In this very long session we went through actual errors in a ZFS pool, we check the Kernel, we remove and reinsert the drive, conduct zpool scrub… in the meantime I talked about Rack, Rack Servers, PSU, redundant components, ECC RAM…
So, I was working on a project and i wanted to test how long a file can be.
The resources I checked, and also the Kernel and C source I reviewed, were pointing that effectively the limit is 255 characters.
But I had one doubt… given that Python 3 String are UTF-8, and that Linux encode by default is UTF-8, will I be able to use 255 characters length, or this will be reduced as the Strings will be encoded as UTF-8 or Unicode?.
So I did a small Proof of Concept.
For the filenames I grabbed a fragment of the translation to English of the book epic book “Tirant lo Blanc” (The White Knight), one of the first books written in Catalan language and the first chivalry novel known in the world. You can download it for free it in:
from carleslibs.fileutils import FileUtils
from colorama import Fore, Back, Style , init
class ColorUtils:
def __init__(self):
# For Colorama on Windows
init()
def print_error(self, s_text, s_end="\n"):
"""
Prints errors in Red.
:param s_text:
:return:
"""
print(Fore.RED + s_text)
print(Style.RESET_ALL, end=s_end)
def print_success(self, s_text, s_end="\n"):
"""
Prints errors in Green.
:param s_text:
:return:
"""
print(Fore.GREEN + s_text)
print(Style.RESET_ALL, end=s_end)
def print_label(self, s_text, s_end="\n"):
"""
Prints a label and not the end line
:param s_text:
:return:
"""
print(Fore.BLUE + s_text, end="")
print(Style.RESET_ALL, end=s_end)
def return_text_blue(self, s_text):
"""
Restuns a Text
:param s_text:
:return: String
"""
s_text_return = Fore.BLUE + s_text + Style.RESET_ALL
return s_text_return
if __name__ == "__main__":
o_color = ColorUtils()
o_file = FileUtils()
s_text = "In the fertile, rich and lovely island of England there lived a most valiant knight, noble by his lineage and much more for his "
s_text += "courage. In his great wisdom and ingenuity he had served the profession of chivalry for many years and with a great deal of honor, "
s_text += "and his fame was widely known throughout the world. His name was Count William of Warwick. This was a very strong knight "
s_text += "who, in his virile youth, had practiced the use of arms, following wars on sea as well as land, and he had brought many "
s_text += "battles to a successful conclusion."
o_color.print_label("Erasure Code project by Carles Mateo")
print()
print("Task 237 - Proof of Concep of Long File Names, encoded is ASCii, in Linux ext3 and ext4 Filesystems")
print()
print("Using as a sample a text based on the translation of Tirant Lo Blanc")
print("Sample text used:")
print("-"*30)
print(s_text)
print("-" * 30)
print()
print("This test uses the OpenSource libraries from Carles Mateo carleslibs")
print()
print("Initiating tests")
print("================")
s_dir = "task237_tests"
if o_file.folder_exists(s_dir) is True:
o_color.print_success("Directory " + s_dir + " already existed, skipping creation")
else:
b_success = o_file.create_folder(s_dir)
if b_success is True:
o_color.print_success("Directory " + s_dir + " created successfully")
else:
o_color.print_error("Directory " + s_dir + " creation failed")
exit(1)
for i_length in range(200, 512, 1):
s_filename = s_dir + "/" + s_text[0:i_length]
b_success = o_file.write(s_file=s_filename, s_text=s_text)
s_output = "Writing file length: "
print(s_output, end="")
o_color.print_label(str(i_length).rjust(3), s_end="")
print(" file name: ", end="")
o_color.print_label(s_filename, s_end="")
print(": ", end="")
if b_success is False:
o_color.print_error("failed", s_end="\n")
exit(0)
else:
o_color.print_success("success", s_end="\n")
# Note: up to 255 work, 256 fails
I tried this in an Ubuntu Virtual Box VM.
As part of my tests I tried to add a non typical character in English, ASCii >127, like Ç.
When I use ASCii character < 128 (0 to 127) for the filenames in ext3/ext4 and in a ZFS Pool, I can use 255 positions. But when I add characters that are not typical, like the Catalan ç Ç or accents Àí the space available is reduced, suggesting the characters are being encoded:
Ç has value 128 in the ASCii table and ç 135.
I used my Open Source carleslibs and the package colorama.
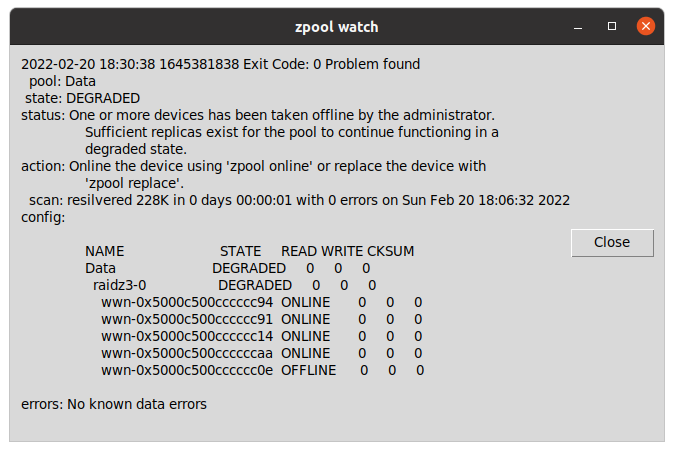
zpool watch is a small Python program for Linux workstations with graphical environment and ZFS, that checks every 30 seconds if your OpenZFS pools are Ok.
If a pool is not healthy, it displays a message in a window using tk inter.
Basically allows you to skip checking from the terminal zpool status continuously or to having to customize the ZED service to send an email and having to figure out how to it can spawn a window alert to the graphical system or what to do if the session has not been initiated.
carleslibs
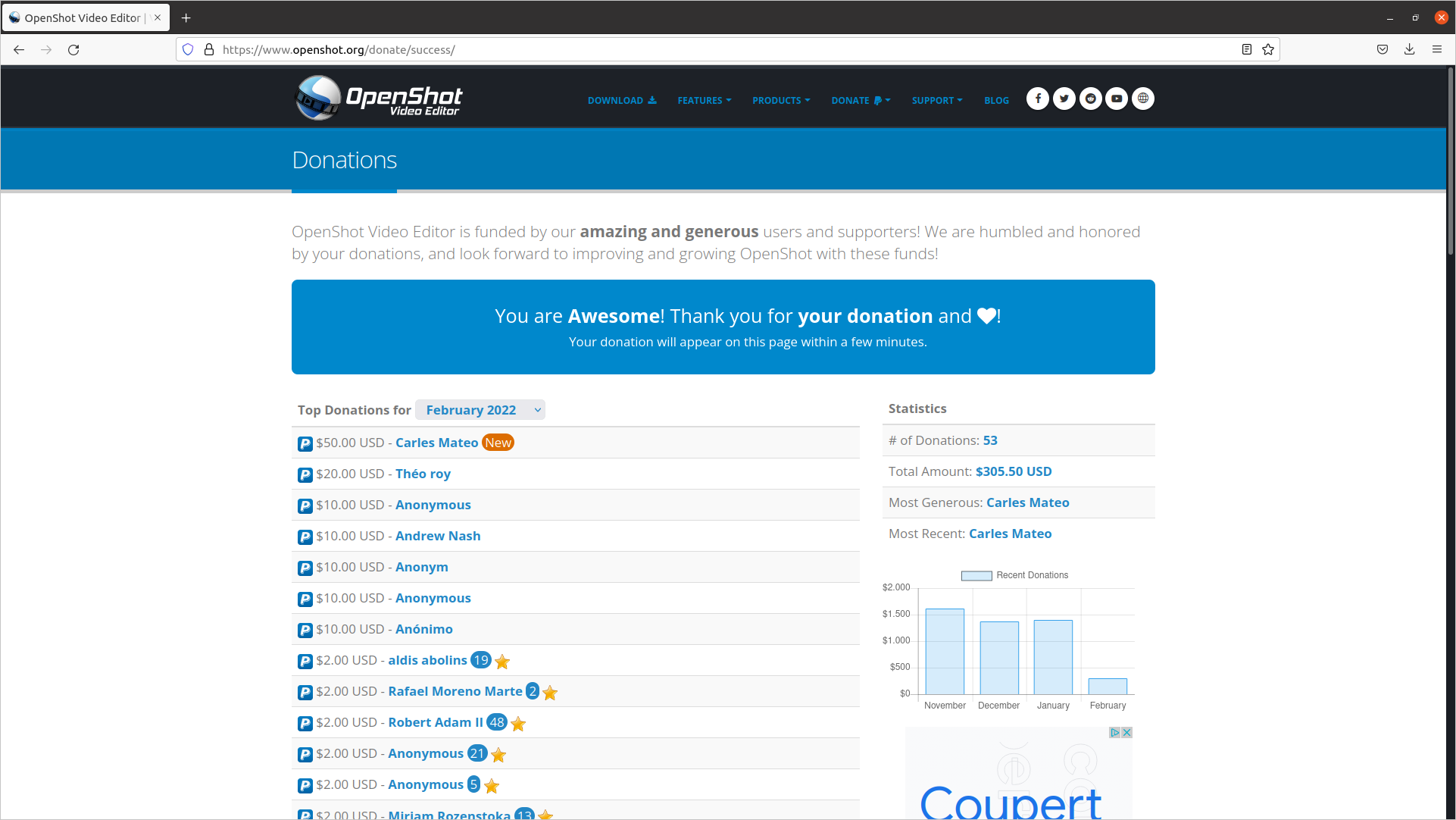
Since last News from the Blog I’ve released carleslibs v.1.06, v.1.0.5 and v.1.0.4.
v.1.0.6 adds a new class OsUtils to deal with mostly-Linux Os tasks, like knowing the userid, the username, if it’s root, the distribution name and kernel version.
It also adds:
DatetimeUtils.sleep(i_seconds)
In v.1.0.5 I’ve included a new method for getting the Datetime in Unix Epoc format as Integer and increased Code Coverage to 95% for ScreenUtils class.
v. 1.0.4 contains a minor update, a method in StringUtils to escape html from a string.
It uses the library html (part of Python core) so it was small work to do for me to create this method, and the Unit Test for it, but I wanted to use carleslibs in more projects and adding it as core functionality, makes the code of these projects I’m working on, much more clear.
