I tried to continue following it since I left Sanmina. ZFS is really an amazing Software and it’s lead by an amazing Community of super cool Engineers and companies. I would like to continue contributing ASAP.
I bought some new hard drives in order to work a bit on this. You don’t need to have dedicated hardware if you want to test features. You can run in a VirtualBox or VMWare Workstation.
I received more books about DevOps and Python
None is perfect. I see flaws in all of them and bad architecture practices*, however from all I learn interesting things.
You know, I study every day. At least 30 minutes, after work. As part of my healthy routines.
But I also study and learn during the work, as we have time available for this.
I’m very fortunate that Blizzard gives me time every day to study. That’s amazing. They also send us to events paying the ticket, travel, hotel, expenses… now with covid-19 we only go to virtual events, but the company still pay for this and give free days. Is a very nice company.
I continue having purchases of my book, and I’m very happy about that. I’m working on improving it and providing more contents and samples going from the scratch, with step by step code samples. From spaghetti code reading CSV files, to OOP with Full Coverage.
My application for a Higher degree Computer Science Cloud Computing (Level 8) has been accepted. The Irish government pays me 90% of the degree, and Blizzard will pay me the other 10% after I pass the first year course.
I’m really grateful to this beautiful country, Ireland.
Having an Irish degree is something that brings me an special illusion.
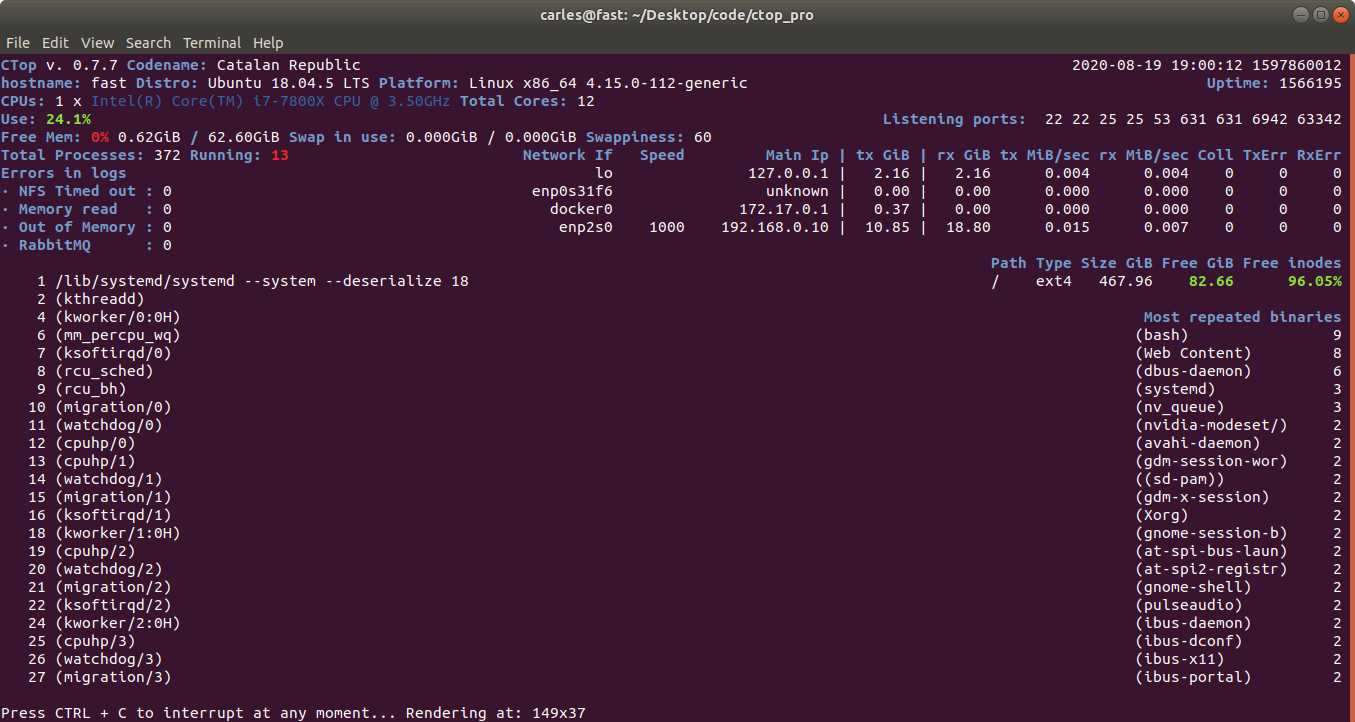
I have updated CTOP.py with some interesting features
It allows to pass a fixed width and height for the terminal render. That’s very useful when you run CTOP in a Docker non interactive session, or from a Cron, with the –iterations=1 so the output can be captured programmatically.
Jetbrains has provided me with a Free License of all their products, in order to support my work in Open Source projects. That’s very nice. I’m using now mainly PyCharm and PhpStorm.
At the beginning of the covid-19 I wrote a simulator in Python. That’s why I was able to anticipate that the number of cases and deaths would be very much higher when nobody around me knew what was going to happen. My first simulations were simple, and the algorithms were growing in complexity until I had a full rich Object Oriented modeler. Maybe I’ll write an article about this someday.
I studied the evolution of several countries and I was working with simulations in Spain until their government started blocking the information and stop providing transparent and accurate metrics.
I’m seeing how the covid is affecting and transforming several kind of business:
Meetup.com I see meetups with more than 1,000 users closing, as they are no meeting anymore
Airlines, obviously
Hotels, offering less services
Metasearchers and OTAs (Online travel agencies)
I can imagine the impact on airbnb
Discos, nightclubs are closing doors
Restaurants, they will lose the Christmas season (with families and companies doing lunch and dinners)
At the same time, other companies are hitting records in sales
Videogames companies
Hardware is being sold, to accommodate WFH and remote working.
Companies like Amazon or Overstock.com are delivering well where people before were buying into stores.
VPN solutions for Remote Working are being implemented in those places that had not enabled Remote Working.
After doing a Masterclass to some colleagues about Refactor, Code Reliability, Quality, The non-happy path and Unit Testing, I’m preparing some contents that I’ll publish to the Community soon. So far I created this repo, where I added the source code for lesson 0: starting to program in Python videos that I created few months ago to help beginners.
I also added some contents to lesson 1, where we refactor pure spaghetti code with no error control, to something more elaborated with unit testing and full code coverage. Still procedural, but I will jump to next class in two weeks, where we will move to OOP and Dependency Injection.
