm) {
Csort.printWithDatetime("Using algorithm: " + s_algorithm);
}
public static void showHelp() {
String s_help = "" +
"CSort.java by Carles Mateo\n" +
"==========================\n" +
"\n" +
"This demonstrates a sort algorithm faster than quicksort,\n" +
"as proposed in the article.\n" +
"Please read the complete article at:\n" +
"http://blog.carlesmateo.com\n" +
"\n" +
"Please invoke the program with one of these parameters:\n" +
"\n" +
"--help or without parameters for this help message\n" +
"1 To test using quicksort\n" +
" Only sorts, does not deletes duplicates\n" +
"7 To test using csort (basic example, sorts and deletes duplicates)\n" +
"8 To test using csort, improvement with indexes assigned when reading\n" +
" Use to watch the time saving from basic csort\n" +
"\n" +
"Please, make sure that the file carles_sort.txt is present in the\n" +
"current directory.\n" +
"\n";
System.out.println(s_help);
}
public int readFile(int i_algorithm) {
BufferedReader br = null;
int i_value = 0;
int i_counter = 0;
try {
String sCurrentLine;
br = new BufferedReader(new FileReader(Csort.s_FILE));
while ((sCurrentLine = br.readLine()) != null) {
i_value = Integer.parseInt(sCurrentLine);
if (i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
this.st_values[i_value] = i_value;
} else {
this.st_values[i_counter] = i_value;
}
if (i_counter % 500000 == 0) {
float f_percent = ((float) i_counter / Csort.i_MAX_REGISTERS) * 100;
String s_percent_msg = "Read register " + i_counter + " value " + i_value + " " + f_percent + "% read";
System.out.println(s_percent_msg);
}
i_counter++;
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (br != null) br.close();
} catch (IOException ex) {
ex.printStackTrace();
this.systemExit("Error processing the file: " + Csort.s_FILE, Csort.i_ERROR_FAILURE);
}
}
return i_counter;
}
// http://www.vogella.com/tutorials/JavaAlgorithmsQuicksort/article.html
public void qsort(int[] values) {
// check for empty or null array
if (values == null || values.length == 0){
return;
}
this.numbers = values;
number = values.length;
quicksort(0, number - 1);
}
private void quicksort(int low, int high) {
int i = low, j = high;
// Get the pivot element from the middle of the list
int pivot = numbers[low + (high-low)/2];
// Divide into two lists
while (i <= j) {
// If the current value from the left list is smaller then the pivot
// element then get the next element from the left list
while (numbers[i] < pivot) {
i++;
}
// If the current value from the right list is larger then the pivot
// element then get the next element from the right list
while (numbers[j] > pivot) {
j--;
}
// If we have found a values in the left list which is larger then
// the pivot element and if we have found a value in the right list
// which is smaller then the pivot element then we exchange the
// values.
// As we are done we can increase i and j
if (i <= j) {
exchange(i, j);
i++;
j--;
}
}
// Recursion
if (low < j)
quicksort(low, j);
if (i < high)
quicksort(i, high);
}
private void exchange(int i, int j) {
int temp = numbers[i];
numbers[i] = numbers[j];
numbers[j] = temp;
}
// End of http://www.vogella.com/tutorials/JavaAlgorithmsQuicksort/article.html
public void csortBasic() {
int i_counter = 0;
int i_value = 0;
int i_max_range = 0;
int i_counter_hit = 0;
try {
for (i_counter=0; i_counter < i_MAX_REGISTERS; i_counter++) {
i_value = this.st_values[i_counter];
this.st_values_sorted[i_value] = i_value;
}
// Resort for forearch
i_max_range = i_MAX_VALUE;
for (i_counter=0; i_counter < i_max_range; i_counter++) {
if (this.st_values_sorted[i_counter] > -1 ) {
this.st_values_sorted_renum[i_counter_hit] = this.st_values_sorted[i_counter];
i_counter_hit++;
}
}
} catch (Exception e) {
printWithDatetime("Exception captured at i_counter: " + i_counter);
this.systemExit("Exception, so ending", i_ERROR_FAILURE);
}
}
public void csortOptimized() {
int i_counter = 0;
int i_value = 0;
int i_max_range = 0;
int i_counter_hit = 0;
try {
// It was sorted while reading :)
// Resort for forearch/list-style lovers
i_max_range = i_MAX_VALUE;
for (i_counter=0; i_counter < i_max_range; i_counter++) {
if (this.st_values[i_counter] > -1 ) {
this.st_values_sorted_renum[i_counter_hit] = this.st_values[i_counter];
i_counter_hit++;
}
}
} catch (Exception e) {
printWithDatetime("Exception captured at i_counter: " + i_counter);
this.systemExit("Exception, so ending", i_ERROR_FAILURE);
}
}
public void csortCompress() {
int i_counter = 0;
int i_value = 0;
for (i_counter=0; i_counter < i_MAX_REGISTERS; i_counter++) {
i_value = this.st_values[i_counter];
this.st_values_sorted[i_value] = this.st_values_sorted[i_value] + 1;
}
}
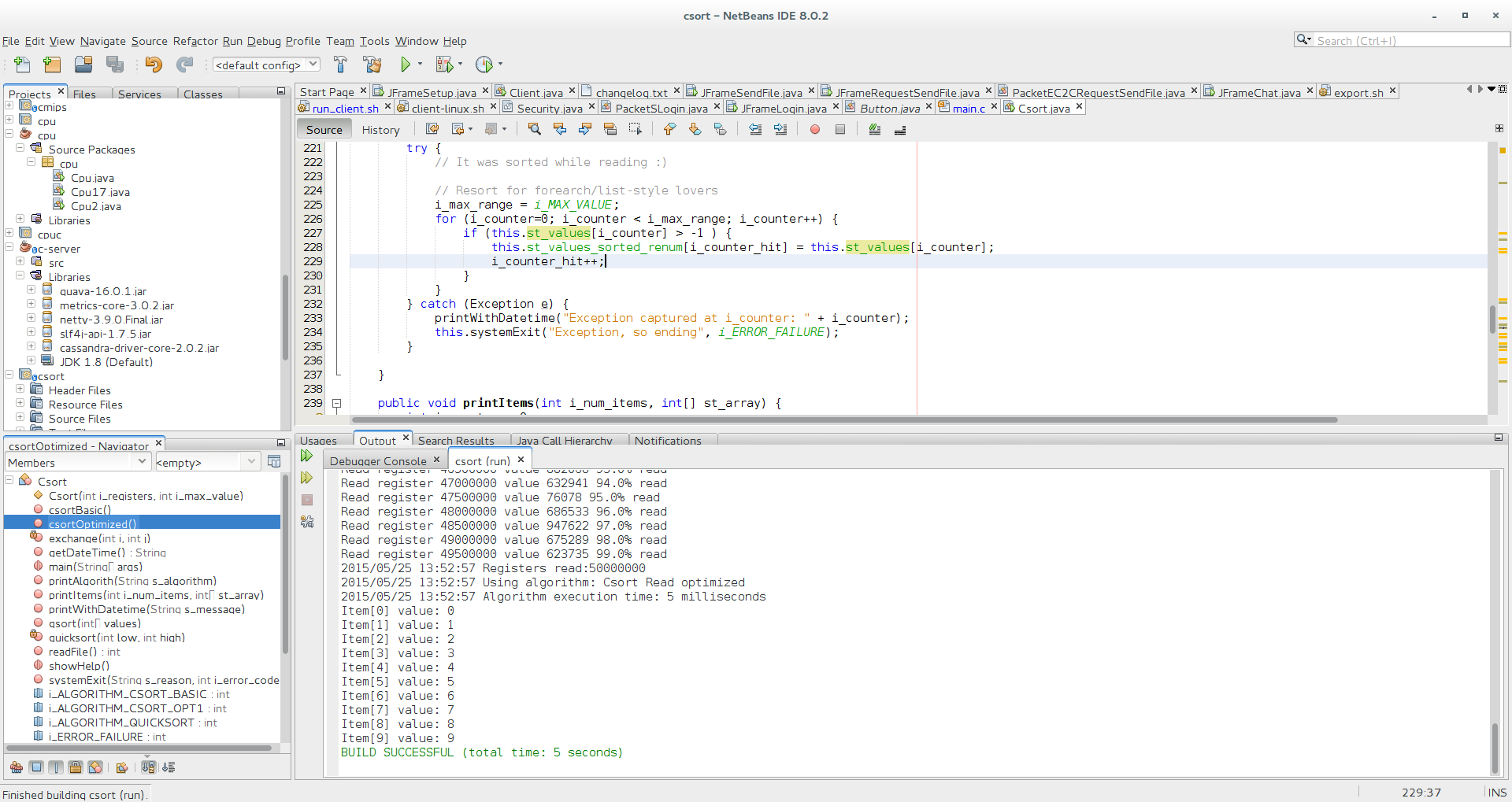
public void printItems(int i_num_items, int[] st_array) {
int i_counter = 0;
int i_value = 0;
for(i_counter=0;i_counter<i_num_items;i_counter++) {
i_value = st_array[i_counter];
System.out.println("Item[" + i_counter + "] value: " + i_value);
}
}
public Csort(int i_registers, int i_max_value) {
// int range is -2,147,483,648 to 2,147,483,647
this.st_values = new int[i_registers];
// If max value is 10 then we could have values from 0 to 10, so a 11 items Array
this.st_values_sorted = new int[i_max_value + 1];
this.st_values_sorted_renum = new int[i_max_value + 1];
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
long l_milliseconds_ini = 0;
long l_milliseconds_end = 0;
long l_milliseconds_total = 0;
int i_items_read = 0;
int i_algorithm = 0;
String s_algorithm = "";
int i_counter = 0;
/* Check parameter consistency */
if (args.length == 0 || args.length > 1 || (args.length == 1 && Integer.valueOf(args[0]) == 0)) {
showHelp();
System.exit(i_ERROR_SUCCESS);
}
i_algorithm = Integer.valueOf(args[0]);
Csort o_csort = new Csort(Csort.i_MAX_REGISTERS, Csort.i_MAX_VALUE);
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC || i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1 || i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