Minor refactors and adding more Code Coverage (Unit Testing), and protection in the code for division per zero when seconds passed as int are 0. (this was not an actual error, but is worth protecting the code just in case for the future)
Currently in Master there is a stable version of 0.8.9 mainly fixing https://gitlab.com/carles.mateo/ctop/-/issues/51 which was not detecting when CTOP was running inside a Docker Container (reporting Unable to decode DMI).
My Books
Docker Combat Guide
Added 20 new pages with some tricks, like clearing the logs (1.6GB in my workstation), using some cool tools, using bind mounts and using Docker in Windows from command line without activating Docker Desktop or WSL.
One of my SATA 2TB 2.5″ 5,400 rpm drive got damaged and so was generating errors, so that was a fantastic opportunity to show how to detect and deal with the situation to replace it with a new SATA 2TB 3.5″ 7,200 rpm and fix the pool.
The company sent me the Stein, which is sent to the employees that serve for two years, with a recognition and a celebration called “The Circle of Honor”.
Books purchased
I bought this book as often I discover new ways, better, to explain the things to my students.
Sometimes I buy books for beginners, as I can get explained what I want to do super fast and some times they teach nice tricks that I didn’t know. I have huge Django books, and it took a lot to finish them.
A simpler book may only talk about how to install and work with it under a platform (Windows or Mac, as instance) but it is all that I require as the command to create projects are the same cross platform.
For example, you can get to install and to create a simple project with ORM, connected to the database, very quickly.
Software
So I just discovered that Zoom has an option to draw in the shared screen, like Slack has. It is called Annotate. It is super useful for my classes. :)
Also discovered the icons in the Chat. It seems that not all the video calls accept it.
Hardware
As Working From Home I needed an scanner, I looked in Amazon and all of them were costing more than €200.
I changed my strategy and I bought a All-In-One from HP, which costed me €68.
So I’ll have a scanner and a backup printer, which always comes handy.
The nightmare started after I tried to connect it with Ubuntu.
Ubuntu was not recognizing it. Checking the manuals they force to configure the printer from an Android/iPhone app or from their web page, my understanding is for windows only. In any case I would not install the proprietary drivers in my Linux system.
Annoyed, I installed the Android application, and it was requesting to get Location permissions to configure it. No way. There was not possible to configure the printer without giving GPS/Location permissions to the app, so I cancelled the process.
I grabbed a Windows 10 laptop and plugged the All-in-one through the USB. I ran the wizard to search for Scanners and Printers and was not unable to use my scanner, only to configure as a printer, so I was forced to install HP drivers.
Irritated I did, and they were suggesting to configure the printer so I can print from Internet or from the phone. Thanks HP, you’ll be the next SolarWinds big-security-hole. I said no way, and in order to use the Wifi I have to agree to open that security door which is that the printer would be connected to Internet permanently, sending and receiving information. I said no, I’ll use only via USB.
Even selecting that, in order to scan, the Software forces me to create an account.
Disappointing. HP is doing very big stupid mistakes. They used to be a good company.
Since they stopped doing the drivers in Barcelona years ago, their Software and solutions (not the hardware) went to hell.
I checked the reviews in the App Store and so many people gave them 1 star and have problems… what a shame the way they created this solution.
This is a great Open Source, multi-platform editor, so I wanted to support the creator.
Security
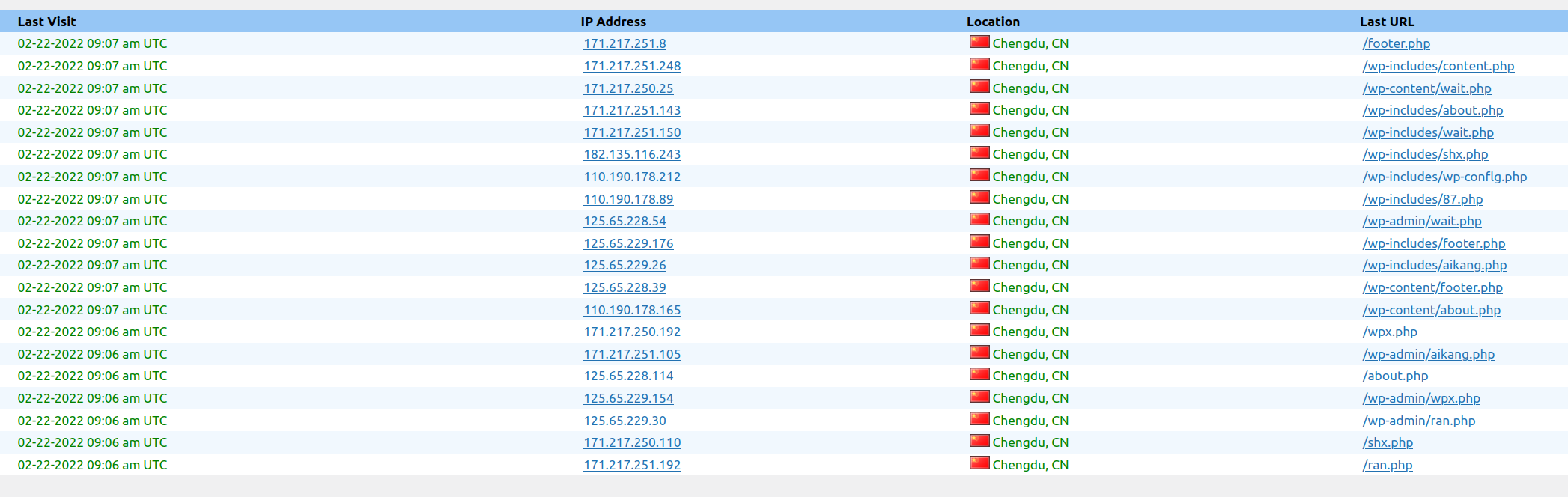
Attacks: looking for exploits
This is just a sample of a set of attacks to the blog in a 3 minutes interval.
Another one this morning:
Now all are blocked in the Firewall.
This is a non stop practice from spammers and pirates that has been going on for years.
It was almost three decades ago, when I was the Linux responsible of an ISP, and I was installing a brand new Linux system connected to a service called “infovia”, at the time when Internet was used with dial-up and modems, and in the interval of time of the installation, it got hacked. I had the Ethernet connected. So then already, this was happening.
The morning I was writing this, I blocked thousands of offending Ip Addresses.
Protection solutions
I recommend you to use CloudFlare, is a CDN/Cache/Accelerator with DoS protection and even in its Free version is really useful.
Fun/Games
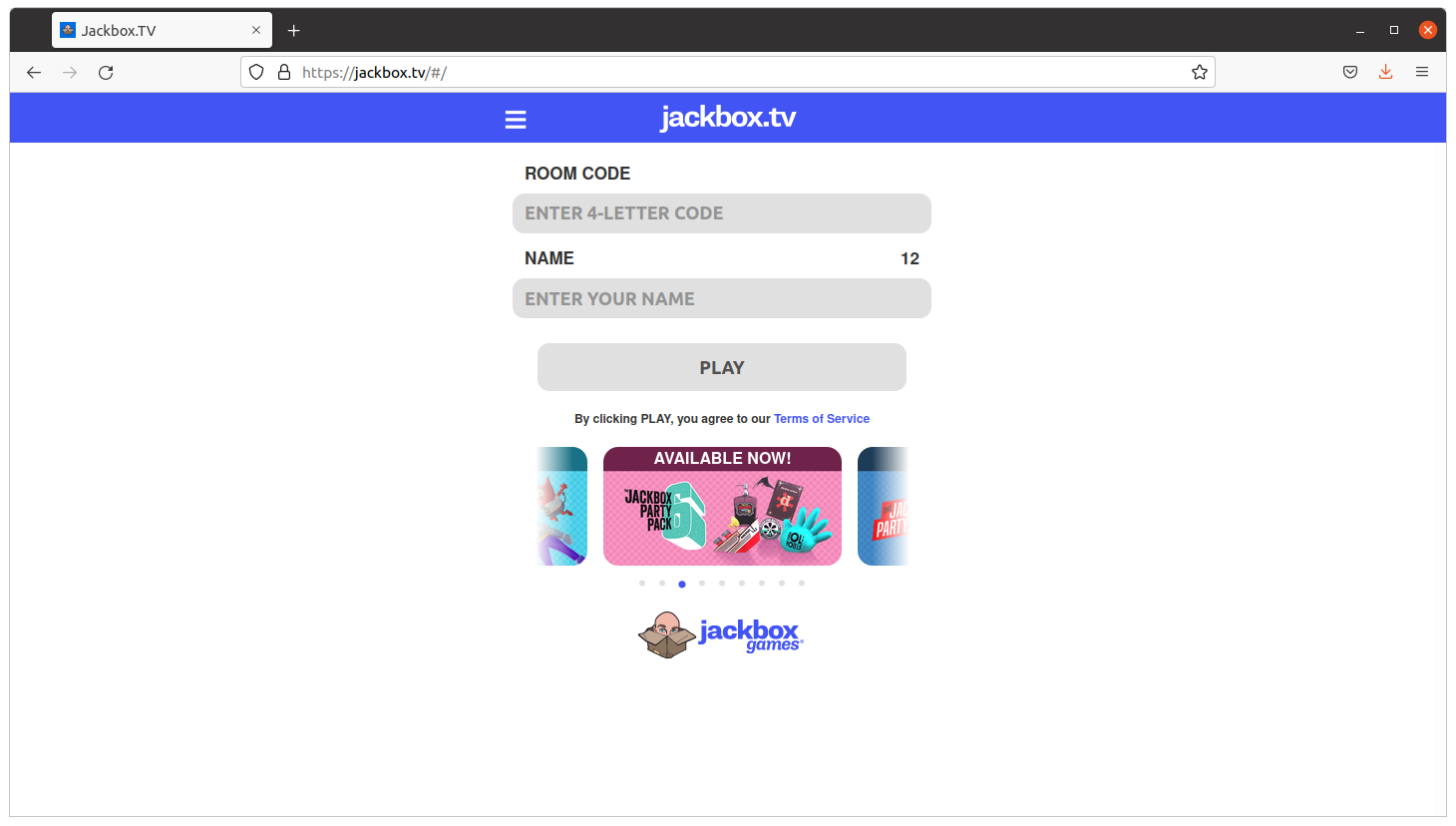
So I come with a game kind of Quiz that you can play with your friends, family or work colleagues working from home (WFH).
The idea is that the master shares screen and sound in Zoom, and then the rest connect to jackbox.tv and enter the code displayed on the master’s screen on their own browser, and an interactive game is started.
It is recommended that the master has two monitors so they can also play.
The games are so fun as a phrase appearing and people having to complete with a lie. If your friends vote your phrase, believing is true, you get points. If you vote the true answer, you get points too.
Very funny and recommendable.
Stuff
<humor>Skynet sent another terminator to end me, but I terminated it. Its processor lays exhibited in my home now</humor>
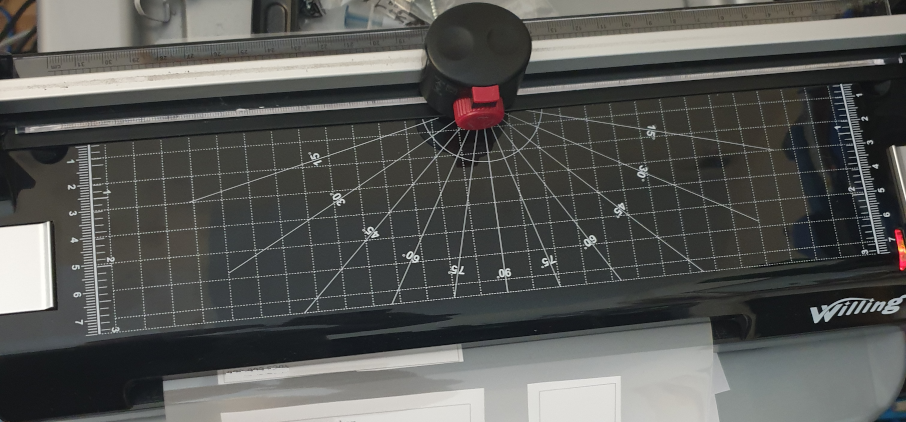
I bought a laminator.
It has also a ruler and a trimmer to cut the paper.
It was only €39 and I’ve to say that I’m very happy with the results.
It takes around 5 minutes to be ready, it takes to get to the hot-enough temperature, and feeds the pages slowly, around 50 secs a DIN-A4, but the results are worth the time.
I’ve protected my medical receipts and other value documents and the work was perfect. No bubbles at all. No big deal if the plastic covers are introduced not 100% straight. Even if you pass again an already plasticized document, all is good.
