FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# This will make sure printing in the Screen when running in detached mode
ENV PYTHONUNBUFFERED=1
RUN apt-get update -y && apt install -y sudo telnetd vim systemctl && apt-get clean
RUN adduser -gecos --disabled-password --shell /bin/bash telnet
RUN echo "telnet:telnet" | chpasswd
EXPOSE 23
CMD systemctl start inetd; while [ true ]; do sleep 60; done
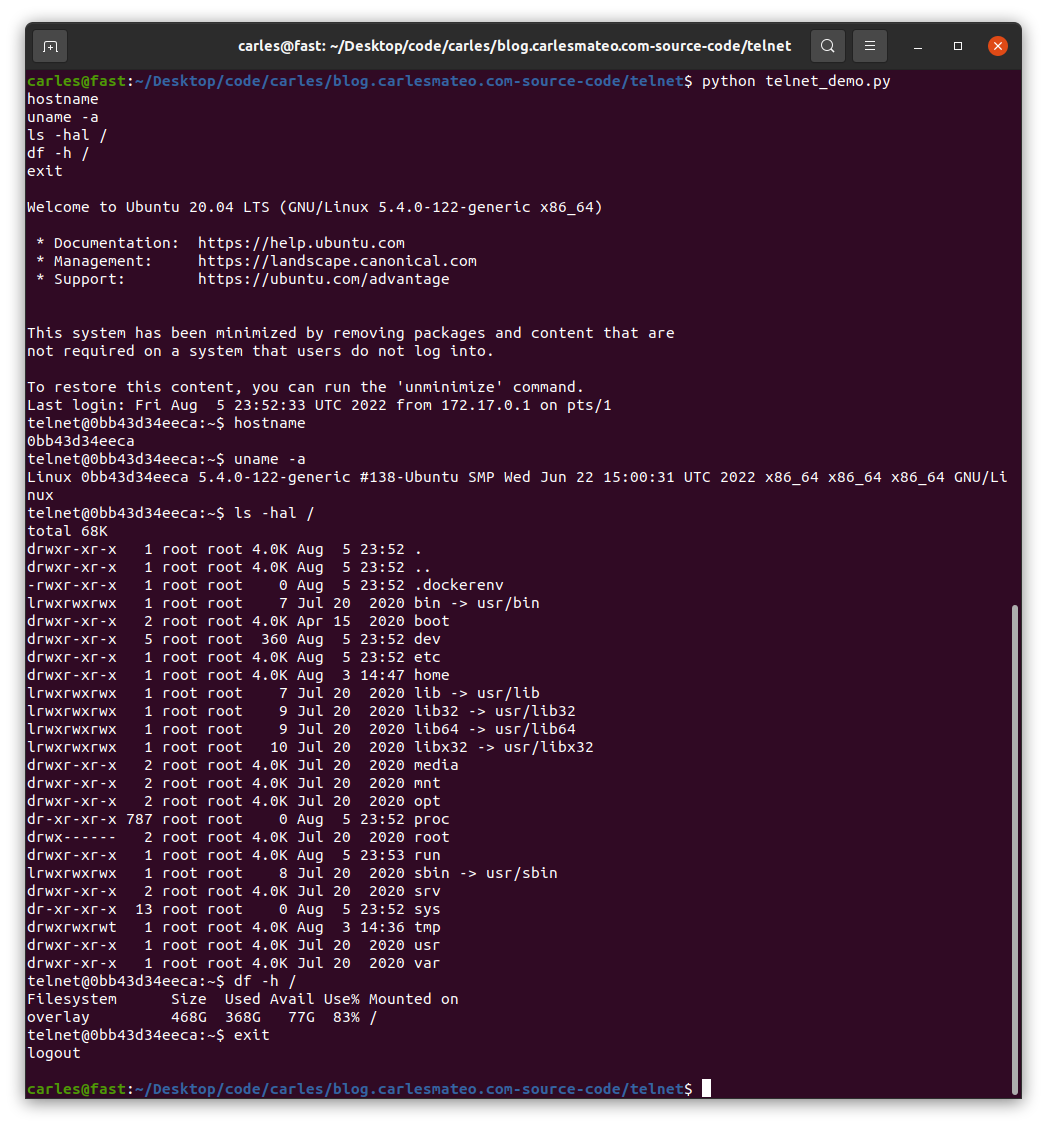
You can see that I use chpasswd command to change the password for the user telnet and set it to telnet. That deals with the complexity of setting the encrypted password.
File: build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="ubuntu_telnet"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
# If you don't want to use cache this is your line
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -it -p 23:23 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
When you run sudo ./build_docker.sh the image will be built. Then run it with:
sudo docker run -it -p 23:23 --name ubuntu_telnet ubuntu_telnet
If you get an error indicating that the port is in use, then your computer has already a process listening on the port 23, use another.
You will be able to stop the Container by pressing CTRL + C
One interesting aspect is that I cover how the messages are delivered as byte sequence. I show this by sending Unicode characters
Files in the project
Dockerfile
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
# This will make sure printing in the Screen when running in dettached mode
ENV PYTHONUNBUFFERED=1
ARG PATH_RABBIT_INSTALL=/tmp/rabbit_install/
ARG PATH_RABBIT_APP_PYTHON=/opt/rabbit_python/
RUN mkdir $PATH_RABBIT_INSTALL
COPY cloudsmith.sh $PATH_RABBIT_INSTALL
RUN chmod +x ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN apt-get update -y && apt install -y sudo python3 python3-pip mc htop less strace zip gzip lynx && apt-get clean
RUN ${PATH_RABBIT_INSTALL}cloudsmith.sh
RUN service rabbitmq-server start
RUN mkdir $PATH_RABBIT_APP_PYTHON
COPY requirements.txt $PATH_RABBIT_APP_PYTHON
WORKDIR $PATH_RABBIT_APP_PYTHON
RUN pwd
RUN pip install -r requirements.txt
COPY *.py $PATH_RABBIT_APP_PYTHON
COPY loop_send_get_messages.sh $PATH_RABBIT_APP_PYTHON
RUN chmod +x loop_send_get_messages.sh
CMD ./loop_send_get_messages.sh
cloudsmith.sh
#!/usr/bin/sh
# From: https://www.rabbitmq.com/install-debian.html#apt-cloudsmith
sudo apt-get update -y && apt-get install curl gnupg apt-transport-https -y
## Team RabbitMQ's main signing key
curl -1sLf "https://keys.openpgp.org/vks/v1/by-fingerprint/0A9AF2115F4687BD29803A206B73A36E6026DFCA" | sudo gpg --dearmor | sudo tee /usr/share/keyrings/com.rabbitmq.team.gpg > /dev/null
## Cloudsmith: modern Erlang repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/gpg.E495BB49CC4BBE5B.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg > /dev/null
## Cloudsmith: RabbitMQ repository
curl -1sLf https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/gpg.9F4587F226208342.key | sudo gpg --dearmor | sudo tee /usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg > /dev/null
## Add apt repositories maintained by Team RabbitMQ
sudo tee /etc/apt/sources.list.d/rabbitmq.list <<EOF
## Provides modern Erlang/OTP releases
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.E495BB49CC4BBE5B.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-erlang/deb/ubuntu bionic main
## Provides RabbitMQ
##
deb [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
deb-src [signed-by=/usr/share/keyrings/io.cloudsmith.rabbitmq.9F4587F226208342.gpg] https://dl.cloudsmith.io/public/rabbitmq/rabbitmq-server/deb/ubuntu bionic main
EOF
## Update package indices
sudo apt-get update -y
## Install Erlang packages
sudo apt-get install -y erlang-base \
erlang-asn1 erlang-crypto erlang-eldap erlang-ftp erlang-inets \
erlang-mnesia erlang-os-mon erlang-parsetools erlang-public-key \
erlang-runtime-tools erlang-snmp erlang-ssl \
erlang-syntax-tools erlang-tftp erlang-tools erlang-xmerl
## Install rabbitmq-server and its dependencies
sudo apt-get install rabbitmq-server -y --fix-missing
build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="rabbitmq"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -it --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
requirements.txt
pika
loop_send_get_messages.sh
#!/bin/bash
echo "Starting RabbitMQ"
service rabbitmq-server start
echo "Launching consumer in background which will be listening and executing the callback function"
python3 rabbitmq_getfrom.py &
while true; do
i_MESSAGES=$(( RANDOM % 10 ))
echo "Sending $i_MESSAGES messages"
for i_MESSAGE in $(seq 1 $i_MESSAGES); do
python3 rabbitmq_sendto.py
done
echo "Sleeping 5 seconds"
sleep 5
done
echo "Exiting loop"
FROM ubuntu:20.04
MAINTAINER Carles Mateo
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y vim python3-pip && \
apt install -y net-tools mc vim htop less strace zip gzip lynx && \
apt install -y apache2 mysql-server ntpdate libapache2-mod-php7.4 mysql-server php7.4-mysql php-dev libmcrypt-dev php-pear && \
apt install -y git && apt autoremove && apt clean && \
pip3 install pytest
RUN a2enmod rewrite
RUN echo "Europe/Ireland" | tee /etc/timezone
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
ENV APACHE_PID_FILE /var/run/apache2/apache2.pid
ENV APACHE_RUN_DIR /var/run/apache2
ENV APACHE_LOCK_DIR /var/lock/apache2
ENV APACHE_LOG_DIR /var/log/apache2
COPY phpinfo.php /var/www/html/
RUN service apache2 restart
EXPOSE 80
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
File: phpinfo.php
<html>
<?php
// Show all information, defaults to INFO_ALL
phpinfo();
// Show just the module information.
// phpinfo(8) yields identical results.
phpinfo(INFO_MODULES);
?>
</html>
File: build_docker.sh
#!/bin/bash
s_DOCKER_IMAGE_NAME="lampp"
echo "We will build the Docker Image and name it: ${s_DOCKER_IMAGE_NAME}"
echo "After, we will be able to run a Docker Container based on it."
printf "Removing old image %s\n" "${s_DOCKER_IMAGE_NAME}"
sudo docker rm "${s_DOCKER_IMAGE_NAME}"
printf "Creating Docker Image %s\n" "${s_DOCKER_IMAGE_NAME}"
# sudo docker build -t ${s_DOCKER_IMAGE_NAME} . --no-cache
sudo docker build -t ${s_DOCKER_IMAGE_NAME} .
i_EXIT_CODE=$?
if [ $i_EXIT_CODE -ne 0 ]; then
printf "Error. Exit code %s\n" ${i_EXIT_CODE}
exit
fi
echo "Ready to run ${s_DOCKER_IMAGE_NAME} Docker Container"
echo "To run in type: sudo docker run -p 80:80 --name ${s_DOCKER_IMAGE_NAME} ${s_DOCKER_IMAGE_NAME}"
echo "or just use run_in_docker.sh"
echo
echo "If you want to debug do:"
echo "docker exec -i -t ${s_DOCKER_IMAGE_NAME} /bin/bash"
If you are getting an error like this when you try to provision using rsync or running commands from SSH from a Docker Instance from a worker node in Jenkins, having your SSH Key as a variable in Jenkins, here is a way to solve it.
These are the kind of errors that you’ll be receiving:
Load key "ssh_yourserver": invalid format
web@myserver.carlesmateo.com: Permission denied (publickey).
rsync: connection unexpectedly closed (0 bytes received so far) [sender]
rsync error: unexplained error (code 255) at io.c(235) [sender=3.1.3]
script returned exit code 255
So this applies if you copied your .pem file as text and pasted in a variable in Jenkins.
You’ll find yourself with the load key invalid format error.
I would suggest to use tokens and Vault or Consul instead of pasting a SSH Key, but if you need to just solve this ASAP that’s the trick that you need.
First encode your key with base64 without any wrapping. This is done with this command:
Note that in this case I’m ignoring Strict Host Key Checking, which is not the preferred option for security, but you may want to use it depending on your strategy and characteristics of your Cloud Deployments.
Note also that I’m indicating as User Known Hosts File /dev/null. That is something you may want to have is you provision using Docker Containers that immediately destroyed after and Jenkins has not created the user properly and it is unable to write to ~home/.ssh/known_hosts
I mention the typical errors where engineers go crazy and spend more time fixing.
As in my case my jenkins container Id is 77b6a5a7ae8d in order to know the jenkins administrator password I check the logs for my jenkins Container with docker logs 77b6a5a7ae8d:
docker logs 77b6a5a7ae8d
Running from: /usr/share/jenkins/jenkins.war
webroot: EnvVars.masterEnvVars.get("JENKINS_HOME")
2022-06-26 21:02:05.492+0000 [id=1] INFO org.eclipse.jetty.util.log.Log#initialized: Logging initialized @549ms to org.eclipse.jetty.util.log.JavaUtilLog
2022-06-26 21:02:05.583+0000 [id=1] INFO winstone.Logger#logInternal: Beginning extraction from war file
2022-06-26 21:02:05.613+0000 [id=1] WARNING o.e.j.s.handler.ContextHandler#setContextPath: Empty contextPath
2022-06-26 21:02:05.674+0000 [id=1] INFO org.eclipse.jetty.server.Server#doStart: jetty-9.4.45.v20220203; built: 2022-02-03T09:14:34.105Z; git: 4a0c91c0be53805e3fcffdcdcc9587d5301863db; jvm 11.0.15+10
2022-06-26 21:02:05.986+0000 [id=1] INFO o.e.j.w.StandardDescriptorProcessor#visitServlet: NO JSP Support for /, did not find org.eclipse.jetty.jsp.JettyJspServlet
2022-06-26 21:02:06.020+0000 [id=1] INFO o.e.j.s.s.DefaultSessionIdManager#doStart: DefaultSessionIdManager workerName=node0
2022-06-26 21:02:06.020+0000 [id=1] INFO o.e.j.s.s.DefaultSessionIdManager#doStart: No SessionScavenger set, using defaults
2022-06-26 21:02:06.021+0000 [id=1] INFO o.e.j.server.session.HouseKeeper#startScavenging: node0 Scavenging every 600000ms
2022-06-26 21:02:06.463+0000 [id=1] INFO hudson.WebAppMain#contextInitialized: Jenkins home directory: /var/jenkins_home found at: EnvVars.masterEnvVars.get("JENKINS_HOME")
2022-06-26 21:02:06.647+0000 [id=1] INFO o.e.j.s.handler.ContextHandler#doStart: Started w.@7cf7aee{Jenkins v2.346.1,/,file:///var/jenkins_home/war/,AVAILABLE}{/var/jenkins_home/war}
2022-06-26 21:02:06.668+0000 [id=1] INFO o.e.j.server.AbstractConnector#doStart: Started ServerConnector@4c402120{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
2022-06-26 21:02:06.669+0000 [id=1] INFO org.eclipse.jetty.server.Server#doStart: Started @1727ms
2022-06-26 21:02:06.669+0000 [id=25] INFO winstone.Logger#logInternal: Winstone Servlet Engine running: controlPort=disabled
2022-06-26 21:02:06.925+0000 [id=32] INFO jenkins.InitReactorRunner$1#onAttained: Started initialization
2022-06-26 21:02:07.214+0000 [id=39] INFO jenkins.InitReactorRunner$1#onAttained: Listed all plugins
2022-06-26 21:02:10.781+0000 [id=47] INFO jenkins.InitReactorRunner$1#onAttained: Prepared all plugins
2022-06-26 21:02:10.794+0000 [id=35] INFO jenkins.InitReactorRunner$1#onAttained: Started all plugins
2022-06-26 21:02:10.803+0000 [id=42] INFO jenkins.InitReactorRunner$1#onAttained: Augmented all extensions
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.codehaus.groovy.vmplugin.v7.Java7$1 (file:/var/jenkins_home/war/WEB-INF/lib/groovy-all-2.4.21.jar) to constructor java.lang.invoke.MethodHandles$Lookup(java.lang.Class,int)
WARNING: Please consider reporting this to the maintainers of org.codehaus.groovy.vmplugin.v7.Java7$1
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2022-06-26 21:02:11.634+0000 [id=30] INFO jenkins.InitReactorRunner$1#onAttained: System config loaded
2022-06-26 21:02:11.635+0000 [id=30] INFO jenkins.InitReactorRunner$1#onAttained: System config adapted
2022-06-26 21:02:11.642+0000 [id=48] INFO jenkins.InitReactorRunner$1#onAttained: Loaded all jobs
2022-06-26 21:02:11.645+0000 [id=46] INFO jenkins.InitReactorRunner$1#onAttained: Configuration for all jobs updated
2022-06-26 21:02:11.668+0000 [id=67] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$1: Started Download metadata
2022-06-26 21:02:11.675+0000 [id=67] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$1: Finished Download metadata. 4 ms
2022-06-26 21:02:11.733+0000 [id=52] INFO jenkins.install.SetupWizard#init:
*************************************************************
*************************************************************
*************************************************************
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
3de0910b83894b9294989552e6fa9773
This may also be found at: /var/jenkins_home/secrets/initialAdminPassword
*************************************************************
*************************************************************
*************************************************************
2022-06-26 21:02:22.901+0000 [id=52] INFO jenkins.InitReactorRunner$1#onAttained: Completed initialization
2022-06-26 21:02:23.013+0000 [id=24] INFO hudson.lifecycle.Lifecycle#onReady: Jenkins is fully up and running
In my case the password is at the bottom, between the stars: 3de0910b83894b9294989552e6fa9773
More funny things happened like when I was installing a VirtualBox VM live, and the ZFS pool became irresponsible due hardware errors in one SATA Spinning drive.
Things from broadcasting live…
Some of the feedback I got from talented Engineers is that even if the original matter to talk about was interesting, seeing everything falling apart live due to unexpected hardware problems, and me troubleshooting live is being the best of the show… which I found very amusing.
RAB Radio the new digital world
I keep doing my radio space for Radio America Barcelona, once per week, addressed to the Catalan Community across the world and expats.
This radio program, streamed also via Twitch, is available in Catalan language only. RAB.
Open Source
carleslibs
I’ve been working in version 1.0.8 branch, and after a session of refactor on Twitch where I found a bug in MenuUtils class, I fixed it and released v. 1.0.8. You can see the video on the link.
Now I’m working on the branch v. 1.0.9.
ctop
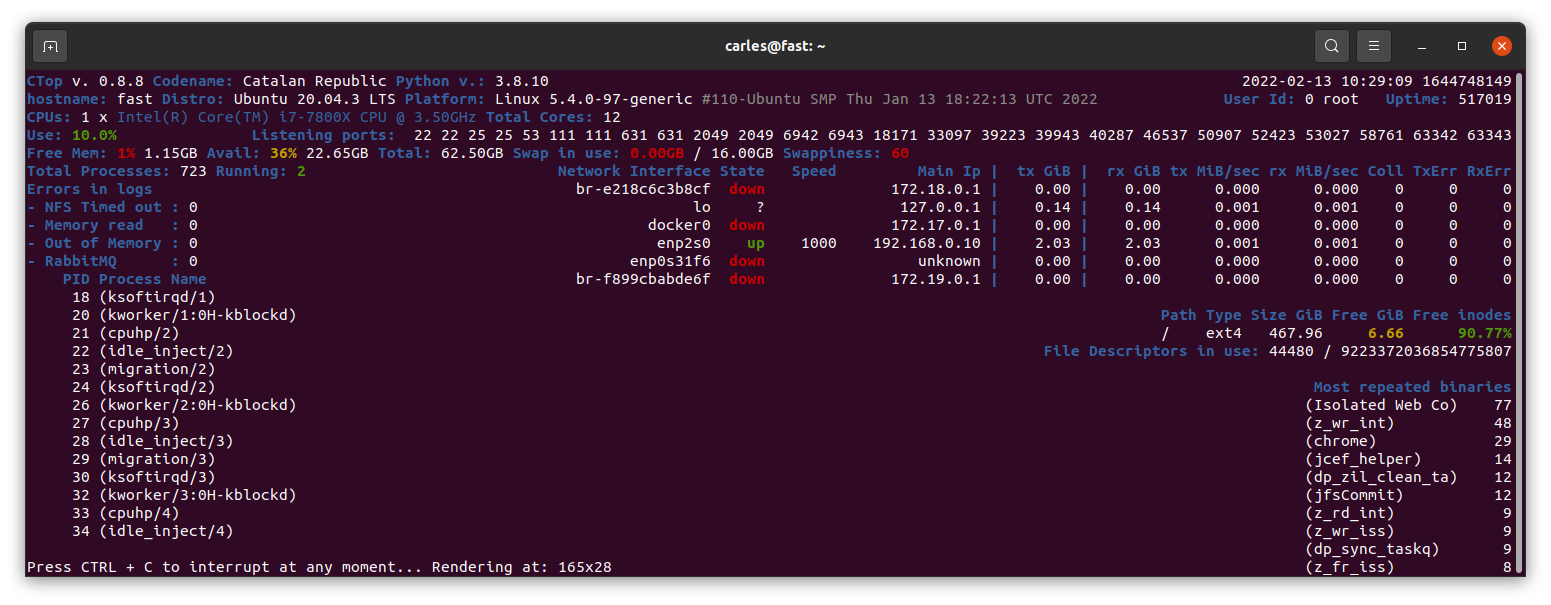
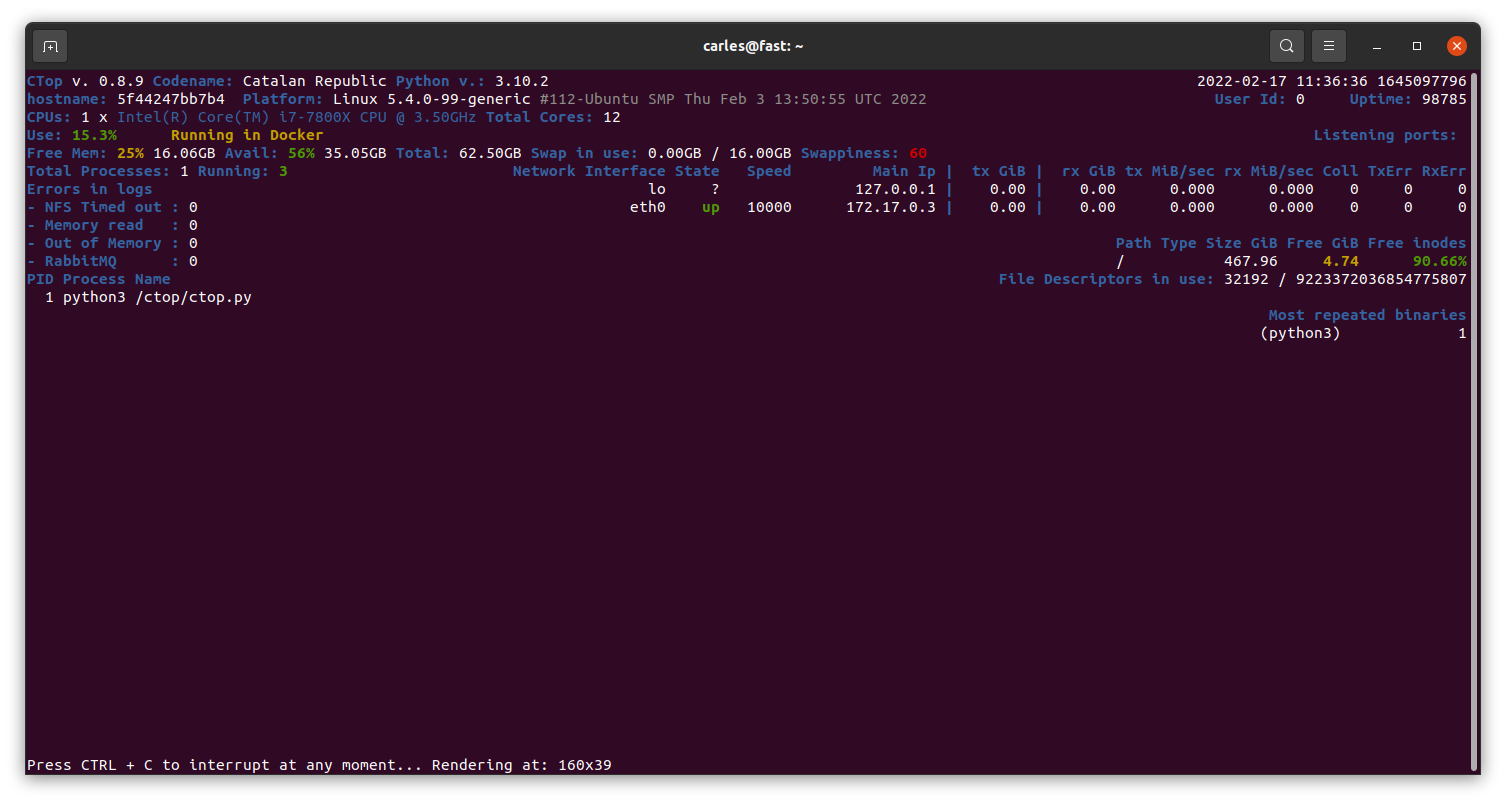
I’ve been working in the branch 0.8.9.
My first Twitch broadcast was about adding Unit Testing to MemUtils class.
This week I decommissioned my last physical server in a Data Center.
It has been a long journey since I created my company to launch my own projects, and I started having my own infrastructure, back at 2000.
I was offering VPS at that time, with VMWare as Hypervisor.
This last Rack Server served me well for 21 years.
Now everything is Cloud, and is not viable to host and maintain servers unless this is your main occupation. Server’s motherboards die, hard drives die and they need to be replaced. Maintaining infrastructure it’s a full time job and you require somebody to do it. Also using fixed servers only prevents you from moving fast, locks a lot of money, and from spawning more compute capacity.
If you are curious this Rack Server is a Super Micro with Intel Xeon processor and SCSI drives.
Security
Firewall
I keep blocking thousands of IP Addresses every day.
When I see a pattern of an IP trying an attacks against the Server I look at the IP and if it’s from a hosting provider I just block the entire range.
I keep blocking any IP Address coming from Russia or Belarus since they invaded Ukraine.
My Health
I visited the hospital for a programmed following on my health.
The analysis are super good, and it’s super clear that I’ve improved radically. My discipline with the diet, taking the medicines and doing exercise regularly has been crucial.
My Doctor is confident that I’ll have a full recovery, but to do so I need to loss a lot of weight in a year or two.
So, I need to focus on my health and in doing exercise, being happy and avoid any kind of negative stress.
The cost of the travels and the medicines have put some stress into my economy, but I’m fortunate that I can handle it.
Entertainment / Life / Reflections
Star Wars and racism
I’m really enjoying new Start Wars series Obi Wan, and I’ve been profoundly shocked to read that there are fans being racist against the black characters.
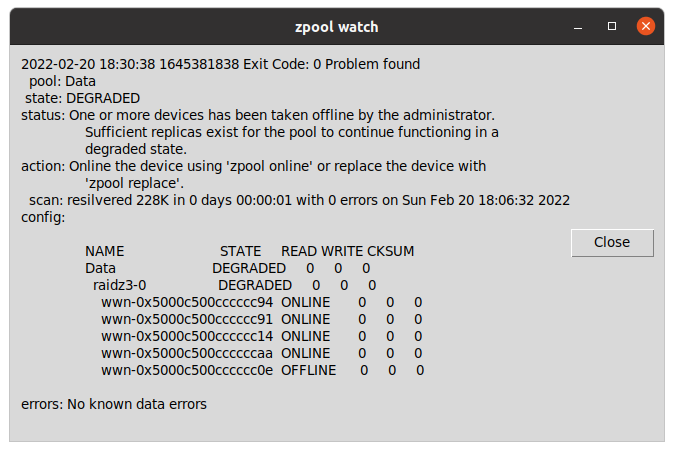
zpool watch is a small Python program for Linux workstations with graphical environment and ZFS, that checks every 30 seconds if your OpenZFS pools are Ok.
If a pool is not healthy, it displays a message in a window using tk inter.
Basically allows you to skip checking from the terminal zpool status continuously or to having to customize the ZED service to send an email and having to figure out how to it can spawn a window alert to the graphical system or what to do if the session has not been initiated.
carleslibs
Since last News from the Blog I’ve released carleslibs v.1.06, v.1.0.5 and v.1.0.4.
v.1.0.6 adds a new class OsUtils to deal with mostly-Linux Os tasks, like knowing the userid, the username, if it’s root, the distribution name and kernel version.
It also adds:
DatetimeUtils.sleep(i_seconds)
In v.1.0.5 I’ve included a new method for getting the Datetime in Unix Epoc format as Integer and increased Code Coverage to 95% for ScreenUtils class.
v. 1.0.4 contains a minor update, a method in StringUtils to escape html from a string.
It uses the library html (part of Python core) so it was small work to do for me to create this method, and the Unit Test for it, but I wanted to use carleslibs in more projects and adding it as core functionality, makes the code of these projects I’m working on, much more clear.
Minor refactors and adding more Code Coverage (Unit Testing), and protection in the code for division per zero when seconds passed as int are 0. (this was not an actual error, but is worth protecting the code just in case for the future)
Currently in Master there is a stable version of 0.8.9 mainly fixing https://gitlab.com/carles.mateo/ctop/-/issues/51 which was not detecting when CTOP was running inside a Docker Container (reporting Unable to decode DMI).
My Books
Docker Combat Guide
Added 20 new pages with some tricks, like clearing the logs (1.6GB in my workstation), using some cool tools, using bind mounts and using Docker in Windows from command line without activating Docker Desktop or WSL.
One of my SATA 2TB 2.5″ 5,400 rpm drive got damaged and so was generating errors, so that was a fantastic opportunity to show how to detect and deal with the situation to replace it with a new SATA 2TB 3.5″ 7,200 rpm and fix the pool.
The company sent me the Stein, which is sent to the employees that serve for two years, with a recognition and a celebration called “The Circle of Honor”.
Books purchased
I bought this book as often I discover new ways, better, to explain the things to my students.
Sometimes I buy books for beginners, as I can get explained what I want to do super fast and some times they teach nice tricks that I didn’t know. I have huge Django books, and it took a lot to finish them.
A simpler book may only talk about how to install and work with it under a platform (Windows or Mac, as instance) but it is all that I require as the command to create projects are the same cross platform.
For example, you can get to install and to create a simple project with ORM, connected to the database, very quickly.
Software
So I just discovered that Zoom has an option to draw in the shared screen, like Slack has. It is called Annotate. It is super useful for my classes. :)
Also discovered the icons in the Chat. It seems that not all the video calls accept it.
Hardware
As Working From Home I needed an scanner, I looked in Amazon and all of them were costing more than €200.
I changed my strategy and I bought a All-In-One from HP, which costed me €68.
So I’ll have a scanner and a backup printer, which always comes handy.
The nightmare started after I tried to connect it with Ubuntu.
Ubuntu was not recognizing it. Checking the manuals they force to configure the printer from an Android/iPhone app or from their web page, my understanding is for windows only. In any case I would not install the proprietary drivers in my Linux system.
Annoyed, I installed the Android application, and it was requesting to get Location permissions to configure it. No way. There was not possible to configure the printer without giving GPS/Location permissions to the app, so I cancelled the process.
I grabbed a Windows 10 laptop and plugged the All-in-one through the USB. I ran the wizard to search for Scanners and Printers and was not unable to use my scanner, only to configure as a printer, so I was forced to install HP drivers.
Irritated I did, and they were suggesting to configure the printer so I can print from Internet or from the phone. Thanks HP, you’ll be the next SolarWinds big-security-hole. I said no way, and in order to use the Wifi I have to agree to open that security door which is that the printer would be connected to Internet permanently, sending and receiving information. I said no, I’ll use only via USB.
Even selecting that, in order to scan, the Software forces me to create an account.
Disappointing. HP is doing very big stupid mistakes. They used to be a good company.
Since they stopped doing the drivers in Barcelona years ago, their Software and solutions (not the hardware) went to hell.
I checked the reviews in the App Store and so many people gave them 1 star and have problems… what a shame the way they created this solution.
This is a great Open Source, multi-platform editor, so I wanted to support the creator.
Security
Attacks: looking for exploits
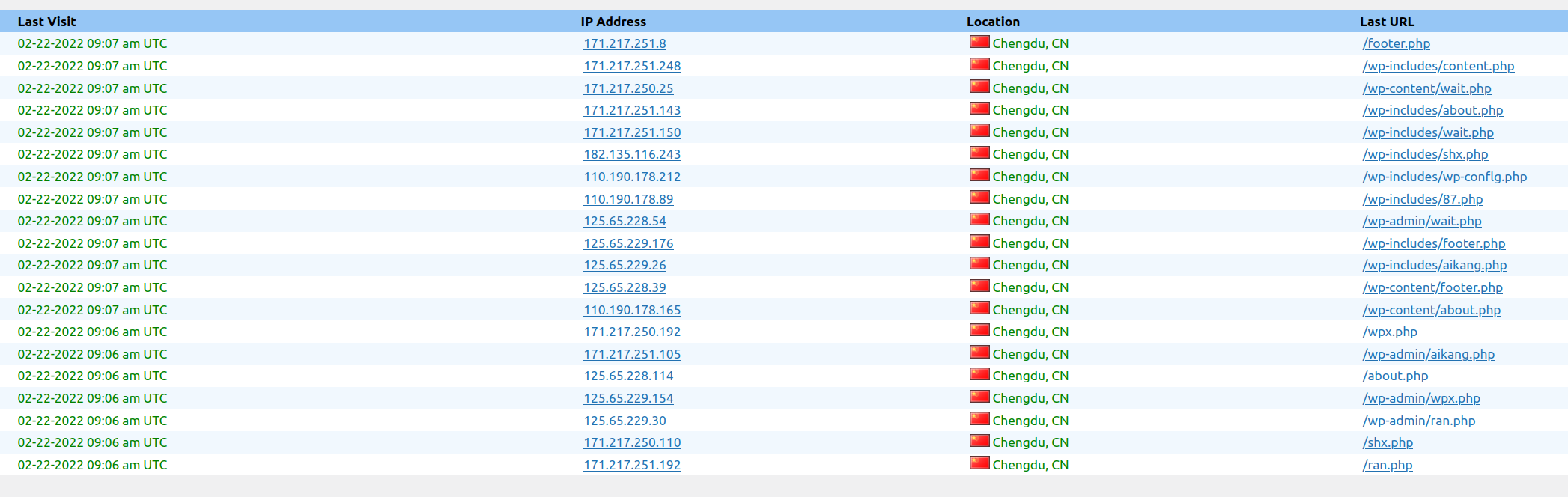
This is just a sample of a set of attacks to the blog in a 3 minutes interval.
Another one this morning:
Now all are blocked in the Firewall.
This is a non stop practice from spammers and pirates that has been going on for years.
It was almost three decades ago, when I was the Linux responsible of an ISP, and I was installing a brand new Linux system connected to a service called “infovia”, at the time when Internet was used with dial-up and modems, and in the interval of time of the installation, it got hacked. I had the Ethernet connected. So then already, this was happening.
The morning I was writing this, I blocked thousands of offending Ip Addresses.
Protection solutions
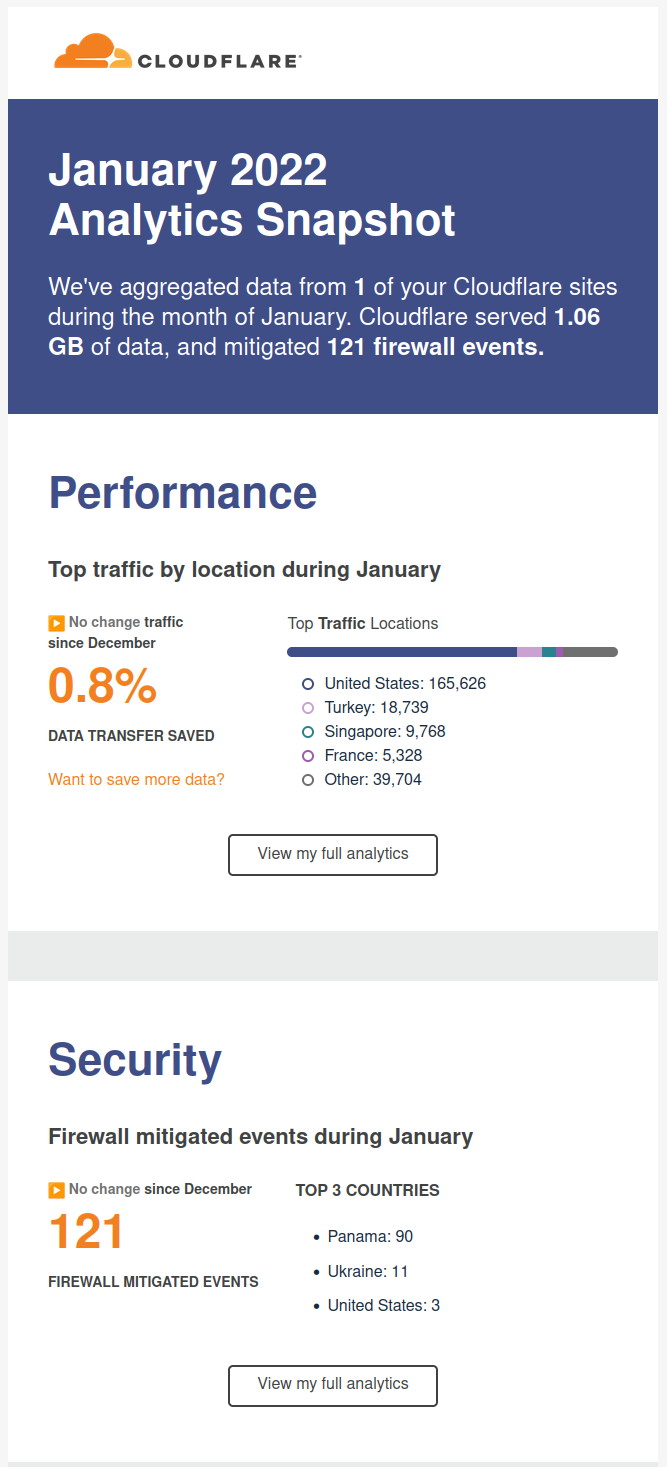
I recommend you to use CloudFlare, is a CDN/Cache/Accelerator with DoS protection and even in its Free version is really useful.
Fun/Games
So I come with a game kind of Quiz that you can play with your friends, family or work colleagues working from home (WFH).
The idea is that the master shares screen and sound in Zoom, and then the rest connect to jackbox.tv and enter the code displayed on the master’s screen on their own browser, and an interactive game is started.
It is recommended that the master has two monitors so they can also play.
The games are so fun as a phrase appearing and people having to complete with a lie. If your friends vote your phrase, believing is true, you get points. If you vote the true answer, you get points too.
Very funny and recommendable.
Stuff
<humor>Skynet sent another terminator to end me, but I terminated it. Its processor lays exhibited in my home now</humor>
I bought a laminator.
It has also a ruler and a trimmer to cut the paper.
It was only €39 and I’ve to say that I’m very happy with the results.
It takes around 5 minutes to be ready, it takes to get to the hot-enough temperature, and feeds the pages slowly, around 50 secs a DIN-A4, but the results are worth the time.
I’ve protected my medical receipts and other value documents and the work was perfect. No bubbles at all. No big deal if the plastic covers are introduced not 100% straight. Even if you pass again an already plasticized document, all is good.
Fun
Databases
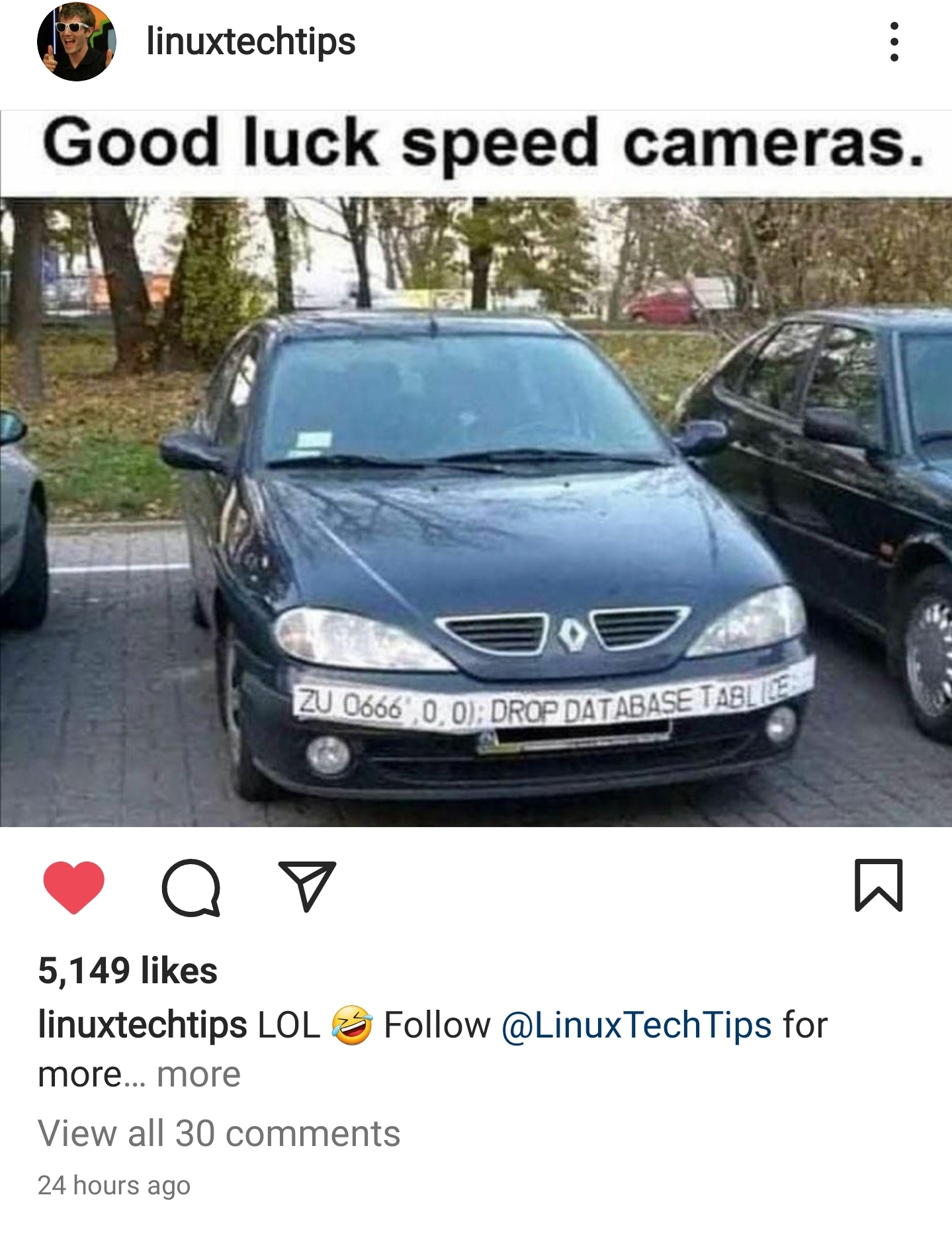
One of my friends sent me this image.
It is old, but still it’s fun. So it assumes the cameras of the parking or speed cameras, will OCR the plate to build a query, and that the code is not well protected. So basically is exploiting a Sql Injection.
Anybody working on the systems side, and with databases, knows how annoying are those potential situations.
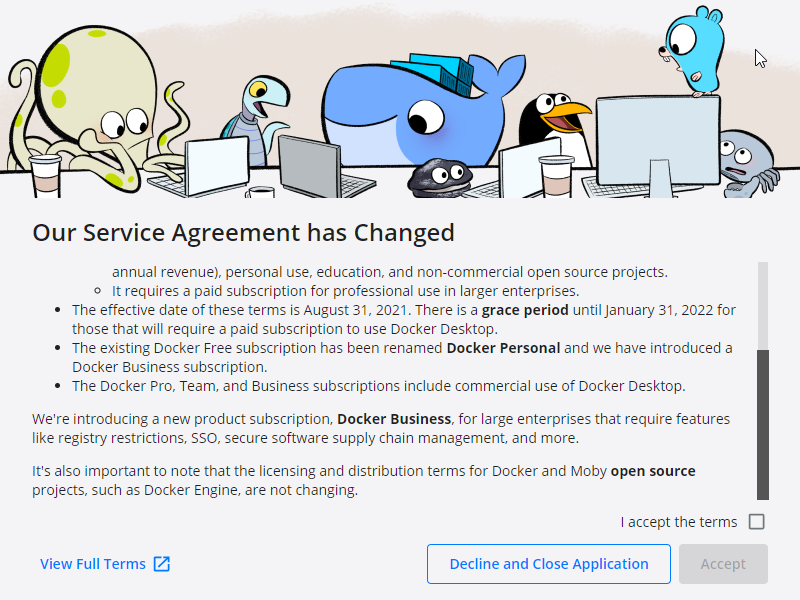
The change of license of Docker Desktop for Windows has been a low punch, a dirty one.
Many big companies use Windows as for the laptops and workstations, we like it or not.
You can setup a Linux development computer or Virtual Machine, you may argue, but things are not as easier.
Big companies have Software licenses assigned to corporation machines, so you may not use your Pycharm license in a Linux VM.
You may no use Docker Desktop either, if your company did not license it.
And finally you may need to have access to internal resources, like Artifactory, or Servers where access is granted via ACL, so only you, from your Development machine can access it. So you have to be able to run Docker locally.
After Docker introduced this changed of license I was using VirtualBox with NAT attached to the VPN Virtual Ethernet, and I port forwarded to be able to SSH, deploy, test, etc… from outside to my Linux VM, and it was working for a while, until with the last VirtualBox update and some Windows updates where pushed to my Windows box and my VirtualBox VMs stopped booting most of the times and having random problems.
I configured a new Linux VM in a Development Server, and I opened Docker API so my Pycharm’s workstation was able to deploy there and I was able to test. But the Dev Ip’s do not have access to the same Test Servers I need my Python Automation projects to reach (and quickly I used 50 GB of space), so I tried WSL. I like Pycharm I didn’t want to switch to VStudio Code because of their good Docker extensions, in any case I could not run my code locally with venv cause some of the packages where not available for Windows, so I needed Linux to run the Unit Testing and see the Code Coverage, run the code, etc…
I tried Hyper-V, tried with NAT External, but it was incompatible with my VPN.
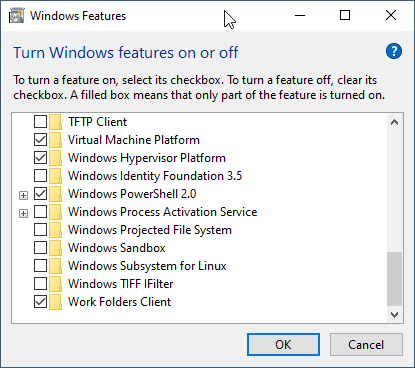
Note: WSL can be used, but I wanted to use Docker Engine, not docker in WSL.
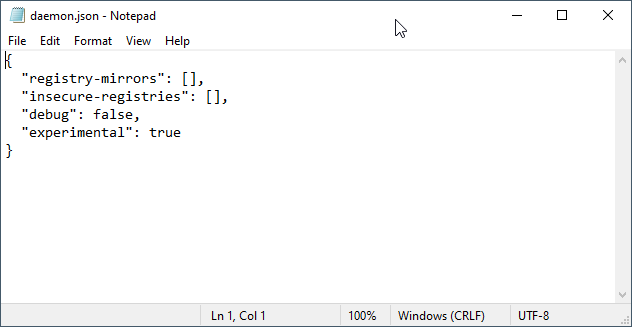
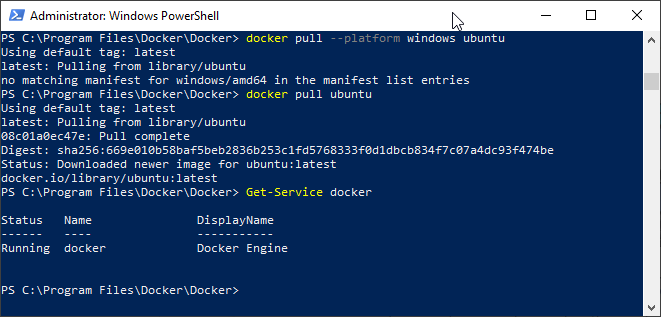
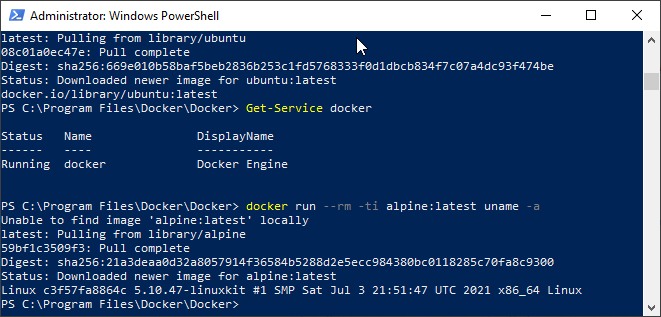
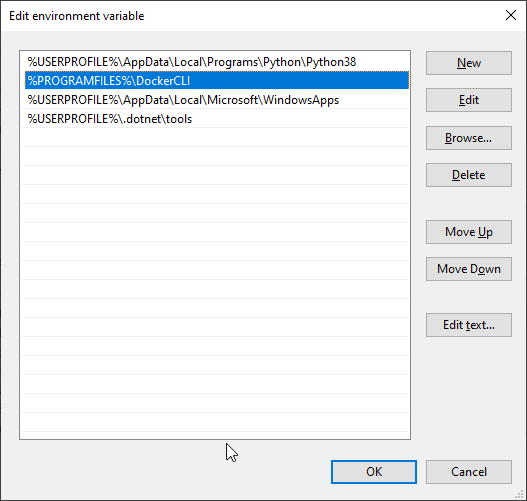
Installing Docker Command line binaries
The first thing I checked was the Docker downloads page.
It has been 9 years since I created the blog, and some articles have old content that still get many visitors. To make sure they get the clear picture and not obsolete information, all the articles of the taxonomy POST, will include the Date and Time when the article was first published.
I also removed the annoying link “Leave a comment” on top. I think it influences some people to leave comments before actually having read the article.
It is still possible to add comments, but they are on the bottom of the page. I believe it makes more sense this way. This is the way.
Technically that involved modifying the files of my template:
functions.php
content.php
My Books
Automating and Provisioning to Amazon AWS using boto3 Amazon’s SDK for Python 3
It’s 128 pages in Full size DIN-A4 DRM-Free, and comes with a link to code samples of a real project CLI Menu based.
Docker Combat Guide
I have updated my book Docker Combat Guide and I added a completely new section, including source code, to work with Docker’s Python SDK.
I show the Docker SDK by showing the code of an actual CLI program I wrote in Python 3.
Here you can see a video that demonstrates how I launched a project with three Docker Containers via Docker compose. The Containers have Python, Flask webserver, and redis as bridge between the two Python Containers.
All the source code are downloadable with the book.
Watch at 1080p at Full Screen for better experience
My Classes
In January I resumed the coding classes. I have new students, and few spots free in my agenda, as some of my students graduated and others have been hired as Software Developers. I can not be more proud. :)
Free Training
Symfony is one of the most popular PHP Frameworks.
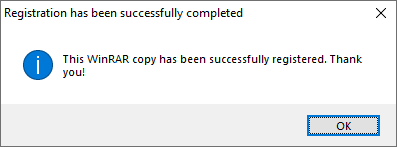
Before leaving 2021, I registered WinRAR for Windows.
WinRAR is a compressing Software that has been with us for 19 years.
I’m pretty sure I registered it in the past, but these holidays I was out only with two Window laptops and I had to do some work for the university and WinRAR came it handy, so I decided to register it again.
I create Software and Books, and I earn my life with this, so it makes a lot of sense to pay others for their good work crafting Software.
Books I Purchased
I bought this book and by the moment is really good. I wanted to buy some updated books as all my Linux books have some years already. Also I keep my skills sharp by reading reading reading.
Hardware I purchased
So I bought a cheap car power inverter.
The ones I saw in Amazon were €120+ and they were not very good rated, so I opted to buy a cheap one in the supermarket and keep it on the car just in case one day I need it. (My new Asus Zenbook laptop has 18 hours of autonomy and I don’t charge it for days, but you never know)
For those that don’t know, a power inverter allows you to get a 220V (120V in US) plug, from the connection of the lighter from your car. Also you can get the energy from an external car battery. This comes in really handy to charge the laptop, cameras, your drone… if you are in the nature and you don’t have any plug near.
I bought one years ago to power up Raspberry Pi’s when I was doing Research for a project I was studying to launch.
Fun
Many friends are using Starlink as a substitute of fiber for their rural homes, and they are super happy with it.
One of them send me a very fun article.
It is in Italian, but you can google translate it.
Anyways you can get the idea of what’s going on in the picture :)
So tell me… so your speed with Starlink drops 80% in winter uh… aha…
Random news about Software
I tried the voice recognition in Slack huddle, and it works pretty well. Also Zoom has this feature and they are great. Specially when you are in a group call, or in a class.
My health
I was experimenting some problems, so I scheduled an appointment to get blood analysis and to be checked. Just in case.
TL;TR I could have died.
The doctors saw my analysis and sent me to the hospital urgently, where they found something that was going to be lethal. For hours they were checking me and doing several more analysis and tests to discard false positives, etc… and they precisely found the issue and provided urgent treatment and confirmed that I could have died at any moment.
Basically I dodged a bullet.
I was doing certain healthy things that helped me in a situation that could have been deadly or extremely dangerous to my health.
With the treatment and my strict discipline, I reverted the situation really quick and now I have more health and more energy than before. I feel rejuvenated.
I’m feeling lucky that with my work, the classes, the books I wrote, etc… I didn’t have to worry about the expensive medicines, the transport, etc… It was a bad moment, during Christmas, with so many people on holidays, pharmacies and GPs closed, so I had to spend more time looking for, traveling, and to pay more than it would had been strictly necessary. Despite all the time I used to my health, I managed to finish my university duties on time, and I didn’t miss my duties at work after the hospital, neither I had to cancel any programming classes or mentoring sessions. Nobody out of my closest circle knew what was going on, with the exception of my boss, which I kept informed in real time, just in case there was any problem, as I didn’t want to let down the company and have my duties at work to be unattended if something major happened.
I was not afraid to die. Unfortunately I’ve lost very significant people since I was a child. Relatives, very appreciated bosses and colleagues which I considered my friends, and great friends of different circles. Illnesses, accidents, and a friend of mine committed suicide years ago, and some of my partners attempted it (before we know each other). When you see people that are so good leaving, this brings a sadness that cannot be explained with words. I have had a tough life.
We have a limited time, and he have freedom to make choices. Some people choose to be miserable, to mistreat others, to lie, to cheat, to be unfaithful, to lack ethic and integrity. Those are their choices. Their wasted time will not come back.
Some of my friends are doctors. I admire them. They save lives and improve the quality of life of people with health problems.
I like being an Engineer cause I can create things, I can build instead of destroy, I can help to improve the world, and I can help users to have a good time and to avoid the frustration of services being down. I chose to do a positive work. So many times I’ve been offered much bigger salaries to do something I didn’t like, or by companies that I don’t admire, and I refused. Cause I wanted to make a better world. I know many people don’t think like that, and they only take take take. They are even unable to understand my choices, even to believe that I’m like that. But it’s enough that I know what I’m doing, and that it makes sense for me, and that I know that I’m doing well. And then, one day, you realize, that doing well, being fair and nice even if other people stabbed you in the back, you got to know fantastic people like you, and people that adore you and love to have you in their life, in their companies… So I’m really fortunate. To all the good-hearted people around, that give without expect anything in return, that try to make the world a better place, thank you.
So here I explain how to solve a problem that was happening to a friend.
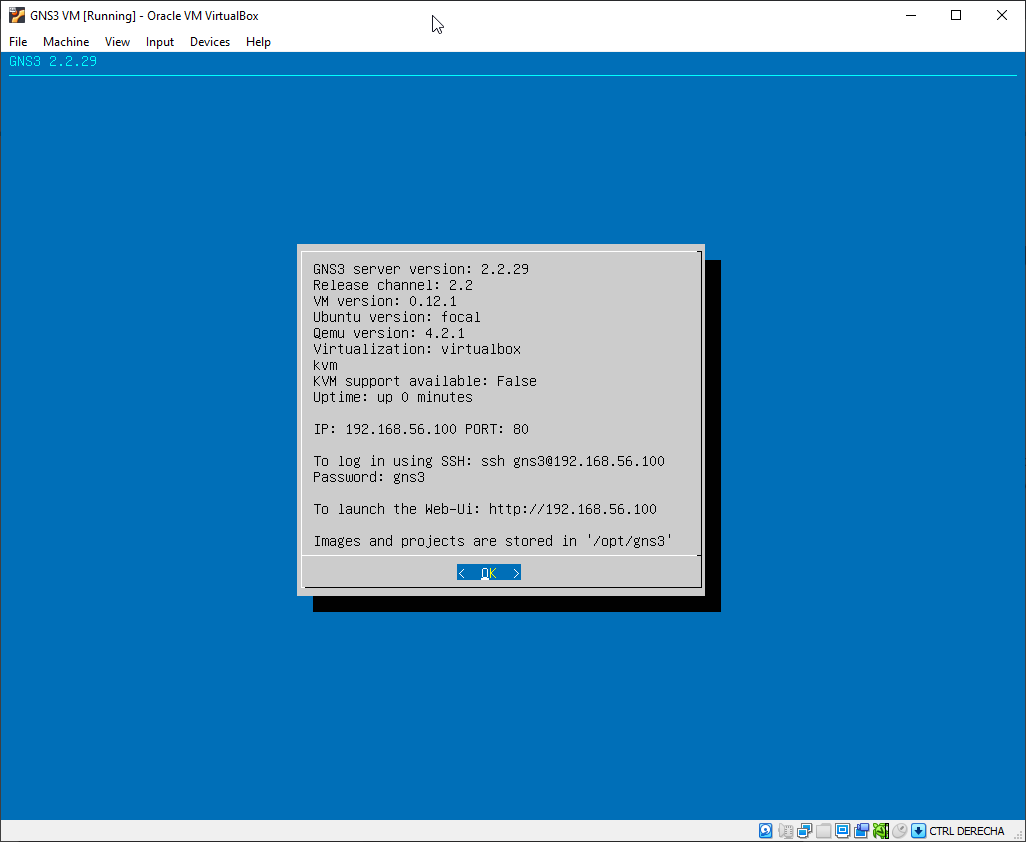
He uses GNS3 for the university, and after installing the latest version, which in this case is 2.2.29, it stopped working.
He had it configured to use the local Server and VirtualBox in Windows 10.
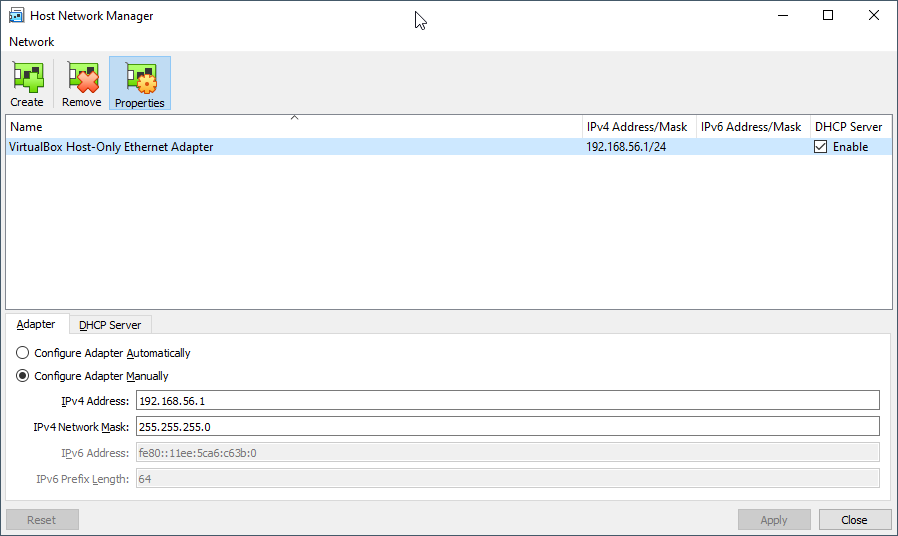
The first thing to check and to fix is the Ip address for Host Only.
If you use Linux or Mac, only certain Ip ranges can be used, or you’ll have to edit a config file inside /etc/vbox
So the first thing is to set an Ip Address in VirtualBox VM that will make you worry free.
So start VirtualBox VM directly, and when the VM boots, use the text menu application to Configure to a valid Ip from the range defined for Host Only.
You can check this in VirtualBox in File > Host Network Manager
In my initial test I picket this Ip for the VM:
192.168.56.100
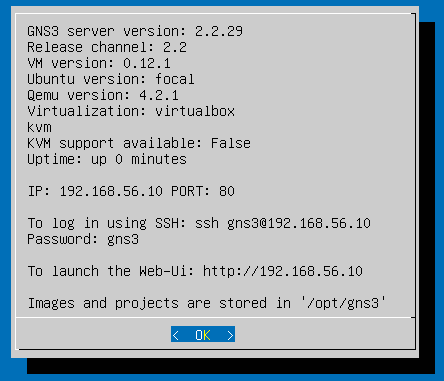
But using 192.168.56.100 can bring problems as the default DHCP Server is defined with this Ip, so I switched to:
192.168.56.10
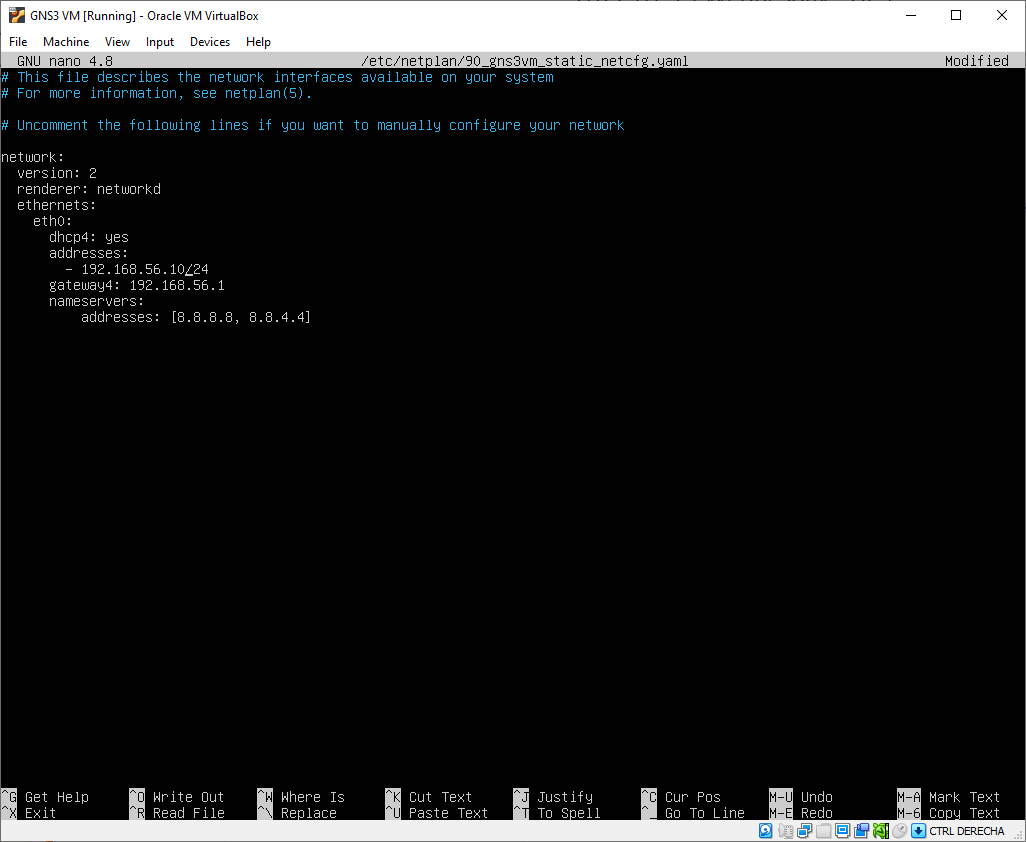
Press CTRL + X to save and exit.
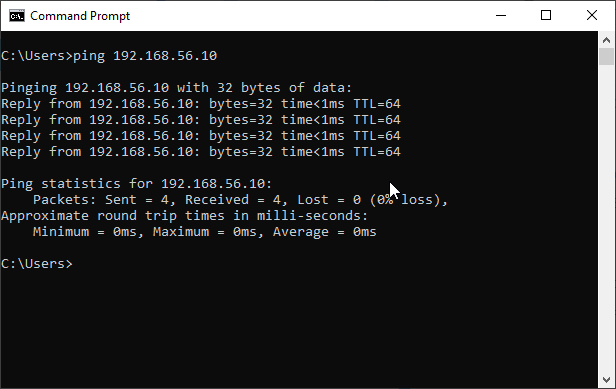
The VM will reboot automatically. Wait until it has booted and ping 192.168.56.10 from the Command Prompt.
Now, open a Windows Command Prompt or a Linux/Mac Terminal in you computer and ping the Ip:
You should also be able to see the web interface going to:
http://192.168.56.10
If it works then power off the VM, as we will start it automatically when running GNS3 main program (not from VirtualBox).
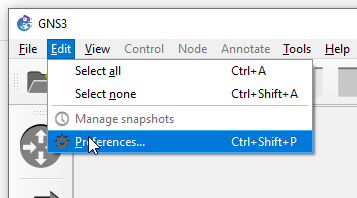
Now launch GNS3 program. Wait 30 seconds until it initializes and go to Edit > Preferences
Make sure you have the configuration like this:
Pay special attention to the Port for the GNS3 VM.
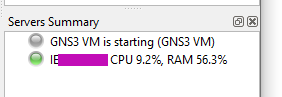
It seems like the main problem of my friend was that he was using a previous version, and he updated, and the settings from the previous version were kept. In his previous version he had configured the port 3080, but the new GNS 3 Server version 2.2.29 in the VM was using port 80, as you saw in my previous screenshots. So GNS3 was unable to connect to the VM.
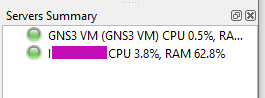
After fixing this, restart GNS3, stop the VM if was not automatically stopped, and start GNS3 again.
After one minute approx connecting, you’ll see it working fine.