// We init empty position to -1 to differenciate from empty items and from value 0 (that is valid)
Csort.printWithDatetime("Initializing values to -1...");
for(i_counter=0; i_counter < Csort.i_MAX_VALUE; i_counter++) {
o_csort.st_values_sorted[i_counter] = -1;
o_csort.st_values_sorted_renum[i_counter] = -1;
}
} else if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
// We init empty position to -1 to differenciate from empty items and from value 0 (that is valid)
Csort.printWithDatetime("Initializing values to 0...");
for(i_counter=0; i_counter < Csort.i_MAX_VALUE; i_counter++) {
o_csort.st_values_sorted[i_counter] = 0;
}
} else {
showHelp();
System.exit(i_ERROR_SUCCESS);
}
Csort.printWithDatetime("Starting csort.java...");
Csort.printWithDatetime("Reading file...");
i_items_read = o_csort.readFile(i_algorithm);
Csort.printWithDatetime("Registers read:" + i_items_read);
l_milliseconds_ini = System.currentTimeMillis();
if (i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
s_algorithm = "Quicksort";
o_csort.printAlgorith(s_algorithm);
o_csort.qsort(o_csort.st_values);
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC) {
s_algorithm = "Csort basic";
o_csort.printAlgorith(s_algorithm);
o_csort.csortBasic();
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
s_algorithm = "Csort Read optimized";
o_csort.printAlgorith(s_algorithm);
o_csort.csortOptimized();
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
s_algorithm = "Csort compress with duplicates";
o_csort.printAlgorith(s_algorithm);
o_csort.csortCompress();
}
l_milliseconds_end = System.currentTimeMillis();
l_milliseconds_total = l_milliseconds_end - l_milliseconds_ini;
Csort.printWithDatetime("Algorithm execution time: " + l_milliseconds_total + " milliseconds");
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC || i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
o_csort.printItems(10, o_csort.st_values_sorted_renum);
}
if (i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
o_csort.printItems(10, o_csort.numbers);
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
o_csort.printItems(10, o_csort.st_values_sorted);
}
}
}
Note: This article is growing. I’ll be expanding the article, putting more samples, detailing timmings from different universes I’ve tested and screenshots, specially in the PHP section, to add more tricks and whys, but I wanted to put the base for being able to discuss with some colleagues.
Notes on 2017-03-26 18:57 CEST – Unix time: 1490547518 :
As several of you have noted, it would be much better to use a random value, for example, read by disk. This will be an improvement done in the next benchmark. Good suggestion thanks.
Due to my lack of time it took more than expected updating the article. I was in a long process with google, and now I’m looking for a new job.
I note that most of people doesn’t read the article and comment about things that are well indicated on it. Please before posting, read, otherwise don’t be surprise if the comment is not published. I’ve to keep the blog clean of trash.
I’ve left out few comments cause there were disrespectful. Mediocrity is present in the society, so simply avoid publishing comments that lack the basis of respect and good education. If a comment brings a point, under the point of view of Engineering, it is always published.
Thanks.
(This article was last updated on 2015-08-26 15:45 CEST – Unix time: 1440596711. See changelog at bottom)
One may think that Assembler is always the fastest, but is that true?.
If I write a code in Assembler in 32 bit instead of 64 bit, so it can run in 32 and 64 bit, will it be faster than the code that a dynamic compiler is optimizing in execution time to benefit from the architecture of my computer?.
What if a future JIT compiler is able to use all the cores to execute a single thread developed program?.
This article shows some results and shares my conclusions. It is as a base to discuss with my colleagues. Is not an end, we are always doing tests, looking for the edge, and looking at the root of the things in detail. And often things change from one version to the other. This article shows not an absolute truth, but brings some light into interesting aspects.
It could show the performance for the certain case used in the test, although generic core instructions have been selected. Many more tests are necessary, and some functions differ in the performance. But this article is a necessary starting for the discussion with my IT-extreme-lover friends and a necessary step for the next upcoming tests.
It brings very important data for Managers and Decision Makers, as choosing the adequate performance language can save millions in hardware (specially when you use the Cloud and pay per hour of use) or thousand hours in Map Reduce processes.
Acknowledgements and thanks
Credit for the great Eduard Heredia, for porting my C source code to:
Go
Ruby
Node.js
And for the nice discussions of the results, an on the optimizations and dynamic vs static compilers.
Thanks to Juan Carlos Moreno, CTO of ECManaged Cloud Software for suggesting adding Python and Ruby to the languages tested when we discussed my initial results.
Thanks to Joel Molins for the interesting discussions on Java performance and garbage collection.
I was inspired to do my own comparisons by the benchmarks comparing different framework by techempower. It is amazing to see the results of the tests, like how C++ can serialize JSon 1,057,793 times per second and raw PHP only 180,147 (17%).
For the impatients
I present the results of the tests, and the conclusions, for those that doesn’t want to read about the details. For those that want to examine the code, and the versions of every compiler, and more in deep conclusions, this information is provided below.
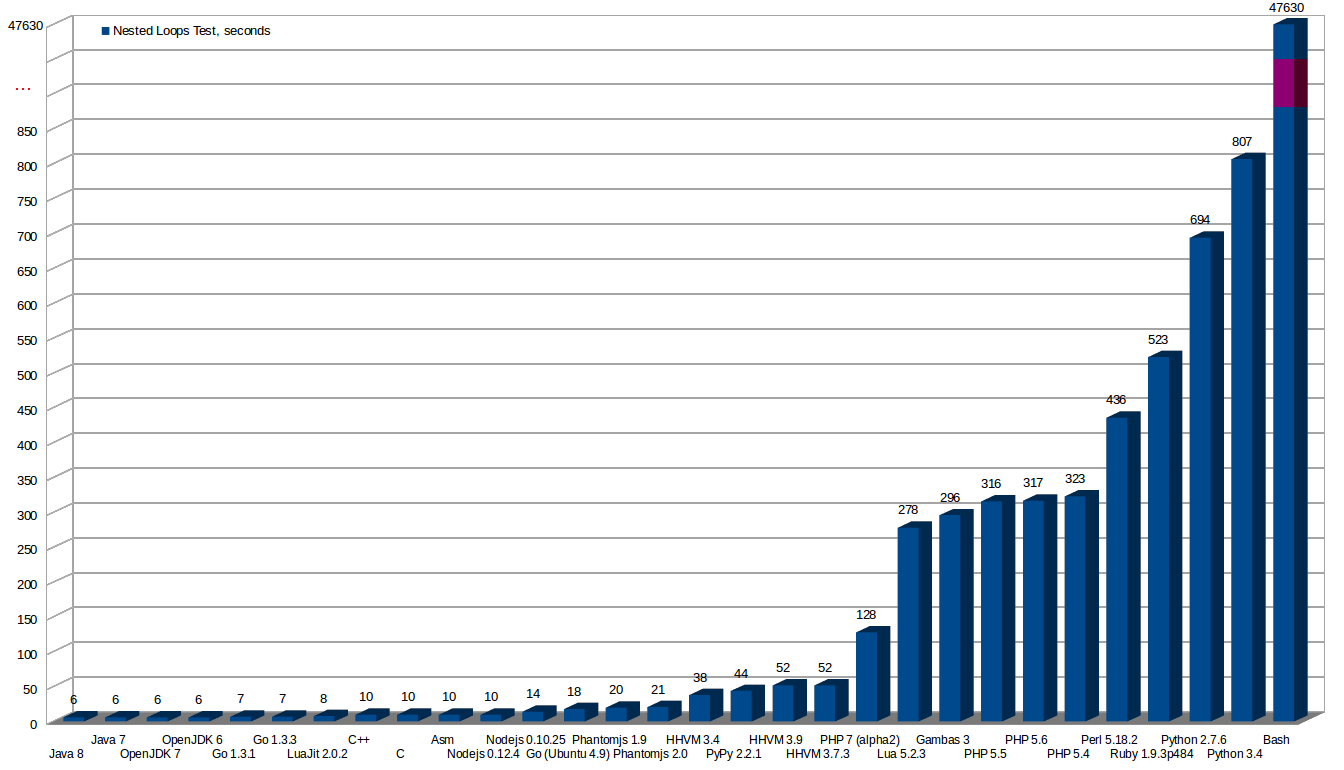
Results
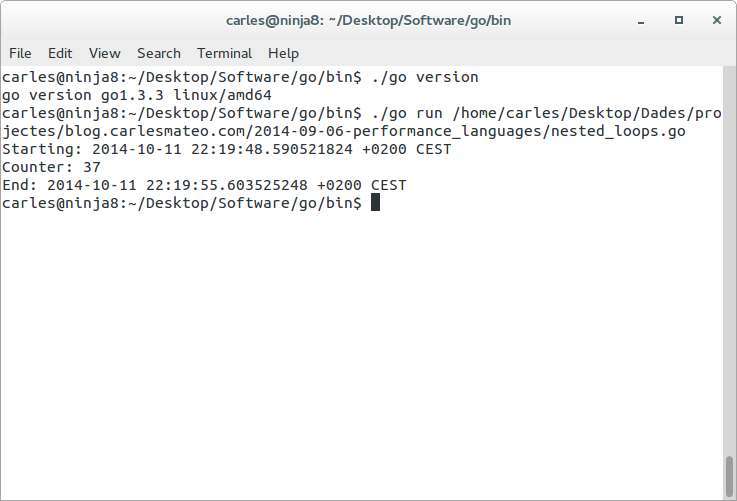
This image shows the results of the tests with every language and compiler.
All the tests are invoked from command line. All the tests use only one core. No tests for the web or frameworks have been made, are another scenarios worth an own article.
More seconds means a worst result. The worst is Bash, that I deleted from the graphics, as the bar was crazily high comparing to others.
* As later is discussed my initial Assembler code was outperformed by C binary because the final Assembler code that the compiler generated was better than mine.
After knowing why (later in this article is explained in detail) I could have reduced it to the same time than the C version as I understood the improvements made by the compiler.
Table of times:
Seconds executing
Language
Compiler used
Version
6 s.
Java
Oracle Java
Java JDK 8
6 s.
Java
Oracle Java
Java JDK 7
6 s.
Java
Open JDK
OpenJDK 7
6 s.
Java
Open JDK
OpenJDK 6
7 s.
Go
Go
Go v.1.3.1 linux/amd64
7 s.
Go
Go
Go v.1.3.3 linux/amd64
8 s.
Lua
LuaJit
Luajit 2.0.2
10 s.
C++
g++
g++ (Ubuntu 4.8.2-19ubuntu1) 4.8.2
10 s.
C
gcc
gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2
10 s.
(* first version was 13 s. and then was optimized)
Assembler
nasm
NASM version 2.10.09 compiled on Dec 29 2013
10 s.
Nodejs
nodejs
Nodejs v0.12.4
14 s.
Nodejs
nodejs
Nodejs v0.10.25
18 s.
Go
Go
go version xgcc (Ubuntu 4.9-20140406-0ubuntu1) 4.9.0 20140405 (experimental) [trunk revision 209157] linux/amd64
20 s.
Phantomjs
Phantomjs
phantomjs 1.9.0
21 s.
Phantomjs
Phantomjs
phantomjs 2.0.1-development
38 s.
PHP
Facebook HHVM
HipHop VM 3.4.0-dev (rel)
44 s.
Python
Pypy
Pypy 2.2.1 (Python 2.7.3 (2.2.1+dfsg-1, Nov 28 2013, 05:13:10))
GNU bash, version 4.3.11(1)-release (x86_64-pc-linux-gnu)
Conclusions and Lessons Learnt
There are languages that will execute faster than a native Assembler program, thanks to the JIT Compiler and to the ability to optimize the program at runtime for the architecture of the computer running the program (even if there is a small initial penalty of around two seconds from JIT when running the program, as it is being analysed, is it more than worth in our example)
Modern Java can be really fast in certain operations, it is the fastest in this test, thanks to the use of JIT Compiler technology and a very good implementation in it
Oracle’s Java and OpenJDK shows no difference in performance in this test
Script languages really sucks in performance. Python, Perl and Ruby are terribly slow. That costs a lot of money if you Scale as you need more Server in the Cloud
JIT compilers for Python: Pypy, and for Lua: LuaJit, make them really fly. The difference is truly amazing
The same language can offer a very different performance using one version or another, for example the go that comes from Ubuntu packets and the last version from official page that is faster, or Python 3.4 is much slower than Python 2.7 in this test
Bash is the worst language for doing the loop and inc operations in the test, lasting for more than 13 hours for the test
From command line PHP is much faster than Python, Perl and Ruby
Facebook Hip Hop Virtual Machine (HHVM) improves a lot PHP’s speed
It looks like the future of compilers is JIT.
Assembler is not always the fastest when executed. If you write a generic Assembler program with the purpose of being able to run in many platforms you’ll not use the most powerful instructions specific of an architecture, and so a JIT compiler can outperform your code. An static compiler can also outperform your code with very clever optimizations. People that write the compilers are really good. Unless you’re really brilliant with Assembler probably a C/C++ code beats the performance of your code. Even if you’re fantastic with Assembler it could happen that a JIT compiler notices that some executions can be avoided (like code not really used) and bring magnificent runtime optimizations. (for example a near JMP is much more less costly than a far JMP Assembler instruction. Avoiding dead code could result in a far JMP being executed as near JMP, saving many cycles per loop)
Optimizations really needs people dedicated to just optimizations and checking the speed of the newly added code for the running platforms
Node.js was a big surprise. It really performed well. It is promising. New version performs even faster
go is promising. Similar to C, but performance is much better thanks to deciding at runtime if the architecture of the computer is 32 or 64 bit, a very quick compilation at launch time, and it compiling to very good assembler (that uses the 64 bit instructions efficiently, for example)
Gambas 3 performed surprisingly fast. Better than PHP
You should be careful when using C/C++ optimization -O3 (and -O2) as sometimes it doesn’t work well (bugs) or as you may expect, for example by completely removing blocks of code if the compiler believes that has no utility (like loops)
Perl performance really change from using a for style or another. (See Perl section below)
Modern CPUs change the frequency to save energy. To run the tests is strictly recommended to use a dedicated machine, disabling the CPU governor and setting a frequency for all the cores, booting with a text only live system, without background services, not mounting disks, no swap, no network
(Please, before commenting read completely the article )
Explanations in details
Obviously an statically compiled language binary should be faster than an interpreted language.
C or C++ are much faster than PHP. And good code machine is much faster of course.
But there are also other languages that are not compiled as binary and have really fast execution.
For example, good Web Java Application Servers generate compiled code after the first request. Then it really flies.
For web C# or .NET in general, does the same, the IIS Application Server creates a native DLL after the first call to the script. And after this, as is compiled, the page is really fast.
With C statically linked you could generate binary code for a particular processor, but then it won’t work in other processors, so normally we write code that will work in all the processors at the cost of not using all the performance of the different CPUs or use another approach and we provide a set of different binaries for the different architectures. A set of directives doing one thing or other depending on the platform detected can also be done, but is hard, long and tedious job with a lot of special cases treatment. There is another approach that is dynamic linking, where certain things will be decided at run time and optimized for the computer that is running the program by the JIT (Just-in-time) Compiler.