If you use ZFS with spinning drives and you share iSCSI, you will need to use a SLOG device for ZIL otherwise you’ll see your iSCSI connections interrupted.
What is a ZIL?
ZIL: Acronym for ZFS Intended Log. Logs synchronous operations to disk
SLOG: Acronym for (S)eperate (LOG) Device
In ZFS Data is first written and stored in-memory, then it’s flushed to drives. This can take 10 seconds normally, a bit more in certain occasions.
So without SLOG it can happen that if a power loss occurs, you may loss the last 10 seconds of Data submitted.
The SLOG device brings security that if there is a power loss, after remounting the pool, the information in the SLOG, acknowledged to iSCSI clients, is not lost and flushed to the Hard drives conforming the pool. Basically this device keeps the writings that come from network and flushes to the Hard drives and then clears this data from the SLOG.
The SLOG also allows ZFS to sort how the transactions will be written, to do in a more efficient way.
Normally I’m describing configurations with a fast device for SLOG ZIL, like one or a pair of NVMe drive or SAS SSD, most commonly in mirror a pool of 12 HDD drives or more SAS preferentially, maybe SATA, with 14TB or more each.
As the SLOG device will persist your Data if there is a power off, and submit to the pool the accepted transactions, it is clear that you cannot spare yourself from having a SLOG ZIL device (or better a mirror). It is needed to bring security when remotely writing.
But what happens if we have a kind of business where we don’t care about that the last 10 seconds writings may be lost? (ZFS will never get corrupted due to its kinda journal system), just because we are filling a Server the fastest possible, migrating from another, or because we are running workouts that can be retaken is some data is lost… do we really need to have the speed constrain of an SSD?. Examples are a Hadoop node, or a SETI@Home client. Tasks will be resumed if something failed.
Or maybe you fill your servers with sync=always, so writing it’s safe, and then you use them only for read, or for a Statics Internet Caches (CDNs like Akamai, Cloudfare…) or you use it for storing Backups, write once read many. You don’t really need the constraint speed of a ZIL running at 800 MB/s.
Let me put in another way, we have 2 NIC 100Gbps, in bonding, so 200Gbps (equivalent to (25GB/s Gigabytes per second), 90 HDD drives that can work in parallel up to 250 MB/s each (22.5GB/s) and our Server has a pair or SAS SSD ZIL in mirror, that writes at 900 MB/s (Megabytes per second, so 0.9 GB/s), so our bottleneck or constraint is the SLOG ZIL.
Adding one RAMDISK, or better two RAMDISKs in mirror, we can get to much more highers speeds. I cannot tell you how much, but in my tests with regular configurations (8D+3P) I was achieving more than 2 GB (Gigabytes) per second sustained of Data to the pool. Take in count that the speed writing to the pool does not only depend on the speed on the ZIL, and the speed of the HDD spinning drives (slow, between 100 and 250 MB/s), but also about the config of the pool (number of vdevs, distributions of data and parity drives) and the throughput of your IOC (Input Output Controller), and the number of them.
Live real scenarios use to be more in the line of having 2x10GbpE cards, combined in bonding making 20Gbps, so being able to transmit 2.5GB/s. So to get the max speed of our Network this Ramdrive will do it. Also NVMe devices used as ZIL will do it.
The problem with the NVMe is that they are connected to the PCI Express bus, and so they are not hot swap. If one dies, you cannot replace without stopping the Server.
The problem with the SSD is that they are not made for writing, they will die, so you need at least a mirror and for heavy IO I strongly recommend you to go with Enterprise grade SAS SSD drives. Those are made to last.
SSD Enterprise grade are double price versus one common SSD, but that peace of mind and extra lasting is worth it. And you don’t need a very big device, only has to hold 10 seconds of Data at max speed. So if you can ingest Data through the Network at 20 Gbps (2.5GB/s) you only need approximately 25 GB of space of the SLOG. 50 GB if you want to be more than safe.
Also you can use partitions instead of complete devices for the SLOG (like for the ZFS pool, where you can add complete drives, or partitions).
If you write locally, and you have 4 IOC’s capable of delivering 8 GB/s each, and you write to a Dataset to the pool, and not to a ZVOL which are slow by nature, you can get astonishing combined speed writing to the drives. If you are migrating a Server to another new, where you can resume if power goes down, then it’s safe to disable sync (set async) while this process runs, and turn sync on when going live to production. If you use async you don’t need to use a SLOG.
4 IOC’s able to deliver 8 GB/s are enough to provide sustained speed to 90 HDD SAS drives. 90x200MB/s=18GB/s required at max speed or 90x250MB/s=22.5GB/s.
The HDD drives provide different speeds in the inner and in the outer areas of the drive, so normally those drives up to 8TB perform between 100 and 200 MB/s, and the drives from 10TB SAS to 14TB SAS perform between 145 and 250 MB/s. I cannot tell about the 16 TB as I’ve not tested them.
The instructions to set a Ramdrive and to assign to a pool are like this:
#!/usr/bin/env bash
RAM_GB=1
RAM_DRIVE_SIZE_IN_BYTES=$((RAM_GB*1048576))
if [[ $(id -u) -ne 0 ]] ; then
echo "Please run as root"
exit 1
fi
modprobe brd rd_nr=1 rd_size=${RAM_DRIVE_SIZE_IN_BYTES} max_part=0
echo "Use it like: zpool add carlespool log ram0"
If you created more than one Ramdisk you can add a mirror for the slog to the pool with:
You can partition the Ramdrive and add a partition but we want to add the whole ram device.
Obviously you cannot put other things to that Ramdisk (like the Metadata) as you need persistence for that.
In any case, please, avoid JBODs loaded of big HDD drives with low bandwidth micro SATA like 3Gbps per channel to the Server, and RAID. The bandwidth is too low. Your rebuilds will take forever.
With ZFS you’ll resilver (rebuild) only the actual data, not the whole drive.
This new scenario challenges the old companies and is driving to some internal tensions in the companies that resist to allow employees to freely Remote Work.
I published this script to read the combined bandwidth, and peak max, from all drives.
I got new sales of my book in LeanPub and I’ve to say that this really makes me happy
I’ve been working in adding new information and I released a new update this week, the version 0.77. Talking about mutable and immutable objects when passing to a function, and references.
