Here is my proposal for sorting much, much faster than quicksort.
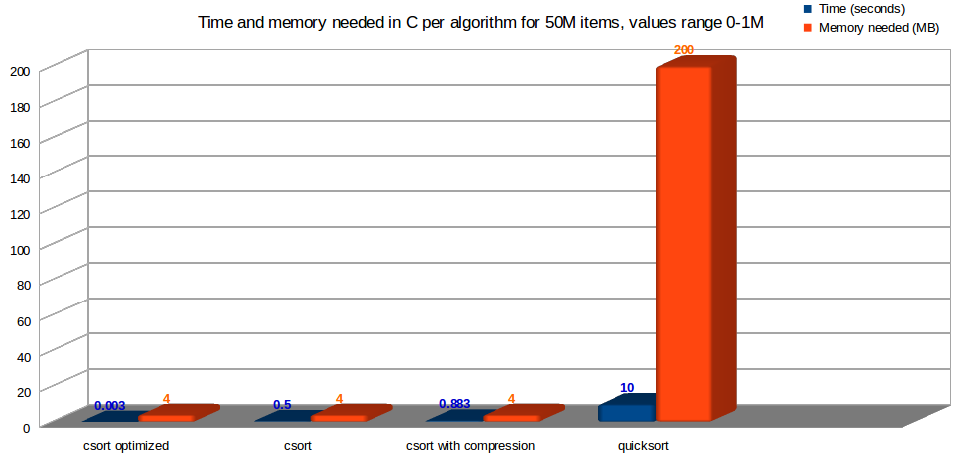
Time and memory consumption in C, for my algorithm csort, versus quicksort, with an universe of 50 Million registers, with values duplicated from 0 to 1,000,000. Less is better
All the algorithms must be checked with different universes of data and their utility is limited to some situations. I explain here the algorithm, show the logic behind code in C, in PHP and Java, the metricas, push the boundaries of the computer… and test against different sets of data looking for the big-O. I prove how much more perfomant it is and explain everything.
This article is complex, is intended for very Senior Engineers at huge companies that need to handle very big data.
The code is written in C to be sure that we compare everything in the same order of magnitude and to avoid optimizations from the compilers / precompilers / Just in Time engines that could bias the conclusions, and so knowing that we are playing fair, but there is a porting to PHP so everyone can understand the algorithm and there are some utilities written in PHP as well. I’ll also explain certain interesting things about PHP internal functions and how it handles memory, and other goodies about C. Finally the code is also available in Java, and is possible to observe how clearly my csort beats quicksort and how fast que JIT compiler performs. Perhaps you can be interested into reading my previous article performance of several languages.
We need a huge amount of data in order to be able to demonstrate the time differences clearly.
Some of the PHP tests and proves require you to have a decent computer with at least 16 GB of RAM. You can skip those or reduce the magnitude of the set of data, or simply use C.
Take this article as an intellectual entertainment, although I think you will discover this useful algorithm / technique of mine will allow you to sort much faster than quicksort in most of the cases I can imagine, and so you will have another tool in your set of resources for sorting fast and dealing with heavy data structures.
Problem
An initial intellectual problem description to enter into matter:
Having a set of 50,000,000 numbers, with values possible between 0 and 1,000,000:
- Sort them and eliminate duplicates as fast as possible
To be fair and trustworthy the numbers will be generated and saved to disk, and the same set of numbers will be used for comparing between all the algorithms and tests and when checking with different languages.
Generating the numbers
For this test I created an array of numeric items.
I created a .txt file filled with the numbers, and then I load the same set of numbers for all the tests so all the numbers are always the same and results cannot be biased by a random set very lucky for the algorithm to sort.
I’ve generated several universes of tests, that you can download.
Code in PHP to generate the random numbers and save to a file
If you prefer to generate a new set of numbers, you can do it by yourselves.
Please note: my computers have a lot of memory, but if you have few memory you can easily modify this program to save the values one by one and so saving memory by not having all the array in memory. Although I recommend you to generate big arrays and pass to a function while measuring the memory consumption to really understand how PHP manages passing Arrays to functions and memory. I found many Senior devs wrong about it.
<?php
/**
* Created by : carles.mateo
* Creation Date: 2015-05-22 18:36
*/
error_reporting(E_ALL);
// To avoid raising warnings from HHVM
date_default_timezone_set('Europe/Andorra');
// This freezes the server, using more than 35 GB RAM
//define('i_NUM_VALUES', 500000000);
// 50M uses ~ 10 GB RAM
define('i_NUM_VALUES', 50000000);
define('i_MAX_NUMBER', 500000000);
function get_random_values() {
$st_values = null;
$s_values_filename = 'carles_sort.txt';
if (file_exists($s_values_filename)) {
print_with_datetime("Reading values...");
$st_values = file($s_values_filename);
print_with_datetime("Ensuring numeric values...");
foreach($st_values as $i_key=>$s_value) {
$i_value = intval($s_value);
$st_values[$i_key] = $i_value;
}
} else {
print_with_datetime("Generating values...");
$st_values = generate_random_values();
print_with_datetime("Writing values to disk...");
save_values_to_disk($s_values_filename, $st_values);
print_with_datetime("Finished writing values to disk");
}
return $st_values;
}
function generate_random_values() {
$i_num_values = i_NUM_VALUES;
$i_max_number = i_MAX_NUMBER;
$st_values = array();
for($i_counter = 0; $i_counter<$i_num_values; $i_counter++) {
$i_random = rand(0, $i_max_number);
$st_values[] = $i_random;
}
return $st_values;
}
function save_values_to_disk($s_values_filename, $st_values) {
$i_counter = 0;
$o_file = fopen($s_values_filename, 'w');
foreach ($st_values as $i_key => $s_value) {
$i_counter++;
fwrite($o_file, $s_value.PHP_EOL);
if (($i_counter % 100000) == 0) {
// every 100K numbers we show a status message
$f_advance_percent = ($i_counter / $i_max_values)*100;
print_with_datetime("Item num: $i_counter ($f_advance_percent%) value: $s_value written to disk");
}
}
fclose($o_file);
}
function get_datetime() {
return date('Y-m-d H:i:s');
}
function print_with_datetime($s_string) {
echo get_datetime().' '.$s_string."\n";
}
print_with_datetime('Starting number generator...');
$st_test_array = get_random_values();
First comments about this code:
- Obviously to generate an array from 50M items in PHP you need enough of RAM. In PHP this takes ~9GB, in C you need much less: just 50M * 4 bytes per item = 200 MB, although as my program is multipurpose and use several arrays you will realistic be needing >2 GB RAM.
- Playing with memory_get_usage() ayou will discover that returning a big array from the function to the main code does not work by copying it to the stack, and that by passing the array to the function by value (not specifying by reference), does not copy the values neither. A pointer alike is passed unless the data passed is modified. It used a technique called copy-on-write. Other modern languages use similar techniques as well to save memory. So it is not true that “
A copy of the original $array is created within the function scope“. As PHP.net section PHP at the Core: A Hacker’s guide defines “PHP is a dynamic, loosely typed language, that uses copy-on-write and reference counting.“
- Please note that when we read from disk we do:
foreach($st_values as $i_key=>$s_value) {
$i_value = intval($s_value);
$st_values[$i_key] = $i_value;
}
This forced conversion to int is because when PHP reads the values from the disk it reads them as String (and it puts a jump of line at the end as well). We convert to make sure we use PHP integer values.
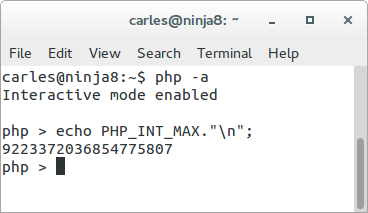
To know the max value of an Integer in your platform do:
echo PHP_INT_MAX;
For a 64 bits is: 9223372036854775807
 I limited the number of registers sorted in this tests to 50,000,000 because it makes PHP use 12.6GB of RAM, and my computer has 32 GB. I tried with 500,000,000 but the Linux computer started to swap like crazy and had to kill the process by ssh (yes, the keyboard and mouse were irresponsible, I had to login via ssh from another computer and kill the process). Although 500M is a reasonably number for the code in C or Java.
I limited the number of registers sorted in this tests to 50,000,000 because it makes PHP use 12.6GB of RAM, and my computer has 32 GB. I tried with 500,000,000 but the Linux computer started to swap like crazy and had to kill the process by ssh (yes, the keyboard and mouse were irresponsible, I had to login via ssh from another computer and kill the process). Although 500M is a reasonably number for the code in C or Java.
- So the fourth conclusion is that for working with big Data Structures PHP is not recommended because it uses a lot of RAM. You can use it if its flexibility brings you more value than performance and memory consumption.
- Everything that you do can do in PHP will be much much much faster if done in C.
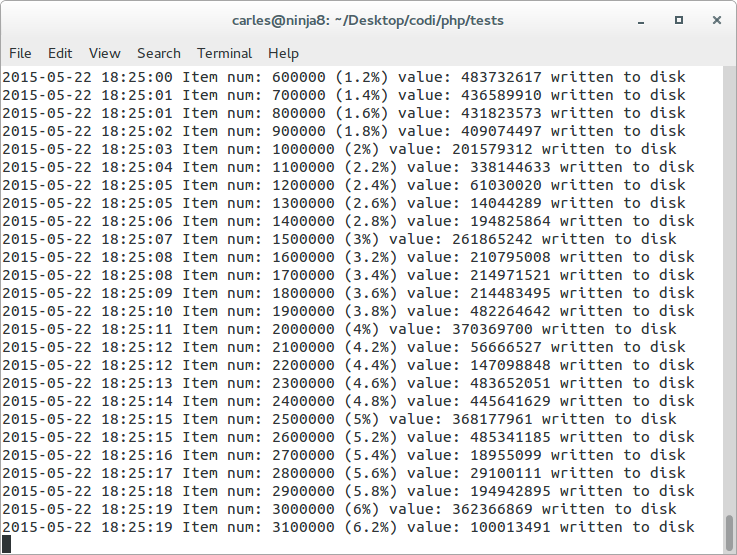
Sample status of the advance of the process of writing to disk from PHP (that is slow) 50M values from ranges 0 to 500M
My solution 1: simple csort
I’ve developed several implementations, with several utility. This is the first case.
Please take a look at this table of the cost of sorting an Array by using different algorithms from http://bigocheatsheet.com/ :

It is interesting to see the complexity of each algorithm in all the cases.
So Quicksort has a complexity of O(n log(n)) for the best case, and O(n^2) for the worst.
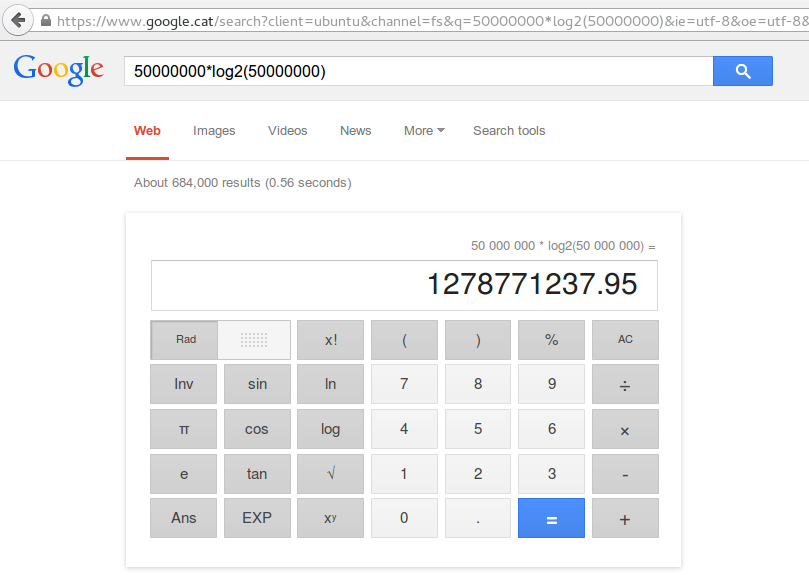
For a 50 Million Array, so n=50M, then 50M * log2(50M) = 1,278,771,237.95 ~ 1.28 Billion
My algorithm approach is this: having the unsorted array loaded into the array st_values, I do a main loop like this (remember that we want to sort and remove duplicates):
for (l_counter=0; l_counter < l_max_values; l_counter++) {
st_values_sorted[st_values[l_counter]] = st_values[l_counter];
}
So, I copy to the destination array st_values_sorted the values, assigning the value as the index of the Array st_values_sorted.
With this:
- We are sure we will have no duplicates, as if the value is duplicated n times it will be simply reassigned to the same position n times, and so having only it one time as st_values_sorted[n] in the final array.
- We have an array, that has as index, the same value. So even, if in a foreach loop you would get the values assorted, they’re sorted by their key (hash index numeric value).
Finally, if you want to generate a sorted sequential array or a linked list, we do:
// Resort for a creating a ordered list
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > -1 ) {
// If the value existed
st_values_sorted_renum[l_counter_hit] = st_values_sorted[l_counter];
l_counter_hit++;
}
}
The magic of this:
- In the first loop, we read each item of the array just one time. So O(n)
- In the second loop, if we really want to generate a sorted list, we simply loop the sorted and deduplicated Array by index, as seen in the code before, from the initial possible value (0) to the maximum value we can have (in this sample m=1M)
- So we loop, for 1,000,001 items
- So in total we do n+m cycles
The cost in the Best and in the Worst case is O(n)
- This is fucking awesome faster than quicksort
For quicksort time complexity is: Best O(n log n). Worst O(n^2)
- After quicksort you would have to delete duplicates also, adding some cost (in the case of PHP unique() function is really costly)
- An optimization is that we can also associate the index, in the process of loading the values from disk, so we save the first loop (step 1) and so we save O(n).
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
exit(EXIT_FAILURE);
}
st_values[l_number] = l_number;
l_counter++;
if (l_counter > l_max_values -1) break;
}
And we will have the Array sorted (by key) without any sort. That’s why I say…
The fastest sort… is no sorting at all!.
This is the recommended way of using the algorithm because it saves a lot of memory, so, instead of having and Array of 50M for loading the data to sort, and another of 1M to hold the csorted data, we will have only the 1M Array. We will be adding the data using csort and eliminating duplicates and sorting on the way.
- If in the process of loading the have all the values sorted, we will not do the first loop O(n), so our cost will be O(m) where m<n
- Finally, if our array is sorted (by index) there is no need to do the second loop to produce a sorted list, as the array is sorted by key. But if we need to do it, the cost is m, otherwise we have no cost at all, it was sorted and deduplicated when loaded from disk!
- Even doing both loops, this is awesome faster than quicksort (even without deduplicating), for the universes tested:
- 50M items, possible values 0-1M
- 50M items, possible values 0-50M
- 50M items, possible values 0-500M
- The same proportions with less items
Comparing the performance for the first case
Notes:
- Please note the code has been compiled with -O0 to disable optimizations for what I think is a bug I found in gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2. that manifests in the csort with compression. With the parameter -O2 the times for the sorting are half and better (0.1 seconds for csort basic, around 4.7 for quicksort).
- To use arrays of 500M, so using more than 2GB of ram you should pass the parameter -mcmodel=medium to gcc or the compiler will return an error “relocation truncated to fit: R_X86_64_32S against .bss”
- Computer used is Intel(R) Core(TM) i7-4770S CPU @ 3.10GHz, as computers nowadays use turbo, times vary a bit from test to test, so tests are done many times and an average value is provided
- Please understand how your language pass the parameters in functions before trying to port this code to another language (passing a pure by value string of 50M items to a function would not be a good idea, even worst for the case of recursive functions)
As you can see in the C code below, I have used two quicksort algorithms, both quicksort take between 8.7 and 10 seconds. (the second algorithm is a bit slower)
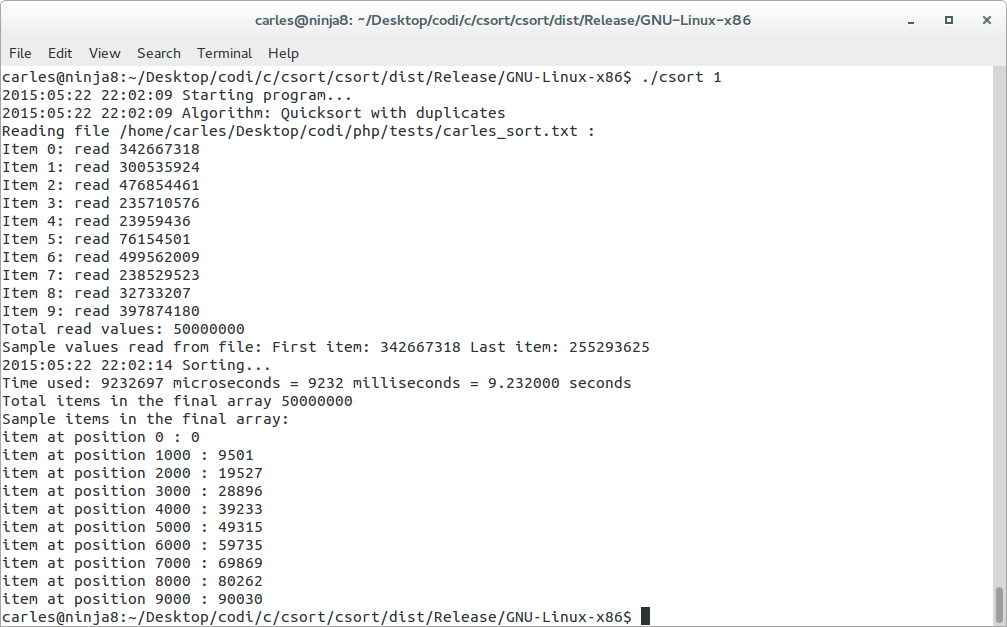
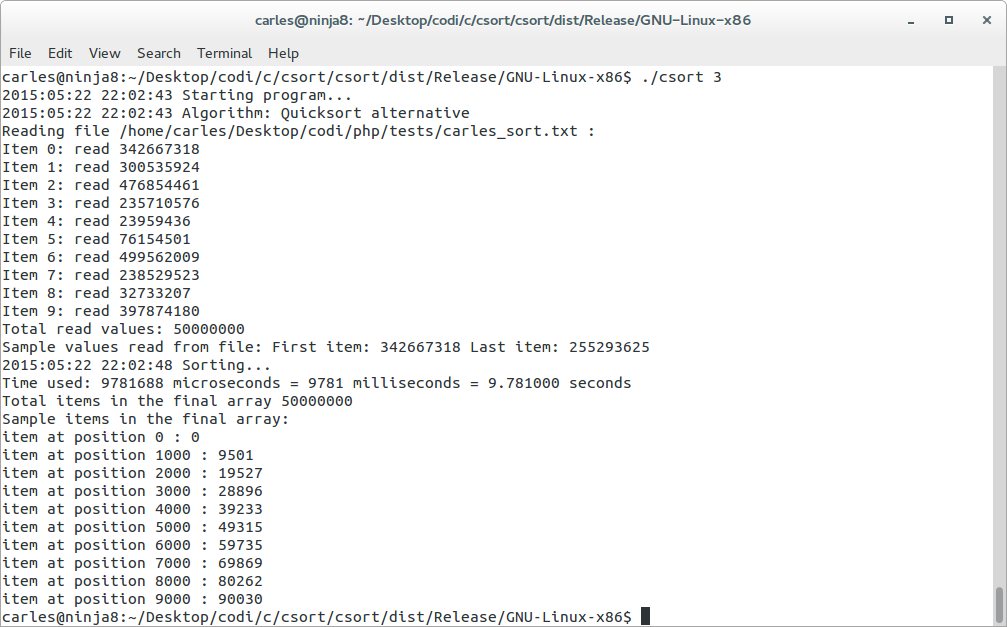 This time does not change, no matter if the random numbers were for ranges 0-1M, 0-50M or 0-500M.
This time does not change, no matter if the random numbers were for ranges 0-1M, 0-50M or 0-500M.
My implementation of the quicksort with removing duplicates take just a bit more as I use the same base of the csort for removing the duplicates.
With the csort basic, doing the two loops (so no optimizing on load) the time for sorting with removing duplicates and generating a final array like a list, depends on the maximum possible value:
- Universe of 50M items, random values between 0-1M, time: 0.5 to 0.7 seconds
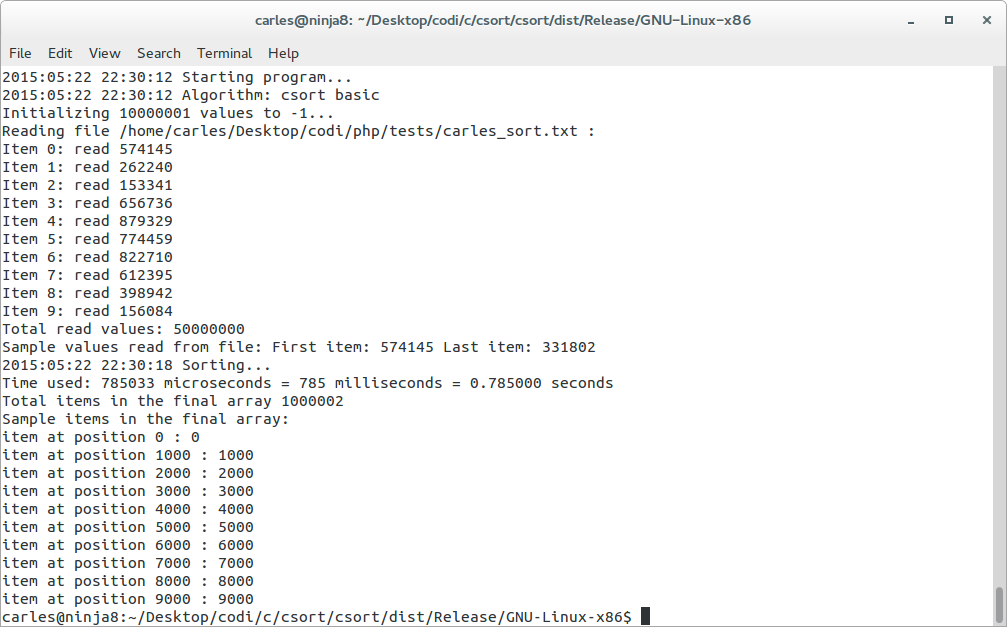
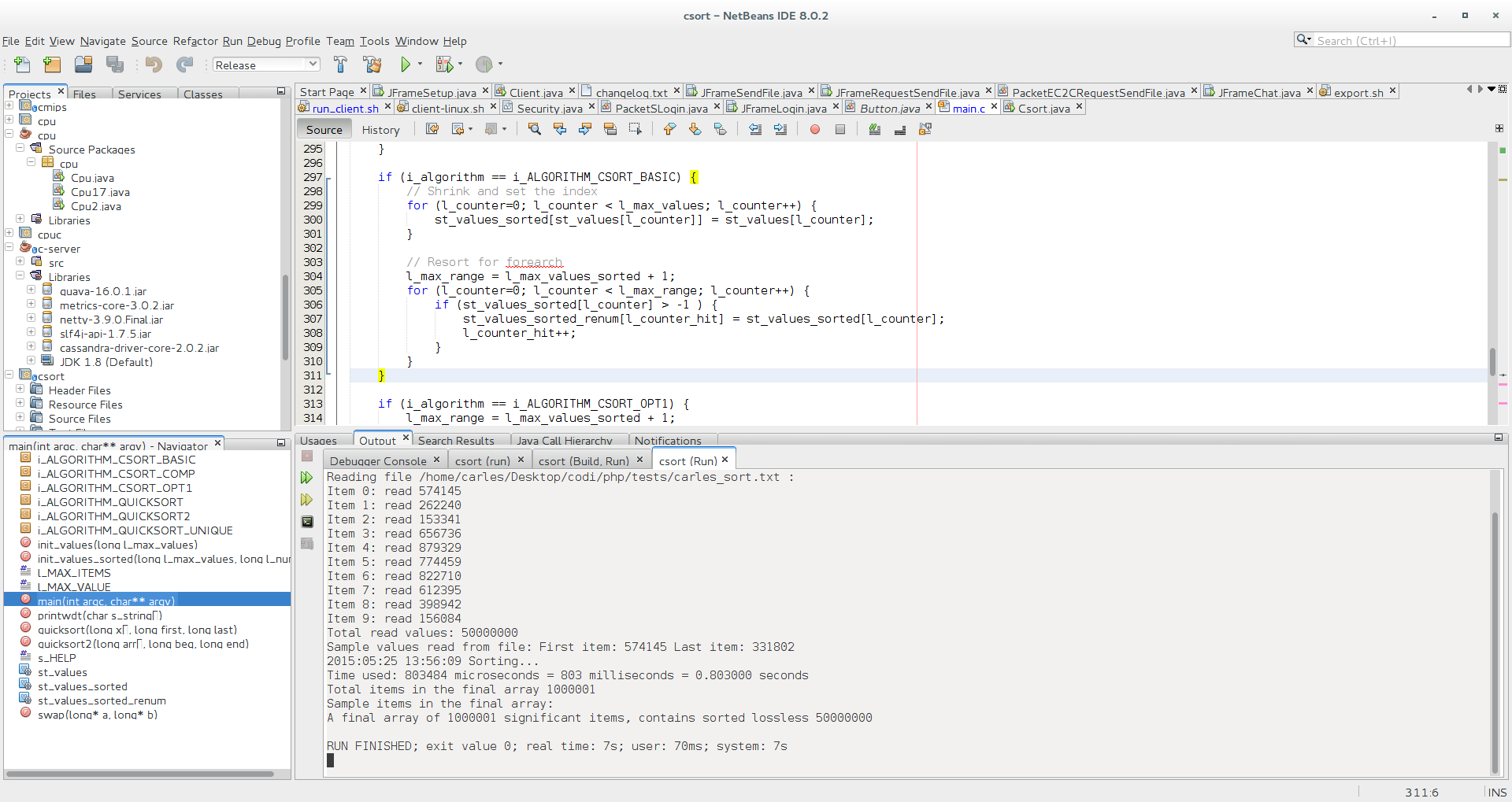
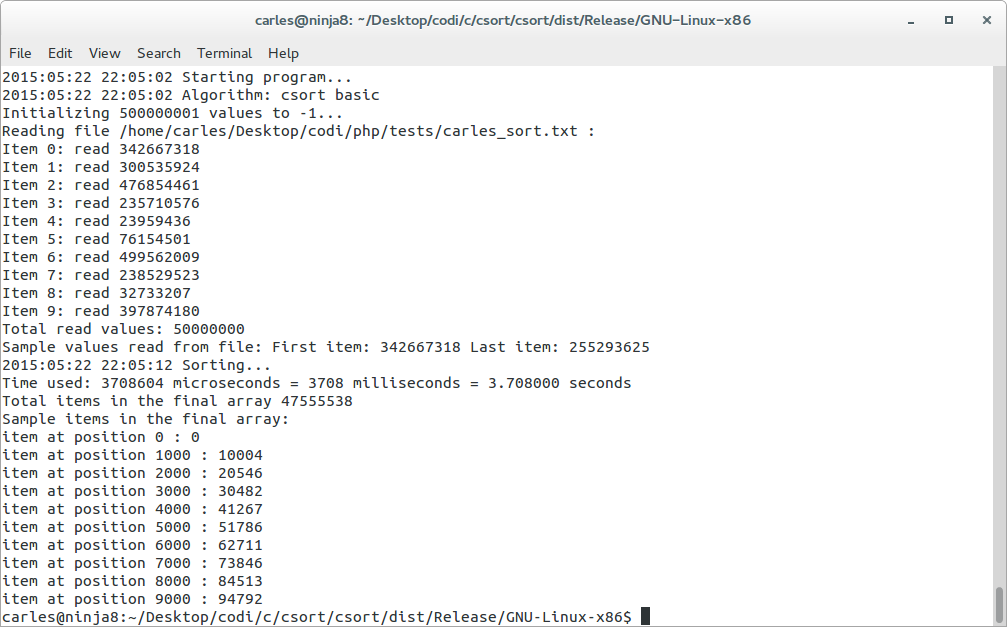
Here csort basic invoked from command line. Firefox was opened and heavily full of tabs, so it was a bit slower but it takes 785 ms
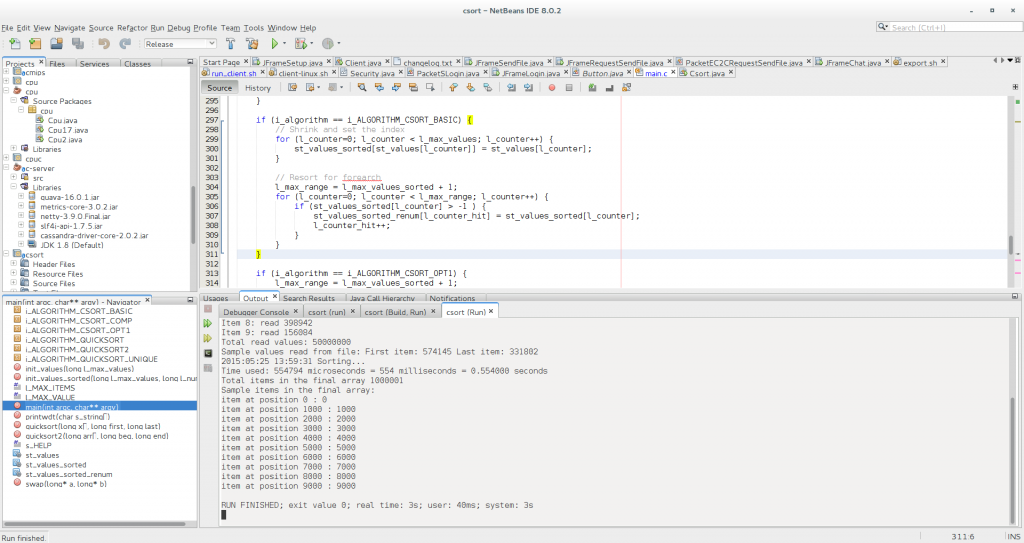
Launching csort basic from the netbeans IDE, Release config but -O0, and firewox removed, takes 554 milliseconds / 0.554 seconds
- Universe of 50M items, random values between 0-50M, 1.7-2 seconds
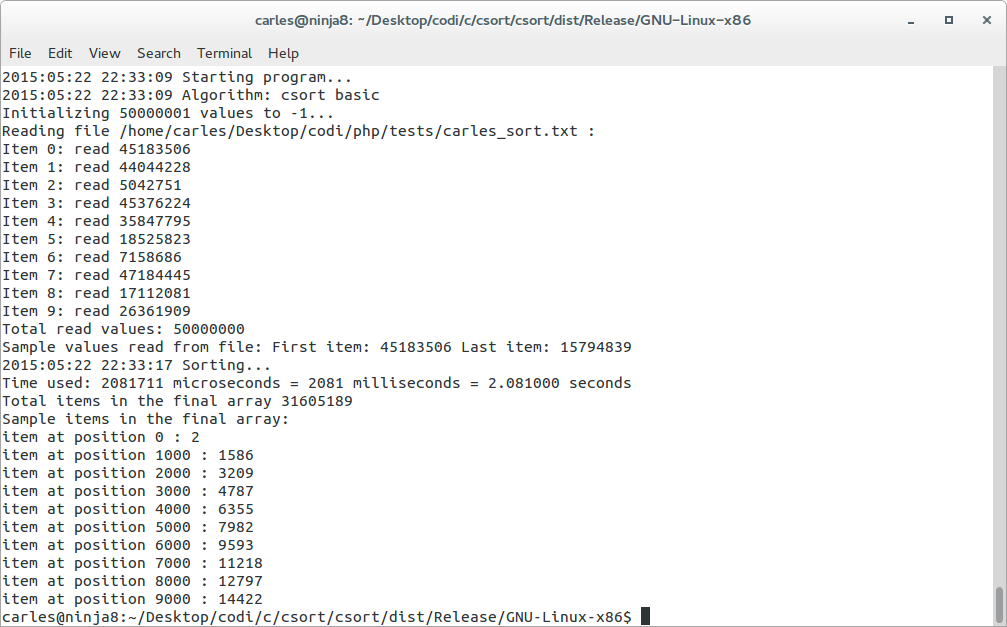
- Universe of 50M items, random values between 0-500M, 3.7 seconds
Advantages of csort (for its purpose, so for the universes compatible, so if the range of values m is smaller or not many times bigger than the number of items n):
- Is super-fast
- It saves a lot of memory
- Can be used to remove duplicates or to keep duplicates
- It is possible to use it with hybrid universes (see additional optimizations) and have significant performance gains respect using a single sorting algorithm
- It is very easy to understand and to implement
Disadvantages of csort basic:
- It is intended for the universe of max(m) < n. If max(m) (maximum value of the number of random values) is much much higher than n (the number of items), then the sorted by key array will use more memory (bigger array), even if it has few values. (* see csort with compression bellow and Additional optimizations sections)
- In certain border edge cases where n is many more times smaller than the difference between min(m) and max(m) the algorithm could be slower than quicksort. (this is if data does not accomplish max(m) < n)
- The sorted array uses memory. Other algorithms, starting from an initial array, do not need additional arrays in order to sort. Although we can generate a final linked list and remove the arrays from memory during the process we are using that memory. But this was supposing we have an original array not sorted, but actually we don’t need to have an starting array, just csort the Data as you get it to the destination Array, and then you save memory because an Array of 1M takes less memory than an Array of 50M. (See My solution 2: optimized when reading)
My solution 2: optimized when reading
This is basically csort, but using the read from disk process to assign the right index, not only save CPU but a lot of memory.
That way the complexity is totally reduced as data is sorted (by index) and deduplicated when loading, with no cost.
In the case of the optimized read, with an universe of 50M items, ranges 0-1M, it takes the astonishing time of.. 3 ms! So 0.003 seconds.
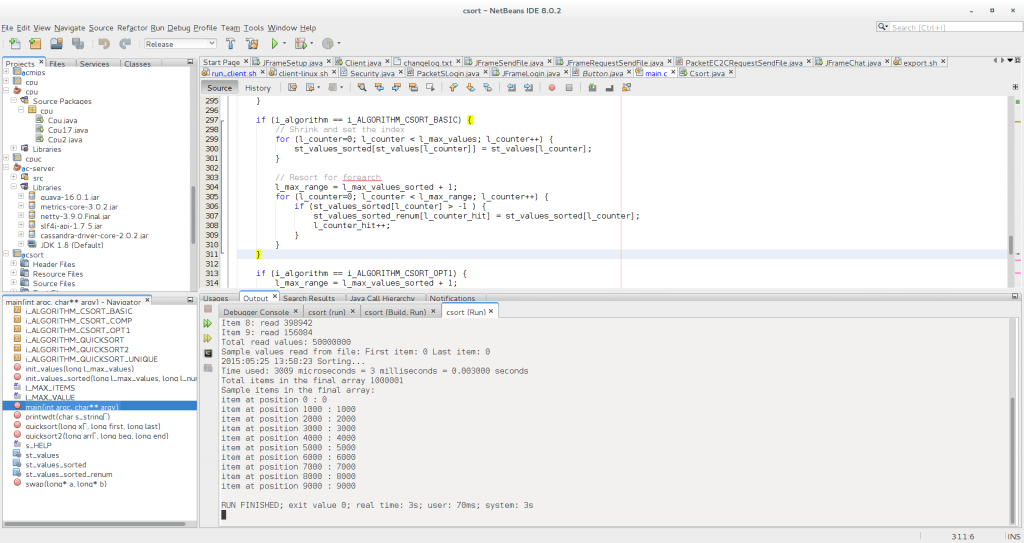
Probably this represents better the idea of beating quicksort: csort 0.003 seconds vs ~10 seconds quicksort.
My solution 3: supporting linked data
Image we have a numeric array with unique values, for example id, and another String array with the names.
For example:
st_values[0] = 1500000; st_names[0] = “Larry Page”;
st_values[1] = 731207; st_names[1] = “Sergey Brin”;
st_values[2] = 23788889; st_names[2] = “Steve Wozniak”;
st_values[3] = 5127890; st_names[3] = “Bill Gates”;
st_values[1000] = 5127890; st_names[1000] = “Alan Turing”;
st_values[10000] = 73215; st_names[10000] = “Grace Hopper”;
st_values[100000] = 218919; st_names[100000] = “Jean E. Sammet”;
Instead of doing:
st_sorted[1500000] = 1500000;
st_values[731207] = 731207;
…
We will do:
st_sorted[1500000] = 0;
st_values[731207] = 1;
st_values[23788889] = 2;
…
So, we will have csorted for the id, but the value will be pointed to the linked data in st_names[].
This can be used too with csort optimized reading and saving the use in memory of the array st_values[]. Obviously st_names[] must be kept.
My solution 4: csort with compression and supporting duplicates
csort is very quick for sorting and removing duplicates. But what happens if we want to sort and keep the duplicates?
The algorithm csort with compression what does is:
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
for (l_counter=0; l_counter < l_max_values; l_counter++) {
l_value = st_values[l_counter];
st_values_sorted[l_value] = st_values_sorted[l_value] + 1;
}
l_counter_hit = l_max_values_sorted + 1;
}
So, it assigns the index, as the other versions of csort, but instead of assigned the same value as the index, it is assigned the number of times that this value is found.
So, assuming we have a list like this:
{0,10,15,0,3,5,21,5,100000,0,7,5}
It will produce:
st_values[0] = 3;
st_values[1] = 0;
st_values[2] = 0;
st_values[3] = 1;
st_values[4] = 0;
st_values[5] = 3;
st_values[6] = 0;
st_values[7] = 1;…
st_values[100000] = 1;
From this Array it is possible to get the original linked list sorted easily:
{0,0,0,3,5,5,5,7,10,15,21,100000}
Now, take the first universe of data 50M items, with ranges 0-1M, and you get that you have compressed an originally unsorted array of 50M items into a sorted array of 1M items (1,000,001 to be exact) and you can still access by index. So a compression of 50 to 1, for this universe of numbers. (As you are thinking that won’t compress, but use more space, if the range of numbers is bigger than the number of items.)
If your values repeat a lot, and you have a huge set of items to sort, like in Big Data, this algorithm is wonderful and have huge memory savings and amazing speedy random access to data.
The idea, as mentioned before, is to do not load the data into an Array, and then sort, but to assigning using csort when reading data from disk. That way instead of having an Array of 50M and another of 1M, we would have only a single Array of 1M.
This is the relation of times for the universe 50M, 0-1M:
- csort basic: 0.553 seconds
Please note: this sample including the time to generate a array like a list: st_values_sorted_renum, so the time just to create the csorted array is ~3ms less
- csort opt read: 0.003 seconds
- csort with compression and duplicates support: 0.883 seconds
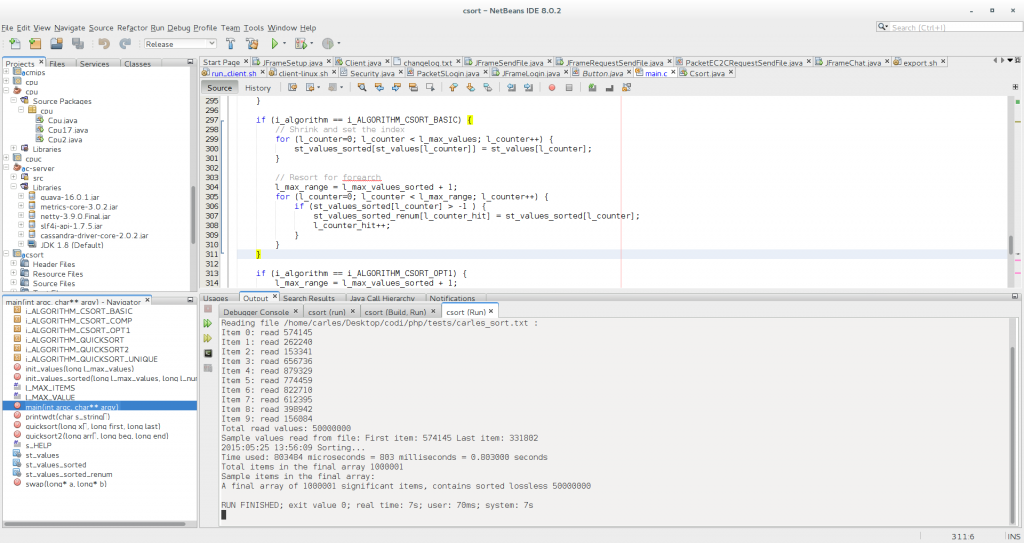
But awesome news are that the csort with compression can be implemented on the load time, like csort opt read.
Additional improvements
1) Using overlay to save Memory and run even faster
Ideally min(m) and max(m) should be calculated.
Imagine that you have a universe of data composed by id driver licenses. Guess that those numbers range from 140,000,000 to 190,000,000.
There is no need have create an array of 190M items. Just create an array of 50M, (max(m) – min(m)) and save an overlay to a variable.
l_overlay = 140000000;
Then simply do your loops from 0 to max(m) – l_overlay and when you’re building the final linked list or the sequentially ordered final array add l_overlay to each value.
You will save memory and increase speed.
2) Hybrid universes / spaces
Guess you have a hybrid universe, composed by let’s say 75% of your values in the range of 0-1M and 25% of your values being frontier values, f.e. between 35M and 900M.
// Last value covered by the csort
long l_last_frontier = 1000000;
long l_counter_unsorted_array = 0;
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
exit(EXIT_FAILURE);
}
if (l_number > l_last_frontier) {
st_values_unsorted[l_counter_unsorted_array] = l_number;
l_counter_unsorted_array++;
} else {
st_values[l_number] = l_number;
}
l_counter++;
if (l_counter > l_max_values -1) break;
}
You can then sort the 25% with another algorithm and merge the csorted array (it goes first) and the 25% (bigger values, go later), now sorted Array, and you’ll have benefit from a 75% super-fast sorting.
3) Hybrid sort big-O
For my tests, as long as you have memory, you can csort up to n * 10, and have significant time saving respect Quicksort. So if you have a really huge universe you can implement a hybrid algorithm that sorts up to m = n * 10 (l_last_frontier = n * 10) and use another algorithm to sort the rest >m. Finally just add the sorted second block to the sorted from first block results.
4) Hybrid sorting, with undetermined n and m
If you don’t know how long will be your space, like in a mapreduce, or the max value, you can also use the hybrid approach and define an array big enough, like 10M. If your arrays are based on long int, so using 4 bytes per position, it will take only 38 Mbytes of RAM. Peanuts. (Use the l_last_frontier seen in the point before just in case you have bigger values)
When you’re loading the data, and csorting using csort opt read, keep a variable with the max and min values found, so you’ll not have to parse all the 10M, just from min-max in order to generate a final sorted, deduplicated, list or array.
It’s up to you to fine tune and adjust the size for the minimum memory consumption and maximum efficiency according to the nature of your data.
5) Using less memory
If you have stored the data to sort in a Collection, you can reduce an item one by one, so you will save memory for huge amounts of Data. So, you can add that item to csort resulting array, and eliminate from the Collection/LinkedList source. One by one. That way you’ll save memory. With the sample of 50M registers with 1M different random values, it passes from 400MB* of RAM to 4MB of RAM in C. (* I’m calculating here a Linked List structure of 2 Long Data-type, one for the value and another for next item, in C. In other languages gain can be even more spectacular)
csort and Big Data
With the progression of Big Data we are finding ourselves with seas of data. Those universe of data tend to have a much bigger number of registers (n) than the range of values (m).
For example, in the case of devices monitoring temperatures every second, we will have 3,600 rows per hour, 86,400 rows per day, 31,536,000 per year while the range of values read will be a very stable subset, like from 19.0 to 24.0 C. In this example, multiplying the float value per 10 to work always with Integers, we would be working with a subset of 190-240, so m would be 51 if optimized, or 0-240 if not. If we want to get the unique temperatures for the past year, csort will generate just an Array of 51 items, crushing any ordering algorithm in space and time.
The bigger the Data is, the faster csort will perform compared to other sorting algorithms.
The complete code in C
This is the complete source code. It supports all the cases and you can invoke it from command line with a parameter for the case number you want to test.
/*
* File: main.c
* Author: Carles Mateo
*
* Created on 2015-05-14 16:45
*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/time.h>
#include <string.h>
/*
* Change does values for your tests, and recompile it
*/
#define l_MAX_ITEMS 50000000
#define l_MAX_VALUE 1000000
static int const i_ALGORITHM_QUICKSORT = 1;
static int const i_ALGORITHM_QUICKSORT_UNIQUE = 2;
static int const i_ALGORITHM_QUICKSORT2 = 3;
static int const i_ALGORITHM_CSORT_BASIC = 7;
static int const i_ALGORITHM_CSORT_OPT1 = 8;
static int const i_ALGORITHM_CSORT_COMP = 9;
#define s_HELP "CSort by Carles Mateo\n"\
"=====================\n"\
"\n"\
"This demonstrates a sort algorithm faster than quicksort,\n"\
"as proposed in the article.\n"\
"Please read the complete article at:\n"\
"http://blog.carlesmateo.com\n"\
"\n"\
"Please invoke the program with one of these parameters:\n"\
"\n"\
"--help or without parameters for this help message\n"\
"1 To test using quicksort\n"\
" Only sorts, does not deletes duplicates\n"\
"2 To test using quicksort and removing duplicates\n"\
"3 To test using another implementation of quicksort\n"\
" Only sorts, does not deletes duplicates\n"\
"7 To test using csort (basic example, sorts and deletes duplicates)\n"\
"8 To test using csort, improvement with indexes assigned when reading\n"\
" Use to watch the time saving from basic csort\n"\
"9 To test using csort, with indexes assigned when reading and counting\n"\
" the number of coincidences (compressed output array)\n"\
"\n"\
"Please, make sure that the file carles_sort.txt is present in the\n"\
"current directory.\n"\
"\n"
// Allocate in the BSS segment, which is a part of the heap
static long st_values[l_MAX_ITEMS];
// Only max value is required
static long st_values_sorted[l_MAX_VALUE];
static long st_values_sorted_renum[l_MAX_VALUE];
int init_values(long l_max_values);
void quicksort(long x[l_MAX_ITEMS], long first, long last);
void quicksort2(long arr[], long beg, long end);
void swap(long *a, long *b);
void printwdt(char s_string[]);
int init_values(long l_max_values) {
long l_counter = 0;
for (l_counter = 0; l_counter < l_max_values; l_counter++) {
// Init to -1
st_values[l_counter] = -1;
}
}
int init_values_sorted(long l_max_values, long l_num) {
long l_counter = 0;
for (l_counter = 0; l_counter < l_max_values; l_counter++) {
// Init to -1
st_values_sorted[l_counter] = l_num;
}
}
// Quicksort modified from original sample from http://www.cquestions.com/2008/01/c-program-for-quick-sort.html
void quicksort(long x[l_MAX_ITEMS], long first, long last){
long pivot,j,temp,i;
if (first<last) {
pivot=first;
i=first;
j=last;
while(i<j){
while(x[i]<=x[pivot]&&i<last)
i++;
while(x[j]>x[pivot])
j--;
if(i<j){
temp=x[i];
x[i]=x[j];
x[j]=temp;
}
}
temp=x[pivot];
x[pivot]=x[j];
x[j]=temp;
quicksort(x,first,j-1);
quicksort(x,j+1,last);
}
}
// Modified by Carles Mateo to use long based on http://alienryderflex.com/quicksort/
void quicksort2(long arr[], long beg, long end)
{
if (end > beg + 1)
{
long piv = arr[beg], l = beg + 1, r = end;
while (l < r)
{
if (arr[l] <= piv)
l++;
else
swap(&arr[l], &arr[--r]);
}
swap(&arr[--l], &arr[beg]);
quicksort2(arr, beg, l);
quicksort2(arr, r, end);
}
}
void swap(long *a, long *b)
{
long t=*a; *a=*b; *b=t;
}
/* print with date and time
*/
void printwdt(char s_string[]) {
time_t timer;
char buffer[26];
struct tm* tm_info;
time(&timer);
tm_info = localtime(&timer);
strftime(buffer, 26, "%Y-%m-%d %H:%M:%S", tm_info);
printf("%s %s\n", buffer, s_string);
}
int main(int argc, char** argv) {
char s_filename[] = "carles_sort.txt";
long l_max_values = l_MAX_ITEMS;
long l_max_values_sorted = l_MAX_VALUE;
char s_ch;
FILE *o_fp;
long l_counter=0;
long l_counter_hit=0;
long l_number;
int b_exit = 0;
int i_fitems_read = 0;
int i_algorithm = 0;
// Small counter for printing some final results
int i_counter=0;
// temp value for the final print
long l_value=0;
// Used for counting the number of results on optimized array
long l_total_items_sorted = 0;
long l_max_range;
long l_items_found = 0;
if (argc < 2) {
printf(s_HELP);
exit(EXIT_SUCCESS);
}
printwdt("Starting program...");
if (strcmp(argv[1], "1") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT;
printwdt("Algorithm: Quicksort with duplicates");
} else if (strcmp(argv[1], "2") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT_UNIQUE;
printwdt("Algorithm: Quicksort removing duplicates");
} else if (strcmp(argv[1], "3") == 0) {
i_algorithm = i_ALGORITHM_QUICKSORT2;
printwdt("Algorithm: Quicksort alternative");
} else if (strcmp(argv[1], "7") == 0) {
i_algorithm = i_ALGORITHM_CSORT_BASIC;
printwdt("Algorithm: csort basic");
} else if (strcmp(argv[1], "8") == 0) {
i_algorithm = i_ALGORITHM_CSORT_OPT1;
printwdt("Algorithm: csort optimized read");
} else if (strcmp(argv[1], "9") == 0) {
i_algorithm = i_ALGORITHM_CSORT_COMP;
printwdt("Algorithm: csort compress");
}
if (i_algorithm == 0) {
printf(s_HELP);
exit(EXIT_SUCCESS);
}
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT2) {
// Use this if you want to make tests with partial data to find the end of the values
//printf("Initializing %li values to -1...\n", l_max_values);
//init_values(l_max_values);
}
if (i_algorithm == i_ALGORITHM_CSORT_BASIC || i_algorithm == i_ALGORITHM_CSORT_OPT1 || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
// We init to -1 as it could happen that some indexes have not a value,
// and we want to know what's the case.
printf("Initializing %li values to -1...\n", l_max_values_sorted + 1);
init_values_sorted(l_max_values_sorted + 1, -1);
}
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
printf("Initializing %li values_sorted to 0...\n", l_max_values_sorted + 1);
init_values_sorted(l_max_values_sorted + 1, 0);
}
o_fp = fopen(s_filename,"r"); // read mode
if( o_fp == NULL ) {
printf("File %s not found or I/O error.\n", s_filename);
perror("Error while opening the file.\n");
exit(EXIT_FAILURE);
}
printf("Reading file %s :\n", s_filename);
while( b_exit == 0 ) {
i_fitems_read = fscanf(o_fp, "%li", &l_number);
if (i_fitems_read < 1) {
printf("Unable to read item %li from file.\n", l_counter);
perror("File ended before reading all the items.\n");
exit(EXIT_FAILURE);
}
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE ||
i_algorithm == i_ALGORITHM_QUICKSORT2 ||
i_algorithm == i_ALGORITHM_CSORT_BASIC || i_algorithm == i_ALGORITHM_CSORT_COMP) {
st_values[l_counter] = l_number;
}
if (i_algorithm == i_ALGORITHM_CSORT_OPT1) {
st_values[l_number] = l_number;
l_total_items_sorted++;
}
if (l_counter < 10) {
// Echo the reads from the first 10 items, for debugging
printf("Item %li: read %li\n", l_counter, l_number);
}
l_counter++;
if (l_counter > l_max_values -1) break;
}
printf("Total read values: %li\n", l_counter);
printf("Sample values read from file: First item: %li Last item: %li\n", st_values[0], st_values[l_max_values -1]);
fclose(o_fp);
printwdt("Sorting...");
struct timeval time;
gettimeofday(&time, NULL); //This actually returns a struct that has microsecond precision.
long l_microsec_ini = ((unsigned long long)time.tv_sec * 1000000) + time.tv_usec;
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
quicksort(st_values, 0, l_MAX_ITEMS-1);
l_counter_hit = l_MAX_ITEMS;
}
if (i_algorithm == i_ALGORITHM_QUICKSORT2) {
quicksort2(st_values, 0, l_MAX_ITEMS-1);
l_counter_hit = l_MAX_ITEMS;
}
if (i_algorithm == i_ALGORITHM_QUICKSORT_UNIQUE) {
printwdt("Removing duplicates...");
l_counter_hit = 0;
long l_last_known_value = -1;
for (l_counter=0; l_counter < l_max_values; l_counter++) {
if (l_last_known_value != st_values[l_counter]) {
l_last_known_value = st_values[l_counter];
st_values_sorted_renum[l_counter_hit] = st_values[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_BASIC) {
// Shrink and set the index
for (l_counter=0; l_counter < l_max_values; l_counter++) {
st_values_sorted[st_values[l_counter]] = st_values[l_counter];
}
// Resort for forearch
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > -1 ) {
st_values_sorted_renum[l_counter_hit] = st_values_sorted[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_OPT1) {
l_max_range = l_max_values_sorted + 1;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values[l_counter] > -1 ) {
st_values_sorted_renum[l_counter_hit] = st_values[l_counter];
l_counter_hit++;
}
}
}
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
for (l_counter=0; l_counter < l_max_values; l_counter++) {
l_value = st_values[l_counter];
st_values_sorted[l_value] = st_values_sorted[l_value] + 1;
}
l_counter_hit = l_max_values_sorted + 1;
}
struct timeval time_end;
gettimeofday(&time_end, NULL); //This actually returns a struct that has microsecond precision.
long l_microsec_end = ((unsigned long long)time_end.tv_sec * 1000000) + time_end.tv_usec;
long l_microsec_total = l_microsec_end - l_microsec_ini;
long l_milliseconds_total = l_microsec_total / 1000;
double f_seconds = (double)l_milliseconds_total / 1000;
printf("Time used: %li microseconds = %li milliseconds = %f seconds \n", l_microsec_total, l_milliseconds_total, f_seconds);
printf("Total items in the final array %li\n", l_counter_hit);
printf("Sample items in the final array:\n");
if (i_algorithm == i_ALGORITHM_CSORT_COMP) {
l_max_range = l_max_values_sorted + 1;
l_counter_hit = 0;
for (l_counter=0; l_counter < l_max_range; l_counter++) {
if (st_values_sorted[l_counter] > 0) {
l_counter_hit++;
l_items_found = l_items_found + st_values_sorted[l_counter];
}
}
printf("A final array of %li significant items, contains sorted lossless %li\n", l_counter_hit, l_items_found);
} else {
for (i_counter=0; i_counter<10000; i_counter=i_counter+1000) {
/* if (st_values_sorted[i_counter] > -1) {
// If you enjoy looking at values being printed or want to debug :)
printf("item at position %i : %li\n", i_counter, st_values_sorted[i_counter]);
}*/
if (i_algorithm == i_ALGORITHM_QUICKSORT || i_algorithm == i_ALGORITHM_QUICKSORT2) {
l_value = st_values[i_counter];
} else {
l_value = st_values_sorted_renum[i_counter];
}
printf("item at position %i : %li\n", i_counter, l_value);
}
}
return (EXIT_SUCCESS);
}
My solution in PHP
As told before I have implemented my algorithm in PHP, and it outperforms by much the PHP native functions (PHP sort() is a quicksort algorithm written in C, and unique() ). I explain everything below for the PHP lovers, is the same than in C, but with special considerations for PHP language. Even in PHP the efficiency of the algorithm is clearly demonstrated.
Warning, do not attempt to run the PHP code as is in your machine unless you have at least 16 GB of RAM. If you have 8 GB RAM you should reduce the scope to avoid your computer to hang up or swap very badly.
Printing of datetime is done by those functions:
function get_datetime() {
return date('Y-m-d H:i:s');
}
function print_with_datetime($s_string) {
echo get_datetime().' '.$s_string."\n";
}
So once we have our numbers generated we do a sort($st_test_values);
And we calculate the time elapsed with microtime for profiling:
$f_microtime_ini = microtime(true);
print_algorithm_type('PHP sort() method');
sort($st_test_array);
$f_microtime_end = microtime(true);
$f_microtime_resulting = $f_microtime_end - $f_microtime_ini;
echo "Microtime elapsed: $f_microtime_resulting\n";
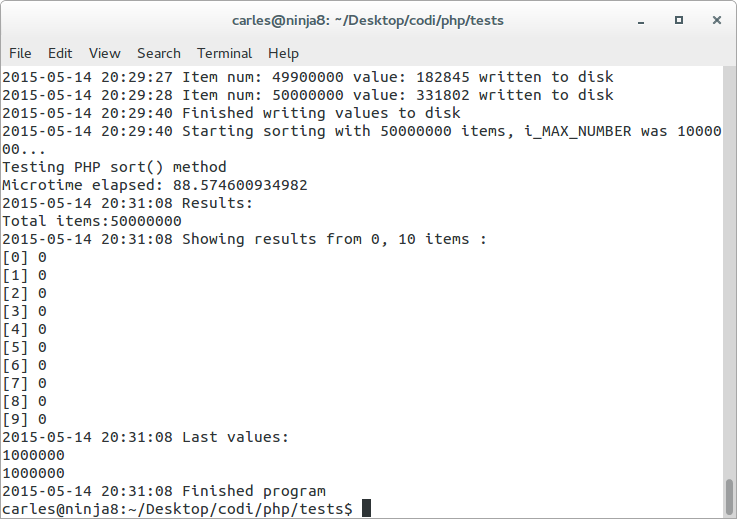 In this case we did a PHP sort(), and we didn’t even remove the duplicates and it takes 88.5 seconds.
In this case we did a PHP sort(), and we didn’t even remove the duplicates and it takes 88.5 seconds.
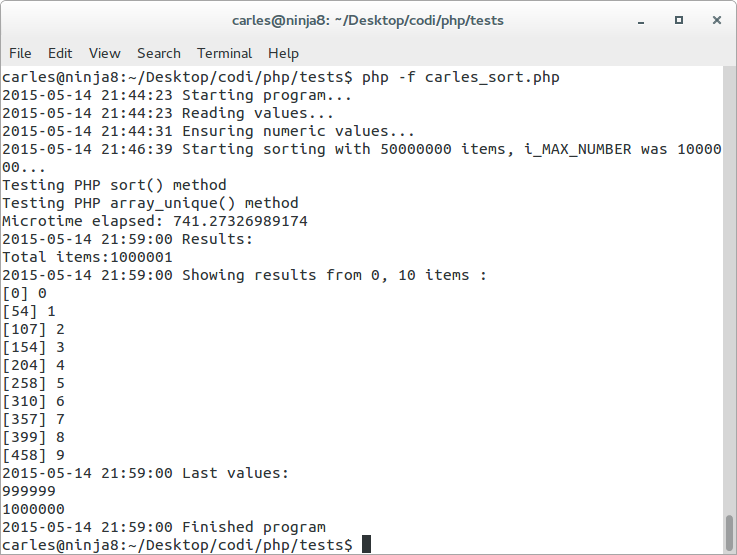
If we do a sort() and array_unique() to get the unique results sorted it takes: 741.27 seconds
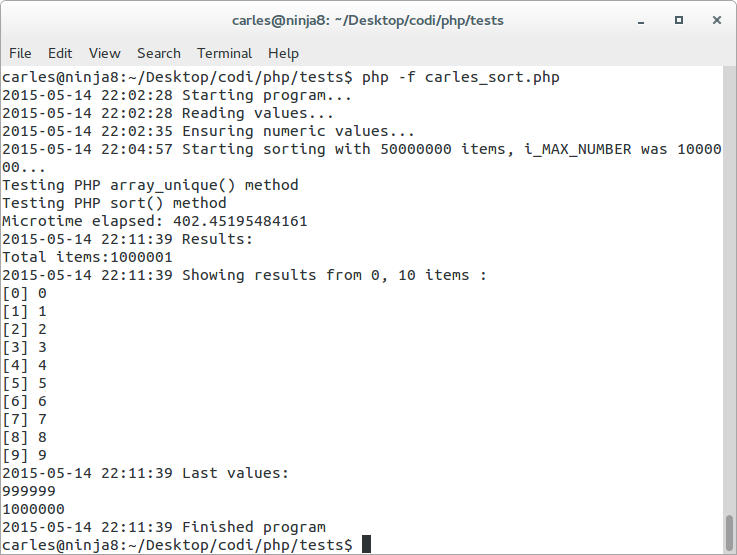
We do the opposite array_unique() and sort() and the result is: 402.45 seconds
 It takes a lot.
It takes a lot.
Please note that sorting and doing array_unique takes more time than doing in the opposite order.
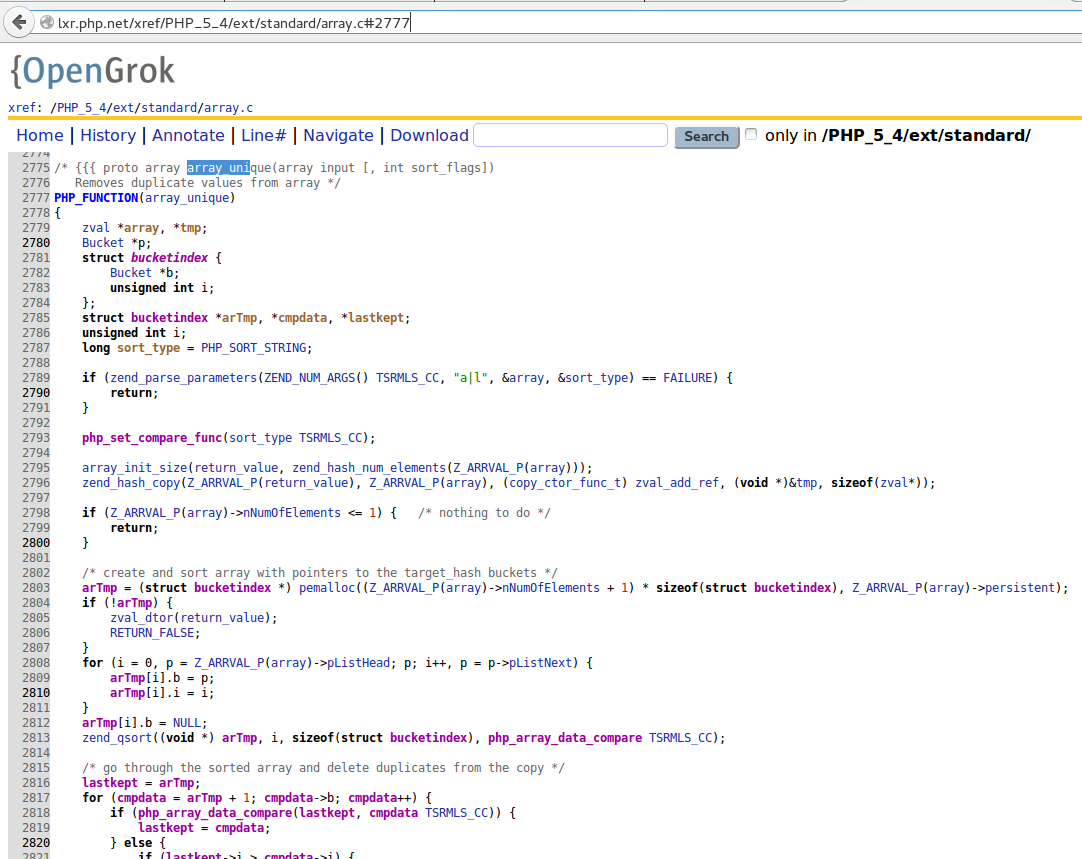
This is curious as one may thing that removing duplicates and sorting could be much faster than sorting and removing duplicates, but just sorting takes 88 seconds. I found the explanation looking at the source Source Code of PHP array_unique. Internally it sorts the array (zend_qsort line 2813) for removing the duplicates.
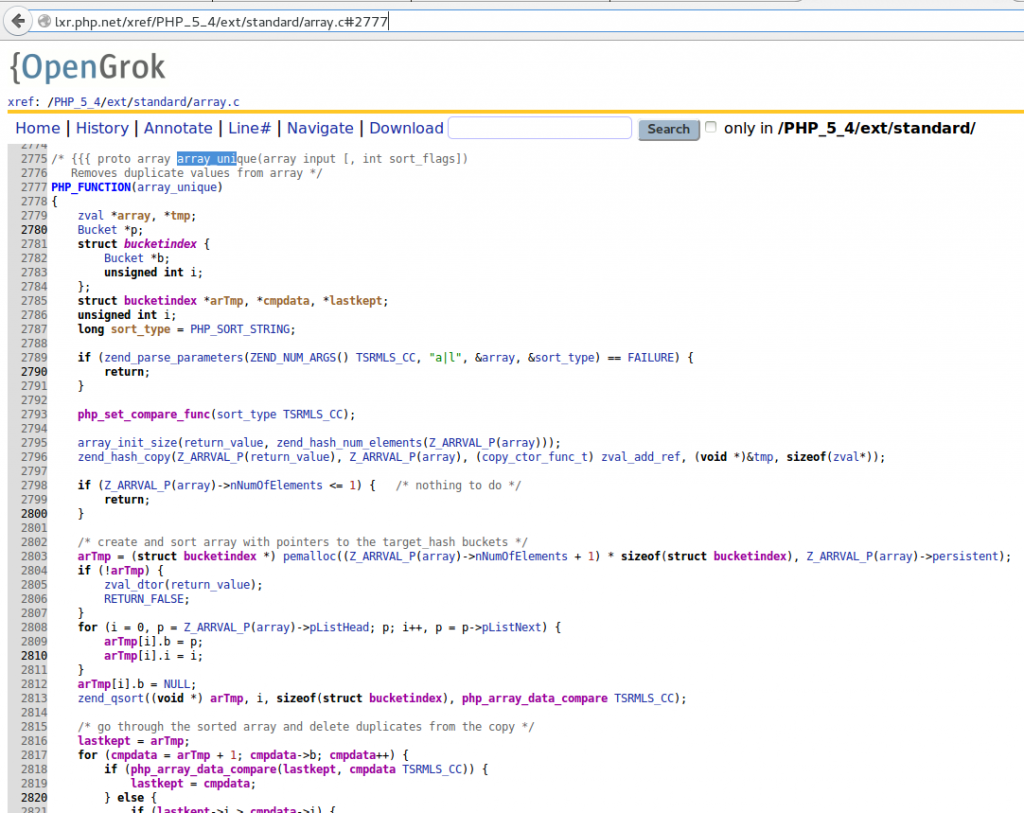 So well, we were sorting twice, and sorting a sorted array. This is the worst case for quicksort, so that explains the slowlyness.
So well, we were sorting twice, and sorting a sorted array. This is the worst case for quicksort, so that explains the slowlyness.
Then it enters what I engined. PHP works with arrays, that can have a numeric index. So my point is: the fastest way to sort an array is… not sorting it at all.
We know that the range of values we have is much smaller than the number of registers:
- We have values between 0 and 1,000,000
- We have 50,000,000 of registers
PHP sort() function is written in C, so it should be fastest than any thing we program in PHP. Should be…. really?.
Knowing that the values are 0-1M and the registers are 50M, and knowing the number of operations that a quick sort will do, I figured another way to improve this.
Look at this code:
function csort($st_test_array) {
$s_algorithm = 'Carles_Sort';
echo "Testing $s_algorithm\n";
$i_loop_counter = 0;
$st_result_array = Array();
$i_ending_pos = count($st_test_array);
for($i_pos = 0; $i_pos < $i_ending_pos; $i_pos++) {
$i_loop_counter++;
$i_value = $st_test_array[$i_pos];
$st_result_array[$i_value] = $i_value;
}
return $st_result_array;
}
So, the only think I’m doing is looping the 50M array and in a new array $st_result_array setting the key to the same value, than the integer value. So if the original $st_test_array[0] is equal to 574145, then I set st_result_array[574145] = 574145. Easy.
Think about it.
With this we achieve three objectives:
- You eliminate duplicates. With 50M items, with values ranged from 0 to 1M you’ll set a value many times. No problem, it will use it’s index.
- We have the key assigned, matching the value, so you can reference every single value
- It’s amazingly faster. Much more than any sorting even in C
If you do a var_export or var_dump or print_r or a foreach you will notice that the first item of the array has key 574145 and value 574145, the second 262240, the third 153341, the fourth 656736 and the fifth 879329. They are not ordered in the way that one will think about an ordered array parsed with foreach(), but the thing is: do we need to sort it?. Not really. Every key is a hash that PHP will access very quickly. So we can do something like this to get the results ordered:
$i_max_value = max($st_result_array);
for($i_pos = 0; $i_pos <= $i_max_value; $i_pos++) {
if (isset($st_result_array[$i_pos])) {
$st_result_array2[] = $i_pos;
}
}
In this code we create a new array, with the values sorted in the sense that a foreach will return them sorted. But instead of recurring 50M registers, we only go to the max value (as values and indexes are the same, the max value also shows the max index), because we now don’t have 50M registers as we eliminated the duplicates, but 1M. And in an universe of 50M values from a range 0-1M, many are duplicates.
Even doing this second step still makes this sorting algorithm written in PHP, much more efficient than the quicksort written in C.
I ported the code to C, with the same data file, and it takes 0.674 seconds (674 milliseconds) and it uses only ~1 GB of RAM.
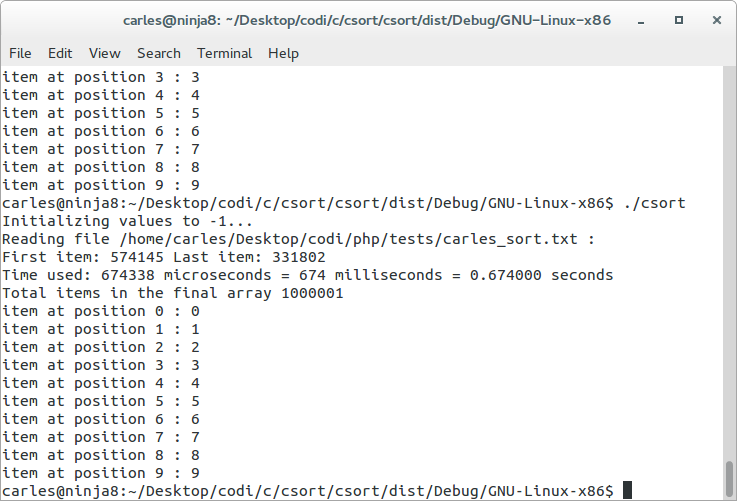 Take in consideration that if the data is directly loaded assigning the right index, so doing like in the next code, it will be blazing fast:
Take in consideration that if the data is directly loaded assigning the right index, so doing like in the next code, it will be blazing fast:
o_fp = fopen(s_filename,"r"); // read mode
if( o_fp == NULL ) {
printf("File %s not found or I/O error.\n", s_filename);
perror("Error while opening the file.\n");
exit(EXIT_FAILURE);
}
printf("Reading file %s :\n", s_filename);
while( 1 ) {
fscanf(o_fp, "%li", &l_number);
// The key is here ;)
st_values[l_number] = l_number;
l_counter++;
if (l_counter > l_max_values -1) break;
}
printf("First item: %li Last item: %li\n", st_values[0], st_values[l_counter-1]);
fclose(o_fp);
So if we only resort in another array to have the values sorted eliminating the non existing values (half the tasks we do in the previous program), it takes and order of milliseconds.
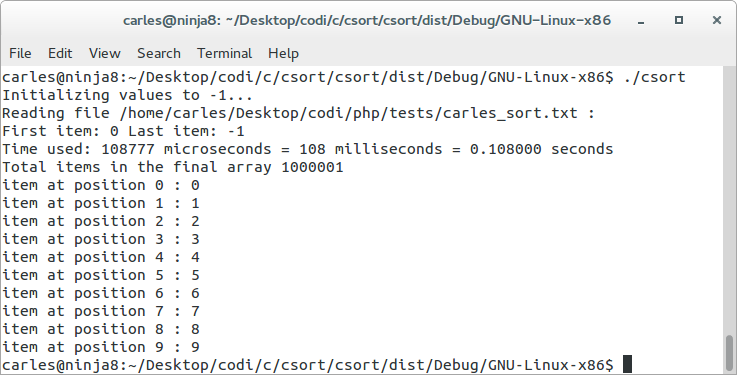
Using csort opt read with a busy computer (firefox using 16 GB RAM and many tabs) it takes 108 ms, with a idle computer 3 ms
Now imagine you don’t want to eliminate the duplicates.
You can create an memory optimized array where the index is the number, and the value represents the number of apparitions in the original file:
$st_example = Array( 0 => 1,
3 => 5,
4 => 1);
That would mean that the original sorted array, in form of list would be:
{0, 3, 3, 3, 3, 3, 4}
For the case of C, where the arrays have static size, a value of 0 would indicate there is no presence of that number in the orderer list so:
st_example[0] = 1;
st_example[1] = 0;
st_example[2] = 0;
st_example[3] = 5;
st_example[4] = 1;
Even in the case of the resulting C array, it will be much smaller than the original 50M Array, as will have only the size corresponding to the max value. In our sample 1M.
In PHP you can get an Array alike the csort compressed by using a function called array_count_values(). It will not have the non existing items = 0, so it would not generate st_example[1] = 0 neither st_example[2] = 0, but it would generate the others.
So conditions for the algorithm to work blazing fast:
- The max number (max(m)) must be ideally lower than the number of registers (this is true for languages like C or Java. Languages like PHP grow dynamically the Array size and work as Array Hash, so it’s not necessary as we can have st_sorted[0] and st_sorted[1000000] and the array size will be only 2 items. In this case we can use less memory than the csort algorithm and be faster using foreach() instead as for() from 0 to 1M)
- The most numbers that are repeated, the faster that will work the algorithm
Key conclusions and Advantages:
- If you directly load the values form disk assigning the value as a key as well, you’ll save one loop per item (n=50M in this universe) and make it faster (having only to parse count(m), in PHP it doesn’t have to be 0-m).
- The fastest way to sort it, is no sorting at all. You can have the values stored per key, even if a foreach doesn’t start by 0,1,2… simply accessing the value index you need will be super-fast.
Source code in PHP
PHP under HHVM
Additionally I executed the csort.php in the Facebook’s Hip Hop Virtual Machine, version 3.4.0-dev, and as expected everything is much faster than with PHP standard.
For example:
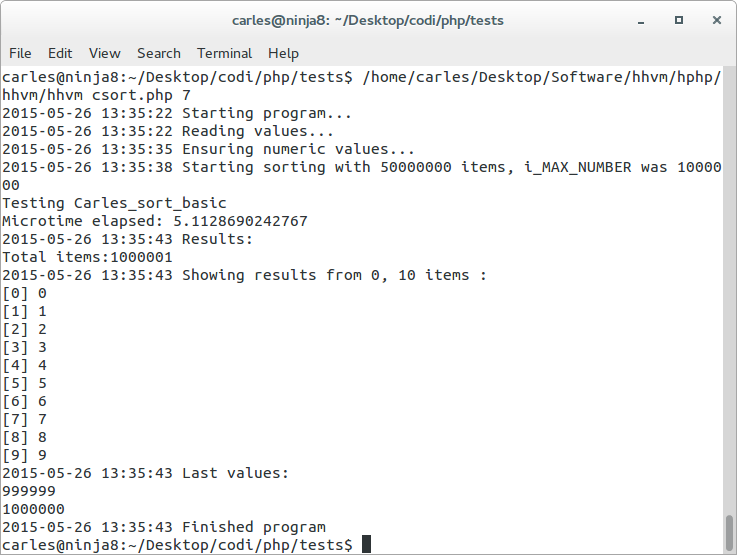
- Using PHP sort() 88-104 seconds, using HHVM PHP sort() 15.8 seconds
- Using csort basic from PHP 34 to 40 seconds, using csort basic from HHVM 3.4 to 5.13 seconds
The version of PHP used for these tests was:
PHP 5.5.9-1ubuntu4.9 (cli) (built: Apr 17 2015 11:44:57)
Copyright (c) 1997-2014 The PHP Group
Zend Engine v2.5.0, Copyright (c) 1998-2014 Zend Technologies
with Zend OPcache v7.0.3, Copyright (c) 1999-2014, by Zend Technologies
The version of hhvm used for the test was:
HipHop VM 3.4.0-dev (rel)
Compiler: heads/master-0-g96dec459bb84f606df2fe15c8c82df684b20ed83
Repo schema: 0100f1aaeeacd7b9d9a369b34ae5160acb0d1163
Extension API: 20140829
Must also mention that some operations like initializing the arrays, are super-fast with HHVM.
The solution in Java
The code has been executed with Oracle’s JDK 1.7.
I love Just In Time compilers. They are amazingly fast.
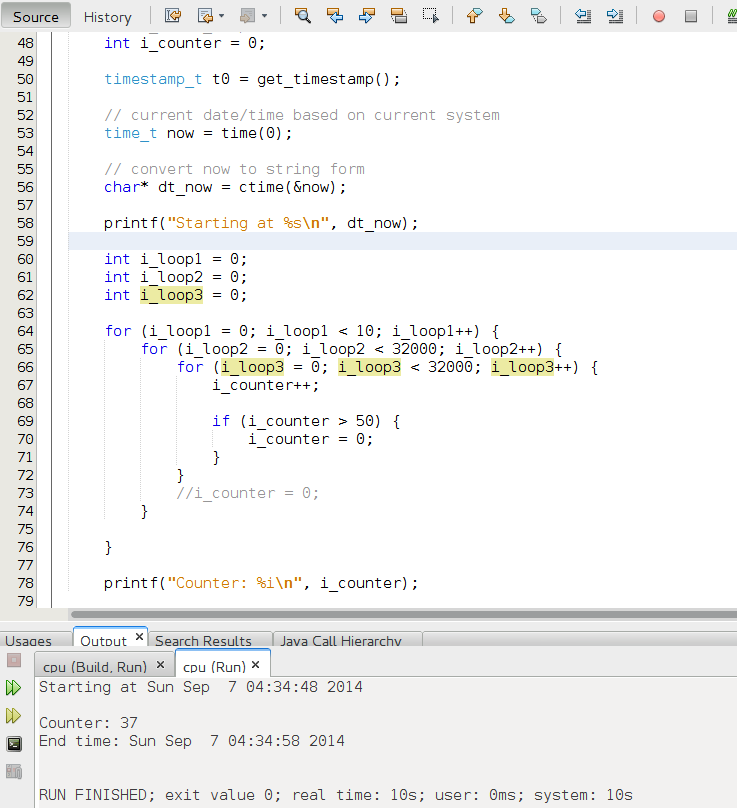
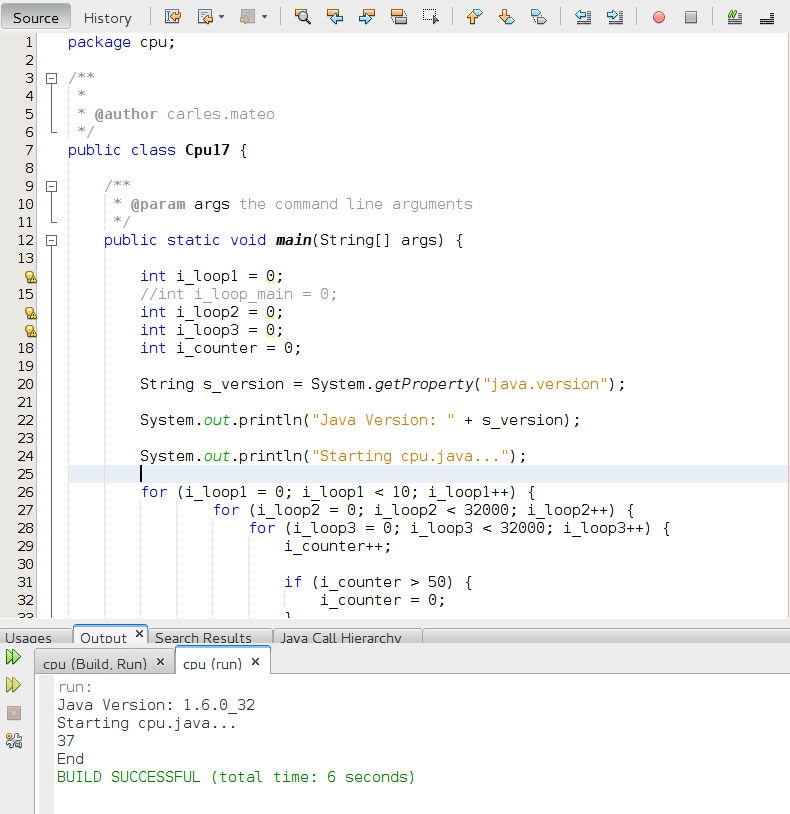
For this case, the results with Java, for the universe of 50M items, range 0-1M of values:
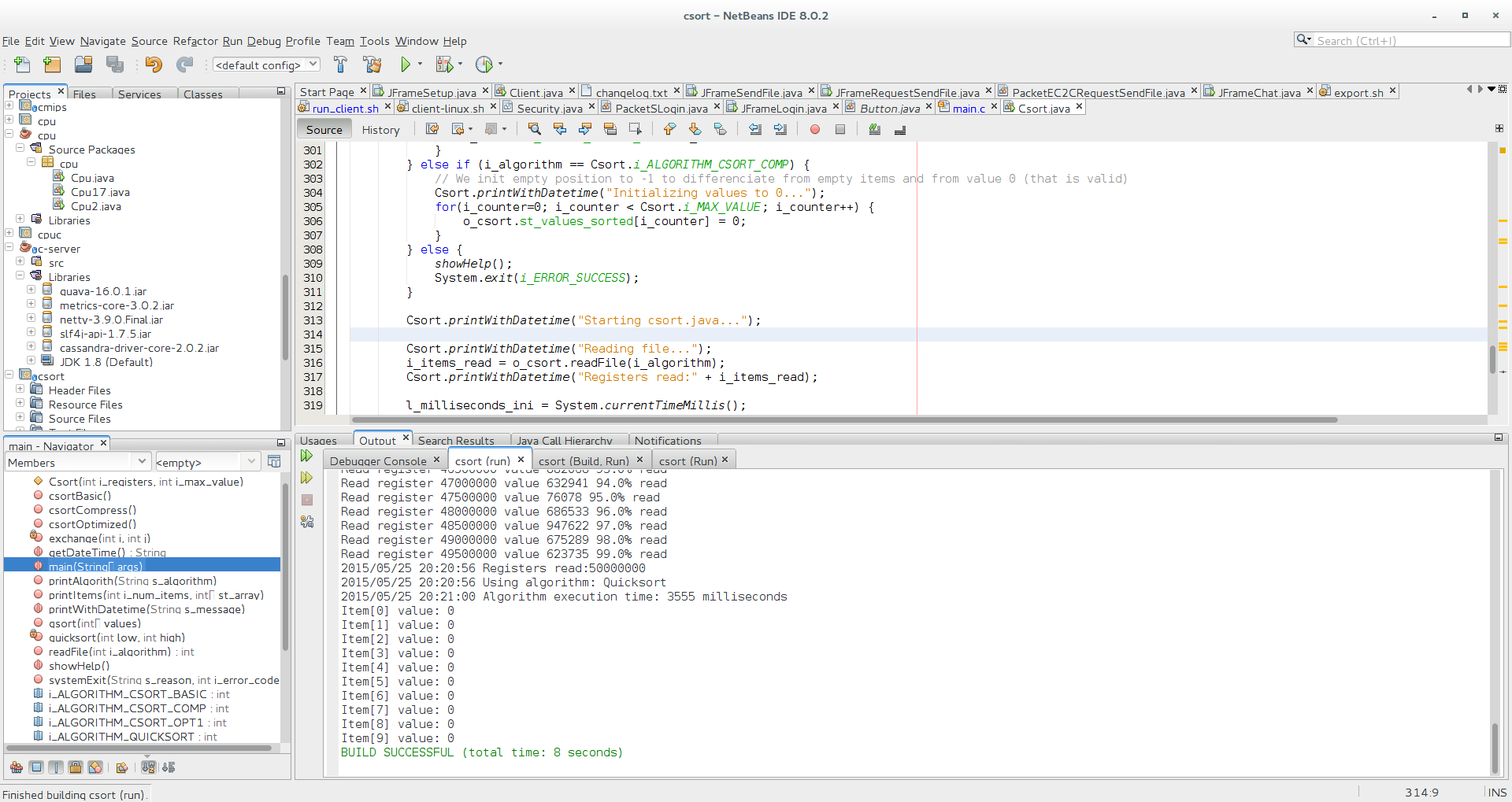
- quicksort in Java: 3555 ms =3.555 seconds versus ~10 seconds in C
Important: In C I had to disable -O2 optimization for what it looks like a bug in gcc (only detected in csort with compression). With -O2 times were around 4.7 seconds
- csort.java basic: 26 ms to 120 ms = 0.026 seconds versus 0.5 seconds csort in C
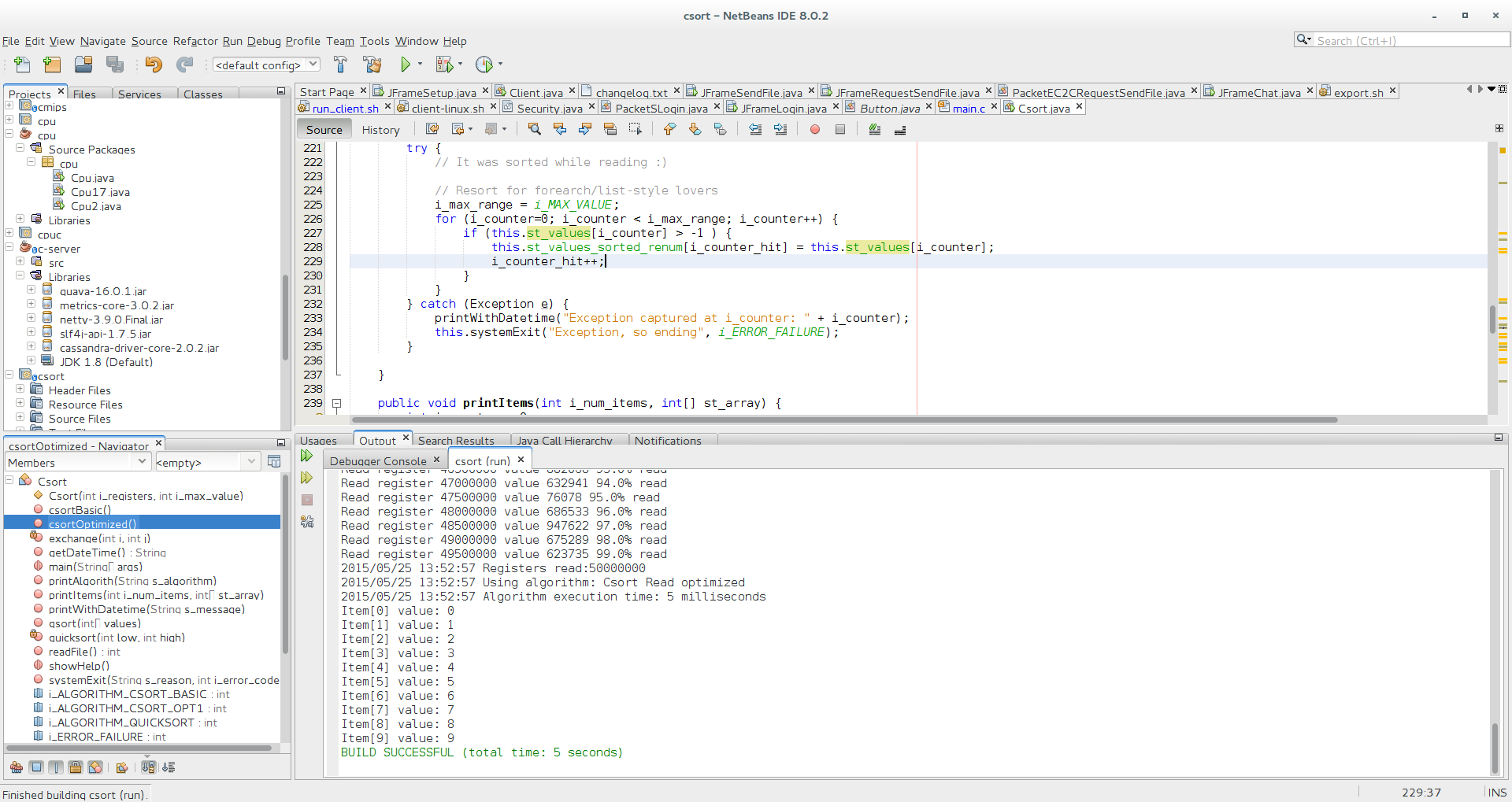
- csort.java opt read: 2-3 ms = 0.002-0.003 seconds versus 3 ms = 0.003 seconds in C
- csort.java with compression and duplicates support: 160 ms = 0.16 seconds versus 0.272-0.277 segons in C
- The execution on those languages (Java and C) is so fast that it’s hard to measure accurately as any random execution of Ubuntu in background will increase a bit the time.
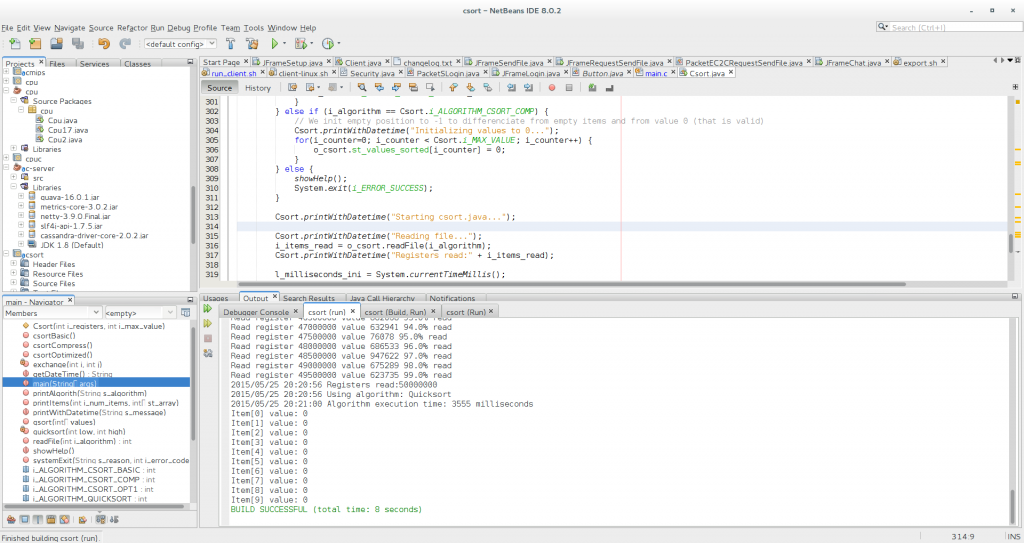
Quicksort in Java, 3555 ms = 3.555 seconds
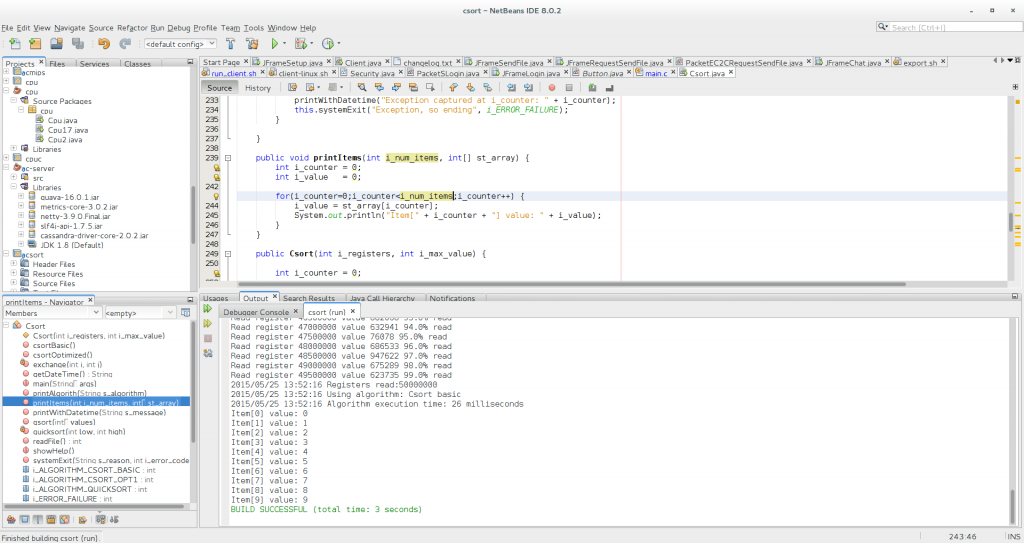
Csort basic with Java, 26 milliseconds

Csort read opt with Java, 5 milliseconds
The code in Java:
/*
* This code, except quicksort implementation, is written by Carles Mateo,
* and published as Open Source.
*/
package csort;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
*
* @author carles
*/
public class Csort {
public static final int i_MAX_REGISTERS = 50000000;
public static final int i_MAX_VALUE = 1000000;
public static final String s_FILE = "/home/carles/Desktop/codi/php/tests/carles_sort.txt";
public static final int i_ERROR_SUCCESS = 0;
public static final int i_ERROR_FAILURE = 1;
public static final int i_ALGORITHM_QUICKSORT = 1;
public static final int i_ALGORITHM_CSORT_BASIC = 7;
public static final int i_ALGORITHM_CSORT_OPT1 = 8;
public static final int i_ALGORITHM_CSORT_COMP = 9;
// Original values read
public int[] st_values;
// Our Csorted array
public int[] st_values_sorted;
// To resort as a alike list array
public int[] st_values_sorted_renum;
// For quicksort
private int[] numbers;
private int number;
public void systemExit(String s_reason, int i_error_code) {
printWithDatetime("Exiting to system, cause: " + s_reason);
System.exit(i_error_code);
}
public static String getDateTime() {
DateFormat o_dateformat = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
Date o_date = new Date();
return o_dateformat.format(o_date);
}
public static void printWithDatetime(String s_message) {
System.out.println(getDateTime() + " " + s_message);
}
public void printAlgorith(String s_algorithm) {
Csort.printWithDatetime("Using algorithm: " + s_algorithm);
}
public static void showHelp() {
String s_help = "" +
"CSort.java by Carles Mateo\n" +
"==========================\n" +
"\n" +
"This demonstrates a sort algorithm faster than quicksort,\n" +
"as proposed in the article.\n" +
"Please read the complete article at:\n" +
"http://blog.carlesmateo.com\n" +
"\n" +
"Please invoke the program with one of these parameters:\n" +
"\n" +
"--help or without parameters for this help message\n" +
"1 To test using quicksort\n" +
" Only sorts, does not deletes duplicates\n" +
"7 To test using csort (basic example, sorts and deletes duplicates)\n" +
"8 To test using csort, improvement with indexes assigned when reading\n" +
" Use to watch the time saving from basic csort\n" +
"\n" +
"Please, make sure that the file carles_sort.txt is present in the\n" +
"current directory.\n" +
"\n";
System.out.println(s_help);
}
public int readFile(int i_algorithm) {
BufferedReader br = null;
int i_value = 0;
int i_counter = 0;
try {
String sCurrentLine;
br = new BufferedReader(new FileReader(Csort.s_FILE));
while ((sCurrentLine = br.readLine()) != null) {
i_value = Integer.parseInt(sCurrentLine);
if (i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
this.st_values[i_value] = i_value;
} else {
this.st_values[i_counter] = i_value;
}
if (i_counter % 500000 == 0) {
float f_percent = ((float) i_counter / Csort.i_MAX_REGISTERS) * 100;
String s_percent_msg = "Read register " + i_counter + " value " + i_value + " " + f_percent + "% read";
System.out.println(s_percent_msg);
}
i_counter++;
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (br != null) br.close();
} catch (IOException ex) {
ex.printStackTrace();
this.systemExit("Error processing the file: " + Csort.s_FILE, Csort.i_ERROR_FAILURE);
}
}
return i_counter;
}
// http://www.vogella.com/tutorials/JavaAlgorithmsQuicksort/article.html
public void qsort(int[] values) {
// check for empty or null array
if (values == null || values.length == 0){
return;
}
this.numbers = values;
number = values.length;
quicksort(0, number - 1);
}
private void quicksort(int low, int high) {
int i = low, j = high;
// Get the pivot element from the middle of the list
int pivot = numbers[low + (high-low)/2];
// Divide into two lists
while (i <= j) {
// If the current value from the left list is smaller then the pivot
// element then get the next element from the left list
while (numbers[i] < pivot) {
i++;
}
// If the current value from the right list is larger then the pivot
// element then get the next element from the right list
while (numbers[j] > pivot) {
j--;
}
// If we have found a values in the left list which is larger then
// the pivot element and if we have found a value in the right list
// which is smaller then the pivot element then we exchange the
// values.
// As we are done we can increase i and j
if (i <= j) {
exchange(i, j);
i++;
j--;
}
}
// Recursion
if (low < j)
quicksort(low, j);
if (i < high)
quicksort(i, high);
}
private void exchange(int i, int j) {
int temp = numbers[i];
numbers[i] = numbers[j];
numbers[j] = temp;
}
// End of http://www.vogella.com/tutorials/JavaAlgorithmsQuicksort/article.html
public void csortBasic() {
int i_counter = 0;
int i_value = 0;
int i_max_range = 0;
int i_counter_hit = 0;
try {
for (i_counter=0; i_counter < i_MAX_REGISTERS; i_counter++) {
i_value = this.st_values[i_counter];
this.st_values_sorted[i_value] = i_value;
}
// Resort for forearch
i_max_range = i_MAX_VALUE;
for (i_counter=0; i_counter < i_max_range; i_counter++) {
if (this.st_values_sorted[i_counter] > -1 ) {
this.st_values_sorted_renum[i_counter_hit] = this.st_values_sorted[i_counter];
i_counter_hit++;
}
}
} catch (Exception e) {
printWithDatetime("Exception captured at i_counter: " + i_counter);
this.systemExit("Exception, so ending", i_ERROR_FAILURE);
}
}
public void csortOptimized() {
int i_counter = 0;
int i_value = 0;
int i_max_range = 0;
int i_counter_hit = 0;
try {
// It was sorted while reading :)
// Resort for forearch/list-style lovers
i_max_range = i_MAX_VALUE;
for (i_counter=0; i_counter < i_max_range; i_counter++) {
if (this.st_values[i_counter] > -1 ) {
this.st_values_sorted_renum[i_counter_hit] = this.st_values[i_counter];
i_counter_hit++;
}
}
} catch (Exception e) {
printWithDatetime("Exception captured at i_counter: " + i_counter);
this.systemExit("Exception, so ending", i_ERROR_FAILURE);
}
}
public void csortCompress() {
int i_counter = 0;
int i_value = 0;
for (i_counter=0; i_counter < i_MAX_REGISTERS; i_counter++) {
i_value = this.st_values[i_counter];
this.st_values_sorted[i_value] = this.st_values_sorted[i_value] + 1;
}
}
public void printItems(int i_num_items, int[] st_array) {
int i_counter = 0;
int i_value = 0;
for(i_counter=0;i_counter<i_num_items;i_counter++) {
i_value = st_array[i_counter];
System.out.println("Item[" + i_counter + "] value: " + i_value);
}
}
public Csort(int i_registers, int i_max_value) {
// int range is -2,147,483,648 to 2,147,483,647
this.st_values = new int[i_registers];
// If max value is 10 then we could have values from 0 to 10, so a 11 items Array
this.st_values_sorted = new int[i_max_value + 1];
this.st_values_sorted_renum = new int[i_max_value + 1];
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) {
long l_milliseconds_ini = 0;
long l_milliseconds_end = 0;
long l_milliseconds_total = 0;
int i_items_read = 0;
int i_algorithm = 0;
String s_algorithm = "";
int i_counter = 0;
/* Check parameter consistency */
if (args.length == 0 || args.length > 1 || (args.length == 1 && Integer.valueOf(args[0]) == 0)) {
showHelp();
System.exit(i_ERROR_SUCCESS);
}
i_algorithm = Integer.valueOf(args[0]);
Csort o_csort = new Csort(Csort.i_MAX_REGISTERS, Csort.i_MAX_VALUE);
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC || i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1 || i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
// We init empty position to -1 to differenciate from empty items and from value 0 (that is valid)
Csort.printWithDatetime("Initializing values to -1...");
for(i_counter=0; i_counter < Csort.i_MAX_VALUE; i_counter++) {
o_csort.st_values_sorted[i_counter] = -1;
o_csort.st_values_sorted_renum[i_counter] = -1;
}
} else if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
// We init empty position to -1 to differenciate from empty items and from value 0 (that is valid)
Csort.printWithDatetime("Initializing values to 0...");
for(i_counter=0; i_counter < Csort.i_MAX_VALUE; i_counter++) {
o_csort.st_values_sorted[i_counter] = 0;
}
} else {
showHelp();
System.exit(i_ERROR_SUCCESS);
}
Csort.printWithDatetime("Starting csort.java...");
Csort.printWithDatetime("Reading file...");
i_items_read = o_csort.readFile(i_algorithm);
Csort.printWithDatetime("Registers read:" + i_items_read);
l_milliseconds_ini = System.currentTimeMillis();
if (i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
s_algorithm = "Quicksort";
o_csort.printAlgorith(s_algorithm);
o_csort.qsort(o_csort.st_values);
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC) {
s_algorithm = "Csort basic";
o_csort.printAlgorith(s_algorithm);
o_csort.csortBasic();
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
s_algorithm = "Csort Read optimized";
o_csort.printAlgorith(s_algorithm);
o_csort.csortOptimized();
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
s_algorithm = "Csort compress with duplicates";
o_csort.printAlgorith(s_algorithm);
o_csort.csortCompress();
}
l_milliseconds_end = System.currentTimeMillis();
l_milliseconds_total = l_milliseconds_end - l_milliseconds_ini;
Csort.printWithDatetime("Algorithm execution time: " + l_milliseconds_total + " milliseconds");
if (i_algorithm == Csort.i_ALGORITHM_CSORT_BASIC || i_algorithm == Csort.i_ALGORITHM_CSORT_OPT1) {
o_csort.printItems(10, o_csort.st_values_sorted_renum);
}
if (i_algorithm == Csort.i_ALGORITHM_QUICKSORT) {
o_csort.printItems(10, o_csort.numbers);
}
if (i_algorithm == Csort.i_ALGORITHM_CSORT_COMP) {
o_csort.printItems(10, o_csort.st_values_sorted);
}
}
}
Note: This article is growing. I’ll be expanding the article, putting more samples, detailing timmings from different universes I’ve tested and screenshots, specially in the PHP section, to add more tricks and whys, but I wanted to put the base for being able to discuss with some colleagues.