Java, with JIT is able to offer optimizations for the CPU that is running the code with awesome results. And it is able to optimize loops and mathematics operations and outperform C/C++ and Assembler code in some cases (like in our tests) or to be really near in others. It sounds crazy but nowadays the JIT is able to know the result of several times executed blocks of code and to optimize that with several strategies, speeding the things incredible and to outperform a code written in Assembler. Demonstrations with code is provided later.
A new generation has grown knowing only how to program for the Web. Many of them never saw Assembler, neither or barely programmed in C++.
None of my Senior friends would assert that a technology is better than another without doing many investigations before. We are serious. There is so much to take in count, so much to learn always, that one has to be sure that is not missing things before affirming such things categorically. If you want to be taken seriously, you have to take many things in count.
Environment for the tests
Hardware and OS
Intel(R) Core(TM) i7-4770S CPU @ 3.10GHz with 32 GB RAM and SSD Disk.
Ubuntu Desktop 14.04 LTS 64 bit
Software base and compilers
PHP versions
Shipped with my Ubuntu distribution:
php -v
PHP 5.5.9-1ubuntu4.3 (cli) (built: Jul 7 2014 16:36:58)
Copyright (c) 1997-2014 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2014 Zend Technologies
with Zend OPcache v7.0.3, Copyright (c) 1999-2014, by Zend Technologies
LuaJIT 2.0.2 -- Copyright (C) 2005-2013 Mike Pall. http://luajit.org/
Nodejs
Installed with apt-get install nodejs:
nodejs --version
v0.10.25
Installed by compiling the sources:
node --version
v0.12.4
Phantomjs
Installed with apt-get install phantomjs:
phantomjs --version
1.9.0
Compiled from sources:
/path/phantomjs --version
2.0.1-development
Python 2.7
python --version
Python 2.7.6
Python 3
python3 --version
Python 3.4.0
Perl
perl -version
This is perl 5, version 18, subversion 2 (v5.18.2) built for x86_64-linux-gnu-thread-multi
(with 41 registered patches, see perl -V for more detail)
Bash
bash --version
GNU bash, version 4.3.11(1)-release (x86_64-pc-linux-gnu)
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Test: Time required for nested loops
This is the first sample. It is an easy-one.
The main idea is to generate a set of nested loops, with a simple counter inside.
When the counter reaches 51 it is set to 0.
This is done for:
Preventing overflow of the integer if growing without control
Preventing the compiler from optimizing the code (clever compilers like Java or gcc with -O3 flag for optimization, if it sees that the var is never used, it will see that the whole block is unnecessary and simply never execute it)
Doing only loops, the increment of a variable and an if, provides us with basic structures of the language that are easily transformed to Assembler. We want to avoid System calls also.
This is the base for the metrics on my Cloud Analysis of Performance cmips.net project.
Here I present the times for each language, later I analyze the details and the code.
Take in count that this code only executes in one thread / core.
C++
C++ result, it takes 10 seconds.
Code for the C++:
/*
* File: main.cpp
* Author: Carles Mateo
*
* Created on August 27, 2014, 1:53 PM
*/
#include <cstdlib>
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <ctime>
using namespace std;
typedef unsigned long long timestamp_t;
static timestamp_t get_timestamp()
{
struct timeval now;
gettimeofday (&now, NULL);
return now.tv_usec + (timestamp_t)now.tv_sec * 1000000;
}
int main(int argc, char** argv) {
timestamp_t t0 = get_timestamp();
// current date/time based on current system
time_t now = time(0);
// convert now to string form
char* dt_now = ctime(&now);
printf("Starting at %s\n", dt_now);
int i_loop1 = 0;
int i_loop2 = 0;
int i_loop3 = 0;
for (i_loop1 = 0; i_loop1 < 10; i_loop1++) {
for (i_loop2 = 0; i_loop2 < 32000; i_loop2++) {
for (i_loop3 = 0; i_loop3 < 32000; i_loop3++) {
i_counter++;
if (i_counter > 50) {
i_counter = 0;
}
}
// If you want to test how the compiler optimizes that, remove the comment
//i_counter = 0;
}
}
// This is another trick to avoid compiler's optimization. To use the var somewhere
printf("Counter: %i\n", i_counter);
timestamp_t t1 = get_timestamp();
double secs = (t1 - t0) / 1000000.0L;
time_t now_end = time(0);
// convert now to string form
char* dt_now_end = ctime(&now_end);
printf("End time: %s\n", dt_now_end);
return 0;
}
You can try to remove the part of code that makes the checks:
/* if (i_counter > 50) {
i_counter = 0;
}*/
And the use of the var, later:
//printf("Counter: %i\n", i_counter);
Note: And adding a i_counter = 0; at the beginning of the loop to make sure that the counter doesn’t overflows. Then the C or C++ compiler will notice that this result is never used and so it will eliminate the code from the program, having as result and execution time of 0.0 seconds.
Java
The code in Java:
package cpu;
/**
*
* @author carles.mateo
*/
public class Cpu {
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
int i_loop1 = 0;
//int i_loop_main = 0;
int i_loop2 = 0;
int i_loop3 = 0;
int i_counter = 0;
String s_version = System.getProperty("java.version");
System.out.println("Java Version: " + s_version);
System.out.println("Starting cpu.java...");
for (i_loop1 = 0; i_loop1 < 10; i_loop1++) {
for (i_loop2 = 0; i_loop2 < 32000; i_loop2++) {
for (i_loop3 = 0; i_loop3 < 32000; i_loop3++) {
i_counter++;
if (i_counter > 50) {
i_counter = 0;
}
}
}
}
System.out.println(i_counter);
System.out.println("End");
}
}
It is really interesting how Java, with JIT outperforms C++ and Assembler.
It takes only 6 seconds.
Go
The case of Go is interesting because I saw a big difference from the go shipped with Ubuntu, and the the go I downloaded from http://golang.org/dl/. I downloaded 1.3.1 and 1.3.3 offering the same performance. 7 seconds.
Here is the Assembler for Linux code, with SASM, that I created initially (bellow is optimized).
%include "io.inc"
section .text
global CMAIN
CMAIN:
;mov rbp, rsp; for correct debugging
; Set to 0, the faster way
xor esi, esi
DO_LOOP1:
mov ecx, 10
LOOP1:
mov ebx, ecx
jmp DO_LOOP2
LOOP1_CONTINUE:
mov ecx, ebx
loop LOOP1
jmp QUIT
DO_LOOP2:
mov ecx, 32000
LOOP2:
mov eax, ecx
;call DO_LOOP3
jmp DO_LOOP3
LOOP2_CONTINUE:
mov ecx, eax
loop LOOP2
jmp LOOP1_CONTINUE
DO_LOOP3:
; Set to 32000 loops
MOV ecx, 32000
LOOP3:
inc esi
cmp esi, 50
jg COUNTER_TO_0
LOOP3_CONTINUE:
loop LOOP3
;ret
jmp LOOP2_CONTINUE
COUNTER_TO_0:
; Set to 0
xor esi, esi
jmp LOOP3_CONTINUE
; jmp QUIT
QUIT:
xor eax, eax
ret
It took 13 seconds to complete.
One interesting explanation on why binary C or C++ code is faster than Assembler, is because the C compiler generates better Assembler/binary code at the end. For example, the use of JMP is expensive in terms of CPU cycles and the compiler can apply other optimizations and tricks that I’m not aware of, like using faster registers, while in my code I use ebx, ecx, esi, etc… (for example, imagine that using cx is cheaper than using ecx or rcx and I’m not aware but the guys that created the Gnu C compiler are)
To be sure of what’s going on I switched in the LOOP3 the JE and the JMP of the code, for groups of 50 instructions, INC ESI, one after the other and the time was reduced to 1 second.
(In C also was reduced even a bit more when doing the same)
To know what’s the translation of the C code into Assembler when compiled, you can do:
objdump --disassemble nested_loops
Look for the section main and you’ll get something like:
Note: this is in the AT&T syntax and not in the Intel. That means that add $0x1,%edx is adding 1 to EDX registerg (origin, destination).
As you can see the C compiler has created a very differed Assembler version respect what I created.
For example at 400470 it uses EDI register to store 10, so to control the number of the outer loop.
It uses ESI to store 32000 (Hexadecimal 0x7D00), so the second loop.
And EAX for the inner loop, at 400480.
It uses EDX for the counter, and compares to 50 (Hexa 0x33) at 40048B.
In 40048E it uses the CMOVGE (Mov if Greater or Equal), that is an instruction that was introduced with the P6 family processors, to move the contents of ECX to EDX if it was (in the CMP) greater or equal to 50. As in 400475 a XOR ECX, ECX was performed, EXC contained 0.
And it cleverly used SUB and JNE (JNE means Jump if not equal and it jumps if ZF = 0, it is equivalent to JNZ Jump if not Zero).
It uses between 4 and 16 clocks, and the jump must be -128 to +127 bytes of the next instruction. As you see Jump is very costly.
Looks like the biggest improvement comes from the use of CMOVGE, so it saves two jumps that my original Assembler code was performing.
Those two jumps multiplied per 32000 x 32000 x 10 times, are a lot of Cpu clocks.
So, with this in mind, as this Assembler code takes 10 seconds, I updated the graph from 13 seconds to 10 seconds.
Lua
This is the initial code:
local i_counter = 0
local i_time_start = os.clock()
for i_loop1=0,9 do
for i_loop2=0,31999 do
for i_loop3=0,31999 do
i_counter = i_counter + 1
if i_counter > 50 then
i_counter = 0
end
end
end
end
local i_time_end = os.clock()
print(string.format("Counter: %i\n", i_counter))
print(string.format("Total seconds: %.2f\n", i_time_end - i_time_start))
In the case of Lua theoretically one could take great advantage of the use of local inside a loop, so I tried the benchmark with modifications to the loop:
for i_loop1=0,9 do
for i_loop2=0,31999 do
local l_i_counter = i_counter
for i_loop3=0,31999 do
l_i_counter = l_i_counter + 1
if l_i_counter > 50 then
l_i_counter = 0
end
end
i_counter = l_i_counter
end
end
I ran it with LuaJit and saw no improvements on the performance.
Node.js
var s_date_time = new Date();
console.log('Starting: ' + s_date_time);
var i_counter = 0;
for (var $i_loop1 = 0; $i_loop1 < 10; $i_loop1++) {
for (var $i_loop2 = 0; $i_loop2 < 32000; $i_loop2++) {
for (var $i_loop3 = 0; $i_loop3 < 32000; $i_loop3++) {
i_counter++;
if (i_counter > 50) {
i_counter = 0;
}
}
}
}
var s_date_time_end = new Date();
console.log('Counter: ' + i_counter + '\n');
console.log('End: ' + s_date_time_end + '\n');
Execute with:
nodejs nested_loops.js
Phantomjs
The same code as nodejs adding to the end:
phantom.exit(0);
In the case of Phantom it performs the same in both versions 1.9.0 and 2.0.1-development compiled from sources.
PHP
The interesting thing on PHP is that you can write your own extensions in C, so you can have the easy of use of PHP and create functions that really brings fast performance in C, and invoke them from PHP.
from datetime import datetime
import time
print ("Starting at: " + str(datetime.now()))
s_unixtime_start = str(time.time())
i_counter = 0
# From 0 to 31999
for i_loop1 in range(0, 10):
for i_loop2 in range(0,32000):
for i_loop3 in range(0,32000):
i_counter += 1
if ( i_counter > 50 ) :
i_counter = 0
print ("Ending at: " + str(datetime.now()))
s_unixtime_end = str(time.time())
i_seconds = long(s_unixtime_end) - long(s_unixtime_start)
s_seconds = str(i_seconds)
print ("Total seconds:" + s_seconds)
Ruby
#!/usr/bin/ruby -w
time1 = Time.new
puts "Starting : " + time1.inspect
i_counter = 0;
for i_loop1 in 0..9
for i_loop2 in 0..31999
for i_loop3 in 0..31999
i_counter = i_counter + 1
if i_counter > 50
i_counter = 0
end
end
end
end
time1 = Time.new
puts "End : " + time1.inspect
Perl
The case of Perl was very interesting one.
This is the current code:
#!/usr/bin/env perl
print "$s_datetime Starting calculations...\n";
$i_counter=0;
$i_unixtime_start=time();
for my $i_loop1 (0 .. 9) {
for my $i_loop2 (0 .. 31999) {
for my $i_loop3 (0 .. 31999) {
$i_counter++;
if ($i_counter > 50) {
$i_counter = 0;
}
}
}
}
$i_unixtime_end=time();
$i_seconds=$i_unixtime_end-$i_unixtime_start;
print "Counter: $i_counter\n";
print "Total seconds: $i_seconds";
But before I created one, slightly different, with the for loops like in the C style:
I repeated this test, with the same version of Perl, due to the comment of a reader (thanks mpapec) that told:
“In this particular case perl style loops are about 45% faster than original code (v5.20)”
And effectively and surprisingly the time passed from 796 seconds to 436 seconds.
So graphics are updated to reflect the result of 436 seconds.
Bash
#!/bin/bash
echo "Bash version ${BASH_VERSION}..."
date
let "s_time_start=$(date +%s)"
let "i_counter=0"
for i_loop1 in {0..9}
do
echo "."
date
for i_loop2 in {0..31999}
do
for i_loop3 in {0..31999}
do
((i_counter++))
if [[ $i_counter > 50 ]]
then
let "i_counter=0"
fi
done
#((var+=1))
#((var=var+1))
#((var++))
#let "var=var+1"
#let "var+=1"
#let "var++"
done
done
let "s_time_end=$(date +%2)"
let "s_seconds = s_time_end - s_time_start"
echo "Total seconds: $s_seconds"
# Just in case it overflows
date
Gambas 3
Gambas is a language and an IDE to create GUI applications for Linux.
It is very similar to Visual Basic, but better, and it is not a clone.
I created a command line application and it performed better than PHP. There has been done an excellent job with the compiler.
Note: in the screenshot the first test ran for few seconds more than in the second. This was because I deliberately put the machine under some load and I/O during the tests. The valid value for the test, confirmed with more iterations is the second one, done under the same conditions (no load) than the previous tests.
' Gambas module file MMain.module
Public Sub Main()
' @author Carles Mateo http://blog.carlesmateo.com
Dim i_loop1 As Integer
Dim i_loop2 As Integer
Dim i_loop3 As Integer
Dim i_counter As Integer
Dim s_version As String
i_loop1 = 0
i_loop2 = 0
i_loop3 = 0
i_counter = 0
s_version = System.Version
Print "Performance Test by Carles Mateo blog.carlesmateo.com"
Print "Gambas Version: " & s_version
Print "Starting..." & Now()
For i_loop1 = 0 To 9
For i_loop2 = 0 To 31999
For i_loop3 = 0 To 31999
i_counter = i_counter + 1
If (i_counter > 50) Then
i_counter = 0
Endif
Next
Next
Next
Print i_counter
Print "End " & Now()
End
Changelog
2015-08-26 15:45
Thanks to the comment of a reader, thanks Daniel, pointing a mistake. The phrase I mentioned was on conclusions, point 14, and was inaccurate. The original phrase told “go is promising. Similar to C, but performance is much better thanks to the use of JIT“. The allusion to JIT is incorrect and has been replaced by this: “thanks to deciding at runtime if the architecture of the computer is 32 or 64 bit, a very quick compilation at launch time, and it compiling to very good assembler (that uses the 64 bit instructions efficiently, for example)”
2015-07-17 17:46
Benchmarked Facebook HHVM 3.9 (dev., the release date is August 3 2015) and HHVM 3.7.3, they take 52 seconds.
Re-benchmarked Facebook HHVM 3.4, before it was 72 seconds, it takes now 38 seconds. I checked the screen captures from 2014 to discard an human error. Looks like a turbo frequency issue on the tests computer, with the CPU governor making it work bellow the optimal speed or a CPU-hungry/IO process that triggered during the tests and I didn’t detect it. Thinking about forcing a fixed CPU speed for all the cores for the tests, like 2.4 Ghz and booting a live only text system without disk access and network to prevent Ubuntu launching processes in the background.
2015-07-05 13:16
Added performance of Phantomjs 1.9.0 installed via apt-get install phantomjs in Ubuntu, and Phantomjs 2.0.1-development.
Added performance of nodejs 0.12.04 (compiled).
Added bash to the graphic. It has so bad performance that I had to edit the graphic to fit in (color pink) in order prevent breaking the scale.
2015-07-03 18:32
Added benchmarks for PHP 7 alpha 2, PHP 5.6.10 and PHP 5.4.42.
2015-07-03 15:13
Thanks to the contribution of a reader (thanks mpapec!) I tried with Perl for style, resulting in passing from 796 seconds to 436 seconds.
(I used the same Perl version: Perl 5.18.2)
Updated test value for Perl.
Added new graphics showing the updated value.
Thanks to the contribution of a reader (thanks junk0xc0de!) added some additional warnings and explanations about the dangers of using -O3 (and -O2) if C/C++.
Updated the Lua code, to print i_counter and do the if i_counter > 50
This makes it take a bit longer, few cents, but passing from 7.8 to 8.2 seconds.
Updated graphics.
This year I was invited to speak at the PHP Conference at Berlin 2014.
It was really nice, but I had to decline as I was working hard in a Start up, and I hadn’t the required time in order to prepare the nice conference I wanted and that people deserves.
However, having time, I decided to write an article about what I would had speak at the conference.
I will cover improving performance in a single server, and Scaling out multi-Server architecture, focusing on the needs of growing and Start up projects. Many of those techniques can be used to improve performance with other languages, not just with PHP.
Many of my friends are very good Developing, but know nothing about Architecture and Scaling. Hope this approach the two worlds, Development ad Operatings, into a DevOps bridge.
Improving performance on a single server
Hosting
Choose a good hosting. And if you can afford it choose a dedicated server.
Shared hostings are really bad. Some of them kill your http and mysql instances if you reach certain CPU use (really few), while others share the same hardware between 100+ users serving your pages sloooooow. Others cap the amount of queries that your MySql will handle per hour at so ridiculous few amount that even Drupal or WordPress are unable to complete a request in development.
Other ISP (Internet Service Providers) have poor Internet bandwidth, and so you web will load slow to users.
Some companies invest hundreds of thousands in developing a web, and then spend 20 € a year in the hosting. Less than the cost of a dinner.
You can use a decent dedicated server from 50 to 99 €/month and you will celebrate this decision every day.
Take in count that virtualization wastes between 20% and 30% of the CPU power. And if there are several virtual machines the loss will be more because you loss the benefits of the CPU caching for optimizing parallel instructions execution and prediction. Also if the hypervisor host allows to allocate more RAM than physically available and at some point it swaps, the performance of all the VM’s will be much worst.
If you have a VM and it swaps, in most providers the swap goes over the network so there is an additional bottleneck and performance penalty.
To compare the performance of dedicated servers and instances from different Cloud Providers you can take a look at my project cmips.net
Improve your Server
If your Sever has few RAM, add more. And if your project is running slow and you can afford a better Server, do it.
Using SSD disk will incredibly improve the performance on I/O operations and on swap operations. (but please, do backups and keep them in another place)
If you use a CMS like ezpublish with http_cache enabled probably you will prefer to have a Server with faster cores, rather tan a Server with one or more CPU’s plenty of cores, but slower cores, and that last for a longer time to render the page to the http cache.
That may seem obvious but often companies invest 320 hours in optimizing the code 2%, at a cost of let’s say 50 €/h * 320 hours = 16.000 €, while hiring a better Server would had bring between a 20% to 1000% improvement at a cost of additional 50€/month only or at the cost of 100 € of increasing the RAM memory.
The point here is that the hardware is cheap, while the time of the Engineers is expensive. And good Engineers are really hard to find.
And you probably, as a CEO or PO, prefer to use the talent to warranty a nice time to market for your project, or adding more features, rather than wasting this time in refactorizing.
Even with the most optimal code in the universe, if your project is successful at certain point you’ll have to scale. So adding more Servers. To save a Server now at the cost of slowing the business has not any sense.
Upgrade you PHP version
Many projects still use PHP 5.3, and 5.4.
Latest versions of PHP bring more and more performance. If you use old versions of PHP you can have a Quick Win by just upgrading to the last PHP version.
Use OpCache (or other cache accelerator)
OpCache is shipped with PHP 5.5 by default now, so it is the recommended option. It is though to substitute APC.
To activate OpCache edit php.ini and add:
Linux/Unix:
zend_extension=/path/to/opcache.so
Windows:
zend_extension=C:\path\to\php_opcache.dll
It will greatly improve your PHP performance.
Ensure that OpCache in Production has the optimal config for Production, that will be different from Development Environment.
Note: If you plan to use it with XDebug in Development environments, load OpCache before XDebug.
Disable Profiling and xdebug in Production
In Production disable the profiling, xdebug, and if you use a Framework ensure the Development/Debug features are disabled in Production.
Ensure your logs are not full of warnings
Check that Production logs are not full of warnings.
I’ve seen systems were every seconds 200 warnings were written to logs, the same all the time, and that obviously was slowing down the system.
Typical warnings like this can be easily fixed:
Message: date() [function.date]: It is not safe to rely on the system’s timezone settings. You are required to use the date.timezone setting or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected ‘UTC’ for ‘8.0/no DST’ instead
Profile in Development
To detect where your slow code is, profile it in Development to see where it is spent the most CPU/time.
Check the slow-queries if you use MySql.
Cache html to disk
Imagine you have a sort of craigslist and you are displaying all the categories, and the number of new messages in this landing page. To do that you are performing many queries to the database, SELECT COUNTs, etc… every time a user visits your page. That certainly will overload your database with actually few concurrent visitors.
Instead of querying the Database all the time, do cache the generated page for a while.
This can be achieved by checking if the cache html file exists, and checking the TTL, and generating a new page if needed.
A simple sample would be:
<?php
// Cache pages for 5 minutes
$i_cache_TTL = 300;
$b_generate_cache = false;
$s_cache_file = '/tmp/index.cache.html';
if (file_exists($s_cache_file)) {
// Get creation date
$i_file_timestamp = filemtime($s_cache_file);
$i_time_now = microtime(true);
if ($i_time_now > ($i_file_timestamp + $i_cache_TTL)) {
$b_generate_cache = true;
} else {
// Up to date, get from the disk
$o_fh = fopen($s_cache_file, "rb");
$s_html = stream_get_contents($o_fh);
fclose($o_fh);
// If the file was empty something went wrong (disk full?), so don't use it
if (strlen($s_html) == 0) {
$b_generate_cache = true;
} else {
// Print the page and exit
echo $s_html;
exit();
}
}
} else {
$b_generate_cache = true;
}
ob_start();
// Render your page normally here
// ....
$s_html = ob_get_clean();
if ($b_generate_cache == true) {
// Create the file with fresh contents
$o_fp = fopen($s_cache_file, 'w');
if (fwrite($o_fp, $s_html) === false) {
// Error. Impossible to write to disk
// throw new Exception('CacheCantWrite');
}
fclose($o_fp);
}
// Send the page to the browser
echo $s_html;
This sample is simple, and works for many cases, but presents problems.
Imagine for example that the page takes 5 seconds to be generated with a single request, and you have high traffic in that page, let’s say 500 requests per second.
What will happen when the cache expires is that the first user will trigger the cache generation, and the second, and the third…. so all of the 500 requests * 5 seconds will be hitting the database to generate the cache, but… if creating the page per one requests takes 5 seconds, doing this 2,500 times will not last 5 seconds… so your process will enter in a vicious state where the first queries have not ended after minutes, and more and more queries are being added to the queue until:
a) Apache runs out of childs/processes, per configuration
b) Mysql runs out of connections, per configuration
c) Linux runs out of memory, and processes crashes/are killed
Not to mention the users or the API client, waiting infinitely for the http request to complete, and other processes reading a partial file (size bigger than 0 but incomplete).
Different strategies can be used to prevent that, like:
a) using semaphores to lock access to the cache generation (only one process at time)
b) using a .lock file to indicate that the file is being generated, and so next requests serving from the cache until the cache generation process ends the task, also writing to a buffer like acachefile.buffer (to prevent incomplete content being read) and finally when is complete renaming to the final name and removing the .lock
c) using memcached, or similar, to keep an index in memory of what pages are being generated now, and why not, keeping the cached files there instead of a filesystem
d) using crons to generate the cache files, so they run hourly and you ensure only one process generates the cache files
If you use crons, a cheap way to generate the .html content is that the crons curls/wget your webpage. I don’t recommend this as has some problems, like if that web request fails for any reason, you’ll have cached an error instead of content.
I prefer preparing my projects to being able of rendering the content being invoked from HTTP/S or from command line. But if you use curl because is cheap and easy and time to market is important for your project, then be sure that you check that your backend code writes an Status OK in the HTML that the cron can check to ensure that the content has been properly generated. (some crons only check for http status, like 200, but if your database or a xml gateway you use fails you will likely get a 200 and won’t detect that you’re caching pages with “error I can’t connect to the database” instead)
Many Frameworks have their own cache implementation that prevent corruption that could come by several processes writing to the same file at the same time, or from PHP dying in the middle of the render.
You can see a more complex MVC implementation, with Views, from my Framework Catalonia here:
By serving .html files instead of executing PHP with logic and performing queries to the database you will be able to serve hundreds of thousands requests per day with a single machine and really fast -that’s important for SEO also-.
I’ve done this in several Start ups with wonderful results, and my Framework Catalonia also incorporates this functionality very easily to use.
Note: This is only one of the techniques to save the load of the Database Servers. Many more come later.
Cache languages to disk
If you have an application that is multi-language, or if your point for the Strings (sections, pages, campaigns..) to be edited by Marketing is the Database, there is no need to query it all the time.
Simply provide a tool to “generate language files”.
Your languages files can be Javascript files loaded by the page, or can be PHP files generated.
For example, the file common_footer_en.php could be generated reading from Database and be like that:
<php
/* Autogenerated English translations file common_footer_en.php
on 2014-08-10 02:22 from the database */
$st_translations['seconds'] = 'seconds';
$st_translations['Time'] = 'Time';
$st_translations['Vars used'] = 'Vars used in these templates';
$st_translations['Total Var replacements'] = 'Total replaced';
$st_translations['Exec time'] = 'Execution time';
$st_translations['Cached controller'] = 'Cached controller';
So the PHP file is going to be generated when someone at your organization updates the languages, and your code is including it normally like with any other PHP file.
Use the Crons
You can set cron jobs to do many operations, like map reduce, counting in the database or effectively deleting the data that the user selected to delete.
Imagine that you have classified portal, and you want to display the number of announces for that category. You can have a table NUM_ANNOUNCES to store the number of announces, and update it hourly. Then your database will only do the counting once per hour, and your application will be reading the number from the table NUM_ANNOUNCES.
The Cron can also be used to make expire old announces. That way you can avoid a user having to wait for that clean up taking process when you have a http request to PHP.
A cron file can be invoked by:
php -f cron.php
By:
./cron.php
If you give permissions of execution with chmod +x and set the first line in cron.php as:
#!/usr/bin/env php
Or you can do a trick, that is emulate a http request from bash, by invoking a url with curl or with wget. Set the .htaccess so the folder for the cron tasks can only be executed from localhost for adding security.
This last trick has the inconvenient that the calling has the same problems as any http requests: restarting Apache will kill the process, the connection can be closed by timed out (e.g. if process is taking more seconds than the max. execution time, etc…)
Use Ramdisk for PHP files
With Linux is very easy to setup a RamDisk.
You can setup a RamDisk and rsync all your web .PHP files at system boot time, and when deploying changes, and config Apache to use the Ramdisk folder for the website.
That way for every request to the web, PHP files will be served from RAM directly, saving the slow disk access. Even with OpCache active, is a great improvement.
At these times were one Gigabyte of memory is really cheap there is a huge difference from reading files from disk, and getting them from memory. (Reading and writing to RAM memory is many many many times faster than magnetic disks, and many times faster than SSD disks)
Also .js, .css, images… can be served from a Ram disk folder, depending on how big your web is.
Ramdisk for /tmp
If your project does operations on disk, like resizing images, compressing files, reading/writing large CSV files, etcetera you can greatly improve the performance by setting the /tmp folder to a Ramdisk.
If your PHP project receives file uploads they will also benefit (a bit) from storing the temporal files to RAM instead to the disk.
Use Cache Lite
Cache Lite is a Pear extension that allows you to keep data in a local cache of the Web Server.
You can cache .html pages, or you can cache Queries and their result.
<?php
require_once "Cache/Lite.php";
$options = array(
'cacheDir' => '/tmp/',
'lifeTime' => 7200,
'pearErrorMode' => CACHE_LITE_ERROR_DIE
);
$cache = new Cache_Lite($options);
if ($data = $cache->get('id_of_the_page')) {
// Cache hit !
// Content is in $data
echo $data;
} else {
// No valid cache found (you have to make and save the page)
$data = '<html><head><title>test</title></head><body><p>this is a test</p></body></html>';
echo $data;
$cache->save($data);
}
It is nice that Cache Lite handles the TTL and keeps the info stored in different sub-directories in order to keep a decent performance. (As you may know many files in the same directory slows the access much).
Use HHVM (HipHop Virtual Machine) from Facebook
Facebook Engineers are always trying to optimize what is run on the Servers.
Faster code means, less machines. Even 1% of CPU use improvement means a lot of Servers less. Less Servers to maintain, less money wasted, less space on the Data Centers…
So they created the HHVM HipHop Virtual Machine that is able to run PHP code, much much faster than PHP. And is compatible with most of the Frameworks and Open Source projects.
They also created the Hack language that is an improved PHP, with type hinting.
So you can use HHVM to make your code run faster with the same Server and without investing a single penny.
Use C extensions
You can create and use your own C extensions.
C extensions will bring really fast execution. Just to get the idea:
I built a PHP extension to compare the performance from calculating the Bernoulli number with PHP and with the .so extension created in C.
In my Core i7 times were:
PHP:
Computed in 13.872583150864 s
PHP calling the C compiled extension:
Computed in 0.038495063781738 s
That’s 360.37 times faster using the C extension. Not bad.
Use Zephir
Zephir is a an Open Source language, very similar to PHP, that allows to create and maintain easily extensions for PHP.
Use Phalcon
Phalcon is a Web MVC Framework implemented as C extension, so it offers a high performance.
Check if you’re using the correct Engine for MySql
Many Developers create the tables and never worry about that. And many are using MyIsam by default. It was the by default Engine prior to MySql 5.5.
While MyIsam can bring good performance in some certain cases, my recommendation is to use InnoDb.
Normally you’ll have a gain in performance with MyIsam if you’ve a table were you only write or only read, but in all the other cases InnoDb is expected to be much more performant and safe.
MyIsam tables also get corruption from time to time and need manually fixing and writing to disks are not so reliable than InnoDb.
As MyIsam uses table-locking for updates and deletes to any existing row, it is easy to see that if you’re in a web environment with multiple users, blocking the table -so the other operations have to wait- will make things be slow.
If you have to use Joins clearly you will benefit from using InnoDb also.
Use InMemory Engine from MySql
MySql has a very powerful Engine called InMemory.
The InMemory Engine will store things in RAM and loss the data when MySql is restarted.
However is very fast and very easy to use.
Imagine that you have a travel application that constantly looks at which country belongs the city specified by user. A Quickwin would be to INSERT all this data in the InMemory Engine of MySql when it is started, and do just one change in your code: to use that Table.
Really easy. Quick improvement.
Use curl asynchronously
If your PHP has to communicate with other systems using curl, you can do the http/s call, and instead of waiting for a response let your PHP do more things in the meantime, and then check the results.
You can also call to multiple curl calls in parallel, and so avoid doing one by one in serial.
Guess that you have a query that returns 1000 results. Then you add one by one to an array.
Probably you’re going to have substantial gain if you keep in the database a single row, with the array serialized.
So an array like:
$st_places = Array(‘Barcelona’, ‘Dublin’, ‘Edinburgh’, ‘San Francisco’, ‘London’, ‘Berlin’, ‘Andorra la Vella’, ‘Prats de Lluçanès’);
Would be serialized to an string like:
a:8:{i:0;s:9:”Barcelona”;i:1;s:6:”Dublin”;i:2;s:9:”Edinburgh”;i:3;s:13:”San Francisco”;i:4;s:6:”London”;i:5;s:6:”Berlin”;i:6;s:16:”Andorra la Vella”;i:7;s:19:”Prats de Lluçanès”;}
This can be easily stored as String and unserialized later back to an array.
Note: In Internet we have a lot of encodings, Hebrew, Japanese… languages. Be careful with encodings when serializing, using JSon, XML, storing in databases without UTF support, etc…
Use Memcached to store common things
Memcached is a NoSql database in memory that can run in cluster.
The idea is to keep things there, in order to offload the load of the database. And as everything is in RAM it really runs fast.
You can use Memcached to cache Queries and their results also.
For example:
You have query SELECT * FROM translations WHERE section=’MAIN’.
Then you look if that String exists as key in the Memcached, and if it exists you fetch the results (that are serialized) and you avoid the query. If it doesn’t exist, you do normally the query to the database, serialize the array and store it in the Memcached with a TTL (Time to Live) using the Query (String) as primary key. For security you may prefer to hash the query with MD5 or SHA-1 and use the hash as key instead of using it plain.
When the TTL is reached the validity of the data would have expired and so it’s time to reinsert the contents in the next query.
Be careful, I’ve seen projects that were caching private data from users without isolating the key properly, so other users were getting the info from other users.
For example, if the key used was ‘Name’ and the value ‘Carles Mateo’ obviously the next user that fetch the key ‘Name’ would get my name and not theirs.
