FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y vim python3-pip && \
apt install -y net-tools mc vim htop less strace zip gzip lynx && \
apt install -y apache2 mysql-server ntpdate libapache2-mod-php7.4 mysql-server php7.4-mysql php-dev libmcrypt-dev php-pear && \
apt install -y git && apt autoremove && apt clean && \
pip3 install pytest
RUN a2enmod rewrite
RUN echo "Europe/Ireland" | tee /etc/timezone
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
ENV APACHE_PID_FILE /var/run/apache2/apache2.pid
ENV APACHE_RUN_DIR /var/run/apache2
ENV APACHE_LOCK_DIR /var/lock/apache2
ENV APACHE_LOG_DIR /var/log/apache2
COPY phpinfo.php /var/www/html/
RUN service apache2 restart
EXPOSE 80
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
File: phpinfo.php
<html>
<?php
// Show all information, defaults to INFO_ALL
phpinfo();
// Show just the module information.
// phpinfo(8) yields identical results.
phpinfo(INFO_MODULES);
?>
</html>
File: build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="lampp"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -p 80:80 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
echo
echo "If you want to debug do:"
echo "docker exec -i -t ${s_DOCKER_IMAGE_NAME} /bin/bash"
More funny things happened like when I was installing a VirtualBox VM live, and the ZFS pool became irresponsible due hardware errors in one SATA Spinning drive.
Things from broadcasting live…
Some of the feedback I got from talented Engineers is that even if the original matter to talk about was interesting, seeing everything falling apart live due to unexpected hardware problems, and me troubleshooting live is being the best of the show… which I found very amusing.
RAB Radio the new digital world
I keep doing my radio space for Radio America Barcelona, once per week, addressed to the Catalan Community across the world and expats.
This radio program, streamed also via Twitch, is available in Catalan language only. RAB.
Open Source
carleslibs
I’ve been working in version 1.0.8 branch, and after a session of refactor on Twitch where I found a bug in MenuUtils class, I fixed it and released v. 1.0.8. You can see the video on the link.
Now I’m working on the branch v. 1.0.9.
ctop
I’ve been working in the branch 0.8.9.
My first Twitch broadcast was about adding Unit Testing to MemUtils class.
This week I decommissioned my last physical server in a Data Center.
It has been a long journey since I created my company to launch my own projects, and I started having my own infrastructure, back at 2000.
I was offering VPS at that time, with VMWare as Hypervisor.
This last Rack Server served me well for 21 years.
Now everything is Cloud, and is not viable to host and maintain servers unless this is your main occupation. Server’s motherboards die, hard drives die and they need to be replaced. Maintaining infrastructure it’s a full time job and you require somebody to do it. Also using fixed servers only prevents you from moving fast, locks a lot of money, and from spawning more compute capacity.
If you are curious this Rack Server is a Super Micro with Intel Xeon processor and SCSI drives.
Security
Firewall
I keep blocking thousands of IP Addresses every day.
When I see a pattern of an IP trying an attacks against the Server I look at the IP and if it’s from a hosting provider I just block the entire range.
I keep blocking any IP Address coming from Russia or Belarus since they invaded Ukraine.
My Health
I visited the hospital for a programmed following on my health.
The analysis are super good, and it’s super clear that I’ve improved radically. My discipline with the diet, taking the medicines and doing exercise regularly has been crucial.
My Doctor is confident that I’ll have a full recovery, but to do so I need to loss a lot of weight in a year or two.
So, I need to focus on my health and in doing exercise, being happy and avoid any kind of negative stress.
The cost of the travels and the medicines have put some stress into my economy, but I’m fortunate that I can handle it.
Entertainment / Life / Reflections
Star Wars and racism
I’m really enjoying new Start Wars series Obi Wan, and I’ve been profoundly shocked to read that there are fans being racist against the black characters.
I’m Catalan. In 1936 the fascist military leaded by franco raised in arms against the elected government of the Spanish Republic. The Italian and nazi German fascist in power bombed the Catalan population. Hundreds of thousands of innocent citizens were assassinated and millions of Catalan and Spaniards had to exile. The sons of those that were ruling with the dictator have been insisting in naming it a “civil war”, but it was the military lead by a fascist, revolting against the legitimate Republic and ending a democracy.
The dictatorship lasted until 1975, when the dictator died in the bed. The effects of the repression never abandoned Catalonia, and nowadays in Catalonia people is still detained by the Spanish police for talking the Catalan language in front of them, and our Parliament decisions are cancelled by the Spanish courts, for example to force the exit of a President of Catalonia that they didn’t like, or to force the Catalan schools to teach 25% of the time in Spanish attacking the Catalan teaching system.
During WW2 millions of Jews were mass murdered, also people from all the nations were assassinated.
Russian population suffered a lot also fighting the nazis.
Now we have to see how Russia’s army is invading Ukraine and murdering innocent citizens.
That’s horrible.
I know Engineers from Ukraine. Those guys were doing great building wealthy based on knowledge and working well for companies across the world. Now these people are being killed or Engineers, amongst all the brave population, are arming themselves to fight the invasion. Shells destroy beautiful cities and population are starving, and young soldiers from both sides will never be seen again by their mothers.
Let music play in solidarity with Ukraine. First is a Catalan group. Second is a famous Irish band in this epic song dedicated to the brave International Brigades, volunteers that fought the fascism in Spain and in Catalonia trying to make a better world.
The Blog
I’ve updated the SSL Certificate. The previous one I bought was issued for two years, and I renewed as it was due to expire.
Honestly, my ego was flattered. It is a lot of reputation.
Although in the past I got an offer from another monstrously big editorial to publish world wide my book Python 3 Combat Guide and I also rejected, and an offer from a digital learning platform to create an interactive course from this same book.
I’ve rejected it again this time.
If you are curious, this is what I answered to them:
Hi XXXX,
I'm well, thank you. I hope you are doing well too.
Thanks for taking the time to explain your conditions to me.
I feel flattered by your editorial thinking about me. I respect your brand, as I mentioned, as I own several of your titles.
However, I have to refuse your offer.
Is not the first time an editor has offered to publish one or more of my books. For all over the world, with much higher economic expectations.
I'll tell you why I love being at LeanPub:
1- I own the rights. All of them.
2- I can publish updates, and my readers get them for free. As I add new materials, the value is maximized for my readers.
3- I get 80% of the royalties.
4- If a reader is not happy, they can return the book for 60 days.
5- I can create vouchers and give a discount to certain readers, or give for free to people that are poor and are trying to get a career in Engineering.
The community of readers are very honest, and I only got 2 returns. One of them I think was from an editorial that purchased the book, evaluated it, and they contacted me to publish it, and after I rejected they applied for the refund.
I teach classes, and I charge 125 EUR per hour. I can make much more by my side than the one time payment you offer. The compensation for the video seems really obsolete.
Also, I could be using Amazon self publishing, which also brings bigger margins than you.
So many thanks for your offer. I thought about it because of the reputation, but I already have a reputation. I've thousands of visits to my tech blog, and because of the higher royalties, even if I sell less books through LeanPub it is much more rewarding.
Thanks again and have a lovely day and rest of the week.
Best,
Carles
The provisioning in Amazon AWS through their SDK is a book I’m particularly proud, as it empowers the developers so much. And I provide source code so they can go from zero to hero, in a moment. Amazon should provide a project sample as I do, not difficult to follow documentation.
Teaching / Mentoring
As I was requested, I’ve been offering advice and having virtual coffees with some people that recently started their journey to become Software Engineers and wanted some guidance and advice.
It has been great seeing people putting passion and studying hard to make a better future for themselves and for their families.
I’ll probably add to the blog more contents for beginners, although it will continue being a blog dedicated to extreme IT, and to super cool Engineering skills and troubleshooting.
For my regular students I have a discord space where we can talk and they can meet new friends studying or working in Engineering.
Free Resources
This github link provides many free books in multiple languages:
Zoom can zoom the view. So if they are sharing their screen, and font is too small, you can give a relax to your eyes by using Zoom’s zoom feature. It is located in View.
My health
After being in the hospital in December 2021, with risk for my life, and after my incredible recuperation, I’ve got the good news that I don’t need anymore 2 of the 3 medicines I was taking in a daily basis. It looks well through a completely recovery thanks to my discipline, doing sport every day several times, and the fantastic Catalan doctors that are supporting me so well.
Since they found what was failing in me, and after the emergency treatments I started to sleep really well. All night. That’s a privilege that I didn’t have for long long time.
Humor
Sad but true history. How many super talented Engineers have been hired and then they were given a shitty laptop/workstation super slow? That happened to me when I was hired by Volkswagen IT: gedas. I was creating projects for very big companies and I calculated that I was wasting 2 hours of my time compiling. The computer did not had enough RAM and was using swap.
Normally if we need to refresh a config in a Container we will spawn a new one, or we will access with sudo docker exec -it /bin/sh mycontainer for instance and force a reload, or we will have to restart the Container.
What if we want to be able to reload the config at any moment without restarting the process, or to trigger a process in our Container (like a dump or a flush) in another way than implementing an API?.
An unexplored way, for many, to communicate with your Container’s main process is to send Signals.
So basically I will show you how you can trap Signals within a Python process which is the main process for your Docker Container, and send them from your Hypervisor with the command:
sudo docker kill --signal=SIGUSR1
I choose to use SIGUSR1 as it is reserved for user defined Signals.
You can clone the project or get the source code from:
FROM ubuntu:20.04
MAINTAINER Carles Mateo
RUN apt update && apt install -y python3 python3-pip vim less && apt-get clean
# This will make sure printing in the Screen when running in dettached mode
ENV PYTHONUNBUFFERED=1
ENV DOCKERSIGNAL /var/dockersignal
RUN mkdir -p $DOCKERSIGNAL
COPY *.py $DOCKERSIGNAL
WORKDIR $DOCKERSIGNAL
# Again to enforce printing to the Screen when running dettached
CMD ["python3", "-u", "/var/dockersignal/dockersignal.py"]
The dockersignal.py file
# By Carles Mateo https://blog.carlesmateo.com
import signal
import time
def handler(signum, frame):
print('Signal handler called with signal', signum)
if signum == 10:
# 10 is the equivalent to SIGUSR1 for most x86/ARM (not for Alpha/Sparc, MIPS, PARISC)
print("Simulated action: Reload config")
if __name__ == "__main__":
print("Waiting for a Signal")
# Listed for this signal, so can listen for more
signal.signal(signal.SIGUSR1, handler)
while True:
# Do Whatever
time.sleep(1)
A shell file to build and run the Container like a pro
#!/bin/bash
DOCKER_CONTAINER_NAME="docker-signal"
DOCKER_IMAGE_NAME="docker-signal"
printf "Removing old Container %s\n" "${DOCKER_CONTAINER_NAME}"
sudo docker rm "${DOCKER_IMAGE_NAME}"
printf "Removing old Image %s\n" "${DOCKER_IMAGE_NAME}"
sudo docker image rm "${DOCKER_IMAGE_NAME}"
echo "Creating Docker Image"
sudo docker build -t ${DOCKER_IMAGE_NAME} . --no-cache
retVal=$?
if [ $retVal -ne 0 ]; then
printf "Error. Exit code %s\n" ${retVal}
exit
fi
echo "Running Docker Container ${DOCKER_CONTAINER_NAME} based in image ${DOCKER_IMAGE_NAME}"
sudo docker run --cpus="1.0" --name ${DOCKER_CONTAINER_NAME} ${DOCKER_IMAGE_NAME}
I published this book to help developers to understand and use Docker.
It is not targeted to SysAdmins, is aimed to Developers that want to get an operative know how by examples very quickly, and easy to read.
My other books have also updates not yet published, however an update has been published for Python 3 exercises for beginners book.
University classes are restarted, and I fixed my tower.
For the Cloud computing degree this semester VMWare is used intensively.
I have a dedicated tower with an AMD Ryzen 7 processor, a Samsung NMVe drive PCIe 4.0, which provides me a throughput of 6GB/second (six Gigabytes, so 48 Gbit/second), SAS drives and SATA too. It’s a little monster with 64 GB of RAM and 2.5 Gbps NIC.
It was not starting.
The problem was in the Video card, which made loosely contact to the motherboard.
I had to disconnect everything until I found what it was, but after moving the video card to another PCI slot, it worked.
I knew it was some sort of short circuit / bad contact as the fans were turning for a second and turning off immediately.
After this, the computer works fine but it will poweroff in about 4h and 12 hours. I’ve been testing and removing each component until I believe is the PSU. I’ve ordered a new one from a Dutch provider with web store in Ireland that my former colleague Thomas showed me one year and half ago.
Since England leaved the EU, it is impossible to buy from amazon.co.uk without experiencing problems in the border and delays.
If you want to learn how to assemble a PC, fix the problems and upgrade your laptop, I wrote this book:
If you are curious about what I use in my day to day:
A tower for developing and reading my email, with Linux, Intel i7 7800X (12 cores) and 64 GB of RAM, with Nvidia graphics card
A tower for holding Virtual Machines, with Linux, AMD Ryzen 7 3700x (16 cores) and 64 GB of RAM, with Nvidia graphics card
An upgraded HP laptop for programming in the cafe, is a Windows 10, with 16 GB of RAM
Raspberry Pi 4 and 3, from time to time
A laptop for programming, for Work, 16 GB of RAM
A tower for programming, for Work, at the office, 32 GB of RAM
I also had a Dell computer which battery inflated elevating the touchpad, an Acer 11.6 Latop very lightweight which screen died cracked apparently (it’s a mistery to me how this happened as I removed from the bag and it was cracked. That little laptop accompanied me during years, to many countries, as for a while I carried it with me 100% of the time. At that time if the companies I worked for had outages they were losing thousands of euros per hour, so as CTO I fixed broken stuff even in a restaurant. Believe when I recommend you and your teams to use Unit Testing) and a 15.6″ Acer with 16GB of RAM that was part of the payment of an Start up I was CTO for, and which screen flicks intermittently and I managed to fix it by applying a pressure point to a connector, so I managed to use as fixed computer at the beginning of being in Ireland. I was not using it much, as I had two laptops from work when working for Sanmina, a Dell with 16 GB of RAM and Core i7 with two external monitors and an Intel Xeon with 32GB of RAM, heavy weight, but very useful for my job (programming, doing demos, having VMs…).
I’ve assembled all my PC from the scratch, piece by piece, and I force myself to do it so I keep up to date of the upcoming technologies, buses, etc…
My students are doing well. Congrats to Albert for getting 8.67 from 10 in his university programming course exams!.
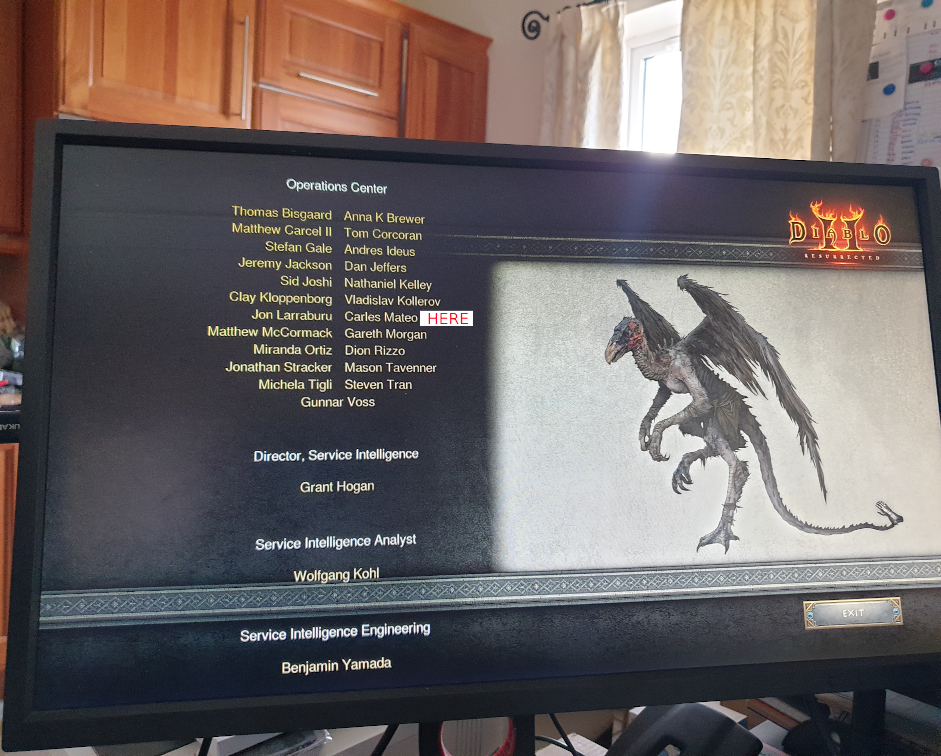
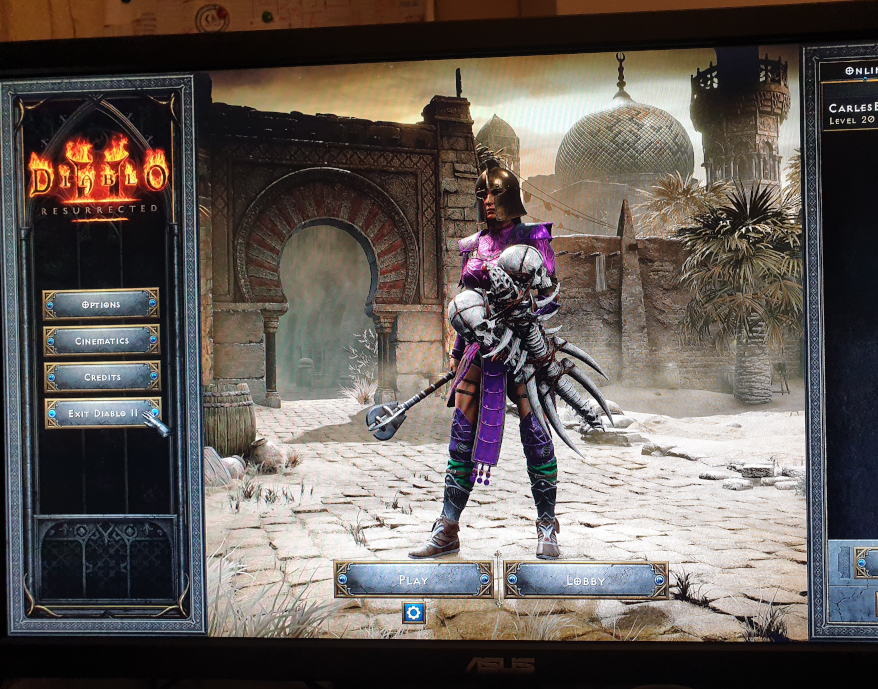
Diablo 2 Resurrected is published and I am in the credits :)
I’m in the credits of all our games since I joined, but I’m happy every time I see myself and my colleagues on them. :)
This release includes SubProcessUtils which is a class that allows you to execute commands to the shell (or without shell) and capture the STDOUT, STDERR, and Exit Code very easily.
I’ve used my libraries for a hackaton PoC for work, for Monitoring one aspect of one of our top games side, and I coded it super quickly. :)
They loved it and we have a meeting scheduled to create a Service from my PoC. :)
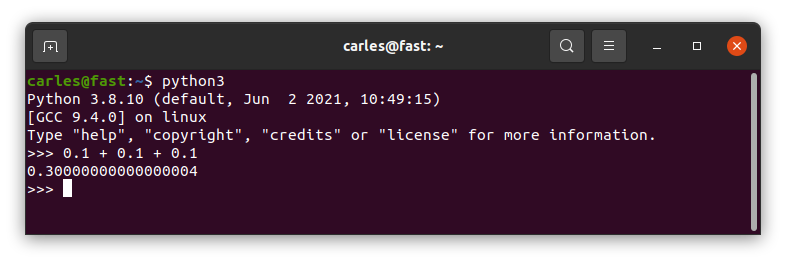
I’m not talking about the wonderful things, like how big can the Integers be, but about the bizarre things that may ruin your day.
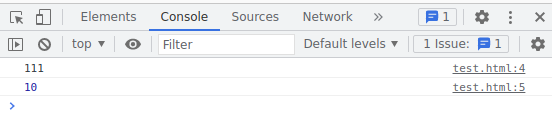
What sums 0.1 + 0.1 + 0.1 in Python?
0.3?
Wrong answer.
A bit of humor
Well, to be honest the computer was wrong. They way programming languages handle the Floats tend to be less than ideal.
Floats
Maybe you know JavaScript and its famous NaN (Not a number).
