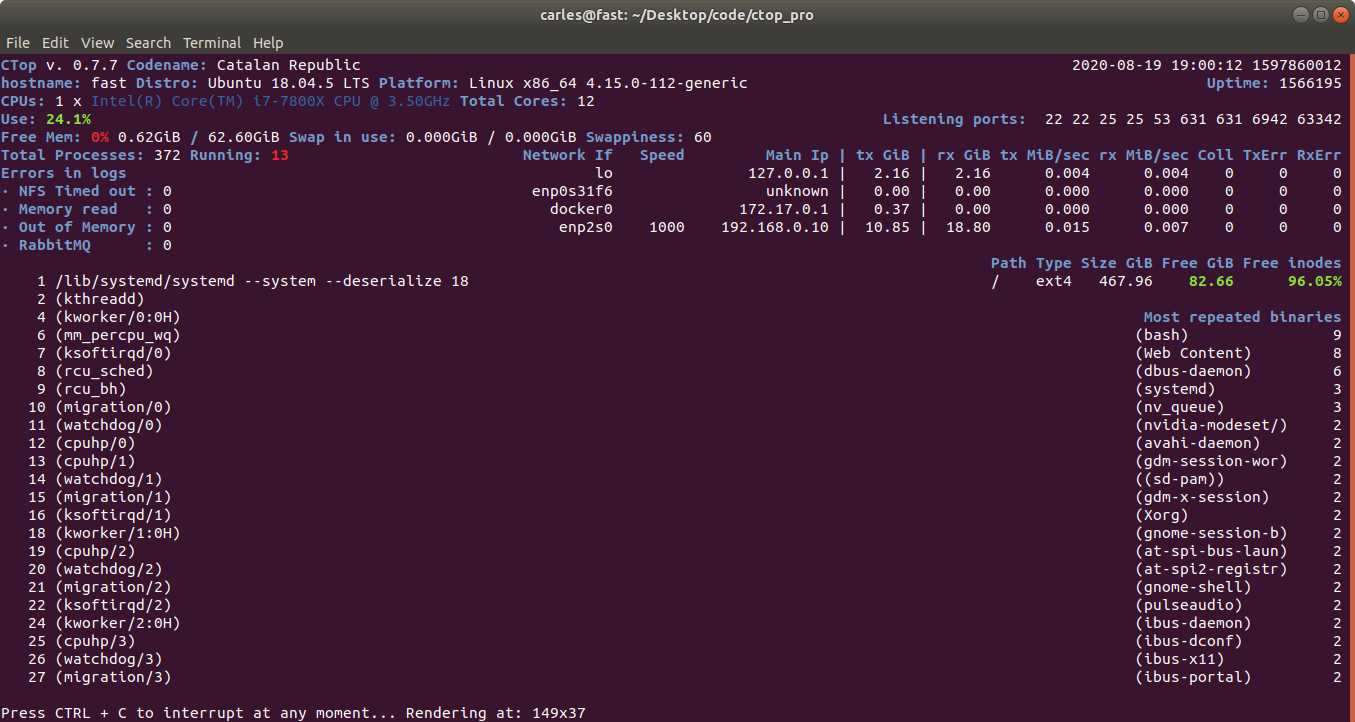
One of my colleagues showed me dstat, a very nice tool for system monitoring, and bandwidth of a drive monitoring. Also ifstat, as complement to iftop is very cool for Network too. This functionality is also available in CTOP.py
As I shared in the past news of the blog, I’m resuming my contributions to ZFS Community.
Long time ago I created some ZFS tools that I want to share soon as Open Source.
I equipped myself with the proper Hardware to test on SAS and SATA:
12G Internal PCI-E SAS/SATA HBA RAID Controller Card, Broadcom’s SAS 3008, compatible for SAS 9300-8I. This is just an HDA (Host Data Adapter), it doesn’t support RAID. Only connects up to 8 drives or 1024 through expander, to my computer. It has a bandwidth of 9,600 MB/s which guarantees me that I’ll be able to add 12 SAS SSD Enterprise grade at almost the max speed of the drives. Those drives perform at 900 MB/s so if I’m using all of them at the same time, like if I have a pool of 8 + 3 and I rebuild a broken drive or I just push Data, I would be using 12×900 = 10,800 MB/s. Close. Fair enough.
VANDESAIL Mini-SAS Cables, 1m Internal Mini-SAS to 4x SAS SATA Forward Breakout Cable Hard Drive Data Transfer Cable (SAS Cable).
SilverStone SST-FS212B – Aluminium Trayless Hot Swap Mobile Rack Backplane / Internal Hard Drive Enclosure for 12x 2.5 Inch SAS/SATA HDD or SSD, fit in any 3x 5.25 Inch Drive Bay, with Fan and Lock, black
Terminator is here. I ordered this T-800 head a while ago and finally arrived.
Finally I will have my empty USB keys located and protected. ;)
I tried to continue following it since I left Sanmina. ZFS is really an amazing Software and it’s lead by an amazing Community of super cool Engineers and companies. I would like to continue contributing ASAP.
I bought some new hard drives in order to work a bit on this. You don’t need to have dedicated hardware if you want to test features. You can run in a VirtualBox or VMWare Workstation.
I received more books about DevOps and Python
None is perfect. I see flaws in all of them and bad architecture practices*, however from all I learn interesting things.
You know, I study every day. At least 30 minutes, after work. As part of my healthy routines.
But I also study and learn during the work, as we have time available for this.
I’m very fortunate that Blizzard gives me time every day to study. That’s amazing. They also send us to events paying the ticket, travel, hotel, expenses… now with covid-19 we only go to virtual events, but the company still pay for this and give free days. Is a very nice company.
I continue having purchases of my book, and I’m very happy about that. I’m working on improving it and providing more contents and samples going from the scratch, with step by step code samples. From spaghetti code reading CSV files, to OOP with Full Coverage.
My application for a Higher degree Computer Science Cloud Computing (Level 8) has been accepted. The Irish government pays me 90% of the degree, and Blizzard will pay me the other 10% after I pass the first year course.
I’m really grateful to this beautiful country, Ireland.
Having an Irish degree is something that brings me an special illusion.
I have updated CTOP.py with some interesting features
It allows to pass a fixed width and height for the terminal render. That’s very useful when you run CTOP in a Docker non interactive session, or from a Cron, with the –iterations=1 so the output can be captured programmatically.
Jetbrains has provided me with a Free License of all their products, in order to support my work in Open Source projects. That’s very nice. I’m using now mainly PyCharm and PhpStorm.
At the beginning of the covid-19 I wrote a simulator in Python. That’s why I was able to anticipate that the number of cases and deaths would be very much higher when nobody around me knew what was going to happen. My first simulations were simple, and the algorithms were growing in complexity until I had a full rich Object Oriented modeler. Maybe I’ll write an article about this someday.
I studied the evolution of several countries and I was working with simulations in Spain until their government started blocking the information and stop providing transparent and accurate metrics.
I’m seeing how the covid is affecting and transforming several kind of business:
Meetup.com I see meetups with more than 1,000 users closing, as they are no meeting anymore
Airlines, obviously
Hotels, offering less services
Metasearchers and OTAs (Online travel agencies)
I can imagine the impact on airbnb
Discos, nightclubs are closing doors
Restaurants, they will lose the Christmas season (with families and companies doing lunch and dinners)
At the same time, other companies are hitting records in sales
Videogames companies
Hardware is being sold, to accommodate WFH and remote working.
Companies like Amazon or Overstock.com are delivering well where people before were buying into stores.
VPN solutions for Remote Working are being implemented in those places that had not enabled Remote Working.
After doing a Masterclass to some colleagues about Refactor, Code Reliability, Quality, The non-happy path and Unit Testing, I’m preparing some contents that I’ll publish to the Community soon. So far I created this repo, where I added the source code for lesson 0: starting to program in Python videos that I created few months ago to help beginners.
I also added some contents to lesson 1, where we refactor pure spaghetti code with no error control, to something more elaborated with unit testing and full code coverage. Still procedural, but I will jump to next class in two weeks, where we will move to OOP and Dependency Injection.
If you use ZFS with spinning drives and you share iSCSI, you will need to use a SLOG device for ZIL otherwise you’ll see your iSCSI connections interrupted.
What is a ZIL?
ZIL: Acronym for ZFS Intended Log. Logs synchronous operations to disk
SLOG: Acronym for (S)eperate (LOG) Device
In ZFS Data is first written and stored in-memory, then it’s flushed to drives. This can take 10 seconds normally, a bit more in certain occasions.
So without SLOG it can happen that if a power loss occurs, you may loss the last 10 seconds of Data submitted.
The SLOG device brings security that if there is a power loss, after remounting the pool, the information in the SLOG, acknowledged to iSCSI clients, is not lost and flushed to the Hard drives conforming the pool. Basically this device keeps the writings that come from network and flushes to the Hard drives and then clears this data from the SLOG.
The SLOG also allows ZFS to sort how the transactions will be written, to do in a more efficient way.
Normally I’m describing configurations with a fast device for SLOG ZIL, like one or a pair of NVMe drive or SAS SSD, most commonly in mirror a pool of 12 HDD drives or more SAS preferentially, maybe SATA, with 14TB or more each.
As the SLOG device will persist your Data if there is a power off, and submit to the pool the accepted transactions, it is clear that you cannot spare yourself from having a SLOG ZIL device (or better a mirror). It is needed to bring security when remotely writing.
But what happens if we have a kind of business where we don’t care about that the last 10 seconds writings may be lost? (ZFS will never get corrupted due to its kinda journal system), just because we are filling a Server the fastest possible, migrating from another, or because we are running workouts that can be retaken is some data is lost… do we really need to have the speed constrain of an SSD?. Examples are a Hadoop node, or a SETI@Home client. Tasks will be resumed if something failed.
Or maybe you fill your servers with sync=always, so writing it’s safe, and then you use them only for read, or for a Statics Internet Caches (CDNs like Akamai, Cloudfare…) or you use it for storing Backups, write once read many. You don’t really need the constraint speed of a ZIL running at 800 MB/s.
Let me put in another way, we have 2 NIC 100Gbps, in bonding, so 200Gbps (equivalent to (25GB/s Gigabytes per second), 90 HDD drives that can work in parallel up to 250 MB/s each (22.5GB/s) and our Server has a pair or SAS SSD ZIL in mirror, that writes at 900 MB/s (Megabytes per second, so 0.9 GB/s), so our bottleneck or constraint is the SLOG ZIL.
