ZFS has a performance problem with the zvol volumes.
Even using a ZIL you will experience low speed when writing to a zvol through the Network.
Even locally, if you format a zvol, for example with ext4, and mount locally, you will see that the speed is several times slower than the native ZFS filesystem.
zvol volumes are nice as they support snapshots and clone (from the snapshot), however too slow.
Using a pool with Spinning Drives and two SSD SLOG devices in mirror, with a 40Gbps Mellanox NIC accessing a zvol via iSCSI, with ext4, from the iSCSI Initiator, you can be copying Data at 70 MB/s, so not even saturating the 1Gbps.
The trick to speed up this consist into instead of using zvols, creating a file in the ZFS File System, and directly share it through iSCSI.
This will give 4 times more speed, so instead of 70MB/s you would get 280MB/s.
Many times it could be very convenient to have a compressed filesystem, so a system that compresses data in Real Time.
This not only reduces the space used, but increases the IO performance. Or better explained, if you have to write to disk 1GB log file, and it takes 5 seconds, you have a 200MB/s performance. But if you have to write 1GB file, and it takes 0.5 seconds you have 2000MB/s or 2GB/s. However the trick in here is that you really only wrote 100MB, cause the Data was compressed before being written to the disk.
This also works for reading. 100MB are Read, from Disk, and then uncompressed in the memory (using chunks, not everything is loaded at once), assuming same speed for Reading and Writing (that’s usual for sequential access on SAS drives) we have been reading from disk for 0.5 seconds instead of 5. Let’s imagine we have 0.2 seconds of CPU time, used for decompressing. That’s it: 0.7 seconds versus 5 seconds.
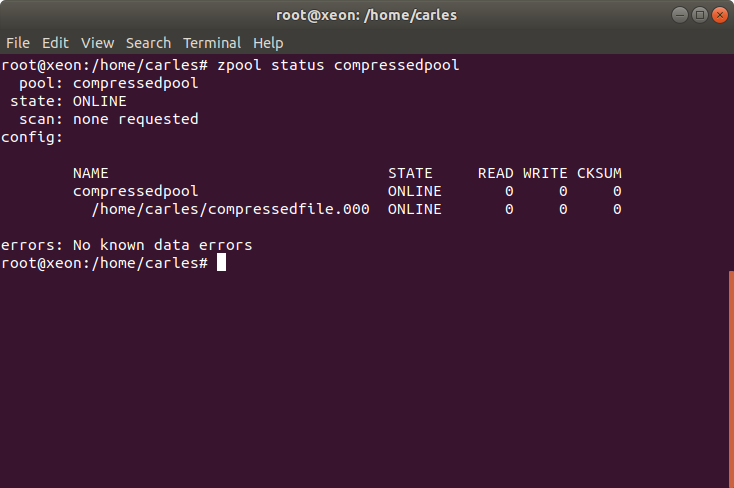
So assuming you have installed ZFS in your Desktop computer those instructions will allow you to create a ZFS filesystem, compressed, and mount it.
ZFS can create pools using disks, partitions or other block devices, like regular files or loop devices.
# Create the File that will hold the Filesystem, 1GB
root@xeon:/home/carles# dd if=/dev/zero of=/home/carles/compressedfile.000 bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.621923 s, 1.7 GB/s
Even if the pool only had 1GB we managed to copy 1.33 GB file.
Then we check and only 142MB are being used for real, thanks to the compression.
root@xeon:/home/carles# zfs list
NAME USED AVAIL REFER MOUNTPOINT
compressedpool 142M 738M 141M /compressedpool
root@xeon:/home/carles# df /compressedpool
Filesystem 1K-blocks Used Available Use% Mounted on
compressedpool 899584 144000 755584 17% /compressedpool
By default ZFS will only import the pools that are based on drives, so in order to import your pool based on files after you reboot or did zfs export compressedpool, you must specify the directory:
zpool import -d /home/carles compressedpool
You can also create a pool using several files from different hard drives. That way you can create mirror, RAIDZ1, RAIDZ2 or RAIDZ3 and not losing any data in that pool based on drives in case you loss a physical drive.
If you use one file in several hard drive, you are aggregating the bandwidth.
You can also do this in your instances or VMs. Create one file of 1GB and creating the pool for compressed logs or compressed core dumps. If later you need more space you can add another file to he pool. You don’t need to use any redundancy, just creating a pool with mountpoint /var/log or /var/core and grow as you need.
Logs and core dumps can be greatly compressed, for example a core dump of 54MB will be around 645KB if you compress it using a tool like bzip2. Using the compression from ZFS, you can choose different algorithms of compression, so expect a massive reduction of space and huge space savings for logs and core dumps.
Also in the Hackaton I presented my mini utility run_with_timeout.sh to execute a command (zdb, zpool, zfs, or any shell command like ls, “sleep 5; ping google.com”…) with a timeout, and returning a Header with the Error Level and the Error Level itself.
I illustrate this troubleshooting as it will be useful for some of you.
I requested to one of the members of my Team to compile and to install ZFS 7.9 to some of the Servers loaded with drives, that were running ZFS 7.4 older version.
Those systems were running RHEL7.4.
The compilation and install was fine, however the module was not able to load.
My Team member reported that: when trying to run “modprobe zfs“. It was giving the error:
modprobe: ERROR: could not insert 'zfs': Invalid argument
Also when trying to use a zpool command it gives the error:
Failed to initialize the libzfs library
That was only failing in one of the Servers, but not in the others.
My Engineer ran dmesg and found:
zfs: `' invalid for parameter `metaslab_debug_unload
He though it was a compilation error, but I knew that metaslab_debug_unload is an option parameter that you can set in /etc/zfs.conf
So I ran:
modprobe -v zfs
And that confirmed my suspicious, so I edited /etc/zfs.conf and commented the parameter and tried again. And it failed.
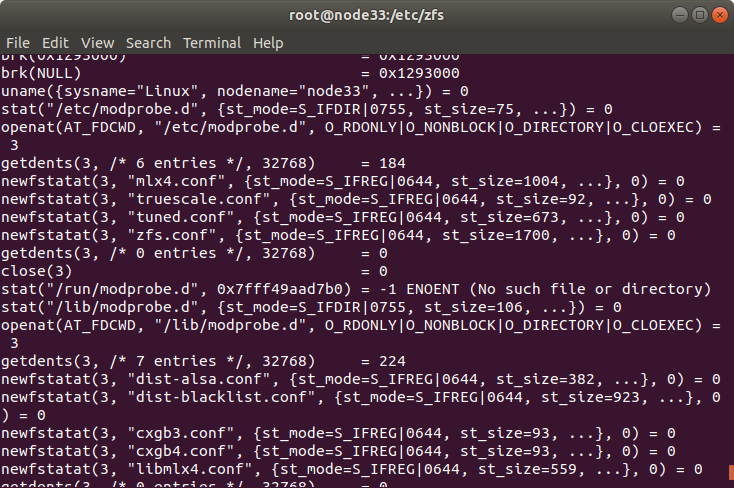
As I run modprobe -v zfs (verbose) it was returning me the verbose info, and so I saw that it was still trying to load those parameters so I knew it was reading those parameters from some file. I could have grep all the files in the filesystem looking for the parameter failing in the verbose or find all the files in the system named zfs.conf. To me it looked inefficient as it would be slow and may not bring any result (as I didn’t know how exactly my team member had compiled the code), however I expected to get the result. But what if I found 5 or 7 zfs.conf files?. Slow. I used strace. It was not installed but the RHEL license was active so I simple did:
yum install strace
strace stands for System Trace and so it records all the System Calls that the programs do. That’s a pro trick that will accompany you all your career.
So I did:
strace modprobe zfs
I did not use -v in here cause all the verbose would had been logged as a System Call and made more difficult my search. I got the output of all the System Calls and I just had to look for which files were being read.
Then I found that zfs.conf under /etc/modprobe.d/zfs.conf That was the one being read. So I commented the line and tried modprobe zfs and it worked perfectly. :)
Article created on: 1528997557 | 2018-06-14 18:32:15 IST
Recently a mentor of the UCC university came to visit me to my office, in order to do the following of one of the members of my Team, an intern.
Conversation was well, and then at some point he asked what courses could do the university teach to their students in order to be more prepared for working with us.
The Head of Business Development, that was in the meeting with me, mentioned something interesting:
– Make the publish their best code in github, bitbucket or similar git repository, and maintain it. It is like a CV.
He pointed that some of the students sent me their repository page, and they have not committed a thing for more than a year. And usually the code that I find there is less than a tic-tac-toe exercise.
– Obviously, to have git experience.
– Having contributed to an Open Source project
I exposed some things that would be helpful to have in the interns and grads that I hire:
– git experience
– Python programming
– C programming
– Unit Testing experience
– Networking experience, in particular iSCSI exports, tcpdump
– Programming Best practices, PEP-8 at least for Python
– Usage of Professional Tools like PyCharm, JetBrains IntelliJ, PHPStorm, Code Lion, Netbeans, Eclipse
– Linux experience. Many of them use Windows at home cause they also play video games. Really few programmers in real life use windows. So at least guys install Virtual Box or VMWare and run Linux in an Virtual Machine.
– Cloud experience. Using instances, CDNs, APIs, tools…
And as the talking advanced I gave him a hint of the Epic fail that all the universities are committing.
They teach git for a semester. They teach Python for one or two semester, the first year usually one, the second year another. And that’s it. Is gone.
When they exit the university they have not programmed in Python for 2 or 3 years, they have not used git, they have not used SQL for the same amount of time, etc…
My boss pointed that the best candidates do side projects in their spare time, and have that bright in their eyes. That sparkling in the eyes is what I call the eye of the tiger, the desire to improve, to learn. That spark.
I told the mentor of my intern that the big mistake is doing things in small parcels, isolated, one block and is gone. That the best way to proceed would be to:
Make the student start a project from the very beginning, from the first semester. Then keep making it bigger and better over time.
Let them improve it over time. Screw it in all the ways possible. Make them reach the limits of their initial architecture. Allow them to face having to redo the thing from the scratch. Allow them to do screw it, to break things, and to learn from their mistakes. Over and over.
Nobody becomes a great programmer coding average things for two semesters.
But let them realize where the problems are. Let them come back to their code of two or three months ago, before holidays, and realize how important is to make comments, to give proper names to the files and to the variables. Let them run that project over so many time, that at some point they have to change computer and they realize that what worked with windows Uppercases and Lowercase mixed files, does not work with Unix (case sensitive).
Let them grow.
Let them see their mistakes over the time.
Let them run the project for so long so they switch several times from Cloud provider, and discover the pros and the cons and the not-to-do, and things like run for your life before using sharing hostings that limit your CPU quota even that kills your MySql instances when they look at the email (true history, connecting to POP3 was raising the CPU and the provider was killing the MySQL instances, and so the queries) or that limits your queries per second, and then ask them to install a drupal and they will learn the hard way why Quality is always better than price and will make the right decisions when they work for somebody else or for their own Startup.
Even many of the supposedly Senior guys never learned from their mistakes, for example the Outsourcing guys, cause they work 6 months to a year in a project and then jump to another. Nobody explains the hell in maintenance and incidental they have left there. Nobody teach them.
Programming an small project for 6 months doesn’t make a master. Doing it for 5 years, growing it, learning from your mistakes and learning the YES and DO-NOT the hard way, the real way that works, cause makes you understand why something is better than other things, is the path.
That also remembers me why I love the MT Notation and many of the guys in Barcelona that saw it criticized the method, while my colleagues at Facebook and Dropbox actually told me that they use it, specially for Python and C/C++.
Allow them to thing about how to solve sorting a list of 1000 items by themselves. Let them think. The lazy will copy, but they will not grow.
Then let them implement a Bubble sort. Let them improve it, if they can. Allow them a week to try to improve that. Then make them sort 1,000,000 items so they see that is bloody slow. How can I improve that?. May I read the data from the drive at once, reading line by line was slow… let them think. Like if they were learning Martial Arts, and so discovering their strengths, that they have fast reflexes, allow them to grow.
Universities have to create good professional, not just machines of passing the exams. Real world demands talent, problem solving abilities, passion, ability to learn, and will to do the things well and to improve, and discipline.
After 5-6 years of programming on a daily basis, with an IDE, git, deploying to the Cloud as the basic, and growing a program and seeing the downsides of the solutions chosen, observing that the caveats where for a reason, learning that the Hardware is important, that is not the same to write to memory that to disk or to network, detecting the problems, redoing things, ending in a cul-de-sac, fixing, improving, learning, growing the project, growing himself/herself as a mind, as a programmer, as a thinker, as an expert, daily, even if it’s 30 minutes per day, then that person is prepared for some serious business.
Like piano, guitar, painting, writing… and any other activity, one require continue training in order to improve.
Students have to follow a journey in order to improve.
Let them start with Command Line, i.e. in C and files. Let’s do add later database support.
Deal with buffer overflow, file descriptor, locks and conversion types. Let them migrate to another language the entire project, using Git from the beginning.
Let them migrate again when they need to add Web support. Allow them to discover that instead of reloading all the page they can use Ajax/JSON. Let them deal with click-click that many common users do on the page buttons (so they submit twice the information). To discover SQL Injections. To use a Web Framework. To add Unit Testing. Add some improvement via Javascript Frameworks like responsive for mobiles.
Allow them to use a new Database, new Webserver or technology that is fashion and everybody on Twitter talks about, so it crashes in their face. And so they discover that they will not play or discover new technologies in actual project time in the Company of their future employers, cause shit happens, and impacts the Schedule, and the Company loses money. Universities: Teach them, let the students learn this for themselves, rather than screwing it up in several companies after university.
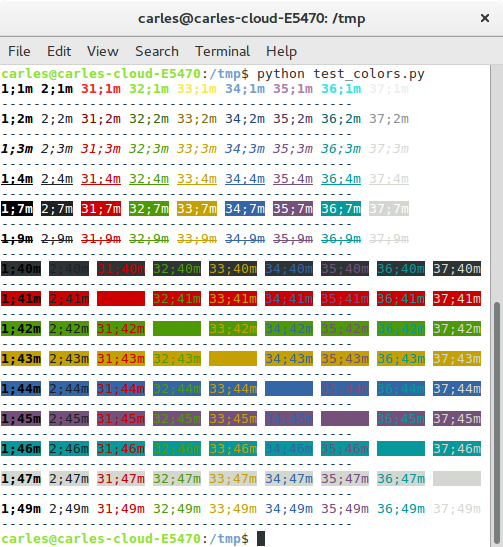
Please, take in count that the colors may be different depending on the Terminal used, so if you’re creating a commercial application I recommend you to try with some of them like: ubuntu terminal, ssh, putty for windows, MobaXTerm…
View from the colors from the Console of PyCharm Community Edition
I like to write Software that does not require from external packages, but if you want to use colors and write a portable program that runs in Linux, Mac OS X and Windows, I recommend you to use colorama.
Today I was checking the code, the latest push to the git repo, as I always do, and I saw something that was wrong.
Often Engineers can be confused by the ways different languages treat similar operations, so similarly as POSIX I try to use an standard way to program in any language that makes the code very clear and easy to understand, no matter if it’s C, Java, Python, PHP…
My code and the code of my Teams will be clear, and easy to understand. And as the good Engineers jump from language to language upon the needs, is better for all to proceed like this to avoid confusions.
In this case I want to cover a simple case that I detected. A wrong usage.
The code was returning True on success and if not simply return.
Here I show a simple demonstration that return itself will be returning return None.
# Proof of Concept for avoiding return without the type
# Author: Carles Mateo
# Creation Date: 2018-03-27
#
from pprint import pprint
def boolean_test(b_value):
if b_value is False:
return
Updated on 2017-04-04 12:58 Barcelona Time 1491303515:
A method writeValuesFromArrayListToDisk(String sFilename) has been introduced as per a request, to easily check that the data is properly sorted.
A silly bug in the final ArrayList generation has been solved. It was storing iCounter that was always 1 as this is not the compressed version, for supporting repeated numbers, of the algorithm. I introduced this method for the article, as it is not necessary for the algorithm as it is already sorted, and unfortunately I didn’t do a final test on the output. My fault.
Some JavaDoc has been updated
Past Friday I was discussing with my best friend about algorithms and he told me that hadoop is not fast enough, and about when I was in Amazon and as part of the test they asked me to defined an S3 system from the scratch, and I did using Java and multiple streams per file and per node (replication factor) and they told me that what I just created was the exact way their system works, and we ended talking about my sorting algorithm CSort, and he asked me if it could run in MultiThread. Yes, it is one of the advantages in front of QuickSort. Also it can run in multinode, different computers. So he asked me how much faster it would be a MultiThread version of CSort, versus a regular QuickSort.
Well here is the answer with 500 Million of registers, with values from 1 to 1000000, and deduplicating.
2017-03-26 18:50:41 CSort time in seconds:0.189129089
2017-03-26 18:51:47 QuickSort cost in seconds:61.853190885
That’s Csort is 327 times faster than QuickSort!. In this example and with my busy 4 cores laptop. In my 8 cores computer it is more than 525 times faster. Imagine in a Intel Xeon Server with a 64 cores!.
How is it possible? The answer is easy, it has O(n) complexity. I use linear access.
This depends on your universe of Data. Please read my original posting about CSort here, that explains it on detail.
Please note that CSort with compression is also available for keeping duplicated values and also saving memory (space) and time, with equally totally astonishing results.
Please note that in this sample I first load the values to an Array, and then I work from this. This is just to avoid bias by discarding the time of loading the data from disk, but, in the other article you have samples where CSort sorts at the same time that loads the data from disks. I have a much more advanced algorithm that self allocates the memory needed for handling an enormous universe of numbers (big numbers and small with no memory penalty), but I’m looking forward to discuss this with a tech giant when it hires me. ;) Yes, I’m looking for a job.
In my original article I demonstrated it in C and PHP, this time here is the code in Java. It uses the MT Notation.
You can download the file I used for the tests from here:
50 Million results, with values from 0 to 1M: carles_sort-50M.txt.zip [156 MB] (344 MB uncompressed)
Obviously it runs much more faster than hashing. I should note that hashing and CSorting with .containsKey() is faster than QuickSorting. (another day I will talk about sorting Strings faster) ;)
/*
* (c) Carles Mateo blog.carlesmateo.com
* Proof of concept of CSort, with multithread, versus QuickSort
* For the variables notation MT Notation is used.
*/
package com.carlesmateo.blog;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
/**
* @author carles mateo
*/
public class CSortMultiThread extends Thread {
// Download the original file from the blog
public static final int piNUM_REGISTERS_IN_FILE = 50000000;
// Max value found, to optimize the memory used for CSort
// Note that CSort can be implemented in the read from file mechanism
// in order to save memory (space)
public static int piMaxValue = 0;
// The array containing the numbers read from disk
public static int[] paiNumbers;
// The array used by CSort (if not using direct loading from disk)
public static int[] paiNumbersCsorted;
// Final ArrayList Sorted. CSort and QuickSort finally fullfil this
public static ArrayList<Integer> pliNumbers = new ArrayList<>();
// For the Threads
private Thread oT;
private String sThreadName;
private int piStart;
private int piEnd;
private boolean bFinished = false;
CSortMultiThread (String name, int iStart, int iEnd) {
sThreadName = name;
piStart = iStart;
piEnd = iEnd;
writeWithDateTime("Creating " + sThreadName );
}
public void run() {
writeWithDateTime("Running " + sThreadName + " to sort from " + piStart + " to " + piEnd);
int iCounter;
int iNumber;
for (iCounter=piStart; iCounter < piEnd; iCounter++) {
iNumber = paiNumbers[iCounter];
paiNumbersCsorted[iNumber] = 1;
}
System.out.println("Thread " + sThreadName + " exiting.");
bFinished = true;
}
public void start () {
writeWithDateTime("Starting " + sThreadName );
if (oT == null) {
oT = new Thread (this, sThreadName);
oT.start ();
}
}
/**
* Write values to Disk to demonstrate that are sorted ;)
* @param sFilenameData
*/
private static void writeValuesFromArrayListToDisk(String sFilenameData) {
ObjectOutputStream out = null;
int iCounter;
try {
out = new ObjectOutputStream(new FileOutputStream(sFilenameData));
for (iCounter=0; iCounter<pliNumbers.size(); iCounter++) {
out.writeChars(pliNumbers.get(iCounter).toString() + "\n");
}
// To store the object instead
//out.writeObject(pliNumbers);
} catch (IOException e) {
System.out.println("I/O Error!");
e.printStackTrace();
displayHelpAndQuit(10);
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
System.out.println("I/O Error!");
e.printStackTrace();
displayHelpAndQuit(10);
}
}
}
}
/**
* Reads the data from the disk. The file has 50M and we will be duplicating
* to get 500M registers.
* @param sFilenameData
*/
private static void readValuesFromFileToArray(String sFilenameData) {
BufferedReader oBR = null;
String sLine;
int iCounter = 0;
int iRepeat;
int iNumber;
// We will be using 500.000.000 items, so dimensionate the array
paiNumbers = new int[piNUM_REGISTERS_IN_FILE * 10];
try {
oBR = new BufferedReader(new FileReader(sFilenameData));
while ((sLine = oBR.readLine()) != null) {
for (iRepeat = 0; iRepeat < 10; iRepeat++) {
int iPointer = (piNUM_REGISTERS_IN_FILE * iRepeat) + iCounter;
iNumber = Integer.parseInt(sLine);
paiNumbers[iPointer] = iNumber;
if (iNumber > piMaxValue) {
piMaxValue = iNumber;
}
}
iCounter++;
}
if (iCounter < piNUM_REGISTERS_IN_FILE) {
write("Warning... only " + iCounter + " values were read");
}
} catch (FileNotFoundException e) {
System.out.println("File not found! " + sFilenameData);
displayHelpAndQuit(100);
} catch (IOException e) {
System.out.println("I/O Error!");
e.printStackTrace();
displayHelpAndQuit(10);
} finally {
if (oBR != null) {
try {
oBR.close();
} catch (IOException e) {
System.out.println("I/O Error!");
e.printStackTrace();
displayHelpAndQuit(10);
}
}
}
}
private static String displayHelp() {
String sHelp = "Help\n" +
"====\n" +
"Csort from Carles Mateo blog.carlesmateo.com\n" +
"\n" +
"Proof of concept of the fast load algorithm\n" +
"\n";
return sHelp;
}
/**
* Displays Help Message and Quits with and Error Level
* Errors:
* - 1 - Wrong number of parameters
* - 10 - I/O Error
* - 100 - File not found
* @param iErrorLevel
*/
private static void displayHelpAndQuit(int iErrorLevel) {
System.out.println(displayHelp());
System.exit(iErrorLevel);
}
// This is QuickSort from vogella http://www.vogella.com/tutorials/JavaAlgorithmsQuicksort/article.html
public static void sort() {
int piNumber = paiNumbers.length;
quicksort(0, piNumber - 1);
}
private static void quicksort(int low, int high) {
int i = low, j = high;
// Get the pivot element from the middle of the list
int pivot = paiNumbers[low + (high-low)/2];
// Divide into two lists
while (i <= j) {
// If the current value from the left list is smaller then the pivot
// element then get the next element from the left list
while (paiNumbers[i] < pivot) {
i++;
}
// If the current value from the right list is larger then the pivot
// element then get the next element from the right list
while (paiNumbers[j] > pivot) {
j--;
}
// If we have found a values in the left list which is larger then
// the pivot element and if we have found a value in the right list
// which is smaller then the pivot element then we exchange the
// values.
// As we are done we can increase i and j
if (i <= j) {
exchange(i, j);
i++;
j--;
}
}
// Recursion
if (low < j)
quicksort(low, j);
if (i < high)
quicksort(i, high);
}
private static void exchange(int i, int j) {
int temp = paiNumbers[i];
paiNumbers[i] = paiNumbers[j];
paiNumbers[j] = temp;
}
/**
* We want to remove duplicated values
*/
private static void removeDuplicatesFromQuicksort() {
int iCounter;
int iOldValue=-1;
int iNewValue;
for (iCounter=0; iCounter<paiNumbers.length; iCounter++) {
iNewValue = paiNumbers[iCounter];
if (iNewValue != iOldValue) {
iOldValue = iNewValue;
pliNumbers.add(iNewValue);
}
}
}
// End of vogella QuickSort code
/**
* Generate the final Array
*/
private static void copyFromCSortToArrayList() {
int iCounter;
int iNewValue;
for (iCounter=0; iCounter<=piMaxValue; iCounter++) {
iNewValue = paiNumbersCsorted[iCounter];
if (iNewValue > 0) {
pliNumbers.add(iCounter);
}
}
}
/**
* Write with the date
* @param sText
*/
private static void writeWithDateTime(String sText) {
DateFormat oDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date oDate = new Date();
String sDate = oDateFormat.format(oDate);
write(sDate + " " + sText);
}
/**
* Write with \n
* @param sText
*/
private static void write(String sText) {
System.out.println(sText + "\n");
}
public static void main(String args[]) throws InterruptedException {
// For Profiling
long lStartTime;
double dSeconds;
long lElapsedTime;
int iThreads = 8;
int iRegistersPerThread = piNUM_REGISTERS_IN_FILE / iThreads;
CSortMultiThread[] aoCSortThreads = new CSortMultiThread[iThreads];
writeWithDateTime("CSort MultiThread proof of concept by Carles Mateo");
writeWithDateTime("Reading values from Disk...");
readValuesFromFileToArray("/home/carles/Desktop/codi/java/carles_sort.txt");
writeWithDateTime("Readed");
writeWithDateTime("Total values to sort de deduplicate " + paiNumbers.length);
writeWithDateTime("The max value between the Data is " + piMaxValue);
paiNumbersCsorted = new int[piMaxValue + 1];
writeWithDateTime("Performing CSort with removal of duplicates");
lStartTime = System.nanoTime();
for (int iThread=0; iThread < iThreads; iThread++) {
int iStart = iThread * iRegistersPerThread;
int iEnd = ((iThread + 1) * iRegistersPerThread) - 1;
if (iThread == (iThreads -1)) {
// Last thread grabs the remaining.
// For instance 100/8 = 12 so each Thread orders 12 registers,
// but last thread orders has 12 + 4 = 16
iEnd = piNUM_REGISTERS_IN_FILE -1 ;
}
CSortMultiThread oThread = new CSortMultiThread("Thread-" + iThread, iStart, iEnd);
oThread.start();
aoCSortThreads[iThread] = oThread;
}
boolean bExit = false;
while (bExit == false) {
bExit = true;
for (int iThread=0; iThread < iThreads; iThread++) {
if (aoCSortThreads[iThread].bFinished == false) {
bExit = false;
// Note: 10 milliseconds. This takes some CPU cycles, but we need
// to ensure that all the threads did finish.
sleep(10);
continue;
}
}
}
writeWithDateTime("Main loop ended");
writeWithDateTime("Copy to the ArrayList");
copyFromCSortToArrayList();
writeWithDateTime("The final array contains " + pliNumbers.size());
lElapsedTime = System.nanoTime() - lStartTime;
dSeconds = (double)lElapsedTime / 1000000000.0;
writeWithDateTime("CSort time in seconds:" + dSeconds);
writeWithDateTime("Writing values to Disk...");
writeValuesFromArrayListToDisk("/home/carles/Desktop/codi/java/carles_sort-csorted.txt");
// Reset the ArrayList
pliNumbers = new ArrayList<>();
lStartTime = System.nanoTime();
/** QuickSort begin **/
writeWithDateTime("Sorting with QuickSort");
sort();
writeWithDateTime("Finished QuickSort");
writeWithDateTime("Removing duplicates from QuickSort");
removeDuplicatesFromQuicksort();
writeWithDateTime("The final array contains " + pliNumbers.size());
lElapsedTime = System.nanoTime() - lStartTime;
dSeconds = (double)lElapsedTime / 1000000000.0;
writeWithDateTime("QuickSort cost in seconds:" + dSeconds);
}
}
The complete traces:
run:
2017-03-26 19:28:13 CSort MultiThread proof of concept by Carles Mateo
2017-03-26 19:28:13 Reading values from Disk...
2017-03-26 19:28:39 Readed
2017-03-26 19:28:39 Total values to sort de deduplicate 500000000
2017-03-26 19:28:39 The max value between the Data is 1000000
2017-03-26 19:28:39 Performing CSort with removal of duplicates
2017-03-26 19:28:39 Creating Thread-0
2017-03-26 19:28:39 Starting Thread-0
2017-03-26 19:28:39 Creating Thread-1
2017-03-26 19:28:39 Starting Thread-1
2017-03-26 19:28:39 Running Thread-0 to sort from 0 to 6249999
2017-03-26 19:28:39 Creating Thread-2
2017-03-26 19:28:39 Starting Thread-2
2017-03-26 19:28:39 Running Thread-1 to sort from 6250000 to 12499999
2017-03-26 19:28:39 Creating Thread-3
2017-03-26 19:28:39 Running Thread-2 to sort from 12500000 to 18749999
2017-03-26 19:28:39 Starting Thread-3
2017-03-26 19:28:39 Creating Thread-4
2017-03-26 19:28:39 Starting Thread-4
2017-03-26 19:28:39 Running Thread-3 to sort from 18750000 to 24999999
2017-03-26 19:28:39 Creating Thread-5
2017-03-26 19:28:39 Running Thread-4 to sort from 25000000 to 31249999
2017-03-26 19:28:39 Starting Thread-5
2017-03-26 19:28:39 Creating Thread-6
2017-03-26 19:28:39 Starting Thread-6
2017-03-26 19:28:39 Running Thread-5 to sort from 31250000 to 37499999
2017-03-26 19:28:39 Creating Thread-7
2017-03-26 19:28:39 Starting Thread-7
2017-03-26 19:28:39 Running Thread-6 to sort from 37500000 to 43749999
2017-03-26 19:28:39 Running Thread-7 to sort from 43750000 to 49999999
Thread Thread-0 exiting.
Thread Thread-2 exiting.
Thread Thread-1 exiting.
Thread Thread-6 exiting.