You are probably sure that Python is much more exact than that…
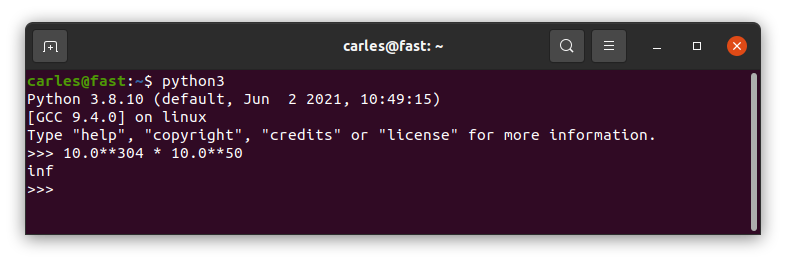
…well, until you do a big operation with Floats, like:
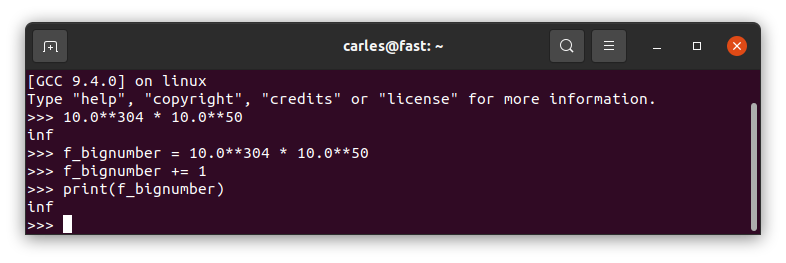
10.0**304 * 10.0**50
and
It returns infinite
I see your infinite and I add one :)
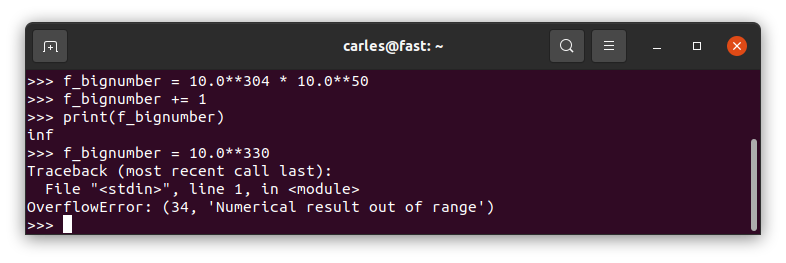
However If we try to define a number too big directly it will return OverflowError:
Please note Integers are handled in a much more robust cooler way:
Negative floats
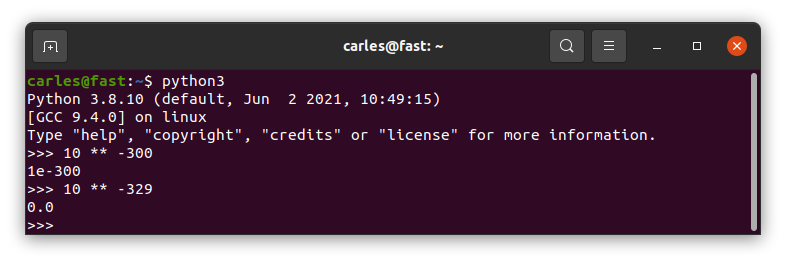
Ok. What happens if we define a number with a negative power, like 10 ** -300 ?
And if we go somewhere a bit more far? Like 10 ** -329
It returns 0.0
Ups!
I mention in my books why is better to work with Integers, and in fact most of the eCommerces, banks and APIs work with Integers. For example, if the amount in USD 10.00 they send multiplied by 100, so they will send 1000. All the actor know that they have to divide by 2.
Breaking the language innocently
I mentioned always that I use the MT Notation, the prefix notation I invented, inspired by the Hungarian Notation and by an amazing C++ programmer I worked with in Volkswagen and in la caixa (now caixabank), that passed away many years ago.
Well, that system of prefixes will name a variable with a prefix for its type.
It’s very useful and also prevents the next weird thing from Python.
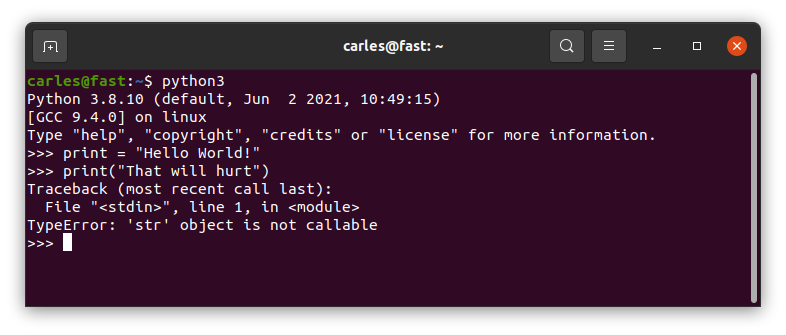
Imagine a Junior wants to print a String and they put in a variable. And unfortunately they call this variable print. Well…
print = "Hello World!"
print("That will hurt")
Observe the output of this and try not to scream:
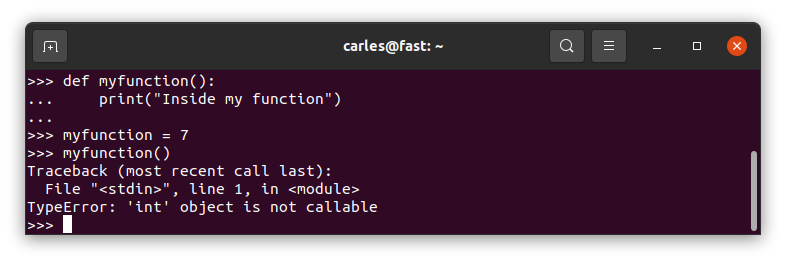
Variables and Functions named equally
Well, most of languages are able to differentiate a function, with its parenthesis, from a variable.
The way Python does it hurts my coder heart:
Another good reason to use MT Notation for the variables, and for taking seriously doing Unit Testing and giving a chance to using getters and setters and class Constructor for implementing limits and sanitation.
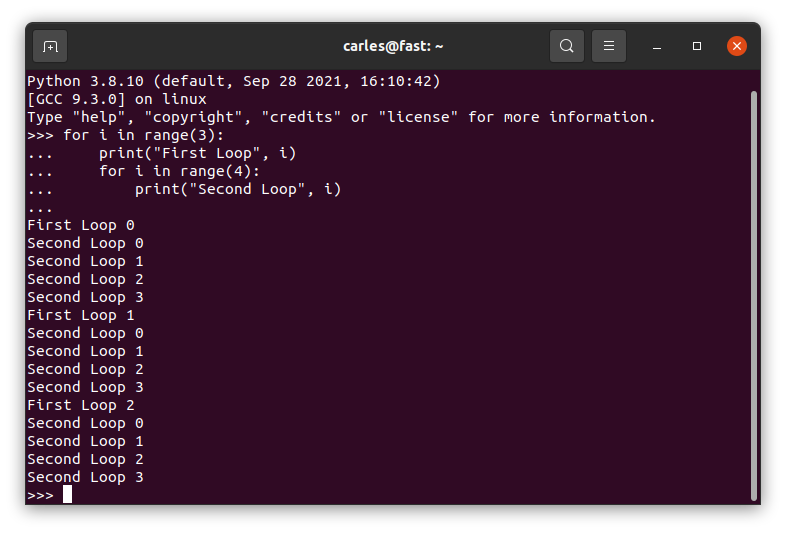
Nested Loops
This will work in Python, it doesn’t work in other languages (but please never do it).
for i in range(3):
print("First Loop", i)
for i in range(4):
print("Second Loop", i)
The code will not crash by overwriting i used in the first loop, but the new i will mask the first variable.
And please, name variables properly.