Bought new books and resumed my routines to study daily in the Coffee Shop (recently open)
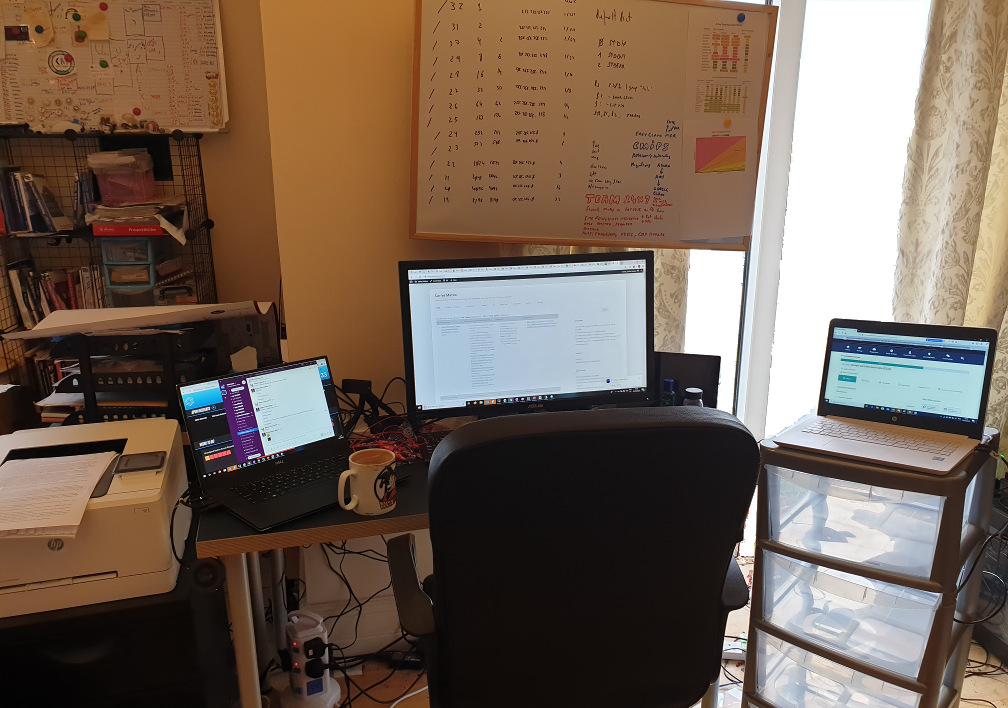
I bought some new hardware
An Arm to support the laptop and a Vesa Monitor. That’s my Desk, actually
It is exactly this model:
I bought also an HDMI switch with 3 inputs and PinP
The most cool feature is the PinP. Is a simple model with reduced but does what I wanted perfectly and cheap. Worth the price.
I bought also this Mic/headphone USB dondle with a single jack. Very cool
Does exactly what I wanted, adding a new device. I’m using on a Windows 10 Enterprise box.
I’ve bought a static bicycle for the WFH / lockdown covid-19.
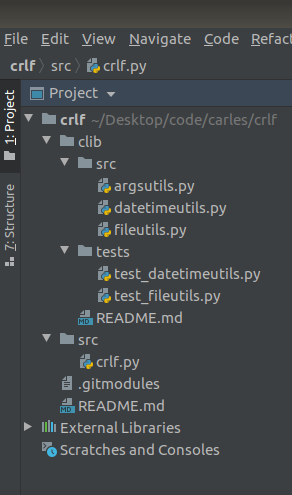
If you are using Git Submodules, is very probable that at some point you will create you own libraries. Probably those libraries will have their own structure, even with their own tests/ folder and you’re adding into a subfolder into your new project and maybe you have problems using relative imports.
This is a trick you can use to add the relevant root folder of your project to the System Path, so the libraries are found, specially when you call by command line from anywhere in the filesystem. This works for Python2 and Python3.
#!/usr/bin/env python3
import sys
import os
s_path_program = os.path.dirname(__file__)
sys.path.append(s_path_program + '../../')
from clib.src.argsutils import ArgsUtils
from clib.src.datetimeutils import DateTimeUtils
from clib.src.fileutils import FileUtils
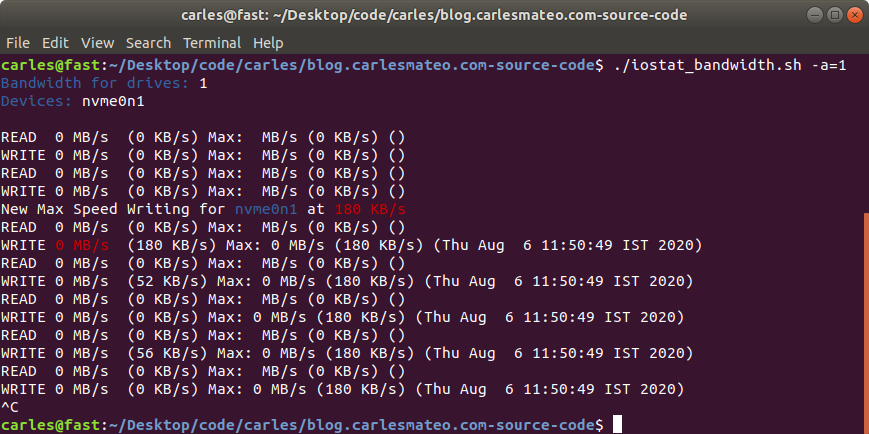
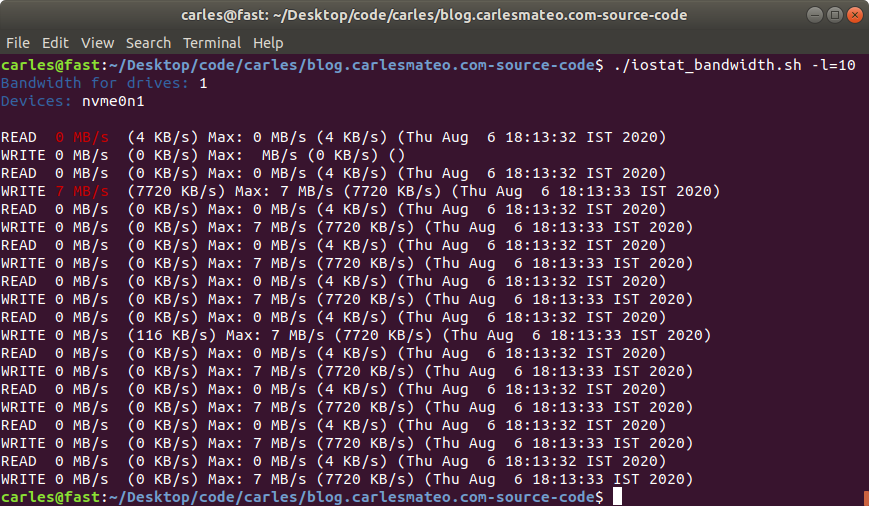
This is a shell script I made long time ago and I use it to monitor in real time what’s the total or individual bandwidth and maximum bandwidth achieved, for READ and WRITE, of Hard drives and NMVe devices.
It uses iostat to capture the metrics, and then processes the maximum values, the combined speed of all the drives… has also an interesting feature to let out the booting device. That’s very handy for Rack Servers where you boot from an SSD card or and SD, and you want to monitor the speed of the other (SAS probably) devices.
I used it to monitor the total bandwidth achieved by our 4U60 and 4U90 Servers, the All-Flash-Arrays 2U and the NVMe 1U units in Sanmina and the real throughput of IOC (Input Output Controllers).
I used also to compare what was the real data written to ZFS and mdraid RAID systems, and to disks and the combined speed with different pool configurations, as well as the efficiency of iSCSI and NFS from clients to the Servers.
You can specify how many times the information will be printed, whether you want to keep the max speed of each device per separate, and specify a drive to exclude. Normally it will be the boot drive.
If you want to test performance metrics you should make sure that other programs are not running or using the swap, to prevent bias. You should disable the boot drive if it doesn’t form part of your tests (like in the 4U60 with an SSD boot drive in a card, and 60 hard drive bays SAS or SATA).
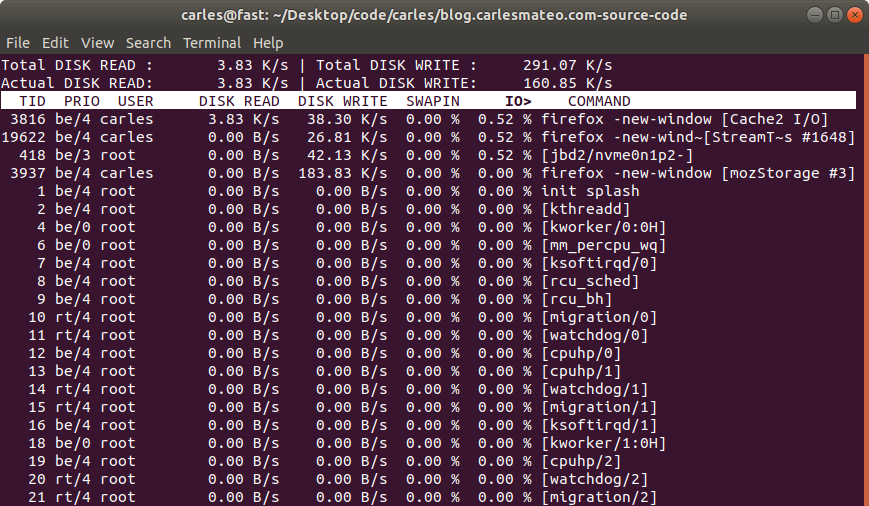
You may find useful tools like iotop.
You can find the code here, and in my gitlab repo:
#!/usr/bin/env bash
AUTHOR="Carles Mateo"
VERSION="1.4"
# Changelog
# 1.4
# Added support for NVMe drives
# 1.3
# Fixed Decimals in KB count that were causing errors
# 1.2
# Added new parameter to output per drive stats
# Counting is performed in KB
# Leave boot device empty if you want to add its activity to the results
# Specially thinking about booting SD card or SSD devices versus SAS drives bandwidth calculation.
# Otherwise use i.e.: s_BOOT_DEVICE="sdcv"
s_BOOT_DEVICE=""
# If this value is positive the loop will be kept n times
# If is negative ie: -1 it will loop forever
i_LOOP_TIMES=-1
# Display all drives separatedly
i_ALL_SEPARATEDLY=0
# Display in KB or MB
s_DISPLAY_UNIT="M"
# Init variables
i_READ_MAX=0
i_WRITE_MAX=0
s_READ_MAX_DATE=""
s_WRITE_MAX_DATE=""
i_IOSTAT_READ_KB=0
i_IOSTAT_WRITE_KB=0
# Internal variables
i_NUMBER_OF_DRIVES=0
s_LIST_OF_DRIVES=""
i_UNKNOWN_OPTION=0
# So if you run in screen you see colors :)
export TERM=xterm
# ANSI colors
s_COLOR_RED='\033[0;31m'
s_COLOR_BLUE='\033[0;34m'
s_COLOR_NONE='\033[0m'
for i in "$@"
do
case $i in
-b=*|--boot_device=*)
s_BOOT_DEVICE="${i#*=}"
shift # past argument=value
;;
-l=*|--loop_times=*)
i_LOOP_TIMES="${i#*=}"
shift # past argument=value
;;
-a=*|--all_separatedly=*)
i_ALL_SEPARATEDLY="${i#*=}"
shift # past argument=value
;;
*)
# unknown option
i_UNKNOWN_OPTION=1
;;
esac
done
if [[ "${i_UNKNOWN_OPTION}" -eq 1 ]]; then
echo -e "${s_COLOR_RED}Unknown option${s_COLOR_NONE}"
echo "Use: [-b|--boot_device=sda -l|--loop_times=-1 -a|--all-separatedly=1]"
exit 1
fi
if [ -z "${s_BOOT_DEVICE}" ]; then
i_NUMBER_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | wc --lines`
s_LIST_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | awk '{printf $1" ";}'`
else
echo -e "${s_COLOR_BLUE}Excluding Boot Device:${s_COLOR_NONE} ${s_BOOT_DEVICE}"
# Add an space after the name of the device to prevent something like booting with sda leaving out drives like sdaa sdab sdac...
i_NUMBER_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | grep -v "${s_BOOT_DEVICE} " | wc --lines`
s_LIST_OF_DRIVES=`iostat -d -m | grep "sd\|nvm" | grep -v "${s_BOOT_DEVICE} " | awk '{printf $1" ";}'`
fi
AR_DRIVES=(${s_LIST_OF_DRIVES})
i_COUNTER_LOOP=0
for s_DRIVE in ${AR_DRIVES};
do
AR_DRIVES_VALUES_AVG[i_COUNTER_LOOP]=0
AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]=0
AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]=0
i_COUNTER_LOOP=$((i_COUNTER_LOOP+1))
done
echo -e "${s_COLOR_BLUE}Bandwidth for drives:${s_COLOR_NONE} ${i_NUMBER_OF_DRIVES}"
echo -e "${s_COLOR_BLUE}Devices:${s_COLOR_NONE} ${s_LIST_OF_DRIVES}"
echo ""
while [ "${i_LOOP_TIMES}" -lt 0 ] || [ "${i_LOOP_TIMES}" -gt 0 ] ;
do
s_READ_PRE_COLOR=""
s_READ_POS_COLOR=""
s_WRITE_PRE_COLOR=""
s_WRITE_POS_COLOR=""
# In MB
# s_IOSTAT_OUTPUT_ALL_DRIVES=`iostat -d -m -y 1 1 | grep "sd\|nvm"`
# In KB
s_IOSTAT_OUTPUT_ALL_DRIVES=`iostat -d -y 1 1 | grep "sd\|nvm"`
if [ -z "${s_BOOT_DEVICE}" ]; then
s_IOSTAT_OUTPUT=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
else
# Add an space after the name of the device to prevent something like booting with sda leaving out drives like sdaa sdab sdac...
s_IOSTAT_OUTPUT=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | grep -v "${s_BOOT_DEVICE} " | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
fi
if [ "${i_ALL_SEPARATEDLY}" -eq 1 ]; then
i_COUNTER_LOOP=0
for s_DRIVE in ${AR_DRIVES};
do
s_IOSTAT_DRIVE=`printf "${s_IOSTAT_OUTPUT_ALL_DRIVES}" | grep $s_DRIVE | head --lines=1 | awk '{sum_read += $3} {sum_write += $4} END {printf sum_read"|"sum_write"\n"}'`
i_IOSTAT_READ_KB=`printf "%s" "${s_IOSTAT_DRIVE}" | awk -F '|' '{print $1;}'`
i_IOSTAT_WRITE_KB=`printf "%s" "${s_IOSTAT_DRIVE}" | awk -F '|' '{print $2;}'`
if [ "${i_IOSTAT_READ_KB%.*}" -gt ${AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]%.*} ]; then
AR_DRIVES_VALUES_READ_MAX[i_COUNTER_LOOP]=${i_IOSTAT_READ_KB}
echo -e "New Max Speed Reading for ${s_COLOR_BLUE}$s_DRIVE${s_COLOR_NONE} at ${s_COLOR_RED}${i_IOSTAT_READ_KB} KB/s${s_COLOR_NONE}"
echo
fi
if [ "${i_IOSTAT_WRITE_KB%.*}" -gt ${AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]%.*} ]; then
AR_DRIVES_VALUES_WRITE_MAX[i_COUNTER_LOOP]=${i_IOSTAT_WRITE_KB}
echo -e "New Max Speed Writing for ${s_COLOR_BLUE}$s_DRIVE${s_COLOR_NONE} at ${s_COLOR_RED}${i_IOSTAT_WRITE_KB} KB/s${s_COLOR_NONE}"
fi
i_COUNTER_LOOP=$((i_COUNTER_LOOP+1))
done
fi
i_IOSTAT_READ_KB=`printf "%s" "${s_IOSTAT_OUTPUT}" | awk -F '|' '{print $1;}'`
i_IOSTAT_WRITE_KB=`printf "%s" "${s_IOSTAT_OUTPUT}" | awk -F '|' '{print $2;}'`
# CAST to Integer
if [ "${i_IOSTAT_READ_KB%.*}" -gt ${i_READ_MAX%.*} ]; then
i_READ_MAX=${i_IOSTAT_READ_KB%.*}
s_READ_PRE_COLOR="${s_COLOR_RED}"
s_READ_POS_COLOR="${s_COLOR_NONE}"
s_READ_MAX_DATE=`date`
i_READ_MAX_MB=$((i_READ_MAX/1024))
fi
# CAST to Integer
if [ "${i_IOSTAT_WRITE_KB%.*}" -gt ${i_WRITE_MAX%.*} ]; then
i_WRITE_MAX=${i_IOSTAT_WRITE_KB%.*}
s_WRITE_PRE_COLOR="${s_COLOR_RED}"
s_WRITE_POS_COLOR="${s_COLOR_NONE}"
s_WRITE_MAX_DATE=`date`
i_WRITE_MAX_MB=$((i_WRITE_MAX/1024))
fi
if [ "${s_DISPLAY_UNIT}" == "M" ]; then
# Get MB
i_IOSTAT_READ_UNIT=${i_IOSTAT_READ_KB%.*}
i_IOSTAT_WRITE_UNIT=${i_IOSTAT_WRITE_KB%.*}
i_IOSTAT_READ_UNIT=$((i_IOSTAT_READ_UNIT/1024))
i_IOSTAT_WRITE_UNIT=$((i_IOSTAT_WRITE_UNIT/1024))
fi
# When a MAX is detected it will be displayed in RED
echo -e "READ ${s_READ_PRE_COLOR}${i_IOSTAT_READ_UNIT} MB/s ${s_READ_POS_COLOR} (${i_IOSTAT_READ_KB} KB/s) Max: ${i_READ_MAX_MB} MB/s (${i_READ_MAX} KB/s) (${s_READ_MAX_DATE})"
echo -e "WRITE ${s_WRITE_PRE_COLOR}${i_IOSTAT_WRITE_UNIT} MB/s ${s_WRITE_POS_COLOR} (${i_IOSTAT_WRITE_KB} KB/s) Max: ${i_WRITE_MAX_MB} MB/s (${i_WRITE_MAX} KB/s) (${s_WRITE_MAX_DATE})"
if [ "$i_LOOP_TIMES" -gt 0 ]; then
i_LOOP_TIMES=$((i_LOOP_TIMES-1))
fi
done
I wanted to automate certain operations that we do very often, and so I decided to do a PoC of how handy will it be to create GUI applications that can automate tasks.
As locating information in several repositories of information (ldap, databases, websites, etc…) can be tedious I decided to create a small program that queries LDAP for the information I’m interested, in this case a Location. This small program can very easily escalated to launch the VPN, to query a Database after querying LDAP if no results are found, etc…
I share with you the basic application as you may find interesting to create GUI applications in Python, compatible with Windows, Linux and Mac.
I’m super Linux fan but this is important, as many multinationals still use Windows or Mac even for Engineers and SRE positions.
With the article I provide a Dockerfile and a docker-compose.yml file that will launch an OpenLDAP Docker Container preloaded with very basic information and a PHPLDAPMIN Container.
This article is more an exercise, like a game, so you get to know certain things about Linux, and follow my mental process to uncover this. Is nothing mysterious for the Senior Engineers but Junior Sys Admins may enjoy this reading. :)
Ok, so the first thing is I wrote an script in order to completely backup my NVMe hard drive to a gziped file and then I will use this, as a motivation to go deep into investigations to understand.
So basically, we are going to restart the computer, boot with Linux Live USB Key, mount the Seagate Hard Drive, and run the script.
We are booting with a Live Linux Cd in order to have our partition unmounted and unmodified while we do the backup. This is in order to avoid corruption or data loss as a live Filesystem is getting modifications as we read it.
The problem with this first script is that it will generate a big gzip file.
By big I mean much more bigger than 2GB. Not all physical supports support files bigger than 2GB or 4GB, but even if they do, it’s a pain to transfer this over the Network, or in USB files, so we are going to do a slight modification.
Then one may ask himself, wait, if pipes use STDOUT and STDIN and dd is displaying into the screen, then will our gz file get corrupted?.
I like when people question things, and investigate, so let’s answer this question.
If it was a young member of my Team I would ask:
Ok, try,it. Check the output file to see if is corrupted.
So they can do zcat or zless to inspect the file, see if it has errors, and to make sure:
gzip -v -t nvme.img.gz
nvme.img.gz: OK
Ok, so what happened?, because we were seeing output in the screen.
Assuming the young Engineer does not know the answer I would had told:
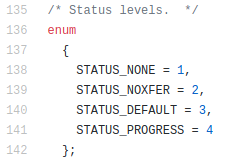
Ok, so you know that if dd would print to STDOUT, then you won’t see it, cause it would be sent to the pipe, so there is something more you’re missing. Let’s check the source code of dd to see what status=progress does
And then look for “progress”.
Soon you’ll find things like everywhere:
if (progress_time)
fputc ('\r', stderr);
Ok, pay attention to where is the data written: stderr. So basically the answer is: dd status=progress does not corrupt STDOUT and prints into the screen because it uses STDERR.
Other funny ways to get the progress would be to use:
So you would see in real time what was the advance and finally 512GB where compressed to around 336GB in 336 files of 1 GB each (except the last one)
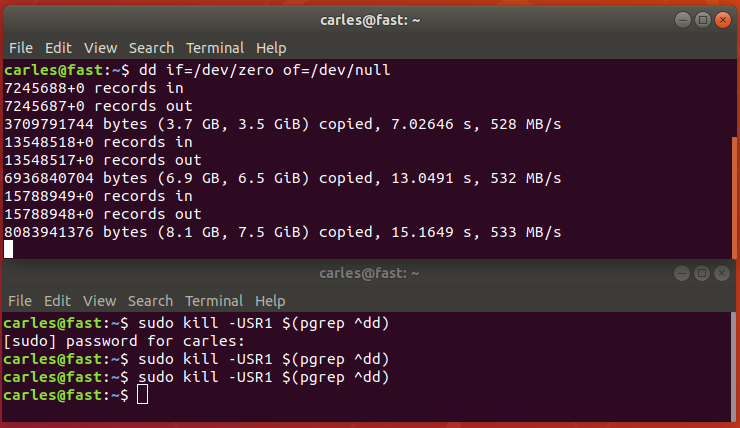
Another funny way would had been sending USR1 signal to the dd process:
Hope you enjoyed this little exercise about the importance of going deep, to the end, to understand what’s going on on the system. :)
Instead of gzip you can use bzip2 or pixz. pixz is very handy if you want to just compress a file, as it uses multiple processors in parallel for the tasks.
xz or lrzip are other compressors. lrzip aims to compress very large files, specially source code.
I wrote this article at the beginning of the lock-down during the pandemic in 2020, to help others to adapt healthy.
My table at the officeMy first WFH setup
Those are crazy times in which is difficult to handle working from home, doing the lock down…
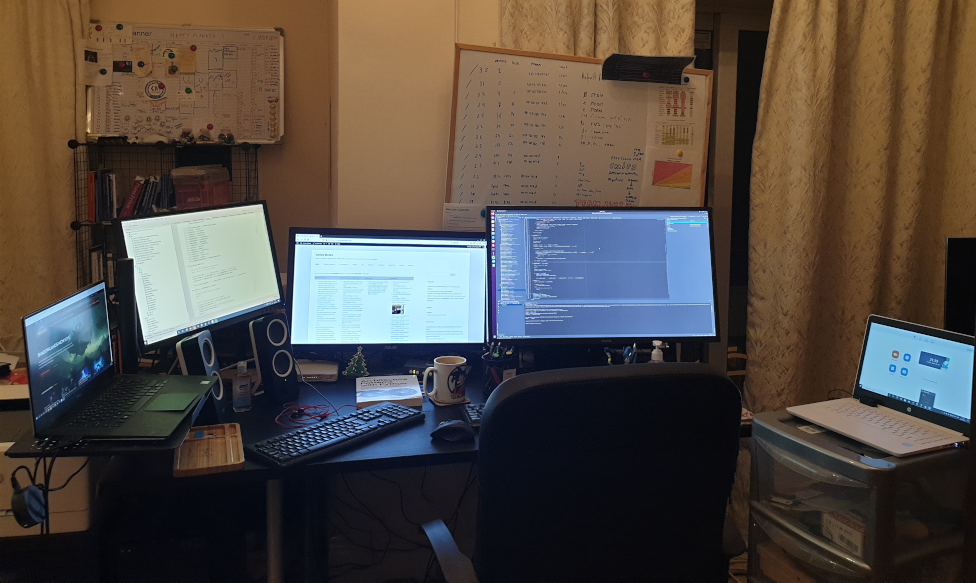
Evolved a bit my setupThis is better
But very nice times in which other people help others. Doctors and sanitary personnel fight in first line, truck drivers and supermarket staff are doing extra hours to provide to the society, investigators are working hard to get a vaccine…
Is beautiful that so many people are helping and contributing to the society.
I want to provide my humble experience on working remotely, from many years working remotely, so you avoid going bananas. Is very easy get depressed, anxious… So here is my advice.
Stick to a routine Respect the working times, like if you was going to the office. Dress yourself like a normal day in the office. Don’t be all day in pajamas or sport wear. Switch to sports wear when you finish your daily work at 6PM, if you want, but not before. If you talk via Slack, myself always keep the video turned on, as is a way to force myself into dressing and taking care of my look. I take a shower, dress like an Engineer at work, I have my break for breakfast and for lunch, and when I finish work I study 30 minutes and do exercise 30 minutes or more. Then I take another shower and I consider myself free. Note: The only exception I do to the dressing is in the shoes. I don’t wear any shoes, as my feet really enjoy walking freely over the parket.
Take care of yourself Shave, cut your nails… be polite. The same way you would if you had to go to the office.
Stick to the working clock As said in the stick to a routine advice, work your time, from 9AM to 6PM, and don’t get lost. The week ends are week ends, don’t work to free your mind. For the week ends I have my side projects, like writing books.
Walk If you can, walk an enjoy nature as much as you can. This clears the mind and keeps your mental health wellness.
Do exercise May be walking, but if you have a home bicycle, use it. Try to set a goal, like 15 minutes of bicycle daily, and grow from there, of keep it like that. But doing even 15 minutes of cardio every day will be highly beneficial for your mind and body. You may find it easy to do if you play videogames while cycling, or watch Netflix.
Stretch After doing exercise stretch your muscles.
See the light As much as you can, see the sun light. Try to do walks too and see nature. Daylight and nature are amazingly good for your mental health and morale.
Study/Learn new things I keep this as part of my routine. I study every day in Linux Academy or read a book at least half an hour. I’ve done this for years.
Keep you hydrated Drink lots of water. I said water, not sugar drinks or carbonated ones, which are very unhealthy.
Do your breaks After each 1 hour of work try to walk a bit in the house, to focus your view in distant points to relax your ocular muscles.
Ergonomics and light Try to have a correct light in the working are, a comfortable chair, the right height for the keyboard and for the monitor, so your neck doesn’t hurt and your hands neither.
Do like in the office: discipline In the office you don’t drink, you don’t smoke at your desk. So do the same. If you want to smoke one cigar after 2 hours of work, Ok, but don’t loss yourself in self-indulgence. Set strict rules respect alcohol if you love beer: No alcohol during working hours. Years ago I was CTO of a company with Team in half the world and I had a Team in Belarus. The Team Lead would be drunk in the sofa at business hours and start talking common words. If you have weak points, you don’t want to lose yourself. Be disciplined.
Set boundaries with your family and pets If you want to close the door of the room you work, your cat is not gonna die. It is used to be alone when you’re are in the office. So if it’s excessively demanding and wants you to pet him, or jumps over your laptop’s keyword while you are typing commands as root, set boundaries. Close the door. He can take it. Also for the kids, the wife, the mother. Please, do not disturb me while I’m working. We will play after.
During covid-19 lockdown, do videoconference Do videoconference with your family and friends. You can use Slack, Skype, Zoom, Whatsapp, Facebook Messenger… I schedule a daily whatsapp video conf with my family, and a weekly with my cool friend Alex :)
Socialize. When the lockdown is over, try as much to socialize, or at least to see friendly faces irl. If you can’t because you’re an expat, go to the coffee and to the commercial center to see faces, for the sake of your mental health. If the law and common sense allow it, try to go to a gym to get back to be fit and healthy.
Despite your beliefs about vaccines, take fruits, and vegetables. You are certainly exiting less home, so your intake of sun is also reduced. Myself I take vitamin supplements.
Be very patient with your colleagues and Team members We are all humans and each one has its own situation. Some people may feel depressed, alone, others may have problems with the partners or the parents of her/him living with them. Other may have a cat trolling all the time stopping the work. Others may have hyperactive children, or just having a poor chair, poor desk, and having only the laptop and no external monitor. Others may have the family far, in another country, and suffer for them. Be patient and understanding. Be Human.
Have a good Internet connection and use Ethernet cable, not Wifi if possible I have 360 Mbit at home with Virgin and I connect the laptops with Ethernet Gigabit cables. That brings me the best and most stable connection. In case of emergency I can do tethering with the phone (share the connection using the phone as Wifi Hotspot)
Use cable headsets, not Bluetooth if possible, and use the microphone from the headset not the one from the laptop The Bluetooth can be very useful to allow you to move around during audio calls, but some times they provide a poor signal and the sound is lost or may sound metallic or they perform poorly when they have few battery, or they can let you down. Using the microphone embedded in the laptop sends echo to your partners, many times. If you don’t use headphones the sound coming from the speakers can couple with the microphone and make it very uncomfortable to your partners talking in a video conference, as they will hear themselves with echo. If you use Bluetooth, I recommend to have cable headsets at least as backup in case the Bluetooth runs out of battery.
Use a camera with cover or add a plastic cover that slides to your webcam. It is good to have a physical barrier to prevent your camera turning on and you not knowing, and to get used to block the camera after you used.
Have spare Hardware and cables In this time of lockdown, is good to have spare cables and adapters for everything. Just in case they die. If you can have a spare monitor, and spare laptops this is great too. I have 3 laptops, plus one tower, plus several raspberry pis, plus the tablet, plus my working laptop. If one dies, I can use the others. I always have all kind of Hardware and cables as spare (Gigabit switches, power adapters, international adapters, Ethernet cables, USB cables, headphones…). Even if I can buy in Amazon nothing can stop me. One day we had an incident with Virgin, which affected all Ireland. I was out as the Fiber was not working and the phone was with Virgin too, but I have two additional SIM cards and spare phones, from vodaphone and Tesco mobile. So I’m well protected. :) As per the comment of Jordi Soler, I update the list of gadgets, mentioning my Hp Laserjet Color Printer, very handy to print document that I have to sign and then scan and sending back by email, and the UPS. The UPS is cool, as if electricity goes down I don’t loss Fiber Internet. Imagine, a router connected to the UPS can last hours! however is very infrequent that in Ireland we loss electricity. And the issues I experienced in 3 years were quickly resolved (unlike Barcelona where once more than 300,000 people were 3 days without electricity).
Keep doing backups If talking about job things, you can upload to Corporate Google Drive or Microsoft One Drive.
Do exercise regularly I bought a static bicycle and a pair of weights, nintendo boxing games, so I keep fit. Sitting all the day and not doing any exercise in not made for humans and is bad for your health.
Play videogames Playing videogames can keep your amused and distracted, with a goal you do to relax.
Have fun. Play Quizz style games online, with your friends/university/work mates Playing Questions/Answers games with other people can be a great source of fun. Recently I played with my friends at work at jackbox.tv , coordinating through Zoom, and it was really fun. I also play in the Quizz that was being performed at my local pub every week, and when the lockdown closed the pubs, they moved to Internet. It is great to see some of the people I was seeing at the pub, and revive these moment, even from home, virtually.
Check your health Take that blood analysis, the breast yearly revision, or whatever test you should do regularly. Performing a blood analysis is particularly a good idea. Most people got weight with the lockdown, and the lack of activity can have had an adverse effect in your health. I recommend you to take a blood analysis to make sure all is good with your health. Deciding to take a proactive blood analysis saved my life.
It is a good moment to go to the university Pick your dream’s degree, that you can do remotely, and before you can realize you’ll have your degree and a bunch of nice good friends. :) Specially if you are older than 40/45 years, many universities will grant you access with your motivation letter. I recommend you evening degrees designed for people that work. They will be helpful and understanding, flexible, and provide workloads more reasonable for people with families and work. Also some countries subsidize certain degrees, for example in IT, as they want workers to be digital capable.
My friend Nico C. de F. provided a super useful tip: When in a call say only nice things (if you talk to another person, if you pick the phone…) always assume you’re not muted. And that’s super true! How many times we have heard or seen something that the other person regretted sharing. Even if you muted your Zoom call, it could happen that it gets unmuted (like pressing ALT A).
Keep liquids far from your hardware It is very easy to poor a cup or glass full of liquid over your laptop or keyboard
Security risks
One of the problems with the laptops and battery-power devices in general is that if we have them connected to the energy line all the time, never using the battery, the battery just loses effectiveness and dies.
But some batteries can also explode.
As we are working all day at home now, our laptops are connected 100% of the time.
In my case one of the equipment I use is a Dell Laptop and the battery started to swallow and to bring the touchpad up. As the temperature of the laptop internally increased by the battery being hot as it swallows, you may notice the internal fan doing extra hours, running almost all the time, a high temperature on the chassis. High temperatures can lead to laptop malfunction like hang or reboot.
In extreme cases the battery can explode, so you should replace it if it is swallowing.
So I recommend you from time to time to unplug the power cable and run the laptop on battery until it almost completely depletes, or at leas for a couple hours before plugging the power cable again.
In another order of things I recommend you not to do drugs. Drugs affect your brain, and is hard enough to be isolated in lock down, to add chemicals messing with your neurons.
This is a trick to restart a Service that is running on a immutable Docker, with some change, and you need to refresh the values very quickly without having to roll the CI/CD Jenkins Pipeline and uploading a new image.
So why would you need to do that?.
I can think about possible scenarios like:
Need to roll out an urgent fix in a time critical manner
Jenkins is broken
Somebody screw it on the git master branch
Docker Hub is down
GitHub is down
Your artifactory is down
The lines between your jumpbox or workstation and the secure Server are down and you have really few bandwidth
You have to fix something critical and you only have a phone with you and SSH only
Maybe the Dockerfile had latest, and the latest image has changed
FROM os:latest
The ideal is that if you work with immutable images, you roll out a new immutable image and that’s it.
But if for whatever reason you need to update this super fast, this trick may become really handy.
Let’s go for it!.
Normally you’ll start your container with a command similar to this:
docker run -d --rm -p 5000:5000 api_carlesmateo_com:v7 prod
The first thing we have to do is to stop the container.
So:
docker ps
Locate your container across the list of running containers and stop it, and then restart without the –rm:
docker stop container_name
docker run -d -p 5000:5000 api_carlesmateo_com:v7 prod
the –rm makes the container to cleanup. By default a container’s file system persists even after the container exits. So don’t start it with –rm.
Ok, so login to the container:
docker exec -it container_name /bin/sh
Edit the config you require to change, for example config.yml
If what you have to update is a password, and is encoded in base64, encode it:
echo -n "ThePassword" | base64
VGhlUGFzc3dvcmQ=
Stop the container. You can do it by stopping the container with docker stop or from inside the container, killing the listening process, probably a Python Flask.
If your Dockerfile ends with something like:
ENTRYPOINT ["./webservice.py"]
And webservice.py has Python Flask code similar to this:
#!/usr/bin/python3
#
# webservice.py
#
# Author: Carles Mateo
# Creation Date: 2020-05-10 20:50 GMT+1
# Description: A simple Flask Web Application
# Part of the samples of https://leanpub.com/pythoncombatguide
# More source code for the book at https://gitlab.com/carles.mateo/python_combat_guide
#
from flask import Flask, request
import logging
# Initialize Flask
app = Flask(__name__)
# Sample route so http://127.0.0.1/carles
@app.route('/carles', methods=['GET'])
def carles():
logging.critical("A connection was established")
return "200"
logging.info("Initialized...")
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000, debug=True)
Then you can kill the process, and so ending the container, from inside the container by doing:
This will finish the container the same way as docker stop container_name.
Then start the container (not run)
docker start container_name
You can now test from outside or from inside the container. If from inside:
/opt/webservice # wget localhost:5000/carles
Connecting to localhost:5000 (127.0.0.1:5000)
carles 100% |**************************************************************************************************************| 3 0:00:00 ETA
/opt/webservice # cat debug.log
2020-05-06 20:46:24,349 Initialized...
2020-05-06 20:46:24,359 * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
2020-05-06 20:46:24,360 * Restarting with stat
2020-05-06 20:46:24,764 Initialized...
2020-05-06 20:46:24,771 * Debugger is active!
2020-05-06 20:46:24,772 * Debugger PIN: 123-456-789
2020-05-07 13:18:43,890 127.0.0.1 - - [07/May/2020 13:18:43] "GET /carles HTTP/1.1" 200 -
if you don’t use YAML files or what you need is to change the code, all this can be avoided as when you update the Python code, Flash realizes that and reloads. See this line in the logs:
2020-05-07 13:18:40,431 * Detected change in '/opt/webservice/wwebservice.py', reloading
The webservice.py autoreloads because we init Flask with debug set to on.
You can also start a container with shell directly: