Here is an easy trick that you can use for adding swap temporarily to a Server, VMs or Workstations, if you are in an emergency.
In this case I had a cluster composed from two instances running out of memory.
I got an alert for one of the Servers, reporting that only had 7% of free memory.
Immediately I checked it, but checked also any other forming part of the cluster.
Another one appeared, had just only a bit more memory than the other, but was considered in Critical condition too.
The owner of the Service was contacted and asked if we can hold it until US Business hours. Those Servers were going to be replaced next day in US Business hours, and when possible it would be nice not to wake up the Team. It was day in Europe, but night in US.
I checked the status of the Server with those commands:
# df -h
There are 13GB of free space in /. More than enough to be safe as this service doesn’t use much.
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 139M 298M 738M 320M
Swap: 0B 0B 0B
I checked the memory, ok, there are only 139MB free in this node, but 738MB are buff/cache. Buff/Cache is memory used by Linux to optimize I/O as long as it is not needed by application. These 738 MB in buff/cache (or most of it) will be used if needed by the System. The field available corresponds to the memory that is available for starting new applications (not counting the swap if there was any), and basically is the free memory plus a fragment of the buff/cache. I’m sure we could use more than 320MB and there is a lot if buff/cache, but to play safe we play by the book.
With that in mind it seemed that it would hold perfectly to Business hours.
I checked top. It is interesting to mention the meaning of the Column RES, which is resident memory, in other words, the real amount of memory that the process is using.
I had a Java process using 4.57GB of RAM, but a look at how much Heap Memory was reserved and actually being used showed a Heap of 4GB (Memory reserved) and 1.5GB actually being used for real, from the Heap, only.
It was unlikely that elastic search would use all those 4GB, and seemed really unlikely that the instance will suffer from memory starvation with 2.5GB of 4GB of the Heap free, ~1GB of RAM in buffers/cache plus free, so looked good.
To be 100% sure I created a temporary swap space in a file on the SSD.
(# means that I’m executing this as root, if you type literally with # in front, this will be a comment)
# fallocate -l 1G /swapfile-temp
# dd if=/dev/zero of=/swapfile-temp bs=1024 count=1048576 status=progress
1034236928 bytes (1.0 GB) copied, 4.020716 s, 257 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 4.26152 s, 252 MB/s
If you ask me why I had to dd, I will tell you that I needed to. I checked with command blkid and filesystem was xfs. I believe that was the reason.
The speed writing to the file is fair enough for a swap.
# chmod 600 /swapfile-temp
# mkswap /swapfile-temp
Setting up swapspace version 1, size = 1048572 KiB
no label, UUID=5fb12c0c-8079-41dc-aa20-21477808619a
# swapon /swapfile-temp
I check that memory is good:
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 117M 298M 770M 329M
Swap: 1.0G 0B 1.0G
And finally I check that the Kernel parameter swappiness is not too aggressive:
# sysctl vm.swappiness
vm.swappiness = 30
Cool. 30 is a fair enough value.
2022-01-05 Update for my students that need to add additional 16GB of swap to their SSD drive:
This article is more an exercise, like a game, so you get to know certain things about Linux, and follow my mental process to uncover this. Is nothing mysterious for the Senior Engineers but Junior Sys Admins may enjoy this reading. :)
Ok, so the first thing is I wrote an script in order to completely backup my NVMe hard drive to a gziped file and then I will use this, as a motivation to go deep into investigations to understand.
So basically, we are going to restart the computer, boot with Linux Live USB Key, mount the Seagate Hard Drive, and run the script.
We are booting with a Live Linux Cd in order to have our partition unmounted and unmodified while we do the backup. This is in order to avoid corruption or data loss as a live Filesystem is getting modifications as we read it.
The problem with this first script is that it will generate a big gzip file.
By big I mean much more bigger than 2GB. Not all physical supports support files bigger than 2GB or 4GB, but even if they do, it’s a pain to transfer this over the Network, or in USB files, so we are going to do a slight modification.
Then one may ask himself, wait, if pipes use STDOUT and STDIN and dd is displaying into the screen, then will our gz file get corrupted?.
I like when people question things, and investigate, so let’s answer this question.
If it was a young member of my Team I would ask:
Ok, try,it. Check the output file to see if is corrupted.
So they can do zcat or zless to inspect the file, see if it has errors, and to make sure:
gzip -v -t nvme.img.gz
nvme.img.gz: OK
Ok, so what happened?, because we were seeing output in the screen.
Assuming the young Engineer does not know the answer I would had told:
Ok, so you know that if dd would print to STDOUT, then you won’t see it, cause it would be sent to the pipe, so there is something more you’re missing. Let’s check the source code of dd to see what status=progress does
And then look for “progress”.
Soon you’ll find things like everywhere:
if (progress_time)
fputc ('\r', stderr);
Ok, pay attention to where is the data written: stderr. So basically the answer is: dd status=progress does not corrupt STDOUT and prints into the screen because it uses STDERR.
Other funny ways to get the progress would be to use:
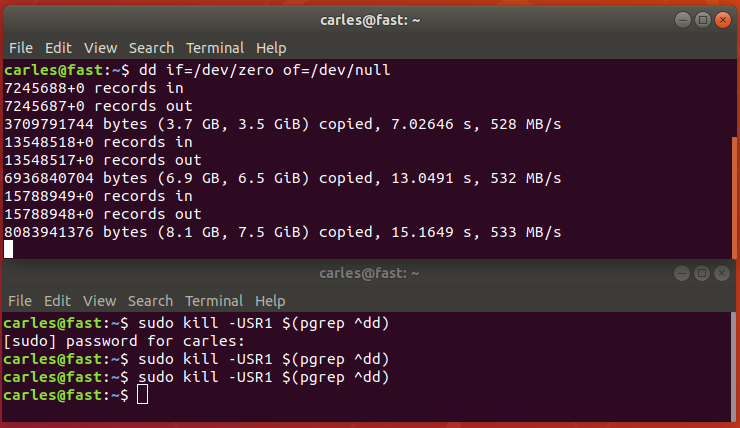
So you would see in real time what was the advance and finally 512GB where compressed to around 336GB in 336 files of 1 GB each (except the last one)
Another funny way would had been sending USR1 signal to the dd process:
Hope you enjoyed this little exercise about the importance of going deep, to the end, to understand what’s going on on the system. :)
Instead of gzip you can use bzip2 or pixz. pixz is very handy if you want to just compress a file, as it uses multiple processors in parallel for the tasks.
xz or lrzip are other compressors. lrzip aims to compress very large files, specially source code.
I came with this solution when one of my 4U60 Servers had two slots broken. You’ll not use this in Production, as SLOG loses its function, but I managed to use one $40K USD broken Server and to demonstrate that the Speed of the SLOG device (ZFS Intented Log or ZIL device) sets the constraints for the writing speed.
The ZFS DRAID config I was using required 60 drives, basically 58 14TB Spinning drives and 2 SSD for the SLOG ZIL. As I only had 58 slots I came with this idea.
This trick can be very useful if you have a box full of Spinning drives, and when sharing by iSCSI zvols you get disconnected in the iSCSI Initiator side. This is typical when ZFS has only Spinning drives and it has no SLOG drives (dedicated fast devices for the ZIL, ZFS INTENDED LOG)
Create a single Ramdrive of 10GB of RAM:
modprobe brd rd_nr=1 rd_size=10485760 max_part=0
Confirm ram0 device exists now:
ls /dev/ram*
Confirm that the pool is imported:
zpool list
Add to the pool:
zpool add carles-N58-C3-D16-P2-S4 log ram0
In the case that you want to have two ram devices as SLOG devices, in mirror.
It is interesting to know that you can work with partitions instead of drives. So for this test we could have partitioned ram0 with 2 partitions and make it work in mirror. You’ll see how much faster the iSCSI communication goes over the network. The writing speed of the ZIL SLOG device is the constrain for ingesting Data from the Network to the Server.
Creating a partition bigger than 2TiB
Master Boot Record (MBR) based partitioning is limited to 2TiB however GUID Partition Table (GPT) has a limit of 8 ZiB.
That’s something very simply, but make you lose time if you’re partitioning big iSCSI Shares, or ZFS Zvols, so here is the trick:
[root@CTRLA-18 ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.6 (Maipo)
[root@CTRLA-18 ~]# parted /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
GNU Parted 3.1
Using /dev/zd0
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
Warning: The existing disk label on /dev/zd0 will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? y
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
(parted) mkpart primary 0GB 58.9TB
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 58.9TB 58.9TB primary
(parted) quit
Information: You may need to update /etc/fstab.
[root@CTRLA-18 ~]# mkfs
mkfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
[root@CTRLA-18 ~]# mkfs.ext4 /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
mke2fs 1.42.9 (28-Dec-2013)
....
[root@CTRLA-18 ~]# mount /dev/zvol/N58-C19-D2-P1-S1/vol54854gb /Data
[root@CTRLA-18 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 50G 2.5G 48G 5% /
devtmpfs 126G 0 126G 0% /dev
tmpfs 126G 0 126G 0% /dev/shm
tmpfs 126G 1.1G 125G 1% /run
tmpfs 126G 0 126G 0% /sys/fs/cgroup
/dev/sdp1 1014M 151M 864M 15% /boot
/dev/mapper/rhel-home 65G 33M 65G 1% /home
logs 49G 349M 48G 1% /logs
mysql 9.7G 128K 9.7G 1% /mysql
tmpfs 26G 0 26G 0% /run/user/0
/dev/zd0 54T 20K 51T 1% /Data
ZFS is unable to use a disk
Some times, after creating many pools ZFS may be unable to create a new pool using a drive that is perfectly fine. In this situation, the ideal is wipe the first areas of it, or all of it if you want. If it’s an SSD that is very fast:
dd if=/dev/zero of=/dev/sdc bs=1M status=progress
The status=progress will show a nice progress bar.
Filling a half Petabyte pool as fast as possible
To fill a 60 drives pool composed by 10TB or 14TB spinning drives, so more than half PB, in order to test with real data, you can use this trick:
First, write to the Dataset directly, that’s way much more faster than using zvols.
Secondly, disable the ZIL, set sync=disabled.
Third, use a file in memory to avoid the paytime of reading the file from disk.
Fourth, increase the recordsize to 1M for faster filling (in my experience).
You can use this script of mine that does everything for you, normally you would like to run it inside an screen session, and create a Dataset called Data. The script will mount it in /Data (zfs set mountpoint=/data YOURPOOL/Data):
#!/usr/bin/env bash
# Created by Carles Mateo
FILE_ORIGINAL="/run/urandom.1GB"
FILE_PATTERN="/Data/urandom.1GB-clone."
# POOL="N56-C5-D8-P3-S1"
POOL="N58-C3-D16-P3-S1"
# The starting number, if you interrupt the filling process, you can update it just by updating this number to match the last partially written file
i_COPYING_INITIAL_NUMBER=1
# For 75% of 10TB (3x(16+3)+1 has 421TiB, so 75% of 421TiB or 431,104GiB is 323,328) use 323328
# i_COPYING_FINAL_NUMBER=323328
# For 75% of 10TB, 5x(8+3)+1 ZFS sees 352TiB, so 75% use 270336
# For 75% of 14TB, 3x(16+3)+1, use 453120
i_COPYING_FINAL_NUMBER=453120
# Creating an array that will hold the speed of the latest 1 minute
a_i_LATEST_SPEEDS=(0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0)
i_POINTER_SPEEDS=0
i_COUNTER_SPEEDS=-1
i_ITEMS_KEPT_SPEEDS=60
i_AVG_SPEED=0
i_FILES_TO_BE_COPIED=$((i_COPYING_FINAL_NUMBER-i_COPYING_INITIAL_NUMBER))
get_average_speed () {
# Calculates the Average Speed
i_AVG_SPEED=0
for i_index in {0..59..1}
do
i_SPEED=$((a_i_LATEST_SPEEDS[i_index]))
i_AVG_SPEED=$((i_AVG_SPEED + i_SPEED))
done
i_AVG_SPEED=$((i_AVG_SPEED/((i_COUNTER_SPEEDS)+1)))
}
echo "Bash version ${BASH_VERSION}..."
