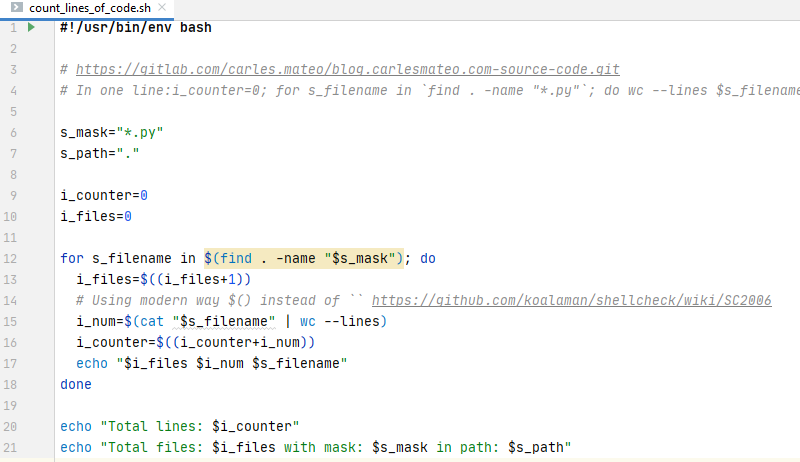
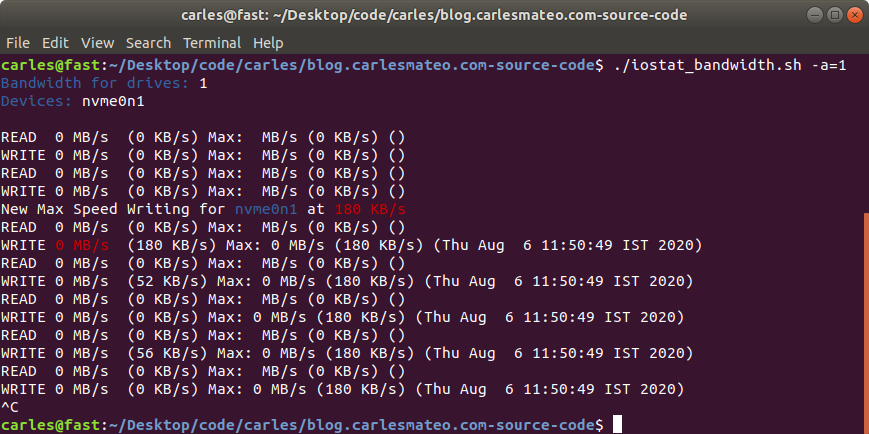
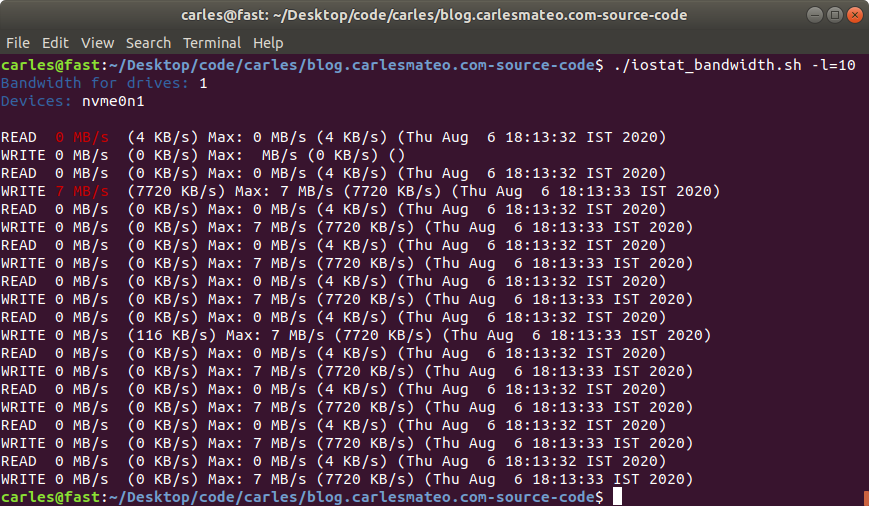
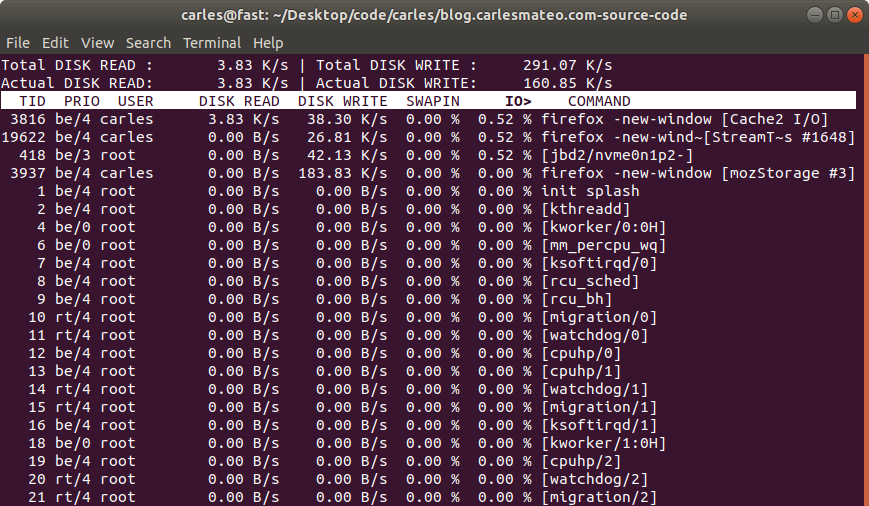
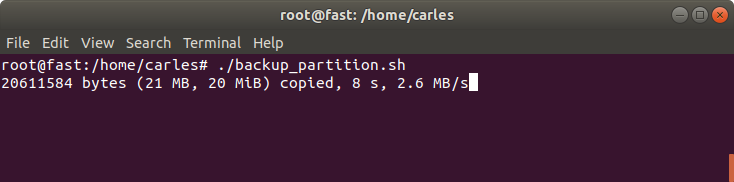
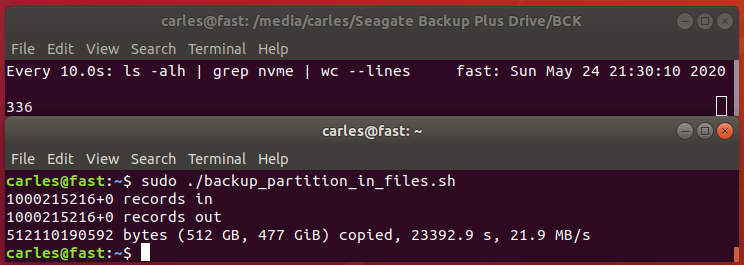
I use this script for my needs, to compress logs and core dumps older than some days, in order to Cron that and save disk space.
You can also download it from here:
https://gitlab.com/carles.mateo/blog.carlesmateo.com-source-code/-/blob/master/compress_old.sh
#!/bin/bash
# By Carles Mateo - https://blog.carlesmateo.com
# Compress older than two days files.
# I use for logs and core dumps. Normally at /var/core/
# =======================================================0
# FUNCTIONS
# =======================================================0
function quit {
# Quits with message in param1 and error code in param2
s_MESSAGE=$1
i_EXIT_CODE=$2
echo $s_MESSAGE
exit $i_EXIT_CODE
}
function add_ending_slash {
# Check if Path has ending /
s_LAST_CHAR_PATH=$(echo $s_PATH | tail -c 2)
if [ "$s_LAST_CHAR_PATH" != "/" ];
then
s_PATH="$s_PATH/"
fi
}
function get_list_files {
# Never follow symbolic links
# Show only files
# Do not enter into subdirs
# Show file modified more than X days ago
# Find will return the path already
s_LIST_FILES=$(find -P $s_PATH -maxdepth 1 -type f -mtime +$i_DAYS | tr " " "|")
