For all my friends and followers, I started to translate my radio space “El nou món digital” (in Catalan) to English “The New Digital World”. I cover Science, Technology, Entertainment and Video games.
I decided to create a Jenkins Pipeline to deploy any updates to this pages and I updated it a bit at least to provide the most common information searched.
Don’t expect anything fancy at Front End level. :)
Cloud
I created a video about how to provision a Ubuntu Droplet in Digital Ocean.
It’s just for beginners, or if you used other CSP’s and you wonder how Digital Ocean user interface is.
It is really easy, to be honest. Amazon AWS should learn from them.
I also created another about how to provision using User Data Cloud Init feature:
This version fixes few bugs, and adds better Unit Testing Code Coverage, and is integrated with jenkins (provides Jenkinsfile and a Dockerfile ready to automate the testing pipeline)
Sudo ku solver, Sudoku solver in Python, and Engineering solving problem approach
I’ve created this video explaining my experience writing a program to solve two impossible, very annoying Sudokus. :)
We have released World of Warcraft Dragonflight Alpha.
In the sync meetings I lead with Wow SRE and product Team I was informed that streaming would be open. Myself I was granted to stream over twitch, but so far I didn’t want to stream video games in my engineering channels. It’s different kind of audiences IMO. Let me know if you would like to get video game streams in my streaming channels.
Lich King
Humor
If you have been in a madness of Servers of a Cluster getting irresponsible and having to cold reboot them from remote hands iDracs or similar, you know why my friends sent me this image :D
I’m Catalan. In 1936 the fascist military leaded by franco raised in arms against the elected government of the Spanish Republic. The Italian and nazi German fascist in power bombed the Catalan population. Hundreds of thousands of innocent citizens were assassinated and millions of Catalan and Spaniards had to exile. The sons of those that were ruling with the dictator have been insisting in naming it a “civil war”, but it was the military lead by a fascist, revolting against the legitimate Republic and ending a democracy.
The dictatorship lasted until 1975, when the dictator died in the bed. The effects of the repression never abandoned Catalonia, and nowadays in Catalonia people is still detained by the Spanish police for talking the Catalan language in front of them, and our Parliament decisions are cancelled by the Spanish courts, for example to force the exit of a President of Catalonia that they didn’t like, or to force the Catalan schools to teach 25% of the time in Spanish attacking the Catalan teaching system.
During WW2 millions of Jews were mass murdered, also people from all the nations were assassinated.
Russian population suffered a lot also fighting the nazis.
Now we have to see how Russia’s army is invading Ukraine and murdering innocent citizens.
That’s horrible.
I know Engineers from Ukraine. Those guys were doing great building wealthy based on knowledge and working well for companies across the world. Now these people are being killed or Engineers, amongst all the brave population, are arming themselves to fight the invasion. Shells destroy beautiful cities and population are starving, and young soldiers from both sides will never be seen again by their mothers.
Let music play in solidarity with Ukraine. First is a Catalan group. Second is a famous Irish band in this epic song dedicated to the brave International Brigades, volunteers that fought the fascism in Spain and in Catalonia trying to make a better world.
The Blog
I’ve updated the SSL Certificate. The previous one I bought was issued for two years, and I renewed as it was due to expire.
Honestly, my ego was flattered. It is a lot of reputation.
Although in the past I got an offer from another monstrously big editorial to publish world wide my book Python 3 Combat Guide and I also rejected, and an offer from a digital learning platform to create an interactive course from this same book.
I’ve rejected it again this time.
If you are curious, this is what I answered to them:
Hi XXXX,
I'm well, thank you. I hope you are doing well too.
Thanks for taking the time to explain your conditions to me.
I feel flattered by your editorial thinking about me. I respect your brand, as I mentioned, as I own several of your titles.
However, I have to refuse your offer.
Is not the first time an editor has offered to publish one or more of my books. For all over the world, with much higher economic expectations.
I'll tell you why I love being at LeanPub:
1- I own the rights. All of them.
2- I can publish updates, and my readers get them for free. As I add new materials, the value is maximized for my readers.
3- I get 80% of the royalties.
4- If a reader is not happy, they can return the book for 60 days.
5- I can create vouchers and give a discount to certain readers, or give for free to people that are poor and are trying to get a career in Engineering.
The community of readers are very honest, and I only got 2 returns. One of them I think was from an editorial that purchased the book, evaluated it, and they contacted me to publish it, and after I rejected they applied for the refund.
I teach classes, and I charge 125 EUR per hour. I can make much more by my side than the one time payment you offer. The compensation for the video seems really obsolete.
Also, I could be using Amazon self publishing, which also brings bigger margins than you.
So many thanks for your offer. I thought about it because of the reputation, but I already have a reputation. I've thousands of visits to my tech blog, and because of the higher royalties, even if I sell less books through LeanPub it is much more rewarding.
Thanks again and have a lovely day and rest of the week.
Best,
Carles
The provisioning in Amazon AWS through their SDK is a book I’m particularly proud, as it empowers the developers so much. And I provide source code so they can go from zero to hero, in a moment. Amazon should provide a project sample as I do, not difficult to follow documentation.
Teaching / Mentoring
As I was requested, I’ve been offering advice and having virtual coffees with some people that recently started their journey to become Software Engineers and wanted some guidance and advice.
It has been great seeing people putting passion and studying hard to make a better future for themselves and for their families.
I’ll probably add to the blog more contents for beginners, although it will continue being a blog dedicated to extreme IT, and to super cool Engineering skills and troubleshooting.
For my regular students I have a discord space where we can talk and they can meet new friends studying or working in Engineering.
Free Resources
This github link provides many free books in multiple languages:
Zoom can zoom the view. So if they are sharing their screen, and font is too small, you can give a relax to your eyes by using Zoom’s zoom feature. It is located in View.
My health
After being in the hospital in December 2021, with risk for my life, and after my incredible recuperation, I’ve got the good news that I don’t need anymore 2 of the 3 medicines I was taking in a daily basis. It looks well through a completely recovery thanks to my discipline, doing sport every day several times, and the fantastic Catalan doctors that are supporting me so well.
Since they found what was failing in me, and after the emergency treatments I started to sleep really well. All night. That’s a privilege that I didn’t have for long long time.
Humor
Sad but true history. How many super talented Engineers have been hired and then they were given a shitty laptop/workstation super slow? That happened to me when I was hired by Volkswagen IT: gedas. I was creating projects for very big companies and I calculated that I was wasting 2 hours of my time compiling. The computer did not had enough RAM and was using swap.
Equitas Health helps thousands of HIV-positive in Ohio, Dayton and Columbus.
Thousands more are reached with our prevention, testing, and other services. We are excited about embracing our expanded mission as a strategic step to further that legacy and its reach by providing care for all – with a focus on a safe and open space and highest quality healthcare for the LGBTQ community and others who are medically underserved.
I did my donation following a post by Terra Field, a former colleague at Blizzard and later leading Netflix’s Trans *ERG, but I didn’t see that she organized a gofund campaign, so I donated again :)
As I saw that there is a lack of clarity in the articles about this theme.
I also provided two alternatives ways, one pure Python3 and the other Bash based (grep awk tr)
Books
The books I publish in LeanPub have two prices, the suggested price, which is the price I consider the right price for the book, and the minimum price, which is the minimum price I authorized a reader can pay to have it.
You can buy it for the minimum price. You know better than anyone your economy.
So when a reader buys one of my books for the suggested price, instead of the minimum price, it’s really showing how they appreciate may work.
So thanks for all the support and appreciation you show!. :)
One of the motives I chose Leanpub platform is because I think is fair. No DRM, no BS. And the reader can ask for a refund within 45 days if they don’t like the book. It also makes very happy seeing that I don’t have any refunds. I appreciate it as a token of the usefulness of my work. Thanks. :)
Updates to Docker Combat File book (v.16 2021-11-24)
I added a nice trick to reverse engineering the original Dockerfile from a running Image.
I also added another typical copy and paste error into the Troubleshoot section.
Automating and Provisioning Amazon AWS (EC2, EBS, S3, CloudWatch) with boto3 (Amazon’s SDK for Python 3) and Python 3 book
I’m writing a book about how to automate your Amazon AWS tasks using Amazon’s AWS Python 3 SDK boto3, provisioning new instances, stopping, starting, creating volumes, creating/deleting buckets in S3, uploading/downloading files from S3…
It is currently 20% completed. With 43 pages it shows EC2 section already.
I’ve working in carleslibs v.1.0.3. I added MenuUtils class, which allows to assemble menus super quickly, that execute the code referenced in the menu array. Ideal for building CLI applications very fast.
I also added KeyboardUtils class, which allows to ask the user for String within certain lengths allowing or not spaces and/or underscores, and ask user for Integer values within a certain min and max, having 0 for go back.
The plan is to release the new version of carleslibs as soon as I’ve tested it properly.
Only 2% of the viewers donate, so I answered the call every time it was made.
This is my 5th donation to Wikimedia.
I consider that Freedom is very important.
I bought these new books
One of my secrets to be on top is that I’m always studying.
I study all the time, at work and in my free time.
I use Linux Academy and I buy books in paper. I don’t connect with reading in tablets. I think information is stored better when read in paper. I use also a marker and pointers to keep a direct access to the most interesting points on the books.
And I study all kind of themes. Obviously I know a lot of Web Scraping, but there is always room for learning more. And whatever new I learn helps me to be better with my students and more clear writing my books.
I’ve never been a Front End, but I’ve been able to fix bugs in the Front End engines from the companies I worked for, like Privalia. I was passed a bug that prevented the Internet Explorer users to buy just one hour before we launching a massive campaign. I debugged and I found a variable named “value” so the html looked like <input name="value" value="">. In less than 30 minutes I proved to the incredulous Head of Development and the CTO that a bug in Internet Explored was causing a conflict when fetching the value from the input named value. We deployed to Production the update and the campaign was a total success. So I consider knowing Javascript and Front also a need, even if I don’t work directly with it. I want to be able to understand all the requirements and possibilities, and weaknesses, so I can fix bugs and save the day. That allowed me to fix scalability problems in Nodejs and Phantomjs projects too. (They are Javascript Server Side, event driven, projects)
It seems that Amazon.co.uk works well again for Ireland. My two last orders arrived on time and I had no problems of border taxes apparently.
Nice Python article
I enjoyed a lot this article, cause explains part of what I did with my student and friend Albert, in a project that analyzes the access logs from Apache for patterns of attempts of exploits, then feeds a database, and then blocks those offender Ip Addresses in the Firewall.
The article only covers the part of Pandas, of reading the access.log file and working with it, but is a very well redacted article:
Here is the complete history of why I migrated all the services from my 11 years old Amazon account to other CSP.
Some lessons can be learned from my adventure.
I migrated my last services from Amazon to GCP
Amazon sent me an email on October 6th, this year 2021, telling me that they will disable EC2-Classic by August 2022. I thought I would not be able to keep my Static Ip’s as in the past VPC Ip’s and EC2-Classic Ip’s were not transferable, so considering that I would loss my Static Ip’s anyway I started to migrate to some to other providers like Digital Ocean.
Is not cool losing Static Ip (Elastic Ip in AWS) Addresses as this is bad for SEO, so given that I though I would lose my Static Ips that have been with me for years, I started to migrate certain services to providers much more economic.
Amazon is terrible communicating, and I talked with some product managers in the past about that, when they lost one of my Volumes, and the email was so cold and terrible that actually that hurt more than Amazon losing my Data. I believed that it was a poorly made Scam and when I realized it was true I reached one of my friends, that is manager there, as I know they care for doing things right, and he organized a meeting with two PM so I can pass my feedback.
The Cloud providers are changing things very fast, and nobody is able to be up to date with the changes, unless their work position allows plenty of time to get updated. Even if pages of documentation are provided, you have to react to an event that they externally generated forcing you to action. Action to read all the documentation about EC2-Classic migrations, action to prepare to have migrated by August 2022.
So August 2022… I was counting that I had plenty of time but I’m writing a new book about using the Amazon SDK for Python, boto3, and I was doing some API calls and they started to fail in a very unusual way, Exceptions with timeout, but only for the only region where I had EC2-Classic.
urllib3.exceptions.NewConnectionError: <botocore.awsrequest.AWSHTTPSConnection object at 0x7f0347d545e0>: Failed to establish a new connection: [Errno -2] Name or service not known
But if I switched to another region name, it would work:
region_name='us-west-2',
I made a mistake in here, the region name is “us-east-1” and not “us-east-1a“. “us-east-1a” is the availability zone. So the SDK was giving a timeout because in order to connect to the endpoint it uses the region name as part of the hostname. So it doesn’t find that endpoint because it doesn’t exist.
I never understood why a company like Amazon is unable to provide the SDK with a sample project or projects 100% working, with the source code so people has a base that works to build up.
Every API that I have created, I have provided it with documentation but also with example for several languages for how to use it.
In 2013 I was CTO of an online travel agency, and we had meta-searchers consuming our API and we were having several hundreds of thousands requests per second. Everything was perfectly documented, examples were provided for several languages, the document and the SDK had version numbers…
Everybody forgets about Developers and companies throw terrible and cold products to the poor Developers, so difficult to use. How many Developers would like to say: Listen Mr. President of the big Cloud Company XXXX, I only want to spawn a VM that works, and fast, with easy wizards. I don’t want to learn 50 hours before being able to use your overpriced platform, by doing 20 things before your Ip’s are reflexes of your infrastructure and based in Microservices. Modern JavaScript frameworks can create nice gently wizards even if you have supercold APIs.
Honestly, I didn’t realize my typo in the region and I connected to the Amazon Console to investigate and I saw this.
Honestly, when I read it I understood that they were going to end my EC2 Networking the 30th of October. It was 29th. I misunderstood.
It was my fault not reading it well to the end, I got shocked by the first part telling about shutdown and I didn’t fully understood as they were going to shutdown EC2-Classic for the zones I didn’t had anything running only.
From the long errors (3 exceptions chained) I didn’t realize that the endpoint is built with the region name. (And I was passing the availability zone)
botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL: "https://ec2.us-east-1a.amazonaws.com/"
Here is when I say that a good SDM would had thought and cared for the Developers more, and would had made the SDK to check if that region exists. How difficult is to create a SDK a bit more clever that detects a invalid region id?. It is not difficult.
It is true that it was late in the evening and I was tired of all the day, and two days of the week between work and zoom university classes I work 15 hours and 13 hours respectively, not counting the assignments, so by the end of the week I am very tired. But that’s why it is very important to follow methodology and to read well. I think Amazon has 50% of the fault by the way they do things: how the created the SDK, how they communicate, and by the errors that the console returned me when I tried to create a VPC instance of an EC2-Classic AMI (they seem related to the fact I had old VPC Network objects with shorter hash than the current they use) and the other 50% was my fault for not identifying the source of the error, and not reading the message in their website well.
But the fact that there were having those errors in the API’s and timeouts made me believe they were going to cut the EC2-Classic Networking the next day.
All the mistakes fall together in a perfect storm.
I checked for documentation and I saw it was possible to migrate my Static Ip’s to VPC Static Ip’s.
It was Friday evening, and I cancelled my plans, in order to migrate the Blog to VPC in an attempt to keep running it with Amazon.
As Cloud Architect, I like to have running instances in several CSP as it allows me to stay up to date with the changes they do.
I checked the documentation for the migration. Disassociating the Static Ip (Elastic Ip in AWS jargon) was easy. Turning into VPC as well.
As I progressed, what had to be easy turned into a nightmare, as I was getting many errors from the Amazon API, without any information, and my Instances were not created.
I figured out that their API could have problems with old VPC objects I created time ago, so I had to create new objects for several things.
I managed to spawn my instances but they were being launch and terminated instantly without information. Frustrating.
When launching a new instance from the AMI (a Snapshot of the blog), I was giving shown options to add more volumes without any sense. My Instance was using 16GB from a 20GB total Space, and I was shown different volume configs, depending on the instance, in some case an additional 20GB volume, in other small SSD, ephemeral and 10 GB for the AMI (which requires at least 16GB).
After some fight I manage to make it work after deleting the volumes that made no sense, and keeping only one of 20GB, the same size of my AMI.
But then my nightmare started to make the VPC Instance to have Internet access and to be seen from outside. I had to create a new Internet Gateway, NAT, Network, etc…
As mentioned the old objects I was trying to reusing were making the process to fail.
I was running out of time, and I thought in few time they were going to shutdown EC2-Classic network (as I did not read correctly), so I decided to download everything and to migrate to another provider. For doing that first I blocked all the traffic, except for my Ip.
I worked in parallel, creating the new config in Google Cloud, just in case I had forgot something. I had created a document for the migration and it was accurate.
I managed to do everything fast enough. The slower part was to download all the Data, as I hold entire VM’s for projects like Cassandra Universal Driver.
Then I powered off my Amazon Instance for the Blog forever.
In GCP I blocked all the traffic in the firewall, except for my Ip, so I could work calmly.
When everything was ready, I had to redirect the DNS to the new static Ip from Google.
The DNS provider I used had implemented some changes in their API so I was getting errors replacing my old entry ‘.’ (their JSON calls returned Internal Server Error). Finally I figured it out how to workaround it and I was able to confirm that the first service was up and running.
I did some tests to make sure there were not unexpected permission problems, entries in the logs, etc…
Only then I opened the Google Firewall. I have a second firewall in each instance where I block or open at Ip tables level what I want. Basically abusive bot’s IPs trying to find exploits or brute force by dictionary passwords.
I checked with my phone, without Wifi that the Firewall was all good. (It is always a good idea to use another external Ip, different from the management one, to check)
I’ve raised back the price for my books to normal levels. I’ve been keeping the price to the minimum to help people that wanted to learn during covid-19. I consider that who wanted to learn has already done it.
I still have bundles with a somewhat reduced price, and I authorized LeanPub platform to do discounts up to 50% at their discretion.
I’ve upgraded one of my AWS machines from Ubuntu 18.04 LTS to Ubuntu 20.04 LTS.
The process was really straightforward, basically run:
sudo apt update
sudp apt upgrade
Then Reboot in order to load the last kernel.
Then execute:
sudo do-release-upgrade
And ask two or three questions in different moments.
After, reboot, and that’s it.
All my Firewall rules, were kept, the services were restarted as they were available, or deferred to be executed when the service is reinstalled in case of dependencies (like for PHP, which was upgraded before Apache) and I’ve not found anything out of place, by the moment. The Kernels were special, with Amazon customization too.
I also recommend you to make sure to disable your Apache directory browsing, if you had like that, as new software install may have enabled it:
a2dismod autoindex
systemctl restart apache2
I always recommend, for Production, to run the Ubuntu LTS version.
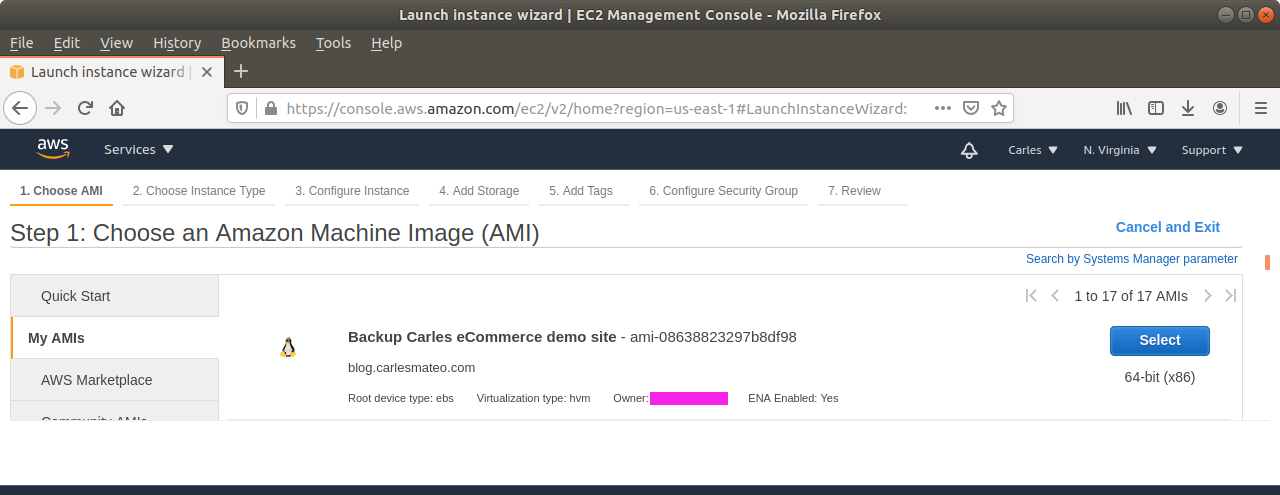
This article covers the desperate situation where you had generated one or more instances, instructed Amazon to use a SSH Key Pair certs where only you have the Private Key, your instances are running, for example, an eCommerce site, running for months, and then you loss your Private Key (.pem file), and with it the SSH access to your instances’ Data.
Actually I’ve seen this situation happening several times, in actual companies. Mainly Start ups. And I solved it for them.
Assuming that you didn’t have a secondary method to access, which is another combination of username/password or other user/KeyPairs, and so you completely lost the access to the Database, the Webservers, etc… I’m going to show you how to recover the data.
For this article I will consider an scenario where there is only one Instance, which contains everything for your eCommerce: Webserver, code, and Database… and is a simple config, with a single persistent drive.
Warning: be very careful as if you use ephemeral drives, contents will be lost is you power off the instance.
Method 1: Quicker, launching a new instance from the previous
Step1: The first step you will take is to close the access from outside, using the Firewall, to avoid any new changes going to the disk. You can allow access to the instance only from your static Ip in the office/home.
Step 2: You’ll wait for 5 minutes to allow any transaction going on to conclude, and pending writes to be flushed to disk.
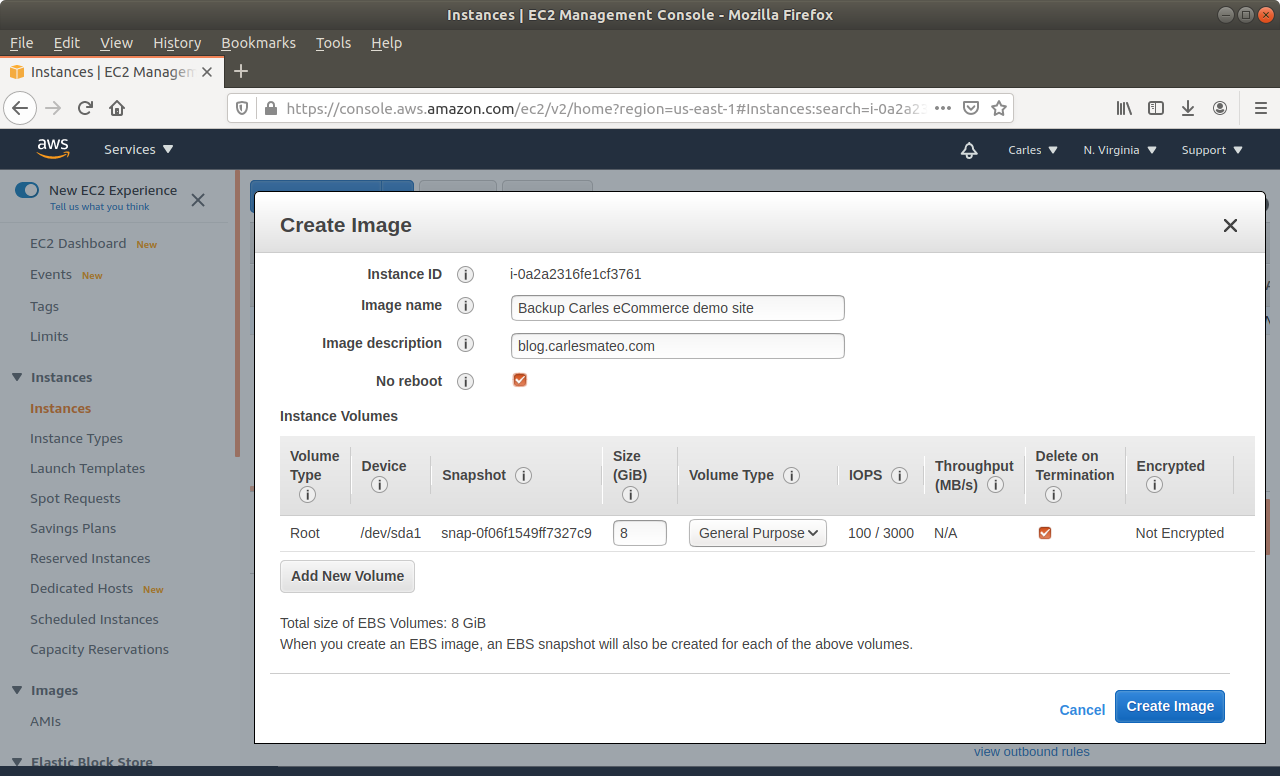
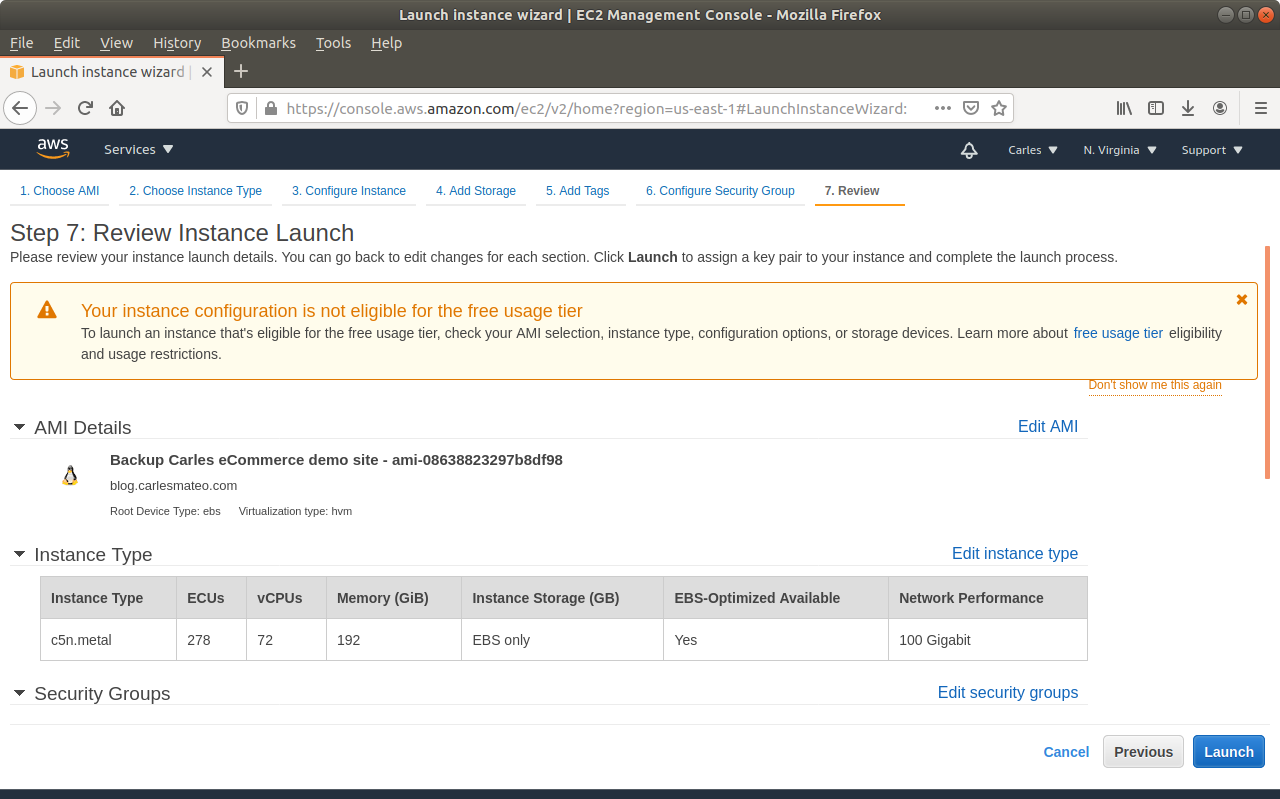
Step 3: From Amazon AWS Console, EC2, you’ll request an Snapshot. That step is to try to get extra security. Taking an Snapshot from a live, mounted, filesystem, is not the best of ideas, specially of a Database, but we are facing a desperate situation so we’re increasing the numbers of leaving this situation without Data loss. This is just for extra security and if everything goes well at the end you will not need this snapshot.
Make sure you select No reboot.
Step 4: Be very careful if you have extra drives and ephemeral drives.
Step 5: Wait till the Snapshot completes.
Step 6: Then request a graceful poweroff. Amazon will try to poweroff the Server in a gentle way. This may take two minutes.
Step 7: When the instance is powered off, request a new Snapshot. This is the one we really want. The other was just to be more safe. If you feel confident you can just unclick No Reboot on the previous Step and do only one Snapshot.
Step 8: Wait till the Snapshot completes.
Step 9: Generate and upload the new key you will use to AWS Console, or ask Amazon to generate a key pair for you. You can do it while creating the new instance through the wizard.
Step 10: Launch a new instance, based on your snapshot AMI. This will generate a copy of your previous instance (using the Snapshot) for the new one. Select the new Key pair. Finish assigning the Security groups, the elastic ip…
Step 11: Start the new instance. You can select a different flavor, like a more powerful instance, if you prefer. (scale vertically)
Step 12: Test your access by login via SSH with the new pair keys and from your static Ip which has access in the Firewall.
Step 13: Check that the web Starts correctly, check the Database logs to see if there is any corruption. Should not have any if graceful shutdown went well.
Step 14: Reopen the access from the Firewall, so the world can connect to your instance.
Method 2: Slower, access the Data and rebuild whatever you need
The second method is exactly the same until Step 6 included.
Step 7: After this, you will create a new instance based on your favorite OS, with a new pair of Keys.
Step 8: You’ll detach the Volume from the eCommerce previous instance (the one you lost access).
Step 9: You’ll attach the Volume to the new instance.
Step 10: You’ll have access to the Data from the previous instance in the new volume. type cat /proc/partitions or df -h to see the mountpoints available. You can then download or backup, or install the Software again and import the Database…
Step 11: Check that everything works, and enable the access worldwide to the Web in the Firewall (Security Group Inbound Rules).
If you are confident enough, you can use this method to upgrade the OS or base Software of your instance, making it part of your maintenance window. For example, to get the last version of Ubuntu or CentOS, MySQL, Python or PHP, etc…
Update: 2021-07-23 Ubuntu 19.04 is no longer available, so I updated the article in order to work with Ubuntu 20.04. and with PHP 7.4 and all their dependencies.
This was interesting under the point of view of dealing with elastic Ip’s, Amazon AWS Volumes, etc… but was a process basically manual. I could have generated an immutable image to start from next time, but this is another discussion, specially because that Server Instance has different base Software, including a MySql Database.
This time I want to explain, step by step, how to containerize my Server, so I can port to different platforms, and I can be independent on what the Server Operating System is. It will work always, as we defined the Operating System for the Docker Container.
So we start to use IaC (Infrastructure as Code).
So first you need to install docker.
So basically if your laptop is an Ubuntu 18.04 LTS or 20.04 LTS you have to:
sudo apt install docker.io
Start and Automate Docker
The Docker service needs to be setup to run at startup. To do so, type in each command followed by enter:
sudo systemctl start docker
sudo systemctl enable docker
Create the Dockerfile
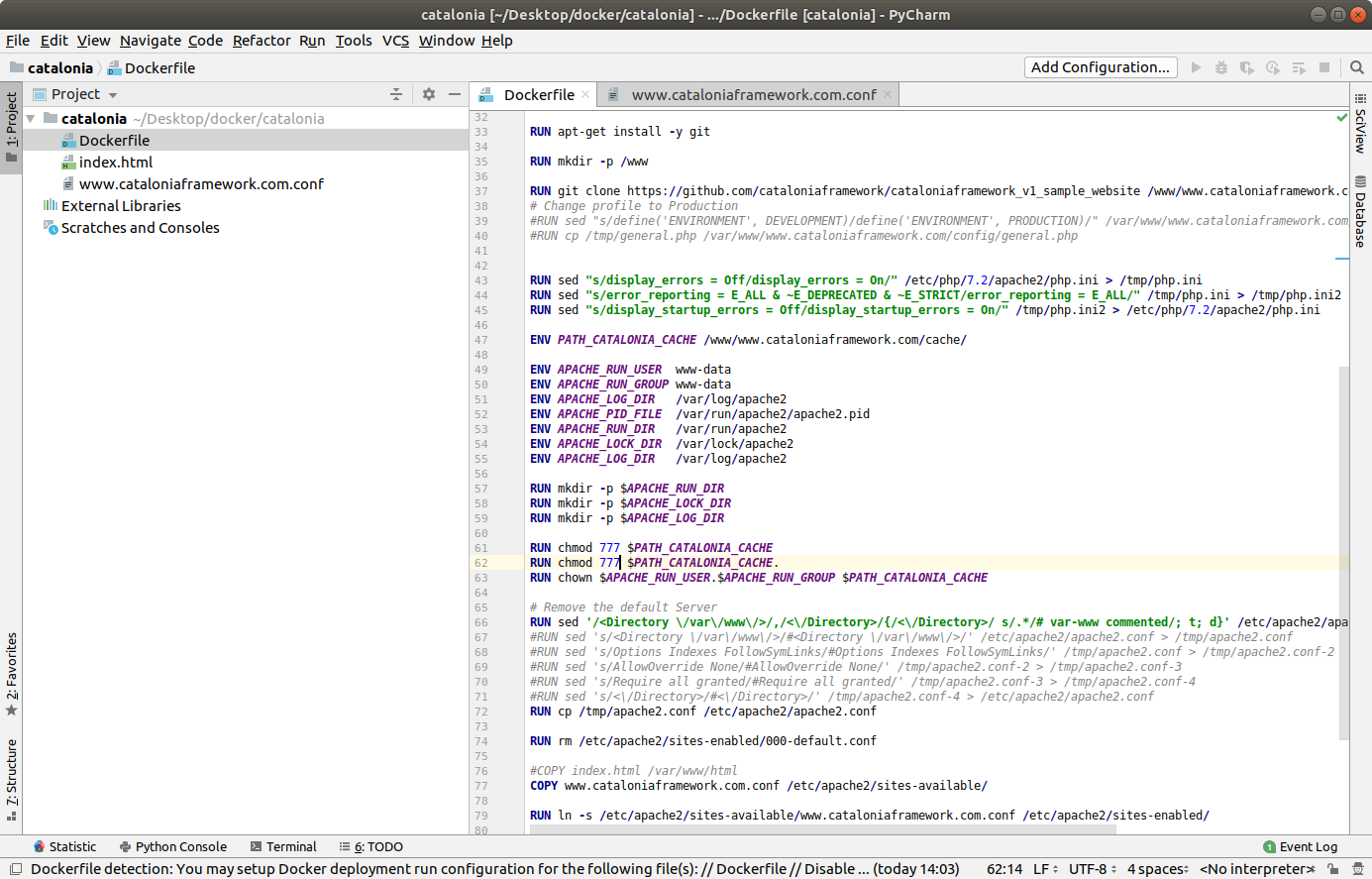
For doing this you can use any text editor, but as we are working with IaC why not use a Code Editor?.
You can use the versatile PyCharm, that has modules for understanding Docker and so you can use Control Version like git too.
This is the updated Dockerfile to work with Ubuntu 20.04 LTS
FROM ubuntu:20.04
MAINTAINER Carles <carles@carlesmateo.com>
ARG DEBIAN_FRONTEND=noninteractive
#RUN echo "nameserver 8.8.8.8" > /etc/resolv.conf
RUN echo "Europe/Ireland" | tee /etc/timezone
# Note: You should install everything in a single line concatenated with
# && and finalizing with
# apt autoremove && apt clean
# In order to use the less space possible, as every command is a layer
RUN apt update && apt install -y apache2 ntpdate libapache2-mod-php7.4 mysql-server php7.4-mysql php-dev libmcrypt-dev php-pear git && apt autoremove && apt clean
RUN a2enmod rewrite
RUN mkdir -p /www
# In order to activate Debug
# RUN sed -i "s/display_errors = Off/display_errors = On/" /etc/php/7.2/apache2/php.ini
# RUN sed -i "s/error_reporting = E_ALL & ~E_DEPRECATED & ~E_STRICT/error_reporting = E_ALL/" /etc/php/7.2/apache2/php.ini
# RUN sed -i "s/display_startup_errors = Off/display_startup_errors = On/" /etc/php/7.2/apache2/php.ini
# To Debug remember to change:
# config/{production.php|preproduction.php|devel.php|docker.php}
# in order to avoid Error Reporting being set to 0.
ENV PATH_CATALONIA /www/www.cataloniaframework.com/
ENV PATH_CATALONIA_WWW /www/www.cataloniaframework.com/www/
ENV PATH_CATALONIA_CACHE /www/www.cataloniaframework.com/cache/
ENV APACHE_RUN_USER www-data
ENV APACHE_RUN_GROUP www-data
ENV APACHE_LOG_DIR /var/log/apache2
ENV APACHE_PID_FILE /var/run/apache2/apache2.pid
ENV APACHE_RUN_DIR /var/run/apache2
ENV APACHE_LOCK_DIR /var/lock/apache2
ENV APACHE_LOG_DIR /var/log/apache2
RUN mkdir -p $APACHE_RUN_DIR
RUN mkdir -p $APACHE_LOCK_DIR
RUN mkdir -p $APACHE_LOG_DIR
RUN mkdir -p $PATH_CATALONIA
RUN mkdir -p $PATH_CATALONIA_WWW
RUN mkdir -p $PATH_CATALONIA_CACHE
# Remove the default Server
RUN sed -i '/<Directory \/var\/www\/>/,/<\/Directory>/{/<\/Directory>/ s/.*/# var-www commented/; t; d}' /etc/apache2/apache2.conf
RUN rm /etc/apache2/sites-enabled/000-default.conf
COPY www.cataloniaframework.com.conf /etc/apache2/sites-available/
RUN chmod 777 $PATH_CATALONIA_CACHE
RUN chmod 777 $PATH_CATALONIA_CACHE.
RUN chown --recursive $APACHE_RUN_USER.$APACHE_RUN_GROUP $PATH_CATALONIA_CACHE
RUN ln -s /etc/apache2/sites-available/www.cataloniaframework.com.conf /etc/apache2/sites-enabled/
# Note: You should clone locally and COPY to the Docker Image
# Also you should add the .git directory to your .dockerignore file
# I made this way to show you and for simplicity, having everything
# in a single file
##RUN git clone https://github.com/cataloniaframework/cataloniaframework_v1_sample_website /www/www.cataloniaframework.com
##RUN git checkout tags/v.1.16-web-1.0
# In order to change profile to Production
# RUN sed -i "s/define('ENVIRONMENT', DOCKER)/define('ENVIRONMENT', PRODUCTION)/" /var/www/www.cataloniaframework.com/config/general.php
COPY *.php /www/www.cataloniaframework.com/www
# for debugging
#RUN apt-get install -y vim
RUN service apache2 restart
EXPOSE 80
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
This will copy the file www.cataloniaframework.com.conf that must be in the same directory that the Dockerfile file, to the /etc/apache2/sites-available/ folder in the container.
<VirtualHost *:80>
ServerAdmin webmaster@cataloniaframework.com# Uncomment to use a DNS name in a multiple VirtualHost Environment #ServerName www.cataloniaframework.com #ServerAlias cataloniaframework.com DocumentRoot /www/www.cataloniaframework.com/www
<Directory /www/www.cataloniaframework.com/www/>
Options -Indexes +FollowSymLinks +MultiViews AllowOverride All Order allow,deny allow from all Require all granted
</Directory>
ErrorLog ${APACHE_LOG_DIR}/www-cataloniaframework-com-error.log # Possible values include: debug, info, notice, warn, error, crit, # alert, emerg. LogLevel warn CustomLog ${APACHE_LOG_DIR}/www-cataloniaframework-com-access.log combined
</VirtualHost>
Stopping, starting the docker Service and creating the Catalonia image
service docker stop && service docker start
To build the Docker Image we will do:
docker build -t catalonia . --no-cache
I use the –no-cache so git is pulled and everything is reworked, not kept from cache.
Now we can run the Catalonia Docker, mapping the 80 port.
docker run -d -p 80:80 catalonia
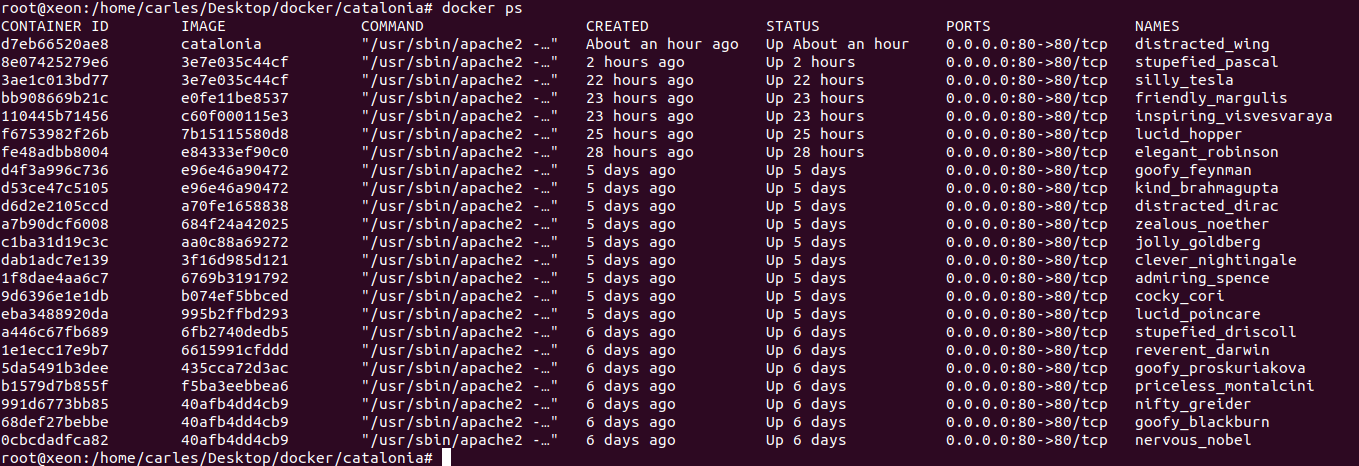
If you want to check what’s going on inside the Docker, you’ll do:
docker ps
And so in this case, we will do:
docker exec -i -t distracted_wing /bin/bash
Finally I would like to check that the web page works, and I’ll use my preferred browser. In this case I will use lynx, the text browser, cause I don’t want Firefox to save things in the cache.
Nothing new, zombie computers, hackers, pirates, networks of computers… trying to abuse the system and to hack into it. Why? There could be many reasons, from storing pirate movies, trying to use your Server for sending Spam, try to phishing or to host Ransomware pages…
Most of those guys doesn’t know that is almost impossible to Spam from Amazon. Few emails per hour can come out from the Server unless you explicitly requests that update and configure everything.
But I thought it was a great opportunity to force myself to update the Operating System, core tools, versions of PHP and MySql.
Forensics / Postmortem of the incident
The task was divided in two parts:
Understanding the origin of the attack
Blocking the offending Ip addresses or disabling XMLRPC
Making the VM boot again (problems with Amazon AWS)
I didn’t know why it was not booting so.
Upgrading the OS
I disabled the access to the site while I was working using Amazon Web Services Firewall. Basically I turned access to my ip only. Example: 8.8.8.8/32
I changed 0.0.0.0/0 so the world wide mask to my_Ip/3
That way the logs were reflecting only what I was doing from my Ip.
Dealing with Snapshots and Volumes in AWS
Well the first thing was doing an Snapshot.
After, I tried to boot the original Blog Server (so I don’t stop offering service) but no way, the Server appeared to be dead.
So then I attached the Volume to a new Server with the same base OS, in order to extract (dump) the database. Later I would attach the same Volume to a new Server with the most recent OS and base Software.
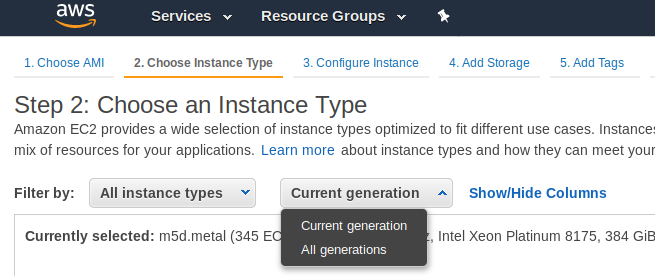
Something that is a bit annoying is that the new Instances, the new generation instances, run only in VPC, not in Amazon EC2 Classic. But my static Ip addresses are created for Amazon EC2 Classic, so I could not use them in new generation instances.
I choose the option to see all the All the generations.
Upgrading the system base Software had its own challenges too.
Upgrading the OS / Base Software
My approach was to install an Ubuntu 18.04 LTS, and install the base Software clean, and add any modification I may need.
I wanted to have all the supported packages and a recent version of PHP 7 and the latest Software pieces link Apache or MySQL.
Config files that before were working stopped working as the new Apache version requires the files or symlinks under /etc/apache2/sites-enabled/ to end with .conf extension.
Also some directives changed, so some websites will not able to work properly.
Those projects using my Catalonia Framework were affected, although I have this very well documented to make it easy to work with both versions of Apache Http Server, so it was a very straightforward change.
From the previous version I had to change my www.cataloniaframework.com.conf file and enable:
<Directory /www/www.cataloniaframework.com> Options Indexes FollowSymLinks MultiViews AllowOverride All Order allow,deny allow from all </Directory>
Then Open the ports for the Web Server (443 and 80).
sudo ufw allow in "Apache Full"
Then service apache restart
Catalonia Framework Web Site, which is also created with Catalonia Framework itself once restored
MySQL
The problem was to use the most updated version of the Database. I could use one of the backups I keep, from last week, but I wanted more fresh data.
I had the .db files and it should had been very straightforward to copy to /var/lib/mysql/ … if they were the same version. But they weren’t. So I launched an instance with the same base Software as the old previous machine had, installed mysql-server, stopped it, copied the .db files, started it, and then I made a dump with mysqldump –all-databases > 2019-04-29-all-databases.sql
Note, I copied the .db files using the mythical mc, which is a clone from Norton Commander.
Then I stopped that instance and I detached that volume and attached it to the new Blog Instance.
I did a Backup of my original /var/lib/mysql/ files for the purpose of faster restoring if something went wrong.
I mounted it under /mnt/blog_old and did mysql -u root -p < /mnt/blog_old/home/ubuntu/2019-04-29-all-databases.sql
That worked well I had restored the blog. But as I was watching the /var/log/mysql/error.log I noticed some columns were not where they should be. That’s because inadvertently I overwritten the MySql table as well, which in MySQL 5.7 has different structure than in MySQL 5.5. So I screwed. As I previewed this possibility I restored from the backup in seconds.
So basically then I edited my .sql files and removed all that was for the mysql database.
I started MySql, and run the mysql import procedure again. It worked, but I had to recreate the users for all the Databases and Grant them permissions.
GRANT ALL PRIVILEGES ON db_mysqlproxycache.* TO 'wp_dbuser_mysqlproxy'@'localhost' IDENTIFIED BY 'XWy$&{yS@qlC|<¡!?;:-ç';
PHP7
Some modules in my blogs where returning errors in /var/log/apache2/mysite-error.log so I checked that it was due to lack of support of latest PHP versions, and so I patched manually the code or I just disabled the offending plugin.
WordPress
As seen checking the /var/log/apache2/blog.carlesmateo.com-error.log some URLs where not located by WordPress.
For example:
The requested URL /wordpress/wp-json/ was not found on this server
I had to activate modrewrite and then restart Apache.
a2enmod rewrite; service apache2 restart
Making the site more secure
Checking at the logs of Apache, /var/log/apache2/blog.carlesmateo.com-access.log I checked for Ip’s accessing Admin areas, I looked for 404 Errors pointing to intents to exploit any unsafe WP Plugin, I checked for POST protocol as well.
I added to the Ubuntu Uncomplicated Firewall (UFW) the offending Ip’s and patched the xmlrpc.php file to exit always.