echo "Disabling sync in the pool $POOL for faster speed"
zfs set sync=disabled $POOL
echo "Maximizing performance with recordsize"
zfs set recordsize=1M ${POOL}
zfs set recordsize=1M ${POOL}/Data
echo "Mounting the Dataset Data"
zfs set mountpoint=/Data ${POOL}/Data
zfs mount ${POOL}/Data
echo "Checking if file ${FILE_ORIGINAL} exists..."
if [[ -f ${FILE_ORIGINAL} ]]; then
ls -al ${FILE_ORIGINAL}
sha1sum ${FILE_ORIGINAL}
else
echo "Generating file..."
dd if=/dev/urandom of=${FILE_ORIGINAL} bs=1M count=1024 status=progress
fi
echo "Starting filling process..."
echo "We are going to copy ${i_FILES_TO_BE_COPIED} , starting from: ${i_COPYING_INITIAL_NUMBER} to: ${i_COPYING_FINAL_NUMBER}"
for ((i_NUMBER=${i_COPYING_INITIAL_NUMBER}; i_NUMBER<=${i_COPYING_FINAL_NUMBER}; i_NUMBER++));
do
s_datetime_ini=$(($(date +%s%N)/1000000))
DATE_NOW=`date '+%Y-%m-%d_%H-%M-%S'`
echo "${DATE_NOW} Copying ${FILE_ORIGINAL} to ${FILE_PATTERN}${i_NUMBER}"
cp ${FILE_ORIGINAL} ${FILE_PATTERN}${i_NUMBER}
s_datetime_end=$(($(date +%s%N)/1000000))
MILLISECONDS=$(expr "$s_datetime_end" - "$s_datetime_ini")
if [[ ${MILLISECONDS} -lt 1 ]]; then
BANDWIDTH_MBS="Unknown (too fast)"
# That sould not happen, but if did, we don't account crazy speeds
else
BANDWIDTH_MBS=$((1000*1024/MILLISECONDS))
# Make sure the Array space has been allocated
if [[ ${i_POINTER_SPEEDS} -gt ${i_COUNTER_SPEEDS} ]]; then
# Add item to the Array the first times only
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
i_COUNTER_SPEEDS=$((i_COUNTER_SPEEDS+1))
else
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
fi
i_POINTER_SPEEDS=$((i_POINTER_SPEEDS+1))
if [[ ${i_POINTER_SPEEDS} -ge ${i_ITEMS_KEPT_SPEEDS} ]]; then
i_POINTER_SPEEDS=0
fi
get_average_speed
fi
i_FILES_TO_BE_COPIED=$((i_FILES_TO_BE_COPIED-1))
i_REMAINING_TIME=$((1024*i_FILES_TO_BE_COPIED/i_AVG_SPEED))
i_REMAINING_HOURS=$((i_REMAINING_TIME/3600))
echo "File cloned in ${MILLISECONDS} milliseconds at ${BANDWIDTH_MBS} MB/s"
echo "Avg. Speed: ${i_AVG_SPEED} MB/s Remaining Files: ${i_FILES_TO_BE_COPIED} Remaining seconds: ${i_REMAINING_TIME} s. (${i_REMAINING_HOURS} h.)"
done
echo "Enabling sync=always"
zfs set sync=always ${POOL}
echo "Setting back recordsize to 128K"
zfs set recordsize=128K ${POOL}
zfs set recordsize=128K ${POOL}/Data
echo "Unmounting /Data"
zfs set mountpoint=none ${POOL}/Data
Creating a Sparse file that you can partition or create a loopback on it
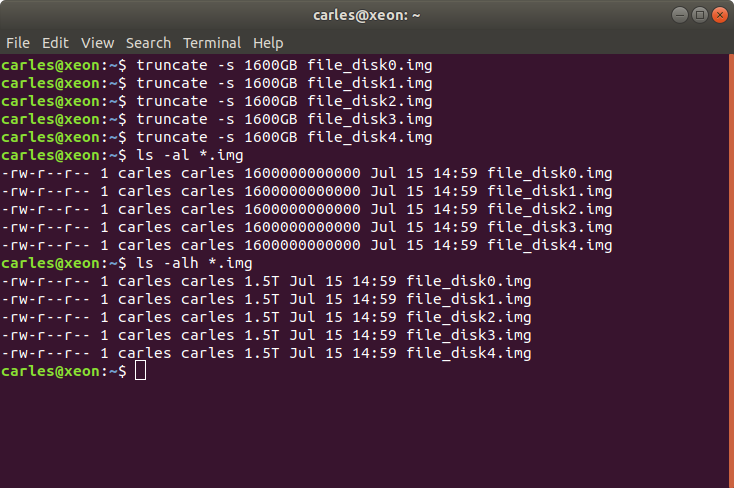
I know, your laptop has 512GB of M.2 SSD or NVMe, so that’s it.
Well, you can create a sparse file much more bigger than your capacity, and use 0 bytes of it at all.
For example:
truncate -s 1600GB file_disk0.img
If the files are stored in / then you can add a loop device:
sudo losetup -f /file_disk0.img
I do with the 5 I created.
Then you can check that they exist with:
lsblk
or
cat /proc/partitions
The loop devices will appear under /dev/ now.
For some tests I did this in a Virtual Box Virtual Machine:
This is the history it happen to me some time ago, and so the commands I used to troubleshot. The purpose is to share knowledge in a interactive way. There are some hidden gems that you’ll acquire if you have the patience to go over all the document and read it all…
I had qualified Intel Xeon single processor platform to run my DRAID (ZFS Declustered RAID) project for my employer.
The platforms I qualified were:
1) single processor for Cold Storage (SAS Spinning drives): 4U60, newest models 4602
2) for multiprocessor: the 4U90 (90 Spinning drives) and Flash: All-Flash-Arrays.
The amounts of RAM I was using for my tests range for 64GB to 384GB.
Somebody in the company, at executive level, assembled an experimental config that was totally new for us and wanted to try by their own. It was the 4602 with multiprocessor and 32GB of RAM.
When they were unable to make it work at the expected speed, they required me to troubleshot and to make it work.
The 4602 single processor had two IOC (Input Output Controller, LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ), while the 4602 double processor had four IOC, so given that each of those IOC can perform at peaks of 6GB/s, with a maximum total of 24 GB/s, the performance when reading/writing from all the drives should be better.
But this Server was returning double times for Rebuilding, respect the single processor version, which didn’t make any sense.
I had to check everything. There was the commands I ran:
Check the upgrade of the CPU:
htop
lscpu
Changing the Zoning.
Those Servers use SAS drives dual ported, which means that two different computers can be connected to the same drive and operate at the same time. Is up to you to make sure you don’t introduce corruption. Those systems are used mainly for HA (High Availability).
Those Systems allow to be configured in different zoning modes. That’s the way on how each of the two servers (Controllers) see the disk. In one zoning each Controller sees only 30 drives, in another each IOC sees all the drives (for redundancy but performance constrained to 1 IOC Speed).
The config I set is each IOC will see 15 drives, so each one of the 4 IOC will have 6GB/s for 15 drives. Given that these spinning drives perform in the outtermost part of the cylinder at 265MB/s, that means that at maximum speed one IOC will be using 3.97 GB/s, will say 4GB/s. Plenty of bandwidth.
Note: Spinning drives have different performance depending on how close you’re to the cylinder. In the innermost part it goes under 145 MB/s, and if you read all of those drive sequentially with dd it will return an average speed of 145 MB/s.
With this command you can sive live how it performs and the average read speed in real time. Use skip to jump to that position (relative to bs) in the drive, so you can test directly the speed at the innermost close to the cylinder part of t.
dd if=/dev/sda of=/dev/null bs=1M status=progress
I saw that the zoning was not right one, so I set it correctly:
The sleeps after rebooting the expanders are recommended. Rebooting the Operating System too, to avoid problems with some Software as the expanders changed live.
If you have ZFS pools or workloads stop them and export the pool before messing with the expanders.
In order to check to which drives is connected each IOC:
I do this for all the drives at the same time and with iostat:
iostat -y 1 1
I check the status of the memory with:
slabtop
free
htop
I checked the memory and htop during a Rebuild. Memory was more than enough. However CPU usage was higher than expected.
The red bars in the image correspond to kernel processes, in this case is the DRAID Rebuild. I see that the load is higher than the usual with a single processor.
I capture all the parameters from ZFS with:
zfs get all
All this information is logged into my forensics document, so later can be checked by my Team or I can share with other Architects or other members of the company. I started this methodology after I knew how Google do their SRE forensics / postmortem documents. Also for myself is useful for the future to have a log of the commands I executed and a verbose output of the results.
I install the smp_utils
yum install smp_utils
Check things:
ls -al /dev/bsg/
total 0drwxr-xr-x. 2 root root 3020 May 22 10:16 .
drwxr-xr-x. 20 root root 8680 May 22 10:16 ..
crw-------. 1 root root 248, 76 May 22 10:00 1:0:0:0
crw-------. 1 root root 248, 126 May 22 10:00 10:0:0:0
crw-------. 1 root root 248, 127 May 22 10:00 10:0:1:0
crw-------. 1 root root 248, 136 May 22 10:00 10:0:10:0
crw-------. 1 root root 248, 137 May 22 10:00 10:0:11:0
crw-------. 1 root root 248, 138 May 22 10:00 10:0:12:0
crw-------. 1 root root 248, 139 May 22 10:00 10:0:13:0
[...]
There are some errors, and I check with the Hardware Team, which pass a battery of tests on the machine and say that the machine passes. They tell me that if the errors counted were in order of millions then it would be a problem, but having few of them is usual.
My colleagues previously reported that the memory was performing well, and the CPU too. They told me that the speed was exactly double respect a platform with one single CPU of the same kind.
Even if they told me that, I ran cmips tests to make sure.
git clone https://github.com/cmips/cmips_bin
It scored 16,000. The performance was Ok in general terms but the problem is that I didn’t have a baseline for that processor in single processor, so I cannot make sure that the memory bandwidth was Ok. The performance was less that an Amazon c3.8xlarge. The system I was testing is a two processor system, but each CPU is cheap, around USD $400.
Still my gut feeling was telling me that this double processor server should score more.
lscpu
[root@DRAID-1135-14TB-2CPU ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2299.951
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4199.73
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts spec_ctrl intel_stibp
I check the memory configuration with:
dmidecode -t memory
I examined the results, I see that the processor can only operate the DDR4 ECC 2400 Memory at 2133 and… I see something!. This Controller before was a single processor with 2 Memory Sticks of 16GB each, dual rank.
I see that now I have the same number of sticks in that machine, but I have two CPU!. So 2 Memory sticks in total, for 2 CPU.
That’s no good. The memory must be in pairs and in the right slots to get the maximum performance.
1 memory module for 1 CPU doesn’t allow to have Dual Channel and probably is affecting the performance. Many Servers will not even boot if you add an odd number of memory sticks per CPU.
And many Servers can operate at full speed only if all the banks are filled.
I request to the Engineers in Silicon Valley to add 4 modules in the right slots. They did, and I repeated the tests and the performance was doubled then.
After some days I had some time with the machine, I repeated the test and I got a CMIPS Score of around 20,000.
Multiprocessor world is far more complicated than single processor. Some times things can work not as expected, and not be evident, for example cache pipeline can act diferent for a program working in multiprocessor and single processor. Or the QPI could be saturated.
After this I shared my forensics document with as many Engineers as I could, so they could learn how I did to troubleshot the problem, and what was the origin of it, and I asked them to do the same so we can track their steps and progress if something needs to be troubleshoot.
After proper intensive testing the Server was qualified. Lesson here is that changes cannot be commited quickly, need their time.