Me, with 4 more Senior BackEnd Engineers wrote the new e-Commerce for a multinational.
The old legacy Software evolved into a different code for every country, making it impossible to be maintained.
The new Software we created used inheritance to use the same base code for each country and overloaded only the specific different behavior of every country, like for the payment methods, for example Brazil supporting “parcelados” or Germany with specific payment players.
We rewrote the old procedural PHP BackEnd into modern PHP, with OOP and our own Framework but we had to keep the transactional code in existing MySQL Procedures, so the logic was split. There was a Front End Team consuming our JSONs. Basically all the Front End code was cached in Akamai and pages were rendered accordingly to the JSONs served from out BackEnd.
It was a huge success.
This e-Commerce site had Campaigns that started at a certain time, so the amount of traffic that would come at the same time would be challenging.
The project was working very well, and after some time the original Team was split into different projects in the company and a Team for maintenance and evolutives was hired.
At certain point they started to encounter duplicate transactions, and nobody was able to solve the mystery.
I’m specialized into fixing impossible problems. They used to send me to Impossible Missions, and I am famous for solving impossible problems easily.
So I started the task with a SRE approach.
The System had many components and layers. The problem could be in many places.
I had in my arsenal of tools, Software like mysqldebugger with which I found an unnoticed bug in decimals calculation in the past surprising everybody.
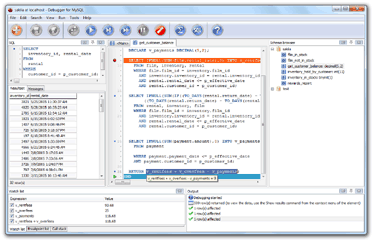
Previous Engineers involved believed the problem was in the Database side. They were having difficulties to identify the issue by the random nature of the repetitions.
Some times the order lines were duplicated, and other times were the payments, which means charging twice to the customer.
Redis Cluster could also play a part on this, as storing the session information and the basket.
But I had to follow the logic sequence of steps.
If transactions from customer were duplicated that mean that in first term those requests have arrived to the System. So that was a good point of start.
With a list of duplicated operations, I checked the Webservers logs.
That was a bit tricky as the Webserver was recording the Ip of the Load Balancer, not the ip of the customer. But we were tracking the sessionid so with that I could track and user request history. A good thing was also that we were using cookies to stick the user to the same Webserver node. That has pros and cons, but in this case I didn’t have to worry about the logs combined of all the Webservers, I could just identify a transaction in one node, and stick into that node’s log.
I was working with SSH and Bash, no log aggregators existing today were available at that time.
So when I started to catch web logs and grep a bit an smile was drawn into my face. :)
There were no transactions repeated by a bad behavior on MySQL Masters, or by BackEnd problems. Actually the HTTP requests were performed twice.
And the explanation to that was much more simple.
Many Windows and Mac User are used to double click in the Desktop to open programs, so when they started to use Internet, they did the same. They double clicked on the Submit button on the forms. Causing two JavaScript requests in parallel.
When I explained it they were really surprised, but then they started to worry about how they could fix that.
Well, there are many ways, like using an UUID in each request and do not accepting two concurrents, but I came with something that we could deploy super fast.
I explained how to change the JavaScript code so the buttons will have no default submit action, and they will trigger a JavaScript method instead, that will set a boolean to True, and also would disable the button so it can not be clicked anymore. Only if the variable was False the submit would be performed. It was almost impossible to get a double click as the JavaScript was so fast disabling the button, that the second click will not trigger anything. But even if that could be possible, only one request would be made, as the variable was set to True on the first click event.
That case was very funny for me, because it was not necessary to go crazy inspecting the different layers of the system. The problem was detected simply with HTTP logs. :)
People often forget to follow the logic steps while many problems are much more simple.
As a curious note, I still see people double clicking on links and buttons on the Web, and some Software not handling it. :)