I’ve good memories of this video.
In the middle of pandemic, with all commerce’s closed and no access to better cameras or equipment, I demonstrated the plug-in architecture that I created and I added to my CTOP.py Open Source Python Monitoring tool in a global conference for all IT in ABK (Activision Blizzard King).
I was so proud.
For that I cloned ctop into a Raspberry Pi 4 with Ubuntu LTS and had that motherboard which is a Christmas Tree LED attached to the GPIO.
As the CPU load on the Raspberry was low, the LED’s were green, and a voice (recorded and provided by an Irish friend) was played “The System is Healthy”.
Then I added load to the CPU and the LED’s changed.
And I added more load to the CPU and the LED’s turned to Red and and human voice “CPU load is too high”.
Voice is only played after a change in the state and with a cool down of a minute, to prevent flapping situations to keep the program chatting like a parrot :)
I should have shaved myself, but you know, it was a savage pandemic.
Also a manager from Blizzard DM me and told me that the touch pad being emerged was due to the battery swallowing and that it could explode, so I requested a replacement. Then I explained to other colleagues with the same symptom, and to others with no problems so they are not at risk if the same happened to them.
WFH made things that would be quickly detected in the offices by others (like the touchpad emerging) go unnoticed.
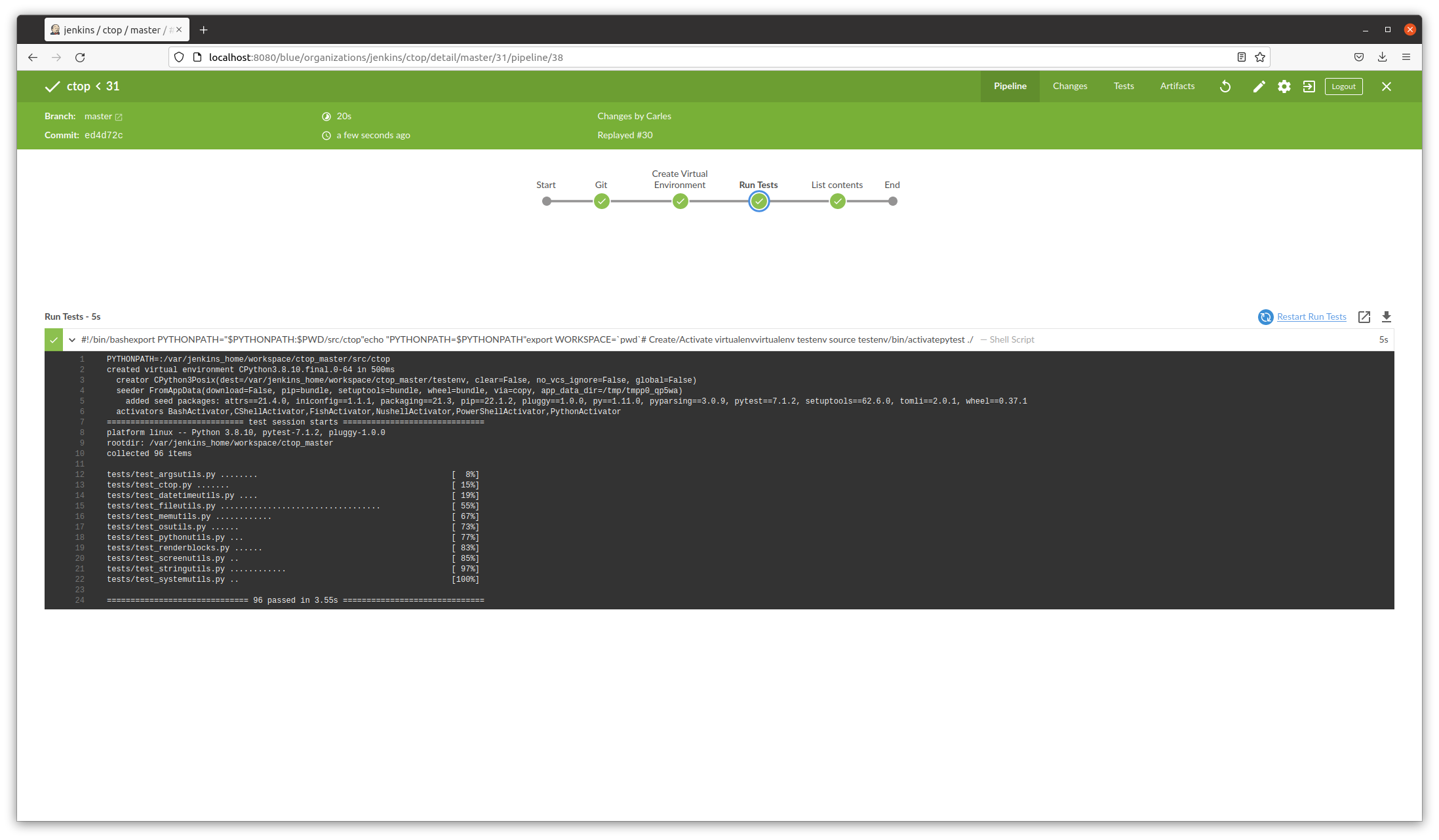
if you are looking for source code, it is in the CTOP’s gitlab repository. However it’s advanced Python plugin architecture code.
If you just look for a sample of how to power on the LED’s in different colors, and the tricks for solving any problem you may encounter, then look at it here: