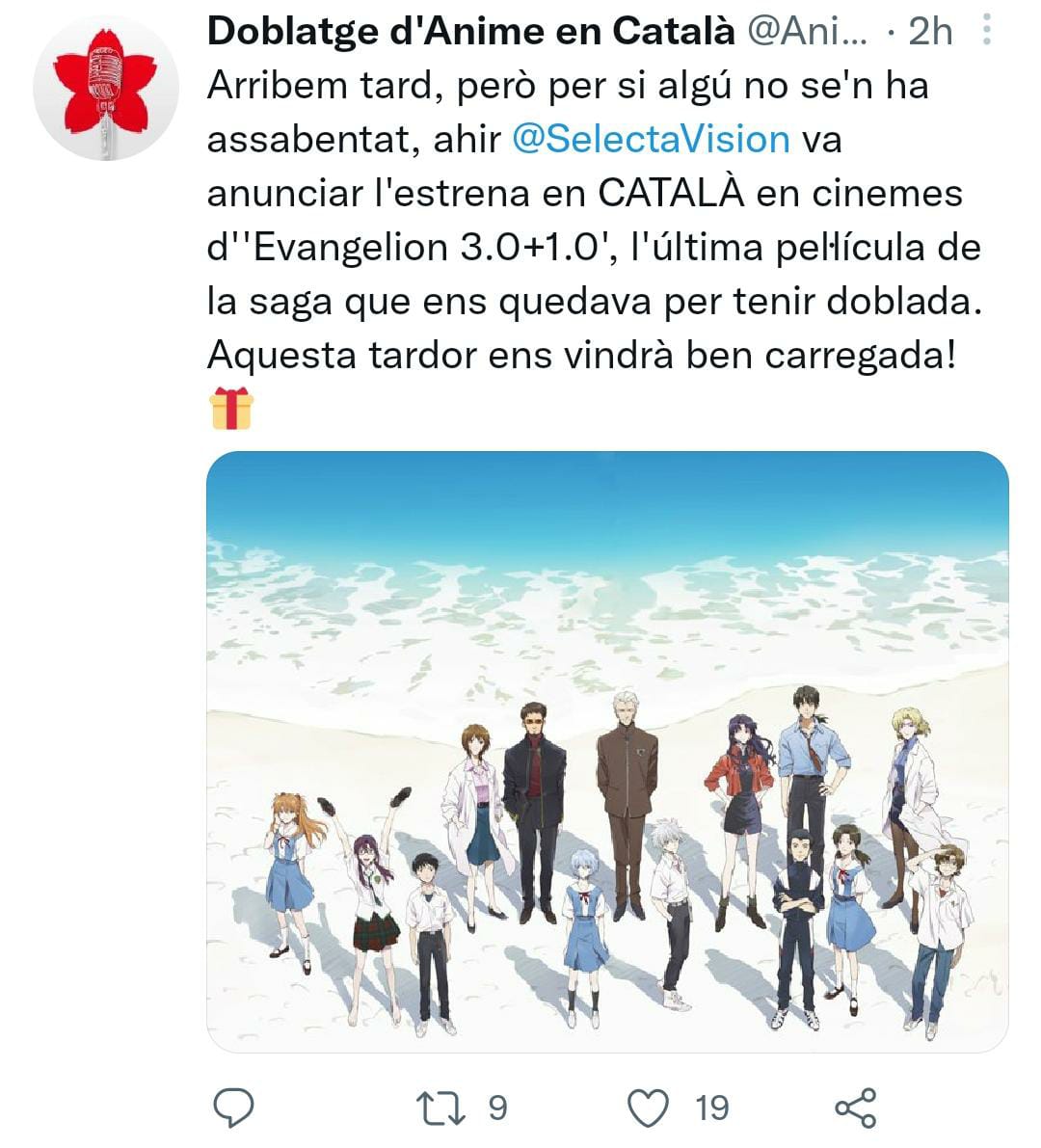
| Aquest és el guió per al proper programa El nou món digital a Ràdio Amèrica Barcelona, que s’emet els Dilluns a les 10:30 Ireland Time / 11:30 Zona horària Catalunya / 02:30 Pacific Time. Disclaimer: Treballo per a Activision Blizzard. Totes les opinions són meves i no representen cap companyia. This is the excerpt of my radio program at Radio America Barcelona that airs on Mondays 10:30 Irish Time / 11:30 Catalonia Time / 02:30 Pacific Time. Disclaimer: I work for Activision Blizzard. Opinions are my own. My opinions do not represent any company. |
Aquesta és la pàgina del proper programa de la setmana del 14 de Novembre de 2022.
This is the page of the upcoming program of 14th November’s 2022 week.
Actualitat
- Meta (Facebook) farà fora 11,000 treballadors a tot al món i aturarà inversions en algunes àrees.
- Sembla ser que experts consideraven que el creixement econòmic durant la pandèmia es mantindria i no ha estat així. Ja han començat a acomiadar.
- https://www.engadget.com/meta-mass-layoffs-facebook-111406126.html
- Twitter també farà fora 13,000 empleats a tot el món.
- També ha fet fora entre 4,500 i 5,500 contractors.
- Sembla ser que la companyia estava en pèrdues i aquests acomiadaments intenten reduïr costs.
- https://mashable.com/article/elon-musk-fires-more-twitter-workers
- Fallides en criptomoneda. FTX, un dels principals actors en la compra venda de criptomonedes ha fet fallida.
- https://www.engadget.com/binance-abandons-ftx-rescue-bid-222642965.html
Entreteniment
- Netflix ha creat un joc de trivial, interactiu, amb preguntes i respostes, que pot jugar una persona sola o dues, una contra d’altra, per torns.
- https://about.netflix.com/en/news/introducing-triviaverse-new-trivia-experience
Ecologia
- França obligarà per llei, els parkings de cotxes amb més de 80 places, a instal·lar panells solars.
- Actualment França general el 25% de la seva energia de fonts renovables, per sota dels seus veïns europeus.
- https://www.engadget.com/france-new-law-parking-lots-solar-panels-100435214.html
Trucs de telèfons
- Un truc per a seleccionar un text, o un pàrraf, d’un text, al mòbil. Es tracta de prèmer amb el dit sobre la pantalla durant dos segons, sobre la paraula que volem copiar. Llavors paraula se’ns selecciona i podem Copiar i Enganxar, o fer d’altres accions com cercar-la a google. També podrem estirar unes boletes que delimiten el text per a cercar per a un pàrraf més gran.
Per a següents programes…
Seguretat
- Desactivar sempre el Bluetooth del mòbil, de l’ordinador i del cotxe quan no el fem servir.
- No només estalviarem bateria, també ens podem estalviar algun hackeig.
- Utilitzar auriculars amb cable és molt més segur.
- Un d’aquests casos de multinacionals assetjant brutalment persones innocents
- Una història d’executius d’eBay enviats a presó per una campanya de bullying contra persones que publicaven una revista, incloent amenaces, enviament de porcs morts, etc…
Trucs
- Desactivar el Caller ID
- En Android:
Step 1: On the Home Screen, tap Phone.
Step 2: Press the left menu button and tap Settings.
Step 3: Under Call settings, tap Supplementary services.
Step 4: Tap Caller ID to turn it on or off.
Entreteniment
Videojocs
Nerd Culture
Internet / Societat
Actualitat
Trucs
- Si s’us omple el mòbil, podeu posar una tarja micro SD, que val uns 20€ per a una de 64GB/128GB.
- També podeu passar les fotos a l’ordinador, o a un disc dur extern.
- Fer una captura de pantalla:
Windows
- Impr Pant, Alt Impr i enganxem a una aplicació com Paint o GIMP
Linux
- Impr Pant, Alt Impr Pant, Shift Impr
Android:
- Cerca a Google per al teu model.
