I started to explain that I was migrating some services from Amazon and that some of my sites were under Maintenance and that I would provide more information.
Here is the complete history of why I migrated all the services from my 11 years old Amazon account to other CSP.
Some lessons can be learned from my adventure.
I migrated my last services from Amazon to GCP
Amazon sent me an email on October 6th, this year 2021, telling me that they will disable EC2-Classic by August 2022. I thought I would not be able to keep my Static Ip’s as in the past VPC Ip’s and EC2-Classic Ip’s were not transferable, so considering that I would loss my Static Ip’s anyway I started to migrate to some to other providers like Digital Ocean.
Is not cool losing Static Ip (Elastic Ip in AWS) Addresses as this is bad for SEO, so given that I though I would lose my Static Ips that have been with me for years, I started to migrate certain services to providers much more economic.
Amazon is terrible communicating, and I talked with some product managers in the past about that, when they lost one of my Volumes, and the email was so cold and terrible that actually that hurt more than Amazon losing my Data. I believed that it was a poorly made Scam and when I realized it was true I reached one of my friends, that is manager there, as I know they care for doing things right, and he organized a meeting with two PM so I can pass my feedback.
The Cloud providers are changing things very fast, and nobody is able to be up to date with the changes, unless their work position allows plenty of time to get updated. Even if pages of documentation are provided, you have to react to an event that they externally generated forcing you to action. Action to read all the documentation about EC2-Classic migrations, action to prepare to have migrated by August 2022.

So August 2022… I was counting that I had plenty of time but I’m writing a new book about using the Amazon SDK for Python, boto3, and I was doing some API calls and they started to fail in a very unusual way, Exceptions with timeout, but only for the only region where I had EC2-Classic.
urllib3.exceptions.NewConnectionError: <botocore.awsrequest.AWSHTTPSConnection object at 0x7f0347d545e0>: Failed to establish a new connection: [Errno -2] Name or service not known
My config was:
o_config = Config(
region_name="us-east-1a",
signature_version="v4",
retries={
'max_attempts': 10,
'mode': 'standard'
}
)
But if I switched to another region name, it would work:
region_name='us-west-2',
I made a mistake in here, the region name is “us-east-1” and not “us-east-1a“. “us-east-1a” is the availability zone. So the SDK was giving a timeout because in order to connect to the endpoint it uses the region name as part of the hostname. So it doesn’t find that endpoint because it doesn’t exist.
I never understood why a company like Amazon is unable to provide the SDK with a sample project or projects 100% working, with the source code so people has a base that works to build up.
Every API that I have created, I have provided it with documentation but also with example for several languages for how to use it.
In 2013 I was CTO of an online travel agency, and we had meta-searchers consuming our API and we were having several hundreds of thousands requests per second. Everything was perfectly documented, examples were provided for several languages, the document and the SDK had version numbers…
Everybody forgets about Developers and companies throw terrible and cold products to the poor Developers, so difficult to use. How many Developers would like to say: Listen Mr. President of the big Cloud Company XXXX, I only want to spawn a VM that works, and fast, with easy wizards. I don’t want to learn 50 hours before being able to use your overpriced platform, by doing 20 things before your Ip’s are reflexes of your infrastructure and based in Microservices. Modern JavaScript frameworks can create nice gently wizards even if you have supercold APIs.
Honestly, I didn’t realize my typo in the region and I connected to the Amazon Console to investigate and I saw this.

Honestly, when I read it I understood that they were going to end my EC2 Networking the 30th of October. It was 29th. I misunderstood.
It was my fault not reading it well to the end, I got shocked by the first part telling about shutdown and I didn’t fully understood as they were going to shutdown EC2-Classic for the zones I didn’t had anything running only.
From the long errors (3 exceptions chained) I didn’t realize that the endpoint is built with the region name. (And I was passing the availability zone)
botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL: "https://ec2.us-east-1a.amazonaws.com/"
Here is when I say that a good SDM would had thought and cared for the Developers more, and would had made the SDK to check if that region exists. How difficult is to create a SDK a bit more clever that detects a invalid region id?. It is not difficult.
It is true that it was late in the evening and I was tired of all the day, and two days of the week between work and zoom university classes I work 15 hours and 13 hours respectively, not counting the assignments, so by the end of the week I am very tired. But that’s why it is very important to follow methodology and to read well. I think Amazon has 50% of the fault by the way they do things: how the created the SDK, how they communicate, and by the errors that the console returned me when I tried to create a VPC instance of an EC2-Classic AMI (they seem related to the fact I had old VPC Network objects with shorter hash than the current they use) and the other 50% was my fault for not identifying the source of the error, and not reading the message in their website well.
But the fact that there were having those errors in the API’s and timeouts made me believe they were going to cut the EC2-Classic Networking the next day.
All the mistakes fall together in a perfect storm.
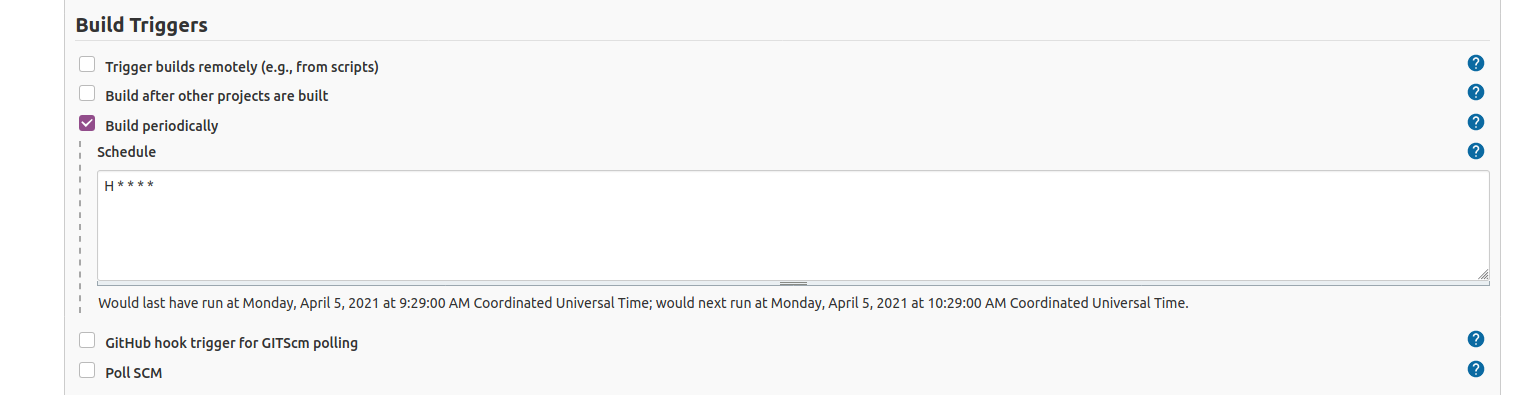
I checked for documentation and I saw it was possible to migrate my Static Ip’s to VPC Static Ip’s.

It was Friday evening, and I cancelled my plans, in order to migrate the Blog to VPC in an attempt to keep running it with Amazon.

As Cloud Architect, I like to have running instances in several CSP as it allows me to stay up to date with the changes they do.
I checked the documentation for the migration. Disassociating the Static Ip (Elastic Ip in AWS jargon) was easy. Turning into VPC as well.

As I progressed, what had to be easy turned into a nightmare, as I was getting many errors from the Amazon API, without any information, and my Instances were not created.
I figured out that their API could have problems with old VPC objects I created time ago, so I had to create new objects for several things.
I managed to spawn my instances but they were being launch and terminated instantly without information. Frustrating.
When launching a new instance from the AMI (a Snapshot of the blog), I was giving shown options to add more volumes without any sense. My Instance was using 16GB from a 20GB total Space, and I was shown different volume configs, depending on the instance, in some case an additional 20GB volume, in other small SSD, ephemeral and 10 GB for the AMI (which requires at least 16GB).
After some fight I manage to make it work after deleting the volumes that made no sense, and keeping only one of 20GB, the same size of my AMI.
But then my nightmare started to make the VPC Instance to have Internet access and to be seen from outside. I had to create a new Internet Gateway, NAT, Network, etc…
As mentioned the old objects I was trying to reusing were making the process to fail.
I was running out of time, and I thought in few time they were going to shutdown EC2-Classic network (as I did not read correctly), so I decided to download everything and to migrate to another provider. For doing that first I blocked all the traffic, except for my Ip.
I worked in parallel, creating the new config in Google Cloud, just in case I had forgot something. I had created a document for the migration and it was accurate.
I managed to do everything fast enough. The slower part was to download all the Data, as I hold entire VM’s for projects like Cassandra Universal Driver.
Then I powered off my Amazon Instance for the Blog forever.
In GCP I blocked all the traffic in the firewall, except for my Ip, so I could work calmly.
When everything was ready, I had to redirect the DNS to the new static Ip from Google.
The DNS provider I used had implemented some changes in their API so I was getting errors replacing my old entry ‘.’ (their JSON calls returned Internal Server Error). Finally I figured it out how to workaround it and I was able to confirm that the first service was up and running.
I did some tests to make sure there were not unexpected permission problems, entries in the logs, etc…
Only then I opened the Google Firewall. I have a second firewall in each instance where I block or open at Ip tables level what I want. Basically abusive bot’s IPs trying to find exploits or brute force by dictionary passwords.
I checked with my phone, without Wifi that the Firewall was all good. (It is always a good idea to use another external Ip, different from the management one, to check)
I added a post explaining that I was migrating some of my Services and were under maintenance.
I mentioned in the blog that some of my services were being migrated from Amazon to Digital Ocean.
For some reasons, in the Backup of the Database one user was lost, so I created it in the MySQL with the typical commands:
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password'; FLUSH PRIVILEGES; GRANT ALL PRIVILEGES ON mydatabase.* TO 'username'@'localhost';