Adding one RAMDISK, or better two RAMDISKs in mirror, we can get to much more highers speeds. I cannot tell you how much, but in my tests with regular configurations (8D+3P) I was achieving more than 2 GB (Gigabytes) per second sustained of Data to the pool. Take in count that the speed writing to the pool does not only depend on the speed on the ZIL, and the speed of the HDD spinning drives (slow, between 100 and 250 MB/s), but also about the config of the pool (number of vdevs, distributions of data and parity drives) and the throughput of your IOC (Input Output Controller), and the number of them.
Live real scenarios use to be more in the line of having 2x10GbpE cards, combined in bonding making 20Gbps, so being able to transmit 2.5GB/s. So to get the max speed of our Network this Ramdrive will do it. Also NVMe devices used as ZIL will do it.
The problem with the NVMe is that they are connected to the PCI Express bus, and so they are not hot swap. If one dies, you cannot replace without stopping the Server.
The problem with the SSD is that they are not made for writing, they will die, so you need at least a mirror and for heavy IO I strongly recommend you to go with Enterprise grade SAS SSD drives. Those are made to last.
SSD Enterprise grade are double price versus one common SSD, but that peace of mind and extra lasting is worth it. And you don’t need a very big device, only has to hold 10 seconds of Data at max speed. So if you can ingest Data through the Network at 20 Gbps (2.5GB/s) you only need approximately 25 GB of space of the SLOG. 50 GB if you want to be more than safe.
Also you can use partitions instead of complete devices for the SLOG (like for the ZFS pool, where you can add complete drives, or partitions).
If you write locally, and you have 4 IOC’s capable of delivering 8 GB/s each, and you write to a Dataset to the pool, and not to a ZVOL which are slow by nature, you can get astonishing combined speed writing to the drives. If you are migrating a Server to another new, where you can resume if power goes down, then it’s safe to disable sync (set async) while this process runs, and turn sync on when going live to production. If you use async you don’t need to use a SLOG.
4 IOC’s able to deliver 8 GB/s are enough to provide sustained speed to 90 HDD SAS drives. 90x200MB/s=18GB/s required at max speed or 90x250MB/s=22.5GB/s.
The HDD drives provide different speeds in the inner and in the outer areas of the drive, so normally those drives up to 8TB perform between 100 and 200 MB/s, and the drives from 10TB SAS to 14TB SAS perform between 145 and 250 MB/s. I cannot tell about the 16 TB as I’ve not tested them.
The instructions to set a Ramdrive and to assign to a pool are like this:
#!/usr/bin/env bash
RAM_GB=1
RAM_DRIVE_SIZE_IN_BYTES=$((RAM_GB*1048576))
if [[ $(id -u) -ne 0 ]] ; then
echo "Please run as root"
exit 1
fi
modprobe brd rd_nr=1 rd_size=${RAM_DRIVE_SIZE_IN_BYTES} max_part=0
echo "Use it like: zpool add carlespool log ram0"
If you created more than one Ramdisk you can add a mirror for the slog to the pool with:
You can partition the Ramdrive and add a partition but we want to add the whole ram device.
Obviously you cannot put other things to that Ramdisk (like the Metadata) as you need persistence for that.
In any case, please, avoid JBODs loaded of big HDD drives with low bandwidth micro SATA like 3Gbps per channel to the Server, and RAID. The bandwidth is too low. Your rebuilds will take forever.
With ZFS you’ll resilver (rebuild) only the actual data, not the whole drive.
My Team in The States report an issue with a Red Hat iSCSI Initiator having issues connecting to a Volume exported by a ZFS Server.
There is an issue on GitLab.
As I always do when I troubleshot a problem, I create a forensics post-mortem document recording everything I do, so later, others can learn how I fix it, or they can learn the steps I did in order to troubleshoot.
Please note: Some Ip addresses have been manually edited.
2019-08-09 10:20:10 Start of the investigation
I log into the Server, with Ip Address: xxx.yyy.16.30. Is an All-Flash-Array Server with RHEL6.10 and DRAID v.08091350.
Htop shows normal/low activity.
I check the addresses in the iSCSI Initiator (client), to make sure it is connecting to the right Server.
[root@Host-164 ~]# ip addr list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:25:90:c5:1e:ea brd ff:ff:ff:ff:ff:ff
inet xxx.yyy.13.164/16 brd xxx.yyy.255.255 scope global eno1
valid_lft forever preferred_lft forever
inet6 fe80::225:90ff:fec5:1eea/64 scope link
valid_lft forever preferred_lft forever
3: eno2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN qlen 1000
link/ether 00:25:90:c5:1e:eb brd ff:ff:ff:ff:ff:ff
4: enp3s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 24:8a:07:a4:94:9c brd ff:ff:ff:ff:ff:ff
inet 192.168.100.164/24 brd 192.168.100.255 scope global enp3s0f0
valid_lft forever preferred_lft forever
inet6 fe80::268a:7ff:fea4:949c/64 scope link
valid_lft forever preferred_lft forever
5: enp3s0f1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 24:8a:07:a4:94:9d brd ff:ff:ff:ff:ff:ff
inet 192.168.200.164/24 brd 192.168.200.255 scope global enp3s0f1
valid_lft forever preferred_lft forever inet6 fe80::268a:7ff:fea4:949d/64 scope link
valid_lft forever preferred_lft forever
I see the luns on the host, connecting to the 10Gbps of the Server:
/dev/sdg1 on /mnt/large type ext4 (ro,relatime,seclabel,data=ordered)
Lsblk shows that /dev/sdg is not present:
[root@Host-164 ~]# lsblk
NAME
MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 119.2G 0 disk
├─sda1 8:1 0 500M 0 part /boot
└─sda2 8:2 0 118.8G 0 part
├─rhel-swap 253:0 0 11.9G 0 lvm [SWAP]
└─rhel-root 253:1 0 106.8G 0 lvm /
sdb 8:16 0 100G 0 disk
sdc 8:32 0 100G 0 disk
sdd 8:48 0 100G 0 disk
sde 8:64 0 100G 0 disk
sdf 8:80 0 100G 0 disk
And as expected:
[root@Host-164 ~]# ls -al /mnt/large
ls: reading directory /mnt/large: Input/output error
total 0
I see that the Volumes appear to not having being partitioned:
[root@Host-164 ~]# fdisk /dev/sdf
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0xddf99f40.
Command (m for help): p
Disk /dev/sdf: 107.4 GB, 107374182400 bytes, 209715200 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xddf99f40
Device Boot
Start
End
Blocks Id System
Command (m for help): q
I create a partition and format with ext2
[root@Host-164 ~]# mke2fs /dev/sdb1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26214144 blocks
1310707 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
I mount:
[root@Host-164 ~]# mount /dev/sdb1 /mnt/vol1
I fill the volume from the client, and it works. I check the activity in the Server with iostat and there are more MB/s written to the Server’s drives than actually speed copying in the client.
I completely fill 100GB but speed is slow. We are working on a 10Gbps Network so I expected more speed.
I check the connections to the Server:
[root@obs4602-1810 ~]# netstat | grep -v "unix"
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55300 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55298 ESTABLISHED
tcp 0 0 xxx.yyy.18.10:ssh xxx.yyy.12.154:57137 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55304 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55301 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55306 ESTABLISHED
tcp 0 0 xxx.yyy.18.10:ssh xxx.yyy.12.154:56395 ESTABLISHED
tcp 0 0 xxx.yyy.18.10:ssh xxx.yyy.14.52:57330 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55296 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55305 ESTABLISHED
tcp 0 0 xxx.yyy.18.10:ssh xxx.yyy.12.154:57133 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55303 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55299 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.176:57542 ESTABLISHED
tcp 0 0 192.168.10.10:iscsi-target 192.168.10.180:55302 ESTABLISHED
I see many connections from Host 180, I check that and another member of the Team is using that client to test with vdbench against the Server.
This explains the slower speed I was getting.
Conclusions
There was a local problem on the Host. The problems with the disconnection seem to be related to a connection that was lost (sdg). All that information was written to iSCSI buffer, not to the Server. In fact, that volume was mapped in the system with another letter, sdg was not in use.
Speed was slow due to another client pushing Data to the Server too
Windows clients with auto reconnect option are not reporting timeout reports while in Red Hat clients iSCSI connection timeouts. It should be increased
2020-03-10 22:16 IST TIP: At that time we were using Google suite and Skype to communicate internally with the different members across the world. If we had used a tool like Slack, and we had a channel like #engineering for example or #sanjoselab, then I could have paged and asked “Is somebody using obs4602-1810?“
1- Make sure the zfs file exists under zfs/contrib/initramfs/scripts/local-top/
if not exists, create a file called zfs under zfs/contrib/initramfs/scripts/local-top/ and add the following to that file:
#!/bin/sh PREREQ=”mdadm mdrun multipath”
prereqs() { echo “$PREREQ” }
case $1 in # get pre-requisites prereqs) prereqs exit 0 ;; esac
# # Helper functions # message() { if [ -x /bin/plymouth ] && plymouth –ping; then plymouth message –text=”$@” else echo “$@” >&2 fi return 0 }
udev_settle() { # Wait for udev to be ready, see https://launchpad.net/bugs/85640 if [ -x /sbin/udevadm ]; then /sbin/udevadm settle –timeout=30 elif [ -x /sbin/udevsettle ]; then /sbin/udevsettle –timeout=30 fi return 0 }
activate_vg() { # Sanity checks if [ ! -x /sbin/lvm ]; then [ “$quiet” != “y” ] && message “lvm is not available” return 1 fi
# Detect and activate available volume groups /sbin/lvm vgscan /sbin/lvm vgchange -a y –sysinit return $? }
I came with this solution when one of my 4U60 Servers had two slots broken. You’ll not use this in Production, as SLOG loses its function, but I managed to use one $40K USD broken Server and to demonstrate that the Speed of the SLOG device (ZFS Intented Log or ZIL device) sets the constraints for the writing speed.
The ZFS DRAID config I was using required 60 drives, basically 58 14TB Spinning drives and 2 SSD for the SLOG ZIL. As I only had 58 slots I came with this idea.
This trick can be very useful if you have a box full of Spinning drives, and when sharing by iSCSI zvols you get disconnected in the iSCSI Initiator side. This is typical when ZFS has only Spinning drives and it has no SLOG drives (dedicated fast devices for the ZIL, ZFS INTENDED LOG)
Create a single Ramdrive of 10GB of RAM:
modprobe brd rd_nr=1 rd_size=10485760 max_part=0
Confirm ram0 device exists now:
ls /dev/ram*
Confirm that the pool is imported:
zpool list
Add to the pool:
zpool add carles-N58-C3-D16-P2-S4 log ram0
In the case that you want to have two ram devices as SLOG devices, in mirror.
It is interesting to know that you can work with partitions instead of drives. So for this test we could have partitioned ram0 with 2 partitions and make it work in mirror. You’ll see how much faster the iSCSI communication goes over the network. The writing speed of the ZIL SLOG device is the constrain for ingesting Data from the Network to the Server.
Creating a partition bigger than 2TiB
Master Boot Record (MBR) based partitioning is limited to 2TiB however GUID Partition Table (GPT) has a limit of 8 ZiB.
That’s something very simply, but make you lose time if you’re partitioning big iSCSI Shares, or ZFS Zvols, so here is the trick:
[root@CTRLA-18 ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.6 (Maipo)
[root@CTRLA-18 ~]# parted /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
GNU Parted 3.1
Using /dev/zd0
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
Warning: The existing disk label on /dev/zd0 will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? y
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
(parted) mkpart primary 0GB 58.9TB
(parted) print
Model: Unknown (unknown)
Disk /dev/zd0: 58.9TB
Sector size (logical/physical): 512B/65536B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 58.9TB 58.9TB primary
(parted) quit
Information: You may need to update /etc/fstab.
[root@CTRLA-18 ~]# mkfs
mkfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
[root@CTRLA-18 ~]# mkfs.ext4 /dev/zvol/N58-C19-D2-P1-S1/vol54854gb
mke2fs 1.42.9 (28-Dec-2013)
....
[root@CTRLA-18 ~]# mount /dev/zvol/N58-C19-D2-P1-S1/vol54854gb /Data
[root@CTRLA-18 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 50G 2.5G 48G 5% /
devtmpfs 126G 0 126G 0% /dev
tmpfs 126G 0 126G 0% /dev/shm
tmpfs 126G 1.1G 125G 1% /run
tmpfs 126G 0 126G 0% /sys/fs/cgroup
/dev/sdp1 1014M 151M 864M 15% /boot
/dev/mapper/rhel-home 65G 33M 65G 1% /home
logs 49G 349M 48G 1% /logs
mysql 9.7G 128K 9.7G 1% /mysql
tmpfs 26G 0 26G 0% /run/user/0
/dev/zd0 54T 20K 51T 1% /Data
ZFS is unable to use a disk
Some times, after creating many pools ZFS may be unable to create a new pool using a drive that is perfectly fine. In this situation, the ideal is wipe the first areas of it, or all of it if you want. If it’s an SSD that is very fast:
dd if=/dev/zero of=/dev/sdc bs=1M status=progress
The status=progress will show a nice progress bar.
Filling a half Petabyte pool as fast as possible
To fill a 60 drives pool composed by 10TB or 14TB spinning drives, so more than half PB, in order to test with real data, you can use this trick:
First, write to the Dataset directly, that’s way much more faster than using zvols.
Secondly, disable the ZIL, set sync=disabled.
Third, use a file in memory to avoid the paytime of reading the file from disk.
Fourth, increase the recordsize to 1M for faster filling (in my experience).
You can use this script of mine that does everything for you, normally you would like to run it inside an screen session, and create a Dataset called Data. The script will mount it in /Data (zfs set mountpoint=/data YOURPOOL/Data):
#!/usr/bin/env bash
# Created by Carles Mateo
FILE_ORIGINAL="/run/urandom.1GB"
FILE_PATTERN="/Data/urandom.1GB-clone."
# POOL="N56-C5-D8-P3-S1"
POOL="N58-C3-D16-P3-S1"
# The starting number, if you interrupt the filling process, you can update it just by updating this number to match the last partially written file
i_COPYING_INITIAL_NUMBER=1
# For 75% of 10TB (3x(16+3)+1 has 421TiB, so 75% of 421TiB or 431,104GiB is 323,328) use 323328
# i_COPYING_FINAL_NUMBER=323328
# For 75% of 10TB, 5x(8+3)+1 ZFS sees 352TiB, so 75% use 270336
# For 75% of 14TB, 3x(16+3)+1, use 453120
i_COPYING_FINAL_NUMBER=453120
# Creating an array that will hold the speed of the latest 1 minute
a_i_LATEST_SPEEDS=(0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0)
i_POINTER_SPEEDS=0
i_COUNTER_SPEEDS=-1
i_ITEMS_KEPT_SPEEDS=60
i_AVG_SPEED=0
i_FILES_TO_BE_COPIED=$((i_COPYING_FINAL_NUMBER-i_COPYING_INITIAL_NUMBER))
get_average_speed () {
# Calculates the Average Speed
i_AVG_SPEED=0
for i_index in {0..59..1}
do
i_SPEED=$((a_i_LATEST_SPEEDS[i_index]))
i_AVG_SPEED=$((i_AVG_SPEED + i_SPEED))
done
i_AVG_SPEED=$((i_AVG_SPEED/((i_COUNTER_SPEEDS)+1)))
}
echo "Bash version ${BASH_VERSION}..."
echo "Disabling sync in the pool $POOL for faster speed"
zfs set sync=disabled $POOL
echo "Maximizing performance with recordsize"
zfs set recordsize=1M ${POOL}
zfs set recordsize=1M ${POOL}/Data
echo "Mounting the Dataset Data"
zfs set mountpoint=/Data ${POOL}/Data
zfs mount ${POOL}/Data
echo "Checking if file ${FILE_ORIGINAL} exists..."
if [[ -f ${FILE_ORIGINAL} ]]; then
ls -al ${FILE_ORIGINAL}
sha1sum ${FILE_ORIGINAL}
else
echo "Generating file..."
dd if=/dev/urandom of=${FILE_ORIGINAL} bs=1M count=1024 status=progress
fi
echo "Starting filling process..."
echo "We are going to copy ${i_FILES_TO_BE_COPIED} , starting from: ${i_COPYING_INITIAL_NUMBER} to: ${i_COPYING_FINAL_NUMBER}"
for ((i_NUMBER=${i_COPYING_INITIAL_NUMBER}; i_NUMBER<=${i_COPYING_FINAL_NUMBER}; i_NUMBER++));
do
s_datetime_ini=$(($(date +%s%N)/1000000))
DATE_NOW=`date '+%Y-%m-%d_%H-%M-%S'`
echo "${DATE_NOW} Copying ${FILE_ORIGINAL} to ${FILE_PATTERN}${i_NUMBER}"
cp ${FILE_ORIGINAL} ${FILE_PATTERN}${i_NUMBER}
s_datetime_end=$(($(date +%s%N)/1000000))
MILLISECONDS=$(expr "$s_datetime_end" - "$s_datetime_ini")
if [[ ${MILLISECONDS} -lt 1 ]]; then
BANDWIDTH_MBS="Unknown (too fast)"
# That sould not happen, but if did, we don't account crazy speeds
else
BANDWIDTH_MBS=$((1000*1024/MILLISECONDS))
# Make sure the Array space has been allocated
if [[ ${i_POINTER_SPEEDS} -gt ${i_COUNTER_SPEEDS} ]]; then
# Add item to the Array the first times only
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
i_COUNTER_SPEEDS=$((i_COUNTER_SPEEDS+1))
else
a_i_LATEST_SPEEDS[i_POINTER_SPEEDS]=${BANDWIDTH_MBS}
fi
i_POINTER_SPEEDS=$((i_POINTER_SPEEDS+1))
if [[ ${i_POINTER_SPEEDS} -ge ${i_ITEMS_KEPT_SPEEDS} ]]; then
i_POINTER_SPEEDS=0
fi
get_average_speed
fi
i_FILES_TO_BE_COPIED=$((i_FILES_TO_BE_COPIED-1))
i_REMAINING_TIME=$((1024*i_FILES_TO_BE_COPIED/i_AVG_SPEED))
i_REMAINING_HOURS=$((i_REMAINING_TIME/3600))
echo "File cloned in ${MILLISECONDS} milliseconds at ${BANDWIDTH_MBS} MB/s"
echo "Avg. Speed: ${i_AVG_SPEED} MB/s Remaining Files: ${i_FILES_TO_BE_COPIED} Remaining seconds: ${i_REMAINING_TIME} s. (${i_REMAINING_HOURS} h.)"
done
echo "Enabling sync=always"
zfs set sync=always ${POOL}
echo "Setting back recordsize to 128K"
zfs set recordsize=128K ${POOL}
zfs set recordsize=128K ${POOL}/Data
echo "Unmounting /Data"
zfs set mountpoint=none ${POOL}/Data
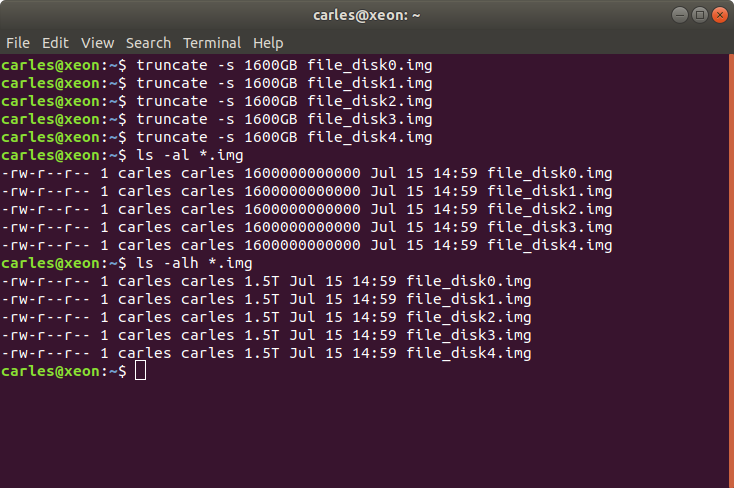
Creating a Sparse file that you can partition or create a loopback on it
I know, your laptop has 512GB of M.2 SSD or NVMe, so that’s it.
Well, you can create a sparse file much more bigger than your capacity, and use 0 bytes of it at all.
For example:
truncate -s 1600GB file_disk0.img
If the files are stored in / then you can add a loop device:
sudo losetup -f /file_disk0.img
I do with the 5 I created.
Then you can check that they exist with:
lsblk
or
cat /proc/partitions
The loop devices will appear under /dev/ now.
For some tests I did this in a Virtual Box Virtual Machine:
This is the history it happen to me some time ago, and so the commands I used to troubleshot. The purpose is to share knowledge in a interactive way. There are some hidden gems that you’ll acquire if you have the patience to go over all the document and read it all…
I had qualified Intel Xeon single processor platform to run my DRAID (ZFS Declustered RAID) project for my employer.
The platforms I qualified were:
1) single processor for Cold Storage (SAS Spinning drives): 4U60, newest models 4602
2) for multiprocessor: the 4U90 (90 Spinning drives) and Flash: All-Flash-Arrays.
The amounts of RAM I was using for my tests range for 64GB to 384GB.
Somebody in the company, at executive level, assembled an experimental config that was totally new for us and wanted to try by their own. It was the 4602 with multiprocessor and 32GB of RAM.
When they were unable to make it work at the expected speed, they required me to troubleshot and to make it work.
The 4602 single processor had two IOC (Input Output Controller, LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) ), while the 4602 double processor had four IOC, so given that each of those IOC can perform at peaks of 6GB/s, with a maximum total of 24 GB/s, the performance when reading/writing from all the drives should be better.
But this Server was returning double times for Rebuilding, respect the single processor version, which didn’t make any sense.
I had to check everything. There was the commands I ran:
Check the upgrade of the CPU:
htop
lscpu
Changing the Zoning.
Those Servers use SAS drives dual ported, which means that two different computers can be connected to the same drive and operate at the same time. Is up to you to make sure you don’t introduce corruption. Those systems are used mainly for HA (High Availability).
Those Systems allow to be configured in different zoning modes. That’s the way on how each of the two servers (Controllers) see the disk. In one zoning each Controller sees only 30 drives, in another each IOC sees all the drives (for redundancy but performance constrained to 1 IOC Speed).
The config I set is each IOC will see 15 drives, so each one of the 4 IOC will have 6GB/s for 15 drives. Given that these spinning drives perform in the outtermost part of the cylinder at 265MB/s, that means that at maximum speed one IOC will be using 3.97 GB/s, will say 4GB/s. Plenty of bandwidth.
Note: Spinning drives have different performance depending on how close you’re to the cylinder. In the innermost part it goes under 145 MB/s, and if you read all of those drive sequentially with dd it will return an average speed of 145 MB/s.
With this command you can sive live how it performs and the average read speed in real time. Use skip to jump to that position (relative to bs) in the drive, so you can test directly the speed at the innermost close to the cylinder part of t.
dd if=/dev/sda of=/dev/null bs=1M status=progress
I saw that the zoning was not right one, so I set it correctly:
The sleeps after rebooting the expanders are recommended. Rebooting the Operating System too, to avoid problems with some Software as the expanders changed live.
If you have ZFS pools or workloads stop them and export the pool before messing with the expanders.
In order to check to which drives is connected each IOC:
I do this for all the drives at the same time and with iostat:
iostat -y 1 1
I check the status of the memory with:
slabtop
free
htop
I checked the memory and htop during a Rebuild. Memory was more than enough. However CPU usage was higher than expected.
The red bars in the image correspond to kernel processes, in this case is the DRAID Rebuild. I see that the load is higher than the usual with a single processor.
I capture all the parameters from ZFS with:
zfs get all
All this information is logged into my forensics document, so later can be checked by my Team or I can share with other Architects or other members of the company. I started this methodology after I knew how Google do their SRE forensics / postmortem documents. Also for myself is useful for the future to have a log of the commands I executed and a verbose output of the results.
I install the smp_utils
yum install smp_utils
Check things:
ls -al /dev/bsg/
total 0drwxr-xr-x. 2 root root 3020 May 22 10:16 .
drwxr-xr-x. 20 root root 8680 May 22 10:16 ..
crw-------. 1 root root 248, 76 May 22 10:00 1:0:0:0
crw-------. 1 root root 248, 126 May 22 10:00 10:0:0:0
crw-------. 1 root root 248, 127 May 22 10:00 10:0:1:0
crw-------. 1 root root 248, 136 May 22 10:00 10:0:10:0
crw-------. 1 root root 248, 137 May 22 10:00 10:0:11:0
crw-------. 1 root root 248, 138 May 22 10:00 10:0:12:0
crw-------. 1 root root 248, 139 May 22 10:00 10:0:13:0
[...]
There are some errors, and I check with the Hardware Team, which pass a battery of tests on the machine and say that the machine passes. They tell me that if the errors counted were in order of millions then it would be a problem, but having few of them is usual.
My colleagues previously reported that the memory was performing well, and the CPU too. They told me that the speed was exactly double respect a platform with one single CPU of the same kind.
Even if they told me that, I ran cmips tests to make sure.
git clone https://github.com/cmips/cmips_bin
It scored 16,000. The performance was Ok in general terms but the problem is that I didn’t have a baseline for that processor in single processor, so I cannot make sure that the memory bandwidth was Ok. The performance was less that an Amazon c3.8xlarge. The system I was testing is a two processor system, but each CPU is cheap, around USD $400.
Still my gut feeling was telling me that this double processor server should score more.
lscpu
[root@DRAID-1135-14TB-2CPU ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
Stepping: 1
CPU MHz: 2299.951
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4199.73
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts spec_ctrl intel_stibp
I check the memory configuration with:
dmidecode -t memory
I examined the results, I see that the processor can only operate the DDR4 ECC 2400 Memory at 2133 and… I see something!. This Controller before was a single processor with 2 Memory Sticks of 16GB each, dual rank.
I see that now I have the same number of sticks in that machine, but I have two CPU!. So 2 Memory sticks in total, for 2 CPU.
That’s no good. The memory must be in pairs and in the right slots to get the maximum performance.
1 memory module for 1 CPU doesn’t allow to have Dual Channel and probably is affecting the performance. Many Servers will not even boot if you add an odd number of memory sticks per CPU.
And many Servers can operate at full speed only if all the banks are filled.
I request to the Engineers in Silicon Valley to add 4 modules in the right slots. They did, and I repeated the tests and the performance was doubled then.
After some days I had some time with the machine, I repeated the test and I got a CMIPS Score of around 20,000.
Multiprocessor world is far more complicated than single processor. Some times things can work not as expected, and not be evident, for example cache pipeline can act diferent for a program working in multiprocessor and single processor. Or the QPI could be saturated.
After this I shared my forensics document with as many Engineers as I could, so they could learn how I did to troubleshot the problem, and what was the origin of it, and I asked them to do the same so we can track their steps and progress if something needs to be troubleshoot.
After proper intensive testing the Server was qualified. Lesson here is that changes cannot be commited quickly, need their time.
Ok, as you know I work with ZFS, DRAID, Erasure Coding… and Cold Storage.
I work with big disks, SAS, SSD, and NVMe.
Sometimes I need to conduct some tests that involve filling completely to 100% the pool.
That’s very slow having to fill 14TB drives, with Servers with 60, 90 and 104 drives, for obvious reasons. So here is a handy script for partitioning those drives with a small partition, then you use the small partition for creating a pool that will fill faster.
1. Get the list of drives in the system
For example this script can help
If your drives had a previous partition this script will detect them, and will use only the drives with wwn identifier.
Warning: some M.2 booting drives have wwn where others don’t. Use with caution.
2. Identify the boot device and remove from the list
3. Do the loop with for DRIVE in $DRIVES or manually:
Please, note:
Nothing is exactly the same as a physical disk pull.
A physical disk pull can trigger errors by the expander that will not be detected just emulating.
Hardware failures are complex, so you should not avoid testing physically.
If your company has the Servers in another location you should request them to have Servers next to you, or travel to the location and spend enough time hands on.
A set of commands very handy for simulating a physical drive pull, when you have not physical access to the Server, or working within a VM.
To delete a disk (Linux stop seeing it until next reboot/power cycle):
for host in /sys/class/scsi_host/host*; do echo '- - -' > $host/scan; done
Disabling the port in the expander
This is more like physically pulling the drive.
In order to use the commands, install the package smp_utils. This is now
installed on the 4602 and the 4U60.
Ok, so I lend one of my Servers to two of my colleagues in The States, that required to prepare some test for a customer. I always try to be nice and to stimulate sales across the organizations I help, so if they need a Server for a PoC and demo to a customer, they know they can count on me.
It is important to remark that the Servers I was using had two motherboards, with their CPU and RAM, and Dual Port SAS drives. We had those Servers so we can implement High Availability. The Dual Port SAS allow two different computers or IO controllers to access the same drive at the same time.
I work with Declustered RAID, DRAID, and ZFS.
The Server was a 4U90, so a 4U Server with 90 SAS3 spinning drives and 4 SSD. Drives are Dual Ported, and two Controllers (motherboard + CPU + RAM) have access simultaneously to the drives for HA.
After their tests my colleagues, returned me the Server, and I needed to use it and my surprise was when I tried to provision with ZFS and I encountered problems. Not much in the logs. Please note I was using only one node (or controller), and the other was not in use but they ask me to keep the OS and the data (in 2xMD drive). I shutdown the node A after the Engineers in San Jose powered the Server off, so only my node was working.
After doing this for all I try to provision and… surprise! does not work. /dev/md127 has respawned like in the old times from Doom video game.
I check the mdmonitor service and even disable it.
systemctl disable mdmonitor
I repeat the process.
And /dev/md127 appears again, using another device.
At this point, just in case, I check the other controller, which should be powered off.
Ok, it was on. With different Ip, so it was not answering to ping, but I still had access to BMC//IPMI. After confirming with my colleagues that I can shutdown that node (they did not turn it on apparently) I launch the poweroff command, and repeat, same!.
I see that the poweroff command on the second Controller is doing a reboot, not poweroff. Is a Firmware issue I find. So I access to the Linux from the management tool and I launch the halt command that makes it not respond to the ping anymore.
I repeat the process, and still the ghost md array appears there, and blocks me from doing my zpool create.
The /etc/mdadm.conf file did not exist (by default is not created).
I try a more aggressive approach:
DRIVES=`cat /proc/partitions | grep 3907018584 | awk '{ print $4; }'`
for DRIVE in $DRIVES; do echo "Trying /dev/${DRIVE}1"; mdadm --examine /dev/${DRIVE}1; done
Ok. And destruction time:
for DRIVE in $DRIVES; do echo "Trying /dev/${DRIVE}"; wipefs -a -f /dev/${DRIVE}; done
for DRIVE in $DRIVES; do echo "Trying /dev/${DRIVE}1"; mdadm --zero-superblock /dev/${DRIVE}1; done
Apparently the system is clean, but still I cannot provision, and /dev/md127 respawns and reappears all the time.
After googling and not finding anything about this problem, and my colleagues no having clue about what is causing this, I just proceed with a simple solution, as I need the Server for my company completing the tests in the next 24 hours.
So I create the file /etc/mdadm.conf with this content:
[root@draid-08 ~]# cat /etc/mdadm.conf
AUTO -all
After that I rebooted the Server and I saw the infamous /dev/md127 is not there and I’m able to provision.
I share the solution as it may help other people.
The most straightforward procedure would had been reinstalling clean the OS, but this operation is very slow when simulating a Virtual CD remotely, so it was worth fixing that as OS level, as I save one day delaying my work.