Thread Thread-7 exiting.
Thread Thread-5 exiting.
Thread Thread-4 exiting.
Thread Thread-3 exiting.
2017-03-26 19:28:39 Main loop ended
2017-03-26 19:28:39 Copy to the ArrayList
2017-03-26 19:28:39 The final array contains 1000001
2017-03-26 19:28:39 CSort time in seconds:0.189129089
2017-03-26 19:28:39 Sorting with QuickSort
2017-03-26 19:29:40 Finished QuickSort
2017-03-26 19:29:40 Removing duplicates from QuickSort
2017-03-26 19:29:41 The final array contains 1000001
2017-03-26 19:29:41 QuickSort cost in seconds:61.853190885
BUILD SUCCESSFUL (total time: 1 minute 28 seconds)
In this article I want to explain how I created a content filter for Postfix, in PHP.
The basic idea is to examine all the incoming messages, looking for a Credit Card pattern, and then sending those emails to another Server, that for instance is PCI compliant, and sending an email to the original receiver telling that they received an email with a CC, that is stored in a safe Server.
I choose the pipe mechanism, because is the last one in the chain of content filters, and first I want to pass the antivirus (Amavis), antispam and other content filters.
Then I inject the emails to sendmail, with the params -G -i , granting that the email will not be reprocessed entering an infinite loop.
#!/usr/bin/php
<?php
/*
* Carles Mateo
*/
date_default_timezone_set('Europe/Andorra');
$s_dest_mail_secure = 'secure@pciserver.carlesmateo.com';
$b_regex_found = false;
$b_emails_rcpt_to = Array();
// All major credit cards regex
// The CC anywhere
$s_cc_regex = '/(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6011[0-9]{12}|622((12[6-9]|1[3-9][0-9])|([2-8][0-9][0-9])|(9(([0-1][0-9])|(2[0-5]))))[0-9]{10}|64[4-9][0-9]{13}|65[0-9]{14}|3(?:0[0-5]|[68][0-9])[0-9]{11}|3[47][0-9]{13})/';
function log_event($s_message) {
syslog(LOG_WARNING, $s_message);
}
function save_message_to_file($s_file, $s_message) {
$o_file = fopen($s_file, "a");
fwrite($o_file, $s_message);
fclose($o_file);
}
function read_file($s_file) {
$s_contents = file_get_contents($s_file);
if ($s_contents === false) {
return '';
}
return $s_contents;
}
function get_all_rcpt_to($st_emails_input) {
// First email is pos 5 of the array
$st_emails = $st_emails_input;
unset($st_emails[0]);
unset($st_emails[1]);
unset($st_emails[2]);
unset($st_emails[3]);
unset($st_emails[4]);
asort($st_emails);
return $st_emails;
}
/*
* Returns a @secure. email, from the original email
*/
function get_secure_email($s_email) {
$i_pos = strpos($s_email, '@');
$s_email_new = $s_email;
if ($i_pos > 0) {
$s_email_new = substr($s_email, 0, $i_pos);
$s_email_new .= 'secure.';
$s_email_new .= substr($s_email, $i_pos +1);
}
return $s_email_new;
}
function replace_tpl_variables($s_text, $s_sender_original) {
// TODO: Replace static values
$s_date_sent = date('r'); // RFC 2822 formatted date
$s_text = str_replace('#DATE_NOW#', $s_date_sent, $s_text);
$s_text = str_replace('#FROM_NAME#', 'Carles Mateo', $s_text);
$s_text = str_replace('#FROM_EMAIL#', 'mateo@blog.carlesmateo.com', $s_text);
$s_text = str_replace('#EMAIL_SENDER_ORIGINAL#', $s_sender_original, $s_text);
return $s_text;
}
function delete_file($s_file) {
unlink($s_file);
}
// Read the RCPT TO: fields ${recipient}
$st_emails_rcpt_to = get_all_rcpt_to($argv);
// Read the email
$email = '';
$fd = fopen("php://stdin", "r");
while (!feof($fd)) {
$line = fread($fd, 1024);
$email .= $line;
}
fclose($fd);
// Get the portion of the email without headers (to avoid id's being detected as CC numbers)
$i_pos_subject = strpos($email, 'Subject:');
if ($i_pos_subject > 0) {
// Found
$email_sanitized = substr($email, $i_pos_subject);
} else {
// If we don't locate subject we look for From:
$i_pos_from = strpos($email, 'From:');
if ($i_pos_from > 0) {
$email_sanitized = substr($email, $i_pos_from);
} else {
// Impossible email, but continue
$email_sanitized = $email;
}
}
// Remove spaces, and points so we find 4111.1111.1111.111 and so
$email_sanitized = str_replace(' ', '', $email_sanitized);
$email_sanitized = str_replace('.', '', $email_sanitized);
$email_sanitized = str_replace('-', '', $email_sanitized);
$s_message = "Script filtercard.php successfully ran\n";
log_event('Arguments: '.serialize($argv));
$i_result = preg_match($s_cc_regex, $email_sanitized, $s_matches);
if ($i_result == 1) {
$b_regex_found = true;
$s_message .= 'Card found'."\n";
log_event($s_message);
} else {
// No credit card
$s_message .= 'No credit card found'."\n";
log_event($s_message);
}
$s_dest_mail_original = $argv[5];
$s_sender_original = $argv[2];
// Generate a unique id
$i_unique_id = time().'-'.rand(0,99999).'-'.rand(0,99999);
$INSPECT_DIR='/var/spool/filter/';
// NEVER NEVER NEVER use "-t" here.
$SENDMAIL="/usr/sbin/sendmail -G -i";
$s_file_unique = $INSPECT_DIR.$i_unique_id;
# Exit codes from <sysexits.h>
$EX_TEMPFAIL=75;
$EX_UNAVAILABLE=69;
// Save the file
save_message_to_file($s_file_unique, $email);
$st_output = Array();
if ($b_regex_found == false) {
// Send normally
foreach ($st_emails_rcpt_to as $i_key=>$s_email_rcpt_to) {
$s_sendmail = $SENDMAIL.' "'.$s_email_rcpt_to.'" <'.$s_file_unique;
$i_status = exec($s_sendmail, $st_output);
log_event('Status Sendmail (original mail): '.$i_status.' to: '.$s_email_rcpt_to);
}
delete_file($s_file_unique);
exit();
}
// Send secure email
$s_sendmail = $SENDMAIL.' "'.$s_dest_mail_secure.'" <'.$s_file_unique;
$i_status = exec($s_sendmail, $st_output);
log_event('Status Sendmail (secure email): '.$i_status.' to: '.$s_dest_mail_secure);
$s_email_tpl = read_file('/usr/share/secure/smtpfilter_email.txt');
if ($s_email_tpl == '') {
// Generic message
$s_date_sent = date('r'); // RFC 2822 formatted date
$s_email_tpl = <<<EOT
Date: $s_date_sent
From: secure <noreply@secure.carlesmateo.com>
Subject: Message with a Credit Card from $s_sender_original
You received a message with a Credit Card
EOT;
}
$s_email_tpl = replace_tpl_variables($s_email_tpl, $s_sender_original);
save_message_to_file($s_file_unique.'-tpl', $s_email_tpl);
// Send the replacement email
foreach ($st_emails_rcpt_to as $i_key=>$s_email_rcpt_to) {
$st_output = Array();
$s_sendmail = $SENDMAIL.' "'.$s_email_rcpt_to.'" <'.$s_file_unique.'-tpl';
$i_status = exec($s_sendmail, $st_output);
log_event('Status Sendmail (TPL): '.$i_status.' to: '.$s_email_rcpt_to);
}
delete_file($s_file_unique);
delete_file($s_file_unique.'-tpl');
/* Headers:
From: Carles Mateo <mateo@carlesmateo.com>
To: "carles2@carlesmateo.com" <carles2@carlesmateo.com>, Secure
<secure@secure.carlesmateo.com>
CC: "test@carlesmateo.com" <test@carlesmateo.com>
Subject: Test with several emails and CCs
Thread-Topic: Test with several emails and CCs
Thread-Index: AQHRt1tmO/z+TpI64UiniKm7I56onw==
Date: Thu, 25 May 2016 14:32:15 +0000
*/
You can test it connecting by telnet to port 25 and doing (in bold the SMTP commands):
HELO mycomputer.com MAIL FROM: test@carlesmateo.com RCPT TO: just@asample.com RCPT TO: another@different.com DATA
Date: Mon, 30 May 2016 14:07:56 +0000
From: Carles Mateo <mateo@blog.carlesmateo.com>
To: Undisclosed recipients
Subject: Test with CC
This is just a test with a Visa CC 4111 1111 11-11-1111.
You can use the nc command for commodity.
When you’re all set I recommend you to test it by sending real emails from real servers
Some additional command-line tools that I use to install and use on my text client Systems. Initially here were not listed commands that are shipped with every Linux, but the additional tools I install in every Workstation or Server.
Apache benchmarks (ab)
To stress a Web Server
atop
A good complement to htop, iftop… monitoring tools
bzip2
Cool compressor better than gzip and that also accepts streams.
cfdisk
Nice tool to work with partitions through modern menus.
ctop
Command line / text based Linux Containers monitoring tool.
Very nice System Stats tool. You can specify individual stats, like a drive.
edac-util
Error reporting utility
edac-util --verbose mc0: 0 Uncorrected Errors with no DIMM info mc0: 0 Corrected Errors with no DIMM info mc0: csrow0: 0 Uncorrected Errors mc0: csrow0: CPU_SrcID#0_MC#0_Chan#0_DIMM#0: 0 Corrected Errors mc0: csrow0: CPU_SrcID#0_MC#0_Chan#1_DIMM#0: 0 Corrected Errors mc0: csrow0: CPU_SrcID#0_MC#0_Chan#2_DIMM#0: 0 Corrected Errors mc1: 0 Uncorrected Errors with no DIMM info mc1: 0 Corrected Errors with no DIMM info mc1: csrow0: 0 Uncorrected Errors mc1: csrow0: CPU_SrcID#0_MC#1_Chan#0_DIMM#0: 0 Corrected Errors mc1: csrow0: CPU_SrcID#0_MC#1_Chan#1_DIMM#0: 0 Corrected Errors mc1: csrow0: CPU_SrcID#0_MC#1_Chan#2_DIMM#0: 0 Corrected Errors mc2: 0 Uncorrected Errors with no DIMM info mc2: 0 Corrected Errors with no DIMM info mc2: csrow0: 0 Uncorrected Errors mc2: csrow0: CPU_SrcID#1_MC#0_Chan#0_DIMM#0: 0 Corrected Errors mc2: csrow0: CPU_SrcID#1_MC#0_Chan#1_DIMM#0: 0 Corrected Errors mc2: csrow0: CPU_SrcID#1_MC#0_Chan#2_DIMM#0: 0 Corrected Errors mc3: 0 Uncorrected Errors with no DIMM info mc3: 0 Corrected Errors with no DIMM info mc3: csrow0: 0 Uncorrected Errors mc3: csrow0: CPU_SrcID#1_MC#1_Chan#0_DIMM#0: 0 Corrected Errors mc3: csrow0: CPU_SrcID#1_MC#1_Chan#1_DIMM#0: 0 Corrected Errors mc3: csrow0: CPU_SrcID#1_MC#1_Chan#2_DIMM#0: 0 Corrected Errors
ethtool
fatrace Reports file access events from all running processes in real time.
flock With flock several processes can have a shared lock at the same time, or be waiting to acquire a write lock. With lslocks from util-linux package you can get a list of these processes.
fstrim
discard unused blocks on a mounted filesystem (local or remote). Is useful for freeing blocks no longer used in ZFS zvols. That can also be achieved by mount -o discard
fuser Show which processes use the named files, sockets, or filesystems.
To set the metrics of all IPV4 routes attached to a given network interface
ifstat
Pretty network interfaces stats.
iftop
To watch metrics for a network interface (or wireless)
iostat
CPU and IO devices stats. I modified some collectors for telegraf and influxdb consumed by grafana for fetching the Write KB/s, Read KB/s, Bandwidth of the Magnetic Spinning drives and SSD during declustered rebuild.
iotop
iperf
Perform network throughput tests
ipmitool
iptables
iscsiadm
java (jre Oracle and OpenJDK)
journalctl
ldap-utils
ldapsearch and the other tools to work with LDAP.
less According to manpages, the opposite of more. :) What it does is display a file, and you can scroll up/down, you can search for patterns… Examples: cat /etc/passwd | less less /etc/passwd # -n doesn’t count the lines, to save time # For a specific Offset less -n +500000000P /var/log/apache2/giant.log # For 50% point less -n +50p /var/log/apache2/giant.log
lrzip /lrztar
Compressor that compresses very efficiently big files, specially GB of of source code.
lrzsz (Zmodem)
An utility to send files to the Server through a terminal.
Very useful when you don’t want to scp or rsftp, for example because that requires MFA (Multi Factor Authentication) to be performed again and you already have a session open.
Moba xTerm for Windows is one of the Terminal clients that accepts Upload/Download of Z-modem
apt install lrzsz
lsblk
List the block devices. Also is handy blkid but you can get this from /dev/disk/by-id/
lynx
Text browser. really handy.
ltrace To trace library calls.
mc
Midnight Commander
md5sum
memtester
Basically for testing Memory.
This will allocate 4GB of RAM and run the test 10 times.
sudo memtester 4096 10
mtr
Network tool mix between ping and traceroute.
mytop
To see in real time queries and slow queries to mysql
ncdu
Show the space used by any directory and subdirectory
nginx (fpm-php) and apache
The webservers
nfs client
nmon
Offers monitoring of different aspects: Network, Disk, Processes…
open-vpn
openssh-server
parted
Partition manipulation
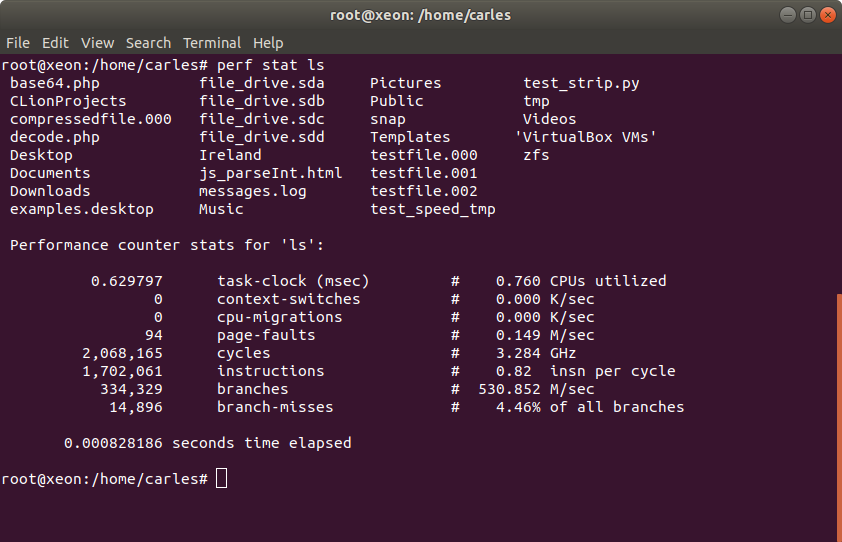
perf
Performance profiler.
Ie: perf top perf stat ls
PHP + curl + mysql (hhvm)
pixz
A parallel, multiprocessor, variant of gzip/bzip2 that can leverage several processors to speed up the compression over files.
If the input looks like a tar archive, it also creates an index of all the files in the archive. This allows the extraction of only a small segment of the tarball, without needing to decompress the entire archive.
postcat
postcat -q ID shows the details of a message in the queue
python-pip and pypy
pv Pipe Viewer – is a terminal-based tool for monitoring the progress of data through a pipeline. It can be inserted into any normal pipeline between two processes to give a visual indication of how quickly data is passing through, how long it has taken, how near to completion it is, and an estimate of how long it will be until completion.
dd if=/dev/urandom | pv | dd of=/dev/null
Output:
1,74MB 0:00:09 [ 198kB/s] [ <=> ]
Probably you’ll prefer to use dd with status=progress option, it’s just a sample.
Utility to work with partitions that can export and import configs through STDIN and STDOUT to automate partitions operations.
slabtop Displays Kernel slab cache information in real time.
smartctl
Utility for dealing with the S.M.A.R.T. features of the disks, knowing errors…
split Split a file into several, based by text lines, or binary: number of bytes per file.
sha512sum
sshfs
Mount a mountpoint on a remote Server by using SSH.
sshpass SSH without typing the password. -f for reading it from a file. sshpass -p “mypassword” ssh -o StrictHostKeyChecking=no root@10.251.35.251
In this sample passing the command ls, so this will be executed, and logout. sshpass -p “mypassword” ssh -o StrictHostKeyChecking=no root@10.251.35.251 ls
sshuttle
A poor’s man VPN through SSH that is available for Linux and Mac OS X.
Tree simply shows the directory hierarchy in a graphical (text mode) way. Useful to see where files and subfolders are.
xxd Make a hexdump or do the reverse
sudo xxd /dev/nvme0n1p1 | less
zcat Just like cat, but for compressed filed.
zcat logs.tar.gz | grep "Error"
zcat logs.tar.gz | less
zless
zram-config
Sergey Davidoff stumbled upon a project called compcache that creates a RAM based block device which acts as a swap disk, but is compressed and stored in memory instead of swap disk (which is slow), allowing very fast I/O and increasing the amount of memory available before the system starts swapping to disk. compcache was later re-written under the name zRam and is now integrated into the Linux kernel.
Whatch allow you to execuate a command and what it (refresh it) at a given intervals, for example every two seconds. For example, if normally I would do:
while [ true ]; do zpool status | head -n10 ; sleep 10; done
while [ true ]; do df -h; sleep 60; done
while [ true ]; do ls -al /tmp | head -n5 ; sleep 2; done
Then I can do:
watch -n10 zpool status
Or:
watch -n60 df -h
Or
watch "ls -al /tmp | head -n5"
For my Dockers, and cloudinit with Ubuntu, my defaults are:
apt update; apt install htop mc ncdu strace git binutils