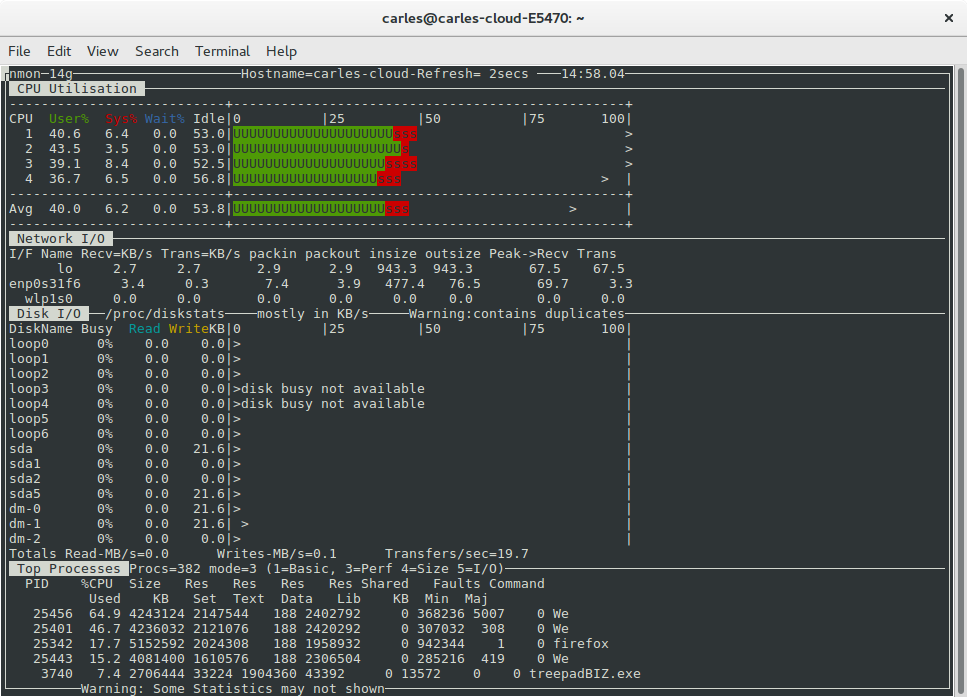
This is the history it happen to me some time ago, and so the commands I used to troubleshot. The purpose is to share knowledge in a interactive way. There are some hidden gems that you’ll acquire if you have the patience to go over all the document and read it all…
I had qualified Intel Xeon single processor platform to run my DRAID (ZFS Declustered RAID) project for my employer.
The platforms I qualified were:
1) single processor for Cold Storage (SAS Spinning drives): 4U60, newest models 4602
2) for multiprocessor: the 4U90 (90 Spinning drives) and Flash: All-Flash-Arrays.
The amounts of RAM I was using for my tests range for 64GB to 384GB.
Somebody in the company, at executive level, assembled an experimental config that was totally new for us and wanted to try by their own. It was the 4602 with multiprocessor and 32GB of RAM.
When they were unable to make it work at the expected speed, they required me to troubleshot and to make it work.
The 4602 single processor had two IOC (Input Output Controller, LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ), while the 4602 double processor had four IOC, so given that each of those IOC can perform at peaks of 6GB/s, with a maximum total of 24 GB/s, the performance when reading/writing from all the drives should be better.
But this Server was returning double times for Rebuilding, respect the single processor version, which didn’t make any sense.
I had to check everything. There was the commands I ran:
Check the upgrade of the CPU:
htop
lscpu
Changing the Zoning.
Those Servers use SAS drives dual ported, which means that two different computers can be connected to the same drive and operate at the same time. Is up to you to make sure you don’t introduce corruption. Those systems are used mainly for HA (High Availability).
Those Systems allow to be configured in different zoning modes. That’s the way on how each of the two servers (Controllers) see the disk. In one zoning each Controller sees only 30 drives, in another each IOC sees all the drives (for redundancy but performance constrained to 1 IOC Speed).
The config I set is each IOC will see 15 drives, so each one of the 4 IOC will have 6GB/s for 15 drives. Given that these spinning drives perform in the outtermost part of the cylinder at 265MB/s, that means that at maximum speed one IOC will be using 3.97 GB/s, will say 4GB/s. Plenty of bandwidth.
Note: Spinning drives have different performance depending on how close you’re to the cylinder. In the innermost part it goes under 145 MB/s, and if you read all of those drive sequentially with dd it will return an average speed of 145 MB/s.
With this command you can sive live how it performs and the average read speed in real time. Use skip to jump to that position (relative to bs) in the drive, so you can test directly the speed at the innermost close to the cylinder part of t.
dd if=/dev/sda of=/dev/null bs=1M status=progress
I saw that the zoning was not right one, so I set it correctly:
[root@4602Carles ~]# sg_map -i | grep NEWISYS /dev/sg30 NEWISYS NDS-4602-CS 0112 /dev/sg61 NEWISYS NDS-4602-CS 0112 /dev/sg63 NEWISYS NDS-4602-CS 0112 /dev/sg64 NEWISYS NDS-4602-CS 0112 [root@4602Carles10 ~]# sg_senddiag /dev/sg30 --pf --raw=04,00,00,01,53 [root@4602Carles10 ~]# sleep 50 [root@4602Carles10 ~]# sg_senddiag /dev/sg30 --pf -r 04,00,00,01,43 [root@4602Carles10 ~]# sleep 50 [root@4602Carles10 ~]# reboot
The sleeps after rebooting the expanders are recommended. Rebooting the Operating System too, to avoid problems with some Software as the expanders changed live.
If you have ZFS pools or workloads stop them and export the pool before messing with the expanders.
In order to check to which drives is connected each IOC:
[root@4602Carles10 ~]# sg_map -i -x /dev/sg0 0 0 0 0 0 /dev/sda TOSHIBA MG07SCA14TA 0101 /dev/sg1 0 0 1 0 0 /dev/sdb TOSHIBA MG07SCA14TA 0101 /dev/sg2 0 0 2 0 0 /dev/sdc TOSHIBA MG07SCA14TA 0101 /dev/sg3 0 0 3 0 0 /dev/sdd TOSHIBA MG07SCA14TA 0101 /dev/sg4 0 0 4 0 0 /dev/sde TOSHIBA MG07SCA14TA 0101 /dev/sg5 0 0 5 0 0 /dev/sdf TOSHIBA MG07SCA14TA 0101 /dev/sg6 0 0 6 0 0 /dev/sdg TOSHIBA MG07SCA14TA 0101 /dev/sg7 0 0 7 0 0 /dev/sdh TOSHIBA MG07SCA14TA 0101 /dev/sg8 1 0 8 0 0 /dev/sdi TOSHIBA MG07SCA14TA 0101 /dev/sg9 1 0 9 0 0 /dev/sdj TOSHIBA MG07SCA14TA 0101 /dev/sg10 1 0 10 0 0 /dev/sdk TOSHIBA MG07SCA14TA 0101 /dev/sg11 1 0 11 0 0 /dev/sdl TOSHIBA MG07SCA14TA 0101 [...] /dev/sg16 4 0 16 0 0 /dev/sdq TOSHIBA MG07SCA14TA 0101 /dev/sg17 4 0 17 0 0 /dev/sdr TOSHIBA MG07SCA14TA 0101 [...] /dev/sg30 0 0 30 0 13 NEWISYS NDS-4602-CS 0112 [...]
Still after setting the right zone the Rebuilds were slow, the scan rate half of the obtained with a single processor.
I tested that the system was able to provide the expected performance by reading from all the drives at the same time. This is done with:
dd if=/dev/sda of=/dev/null bs=1M status=progress & dd if=/dev/sdb of=/dev/null bs=1M status=progress & dd if=/dev/sdc of=/dev/null bs=1M status=progress & dd if=/dev/sdd of=/dev/null bs=1M status=progress & [...]
I do this for all the drives at the same time and with iostat:
iostat -y 1 1
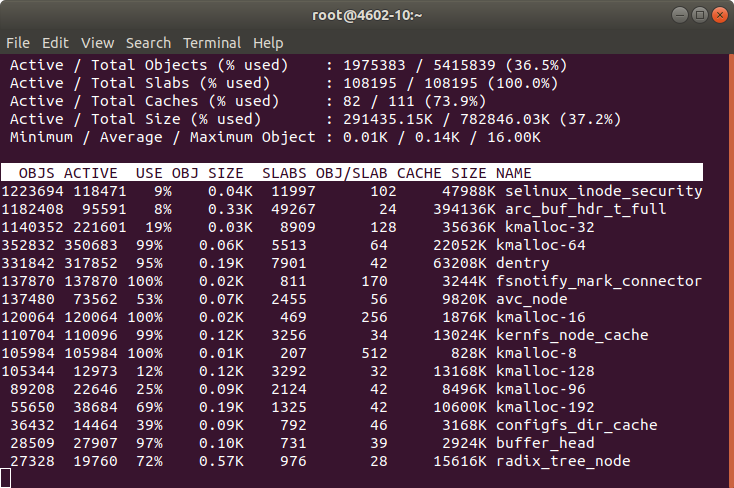
I check the status of the memory with:
slabtop free htop
I checked the memory and htop during a Rebuild. Memory was more than enough. However CPU usage was higher than expected.

I capture all the parameters from ZFS with:
zfs get all
All this information is logged into my forensics document, so later can be checked by my Team or I can share with other Architects or other members of the company. I started this methodology after I knew how Google do their SRE forensics / postmortem documents. Also for myself is useful for the future to have a log of the commands I executed and a verbose output of the results.
I install the smp_utils
yum install smp_utils
Check things:
ls -al /dev/bsg/ total 0drwxr-xr-x. 2 root root 3020 May 22 10:16 . drwxr-xr-x. 20 root root 8680 May 22 10:16 .. crw-------. 1 root root 248, 76 May 22 10:00 1:0:0:0 crw-------. 1 root root 248, 126 May 22 10:00 10:0:0:0 crw-------. 1 root root 248, 127 May 22 10:00 10:0:1:0 crw-------. 1 root root 248, 136 May 22 10:00 10:0:10:0 crw-------. 1 root root 248, 137 May 22 10:00 10:0:11:0 crw-------. 1 root root 248, 138 May 22 10:00 10:0:12:0 crw-------. 1 root root 248, 139 May 22 10:00 10:0:13:0 [...]
[root@4602Carles10 ~]# smp_discover /dev/bsg/expander-1:0 [...] [root@4602Carles10 ~]# smp_discover /dev/bsg/expander-1:1
I check for errors in the expander that could justify the problems of performance:
for i in `seq 0 64`; do smp_rep_phy_err_log -p $i /dev/bsg/expander-1\:0 ; done Report phy error log response: Expander change count: 567 phy identifier: 0 invalid dword count: 0 running disparity error count: 0 loss of dword synchronization count: 0 phy reset problem count: 0 [...] Report phy error log response: Expander change count: 567 phy identifier: 52 invalid dword count: 168 running disparity error count: 172 loss of dword synchronization count: 5 phy reset problem count: 0 Report phy error log response: Expander change count: 567 phy identifier: 53 invalid dword count: 6 running disparity error count: 6 loss of dword synchronization count: 0 phy reset problem count: 0 Report phy error log response: Expander change count: 567 phy identifier: 54 invalid dword count: 267 running disparity error count: 270 loss of dword synchronization count: 4 phy reset problem count: 0 Report phy error log response: Expander change count: 567 phy identifier: 55 invalid dword count: 127 running disparity error count: 131 loss of dword synchronization count: 5 phy reset problem count: 0 Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant Report phy error log result: Phy vacant
There are some errors, and I check with the Hardware Team, which pass a battery of tests on the machine and say that the machine passes. They tell me that if the errors counted were in order of millions then it would be a problem, but having few of them is usual.
My colleagues previously reported that the memory was performing well, and the CPU too. They told me that the speed was exactly double respect a platform with one single CPU of the same kind.
Even if they told me that, I ran cmips tests to make sure.
git clone https://github.com/cmips/cmips_bin
It scored 16,000. The performance was Ok in general terms but the problem is that I didn’t have a baseline for that processor in single processor, so I cannot make sure that the memory bandwidth was Ok. The performance was less that an Amazon c3.8xlarge. The system I was testing is a two processor system, but each CPU is cheap, around USD $400.
Still my gut feeling was telling me that this double processor server should score more.
lscpu
[root@DRAID-1135-14TB-2CPU ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 32 On-line CPU(s) list: 0-31 Thread(s) per core: 2 Core(s) per socket: 8 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 79 Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz Stepping: 1 CPU MHz: 2299.951 CPU max MHz: 3000.0000 CPU min MHz: 1200.0000 BogoMIPS: 4199.73 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 20480K NUMA node0 CPU(s): 0-7,16-23 NUMA node1 CPU(s): 8-15,24-31 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts spec_ctrl intel_stibp
I check the memory configuration with:
dmidecode -t memory
I examined the results, I see that the processor can only operate the DDR4 ECC 2400 Memory at 2133 and… I see something!. This Controller before was a single processor with 2 Memory Sticks of 16GB each, dual rank.
I see that now I have the same number of sticks in that machine, but I have two CPU!. So 2 Memory sticks in total, for 2 CPU.
That’s no good. The memory must be in pairs and in the right slots to get the maximum performance.
1 memory module for 1 CPU doesn’t allow to have Dual Channel and probably is affecting the performance. Many Servers will not even boot if you add an odd number of memory sticks per CPU.
And many Servers can operate at full speed only if all the banks are filled.
I request to the Engineers in Silicon Valley to add 4 modules in the right slots. They did, and I repeated the tests and the performance was doubled then.
After some days I had some time with the machine, I repeated the test and I got a CMIPS Score of around 20,000.
Multiprocessor world is far more complicated than single processor. Some times things can work not as expected, and not be evident, for example cache pipeline can act diferent for a program working in multiprocessor and single processor. Or the QPI could be saturated.
After this I shared my forensics document with as many Engineers as I could, so they could learn how I did to troubleshot the problem, and what was the origin of it, and I asked them to do the same so we can track their steps and progress if something needs to be troubleshoot.
After proper intensive testing the Server was qualified. Lesson here is that changes cannot be commited quickly, need their time.