}
function check_dir_exists {
s_DIRECTORY="$1"
if [ ! -d "$s_DIRECTORY" ];
then
quit "Directory $s_DIRECTORY does not exist." 1
fi
}
function compress_files {
echo "Compressing files from $s_PATH modified more than $i_DAYS ago..."
for s_FILENAME in $s_LIST_FILES
do
s_FILENAME_SANITIZED=$(echo $s_FILENAME | tr "|" " ")
s_FILEPATH="$s_PATH$s_FILENAME_SANITIZED"
echo "Compressing $s_FILENAME_SANITIZED..."
# Double quotes around $s_FILENAME_SANITIZED avoid files with spaces failing
gzip "$s_FILENAME_SANITIZED"
i_ERROR=$?
if [ $i_ERROR -ne 0 ];
then
echo "Error $i_ERROR happened"
fi
done
}
# =======================================================0
# MAIN PROGRAM
# =======================================================0
# Check Number of parameters
if [ "$#" -lt 1 ] || [ "$#" -gt 2 ];
then
quit "Illegal number of parameters. Pass a directory and optionally the number of days to exclude from mtime. Like: compress_old.sh /var/log 2" 1
fi
s_PATH=$1
if [ "$#" -eq 2 ];
then
i_DAYS=$2
else
i_DAYS=2
fi
add_ending_slash
check_dir_exists $s_PATH
get_list_files
compress_files

If you want to compress everything in the current directory, event files modified today run with:
./compress_old.sh ./ 0