If you store private data of users in Memcache, it is a nice idea to append the owner of that info to the hash. E.g. using key: 10701577-FFADCEDBCCDFFFA10C
Where ‘10701577’ would be the user_id of the owner of the info, and ‘FFADCEDBCCDFFFA10C’ a hash of the query.
Before I suggested that you can keep a table of counting for the announces in a classified portal. This number can be stored in the Memcached instead.
You can store also common things, like translations, or cities like in the example before, rate of change for a currency exchanging website…
The most common way to store things there is serialized or Json encoded.
Be aware of the memory limits of Memcached and contrl the cache hitting ratio to avoid inserting data, and losing it constantly because is used few and Memcached has few memory.
Use jQuery for Production (small file) and minimized files for js
Use the Production jQuery library in Production, I mean do not use the bigger file Development jQuery library for Production.
There are product that eliminate all the necessary spaces in .js and .css files, and so are served much faster. These process is called minify.
It is important to know that in many emerging markets in the world, like Brazil, they have slow DSL lines. Many 512 Kbit/secons, and even modem connections!.
Activate compression in the Server
If you send large text files, or Jsons, you’ll benefit from activating the compression at the Server.
It consumes some CPU, but many times it brings an important improvement in speed serving the pages to the users.
Use a CDN
You can use a Content Delivery Network to offload your Servers from sending plain texts, html, images, videos, js, css…
You can delegate this to the CDN, they have very speedy Internet lines and Servers, so your Servers can concentrate into doing only BackEnd operations.
Please take attention to the documentation, a common mistake is to send Cache Headers to the CDN servers, while they’ll use this headers to set the cache TTL and ignore their web configuration parameters. (For example s-maxage, like: Cache-Control: public, s-maxage=600)
You can take a look at any website by telneting to the port 80 and doing the request manually or easily by using lynx:
lynx -mime_header http://blog.carlesmateo.com | less
Do you need a Framework?
If you’re processing only BackEnd petitions, like in the video games industry, serving API’s, RESTful, etc… you probably don’t need a Framework.
The Frameworks are generic and use much more resources than you’re really need for a fast reply.
Many times using a heavy Framework has a cost of factor times, compared to use simply PHP.
Save database connections until really needed
Many Frameworks create a connection to the Database Server by default. But certain parts of your code application do not require to connect to the database.
For example, validating the data from a form. If there are missing fields, the PHP will not operate with the Database, just return an error via JSon or refreshing the page, informing that the required field is missing.
If a not logged user is requesting the dashboard page, there is no need to open a connection to the database (unless you want to write the access try to an error log in the database).
In fact opening connections by default makes easier for attackers to do DoS attacks.
With a Singleton pattern you can easily implement a Db class that handles this transparently for you.
Scaling out / Multi Server Environment
Memcached session
When you have several Web Servers you’ll need something more flexible than the default PHP handler (that stores to a file in the Web Server).
The most common is to store the Session, serialized, in a Memcached Cluster.
Use Cassandra
Apache Cassandra is a NoSql database that allows to Scale out very easily.
The main advantage is that scales linearly. If you have 4 nodes and add 4 more, your performance will be doubled. It has no single point of failure, is also resilient to node failures, it replicates the data among the nodes, splits the load over the nodes automatically and support distributed datacenter architectures.
A easy way to split the load is to have a MySql primary Server, that handles the writes, and MySql secondary (or Slave) Servers handling the reads.
Every write sent to the Master is replicated into the Slaves. Then your application reads from the slaves.
You have to tell your code to do the writes to database to the primary Server, and the reads to the secondaries. You can have a Load Balancer so your code always ask the Load Balancer for the reads and it makes the connection to the less used server.
Do Database sharding
To shard the data consist into splitting the data according to a criteria.
For example, imagine we have 8 MySql Servers, named mysql0 to mysql7. If we want to insert or read data for user 1714, then the Server will be chosen from dividing the user_id, so 1714, between the number of Servers, and getting the MOD.
So 1714 % 8 gives 2. This means that the MySql Server to use is the mysql2.
For the user_id 16: 16 & 8 gives 0, so we would use mysql0. And so.
You can shard according to the email, or other fields as well. And you can have the same master and secondaries for the shards also.
When doing sharding in MySql you cannot do joins to data in other Servers. (but you can replicate all the data from the several shards in one big server in house, in your offices, and so query it and join if you need that for marketing purposes).
I always use my own sharding, but there is a very nice product from CodeFutures called dbshards. It handles the traffics transparently. I used it when in a video games Start up with very satisfying result.
Use Cassandra assync queries
Cassandra support asynchronous queries. That means you can send the query to the Server, and instead of waiting, do other jobs. And check for the result later, when is finished.
Consider using Hadoop + HBASE
A Cluster alternative to Cassandra.
Use a Load Balancer
You can put a Load Balancer or a Reverse Proxy in front of your Web Servers. The Load Balancer knows the state of the Web Servers, so it will remove a Web Server from the Array if it stops responding and everything will continue being served to the users transparently.
There are many ways to do Load Balancing: Round Robin, based on the load on the Web Servers, on the number of connections to each Web Server, by cookie…
To use a Cookie based Load Balancer is a very easy way to split the load for WordPress and Drupal Servers.
Imagine you have 10 Web Servers. In the .htaccess they set a rule to set a Cookie like:
SERVER_ID=WEB01
That was in the case of the first Web Server.
Second Server would have in the .htaccess to set a Cookie like:
SERVER_ID=WEB02
Etcetera
When for first time an user connects to the Load Balancer it sends the user to one of the 10 Web Servers. Then the Web Server sends its cookie to the browser of the Client. E.g. WEB07
After that, in the next requests from the client it will be redirected to the server by the Load Balancer to the Server that set the Cookie, so in this example WEB07.
The nice thing of this way of splitting the traffic is that you don’t have to change your code, nor handling the Sessions different.
If you use two Load Balancers you can have a heartbeat process in them and a Virtual Ip, and so in case your main Load Balancer become irresponsible the Virtual Ip will be mapping to the second Load Balancer in milliseconds. That provides HA.
Use http accelerators
Nginx, varnish, squid… to serve static content and offload the PHP Web Servers.
Auto-Scale in the Cloud
If you use the Cloud you can easily set Auto-Scaling for different parts of your core.
A quick win is to Scale the Web Servers.
As in the Cloud you pay per hour using a computer, you will benefit from cost reduction in you stop using the servers when you don’t need them, and you add more Servers when more users are coming to your sites.
Video game companies are a good example of hours of plenty use and valleys with few users, although as users come from all the planet it is most and most diluted.
Actually the Performance of the Google Cloud to Scale without any precedent is great.
Opposite to other Clouds that are based on instances, Google Cloud offers the platform, that will spawn your code across so many servers as needed, transparently to you. It’s a black box.
Schedule operations with RabbitMQ
Or other Queue Manager.
The idea is to send the jobs to the Queue Manager, the PHP will continue working, and the jobs will be performed asynchronously and notify the end.
RabbitMQ is cool also because it can work in cluster and HA.
Use GlusterFs for NAS
GlusterFs (and other products) allow you to have a Distributed File System, that splits the load and the data across the Servers, and resist node failures.
If you have to have a shared folder for the user’s uploads, for example for the profile pictures, to have the PHP and general files locally in the Servers and the Shared folder in a GlusterFs is a nice option.
Avoid NFS for PHP files and config files
As told before try to have the PHP files in a RAM disk, or in the local disk (Linux caches well and also OpCache), and try to not write code that reads files from disk for determining config setup.
I remember a Start up incubator that had a very nice Server, but the PHP files were read from a mounted NFS folder.
That meant that on every request, the Server had to go over the network to fetch the files.
Sadly for the project’s performance the PHP was reading a file called ENVIRONMENT that contained “PROD” or “DEVEL”. And this was done in every single request.
Even worst, I discovered that the switch connecting the Web Server and the NFS Server was a cheap 10 Mbit one. So all the traffic was going at 10 Mbit/s. Nice bottleneck.
Improve your network architecture
You can use 10 GbE (10 Gigabit Ethernet) to connect the Servers. The Web Servers to the Databases, Memcached Cluster, Load Balancers, Storage, etc…
You will need 10 GbE cards and 10 GbE switchs supporting bonding.
Use bonding to aggregate 10 + 10 so having 20 Gigabit.
You can also use Fibre Channel, for example 10 Gb and aggregate them, like 10 + 10 so 20 Gbit for the connection between the Servers and the Storage.
The performance improvements that your infrastructure will experiment are amazing.