- Prem tecla de baixar el volum i d’encendre el mòbil a la mateixa hora. I mantent-los pulsats durant mig segon.
iPhone:
- 13 i altres amb face id: Prem: el botó del costat i el de pujar el volum a l’hora.
- Models amb touch id: Prem el botó de home, el rodonet, i el del costat (power).
- Els que tenen el botó a dalt, han de prèmer el botó de dalt i home.
- iPhone 12
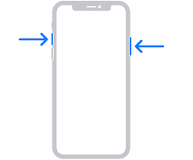
https://support.apple.com/en-ie/HT200289
Dones en ciència i tecnologia
- Ada Lovelace
Trucs de Zoom
- Un Zoom és un sistema de videoconferència que s’utilitza molt en teletreball a les empreses.
- Es pot utilitzar gratuïtament, amb un límit de temps per cada trucada. Ara fa poc s’ha limitat el temps de persones individuals a 45 minuts, fins ara era il·limitat i s’emprava molt per professors, terapeutes, particulars…
- Jo uso la versió professional per a les meves classes i pago 18€ al mes i puc donar classes a 100 persones sense límit de temps.
- Es pot compartir la pantalla. I es pot demanar control remot. L’altre t’ha d’autoritzar.
- S’empra molt per a presentacions.
- També per a jugar a jocs amb amics.
- Per a arreglar l’ordinador a la tieta.
- També es pot dibuixar a la pantalla de l’atri, posar fletxes i textes. La opció es diu Annotate.
- Per a evitar problemes amb l’aúdio es recomana connectar un headset (auriculars amb micròfon). A TV3 s’ha pogut veure molta gent amb problemes d’aúdio acoplant-se per no emprar auriculars i micro.
- També es pot difuminar la imatge de fons o posar una imatge o un vídeo de fons
- Pots posar mute (Desactivar Aúdio) i parar la imatge (Detenir Vídeo)
- Es pot enregistrar vídeo. Molt útil per a classes, per a que els estudiants puguin tornar a repassar la lliçó després.
Trucs de Mòbils
Copiar i Enganxar:
- És possible seleccionar text, copiar i enganxar apretant amb el dit sobre el text durant dos o tres segons. Un menu se’ns obrirà i també dues boletes ens indicaran el principi i el final del text seleccionat.
Trucs per a trobar feina
- Estudiar una carrera
- Es pot fer de tardes, remotament, per Internet
- S’aprèn molt
- Es fan bons contactes
- Alguns govers (Irlanda, Escòcia…) te la financen/subsidien.
- Estudiar un curs de programació
- La Generalitat de Catalunya fa cursos gratuïts per a aturats
Temes proposats per a següents programes
- La importància de LinkedIn en la estratègia per a trobar feina. Trucs i consells.
- Aprèn a programar i canvia la teva trajectoria laboral. Trucs, consells, històries d’èxit.
- Trucs per a utilitzar programes més eficientment:
- Cercar textes dins pàgines webs i documents
- Copiar, enganxar
- Utilitzar google docs per a treballar en un document conjuntament
- Compartir arxius i vídeos amb Google Drive
- Ergonomia, com usar un monitor extern, teclat i ratolí, pot fer desaparèixer el mal de coll. Emprar llum addient i una bona cadira.
- La importància de les còpies de seguretat. Tenir les còpies distribuïdes geogràficament per estratègies de disaster and recovery.
- Com alliberar espai al mòbil. Passar fotos a una tarja SD o a l’ordinador. Arxius que guarda Whatsapp i mai allibera.
- Com emprar negreta, cursiva, i marcar un bloc de codi a WhatsApp.
- L’experiència dels estudiants a la universitat i masters, costos, països que subvencionen.
- Irlanda
- Escòcia
- Resolució de preguntes. Envia la teva pregunta a l’equip del programa i la resoldrem en un proper programa.
Programes anteriors
Programa anterior: RAB El nou món digital del Dilluns 31 d’Octubre de 2022 [CA]
Tots els programes: RAB