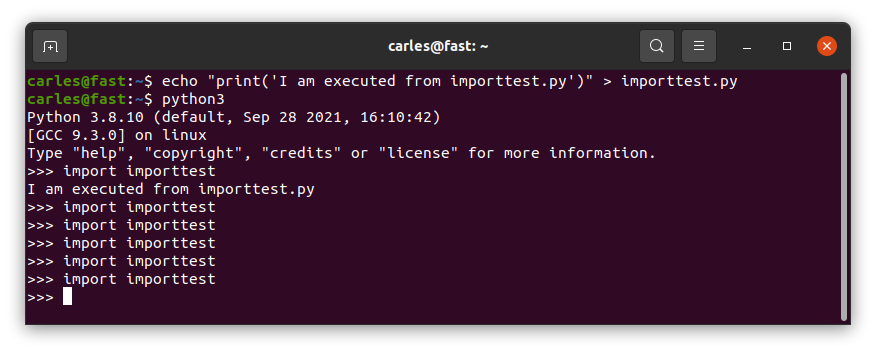
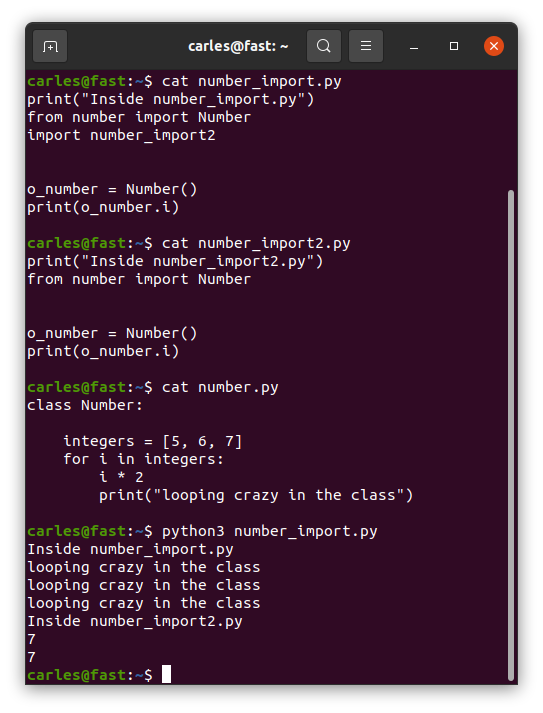
Import… once?
Imports are imported only once. Even if different files imported do import the same file.
So don’t have code in the middle of them, outside functions/classes, unless you’re really know what you’re doing.
Define functions first, and execute code after if __name__ == “__main__”:
Take a look at this code:
def first_function():
print("Inside first function")
second_function()
first_function()
def second_function():
print("Inside second function")
Well, this will crash as Python executes the code from top to bottom, and when it gets to first_function() it will attempt to call second_function() which has not been read by Python yet. This example will throw an error.
You’ll get an error like:
Inside first function
Traceback (most recent call last):
File "/home/carles/Desktop/code/carles/python_combat_guide/src/structure_dont_do_this.py", line 14, in <module>
first_function()
File "/home/carles/Desktop/code/carles/python_combat_guide/src/structure_dont_do_this.py", line 12, in first_function
second_function()
NameError: name 'second_function' is not defined
Process finished with exit code 1
Add your code at the bottom always, under:
if __name__ == "__main__":
first_function()
The code inside this if will only be executed if you directly call this code as main file, but will not be executed if you import this file from another one.
You don’t have this problem with classes in Python, as they are defined first, completely read, and then you instantiate or use them. To avoid messing and creating bugs, have the imports always on the top of your file.
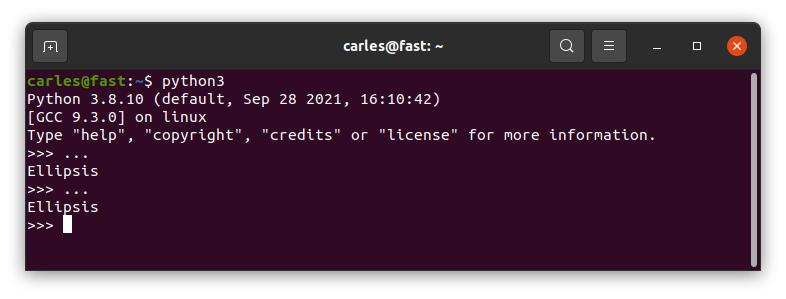
…Ellipsis
Today is Halloween and one of my colleagues asked me help to improve his Automation project.
I found something weird in his code.
He had something like that.
class Router:
def router_get_info(self):
...
def get_help_command(self):
return "help"
So I asked why you use … (dot dot dot) on that empty method?.
He told me that when he don’t want to implement code he just put that.
Well, dot dot dot is Ellipsis.
And what is Ellipsis?.
Ellipsis is an object that may appear in slice notation.
In Python all the methods, functions, if, while …. require to have an instruction at least.
So the instruction my colleague was looking for is pass.
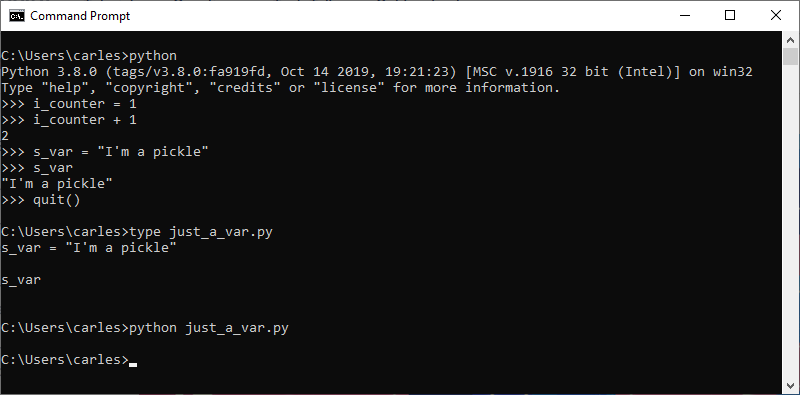
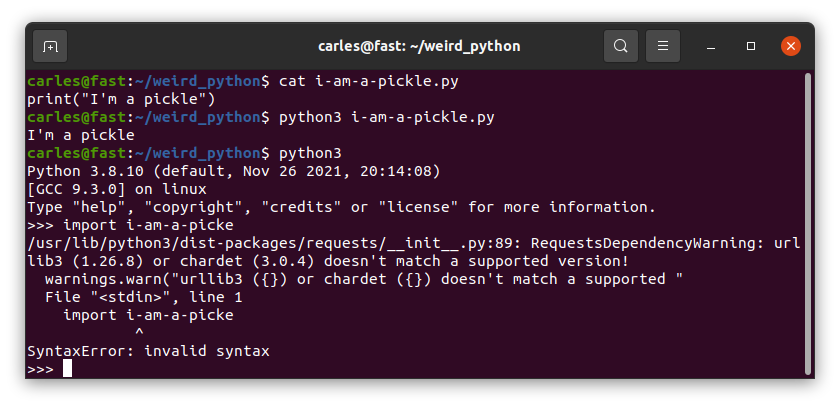
Just a variable?
In Python you can have just a var, without anything else, like no operation with it, no call, nothing.
This makes it easy to commit an error and not detecting it.
As you see we can have just s_var variable in a line, which is a String, and this does not raises an error.
If we do from python interpreter interactively, it will print the String “I’m a pickle” (famous phrase from Rick and Morty).
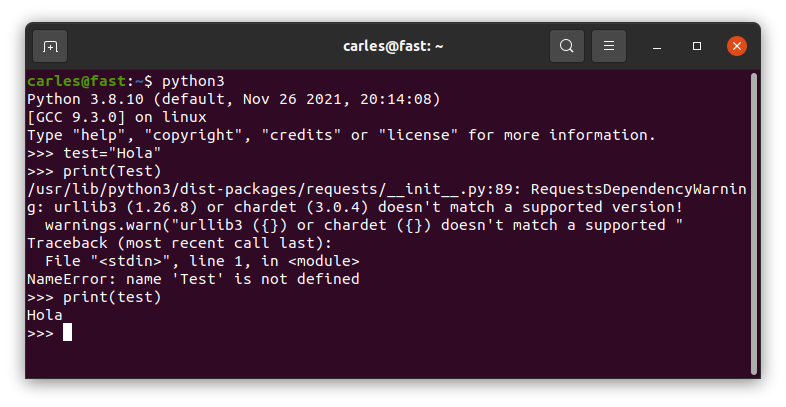
Variables are case sensitive
So you can define true false none … as they are different from True False None
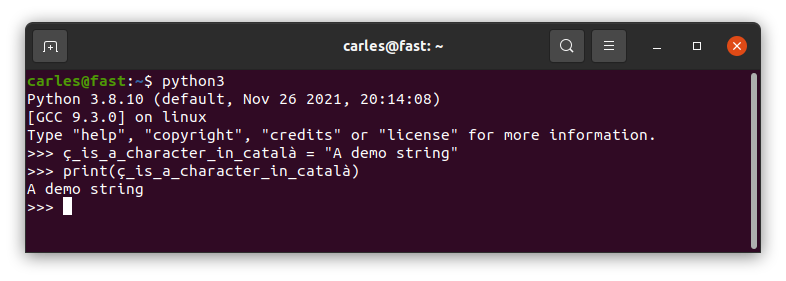
Variables in Unicode
Python3 accepts variables in Unicode.
I would completely discourage you to use variables with accents or other characters different from a-z 0-9 and _
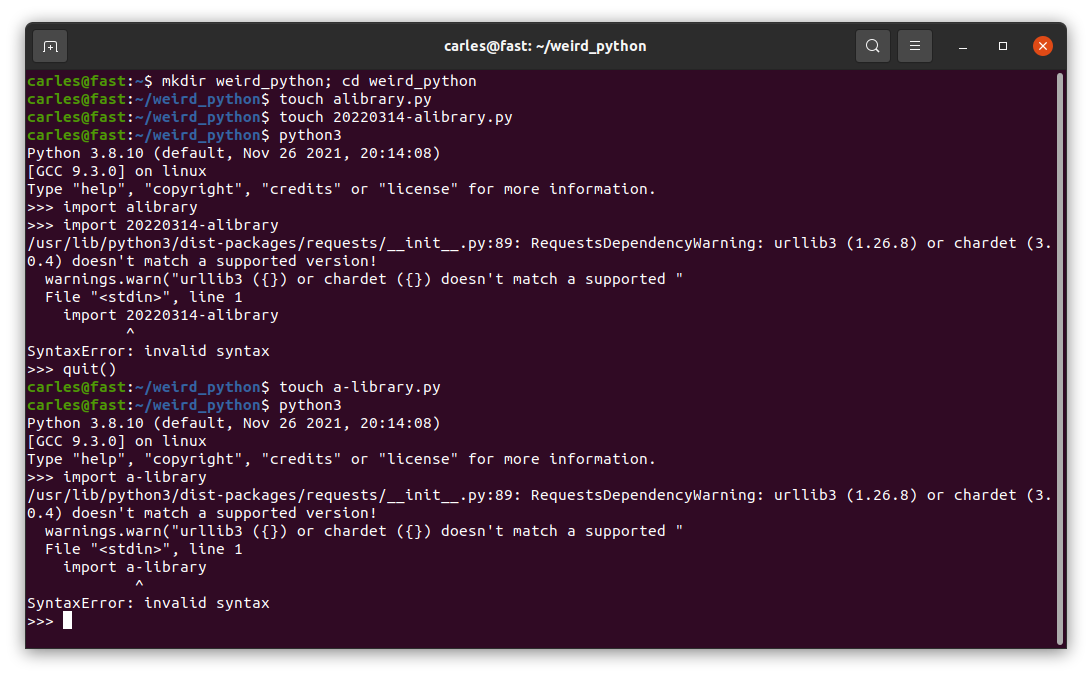
Python files with these names yes, but kaboom if you import them
So you can create Python files with dash or beginning with numbers, like 20220314_programming_class.py and execute them, but you cannot import them.
RYYFTK RODRIGUEZ,LEELA,FRY, FUTURAMA, 1999
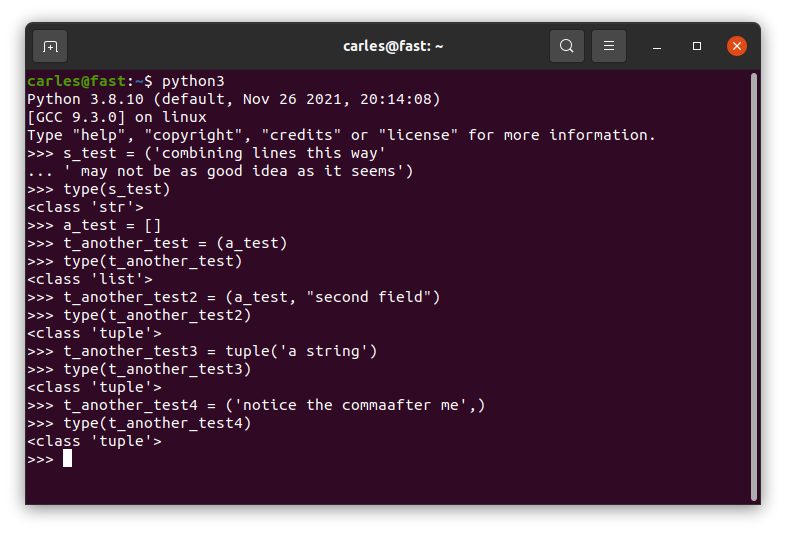
A Tuple of a String is not a Tuple, it’s a String
This can be very messy and confusing. Normally you define a tuple with parenthesis, although you can use tuple() too.
Parenthesis are the way we normally build tuples. But if we do:
print(type('this is a String'))
You get that this is a String, I mean
<class 'str'>
If you want to get a tuple of a String you can add a comma after the first String, which is weird. You can also do tuple("this is a String")
I think the definition of a tuple should be consistent and idempotent, no matter if you use one or more parameters. Probably as parenthesis are used for other tasks, like invoking functions or methods, or separating arithmetic operations, that reuse of the signs () for multiple purposes is what caused a different behavior depending on if there is one or more parameters the mayhem IMO.
See some example cases.
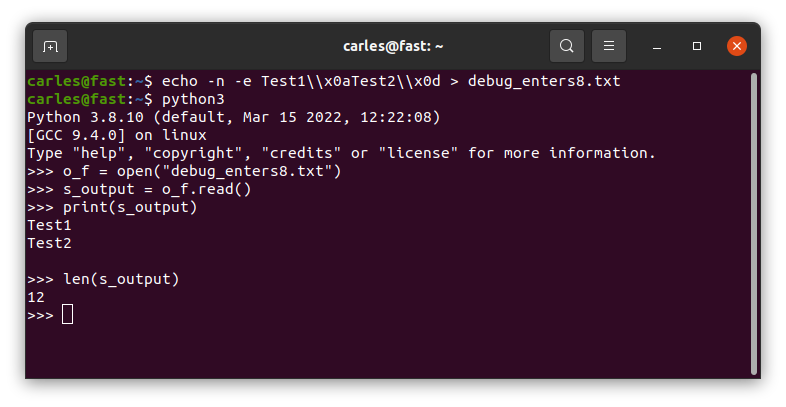
Python simplifies the jump of line \n platform independent and some times it’s messy
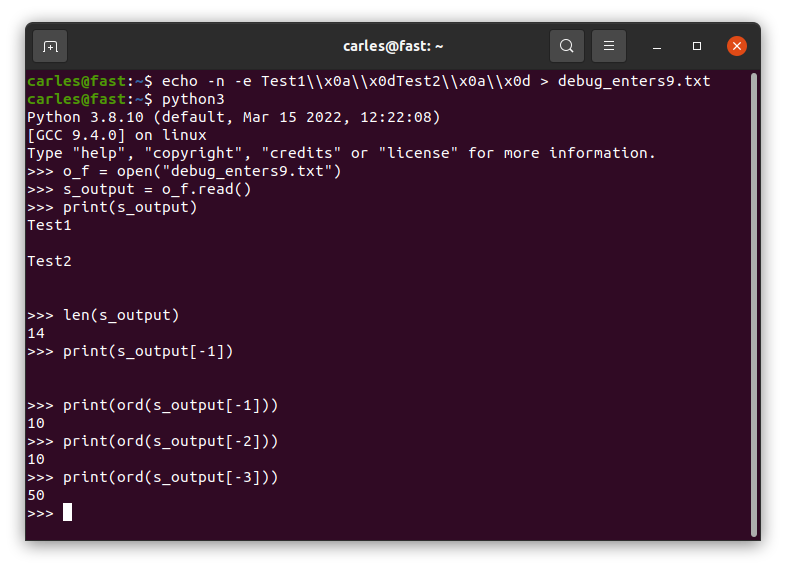
If you come from a C background you will expect text file in different platforms: Linux, Mac OS X (changes from old to new versions), Windows… to be represented different. In some cases this is an ASCii code 10 (LF), in others 13 (CR), and in other two characters: 13 and immediately after 10.
Python simplifies the Enter character by naming it \n like in C.
So, platform independent, whenever you read a text file you will get \n for any ASCii 10 [LF] or 13 [CR]. [CR] will be converted to [10] in Linux.
If you read a file in a Linux system, where enters are represented by 10, which was generated in a Windows system, so it has [CR][LF] instead of [LF] at the end of each line, you’ll get a \n too, but two times.
And if you do len(“\n”) to know the len of that String, this returns 1 in all the platform.
To read the [LF] and [CR] (represented by \r) you need to open the file as binary. By default Python opens the files as text.
You can check this by writting [LF] and [CR] in Linux and see how Python seamlessly reads the file as it was [LF].
A file generated by Windows will get \n\n:
Random code when the class is imported
In a procedural file, the code that is outside a function, will be executed when it is imported. But if this file is imported again it will not be re-executed.
Things are more messy if you import a class file. Inside the body of the class, in the space you would reserve for static variables definition, you can have random code. And this code will be only executed on the first import, not on subsequent.
Disclaimer: the pictures from Futurama are from their respective owners.
I had this idea after one my Python and Linux students with two laptops, a Mac OS X and a Windows one explained me that the Mac OS X is often taken by their daughters, and that the Windows 10 laptop has not enough memory to run PyCharm and Virtual Box fluently. She wanted to have a Linux VM to practice Linux, and do the Bash exercises.
So this article explains how to create a Ubuntu 20.04 LTS Docker Container, and execute a shell were you can practice Linux, Ubuntu, Bash, and you can use it to run Python, Apache, PHP, MySQL… as well, if you want.
You need to install Docker for Windows of for Mac:
Just pay attention to your type of processor: Mac with Intel chip or Mac with apple chip.
The first thing is to create the Dockerfile.
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y vim python3-pip && \
apt install -y net-tools mc htop less strace zip gzip lynx && \
pip3 install pytest && \
apt-get clean
RUN echo "#!/bin/bash\nwhile [ true ]; do sleep 60; done" > /root/loop.sh; chmod +x /root/loop.sh
CMD ["/root/loop.sh"]
So basically the file named Dockerfile contains all the blueprints for our Docker Container to be created.
You see that I all the installs and clean ups in one single line. That’s because Docker generates a layer of virtual disk per each line in the Dockerfile. The layers are persistent, so even if in the next line we delete the temporary files, the space used will not be recovered.
You see also that I generate a Bash file with an infinite loop that sleeps 60 seconds each loop and save it as /root/loop.sh This is the file that later is called with CMD, so basically when the Container is created will execute this infinite loop. Basically we give to the Container a non ending task to prevent it from running, and exiting.
Now that you have the Dockerfile is time to build the Container.
For Mac open a terminal and type this command inside the directory where you have the Dockerfile file:
sudo docker build -t cheap_ubuntu .
I called the image cheap_ubuntu but you can set the name that you prefer.
For Windows 10 open a Command Prompt with Administrative rights and then change directory (cd) to the one that has your Dockerfile file.
docker.exe build -t cheap_ubuntu .
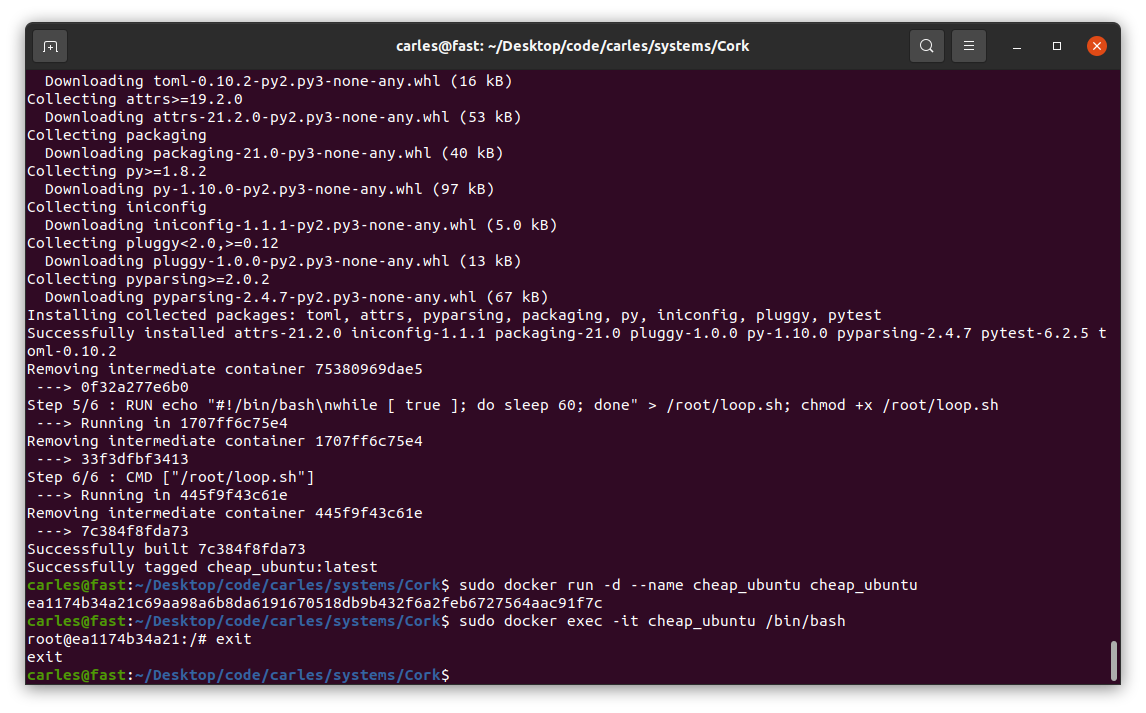
Image being built… (some data has been covered in white)
Now that you have the image built, you can create a Container based on it.
For Mac:
sudo docker run -d --name cheap_ubuntu cheap_ubuntu
For Windows (you can use docker.exe or just docker):
docker.exe run -d --name cheap_ubuntu cheap_ubuntu
Now you have Container named cheap_ubuntu based on the image cheap_ubuntu.
It’s time to execute an interactive shell and be able to play:
sudo docker exec -it cheap_ubuntu /bin/bash
For Windows:
docker.exe exec -it cheap_ubuntu /bin/bash
Our Ubuntu terminal inside Windows
Now you have an interactive shell, as root, to your cheap_ubuntu Ubuntu 20.04 LTS Container.
You’ll not be able to run the graphical interface, but you have a complete Ubuntu to learn to program in Bash and to use Linux from Command Line.
You will exit the interactive Bash session in the container with:
exit
If you want to stop the Container:
sudo docker stop cheap_ubuntu
Or for Windows:
docker.exe stop cheap_ubuntu
If you want to see what Containers are running do:
The addition I made to this version is StringUtils class which offer functionalities for handling amount conversions (to different units), number formatting, string formatting and align (left, right…). I added a 85% of Unit Testing Code Coverage.
Here you have some general information about how to install and how to use the package:
After Docker Image flask_app is built, you can run a Docker Container based on it with:
sudo docker run -d -p 5000:5000 --name flask_app flask_app
After you’re done, in order to stop the Container type:
sudo docker stop flask_app
Here is the source code of the Python file flask_app.py:
#
# flask_app.py
#
# Author: Carles Mateo
# Creation Date: 2020-05-10 20:50 GMT+1
# Description: A simple Flask Web Application
# Part of the samples of https://leanpub.com/pythoncombatguide
# More source code for the book at https://gitlab.com/carles.mateo/python_combat_guide
#
from flask import Flask
import datetime
def get_datetime(b_milliseconds=False):
"""
Return the datetime with miliseconds in format YYYY-MM-DD HH:MM:SS.xxxxx
or without milliseconds as YYYY-MM-DD HH:MM:SS
"""
if b_milliseconds is True:
s_now = str(datetime.datetime.now())
else:
s_now = str(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
return s_now
app = Flask(__name__)
# Those variables will keep their value as long as Flask is running
i_votes_r2d2 = 0
i_votes_bb8 = 0
@app.route('/')
def page_root():
s_page = "<html>"
s_page += "<title>My Web Page!</title>"
s_page += "<body>"
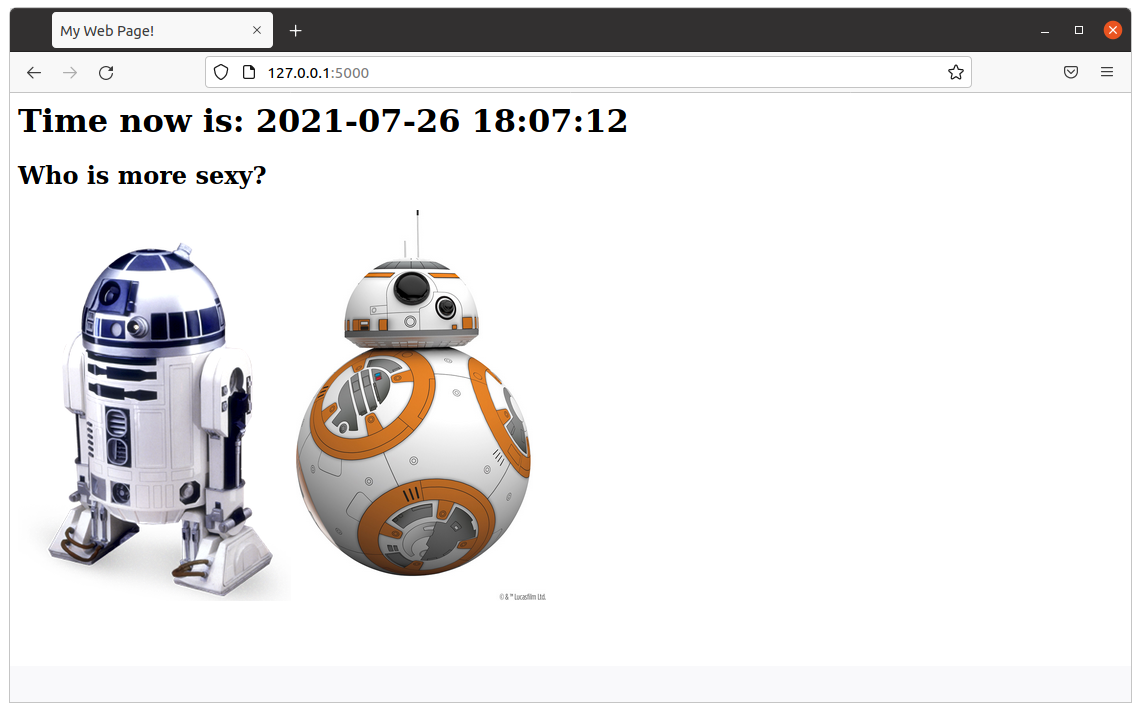
s_page += "<h1>Time now is: " + get_datetime() + "</h1>"
s_page += """<h2>Who is more sexy?</h2>
<a href="r2d2"><img src="static/r2d2.png"></a> <a href="bb8"><img width="250" src="static/bb8.jpg"></a>"""
s_page += "</body>"
s_page += "</html>"
return s_page
@app.route('/bb8')
def page_bb8():
global i_votes_bb8
i_votes_bb8 = i_votes_bb8 + 1
s_page = "<html>"
s_page += "<title>My Web Page!</title>"
s_page += "<body>"
s_page += "<h1>Time now is: " + get_datetime() + "</h1>"
s_page += """<h2>BB8 Is more sexy!</h2>
<img width="250" src="static/bb8.jpg">"""
s_page += "<p>I have: " + str(i_votes_bb8) + "</p>"
s_page += "</body>"
s_page += "</html>"
return s_page
@app.route('/r2d2')
def page_r2d2():
global i_votes_r2d2
i_votes_r2d2 = i_votes_r2d2 + 1
s_page = "<html>"
s_page += "<title>My Web Page!</title>"
s_page += "<body>"
s_page += "<h1>Time now is: " + get_datetime() + "</h1>"
s_page += """<h2>R2D2 Is more sexy!</h2>
<img src="static/r2d2.png">"""
s_page += "<p>I have: " + str(i_votes_r2d2) + "</p>"
s_page += "</body>"
s_page += "</html>"
return s_page
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
As always, the naming of the variables is based on MT Notation.
The Dockerfile is very straightforward:
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y vim python3-pip && pip3 install pytest && \
apt-get clean
ENV PYTHON_COMBAT_GUIDE /var/python_combat_guide
RUN mkdir -p $PYTHON_COMBAT_GUIDE
COPY ./ $PYTHON_COMBAT_GUIDE
ENV PYTHONPATH "${PYTHONPATH}:$PYTHON_COMBAT_GUIDE/src/:$PYTHON_COMBAT_GUIDE/src/lib"
RUN pip3 install -r $PYTHON_COMBAT_GUIDE/requirements.txt
# This is important so when executing python3 -m current directory will be added to Syspath
# Is not necessary, as we added to PYTHONPATH
#WORKDIR $PYTHON_COMBAT_GUIDE/src/lib
EXPOSE 5000
# Launch our Flask Application
CMD ["/usr/bin/python3", "/var/python_combat_guide/src/flask_app.py"]