Fun
Databases
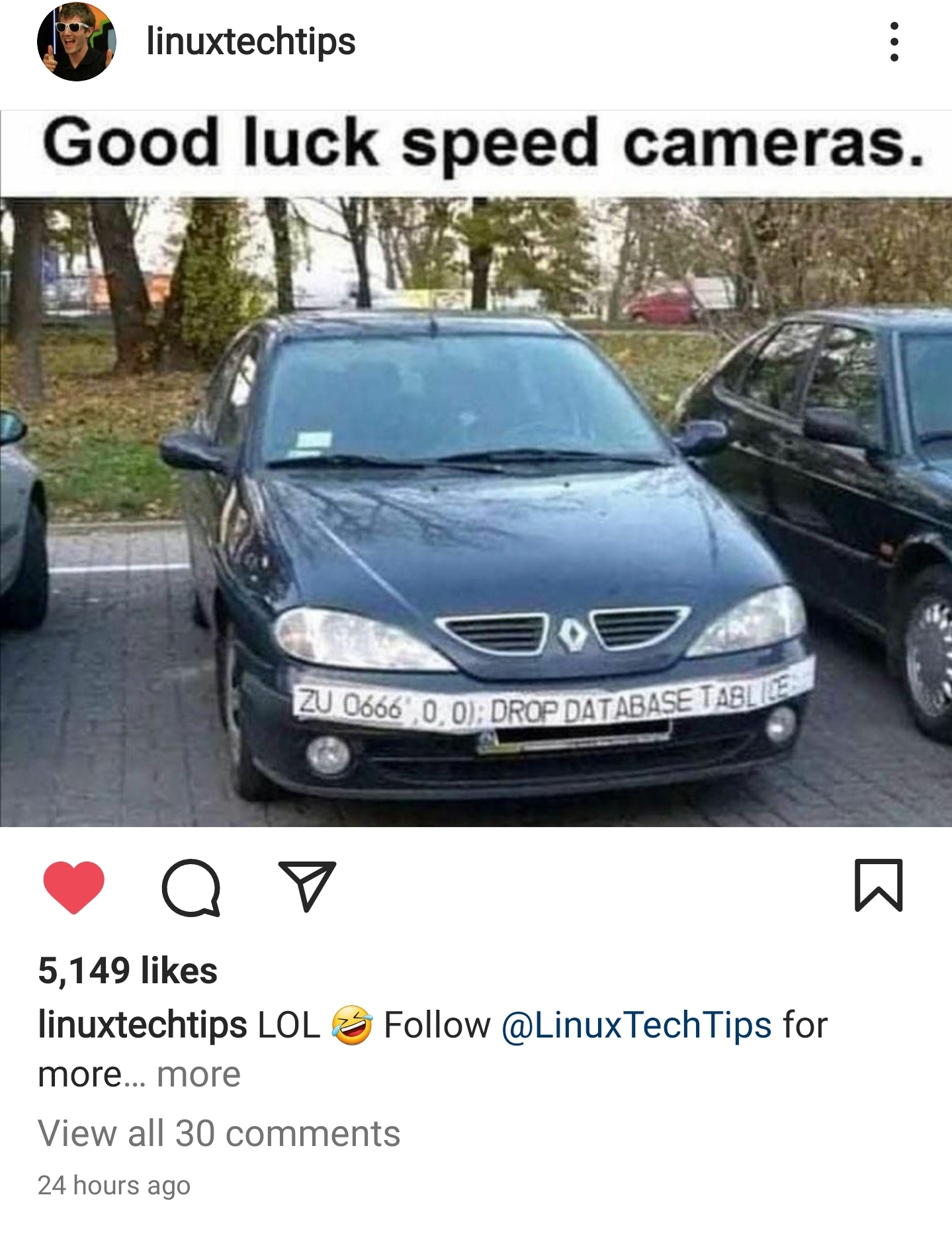
One of my friends sent me this image.
It is old, but still it’s fun. So it assumes the cameras of the parking or speed cameras, will OCR the plate to build a query, and that the code is not well protected. So basically is exploiting a Sql Injection.
Anybody working on the systems side, and with databases, knows how annoying are those potential situations.
I completed my ZFS on Ubuntu 20.04 LTS book. I had an error in an actual hard drive so I added a Troubleshooting section explaining how I fixed it.
I paused for a while the advance of my book Python: basic exercises for beginners, as my colleague Michela is translating it to Italian. She is a great Engineer and I cannot be more happy of having her help.
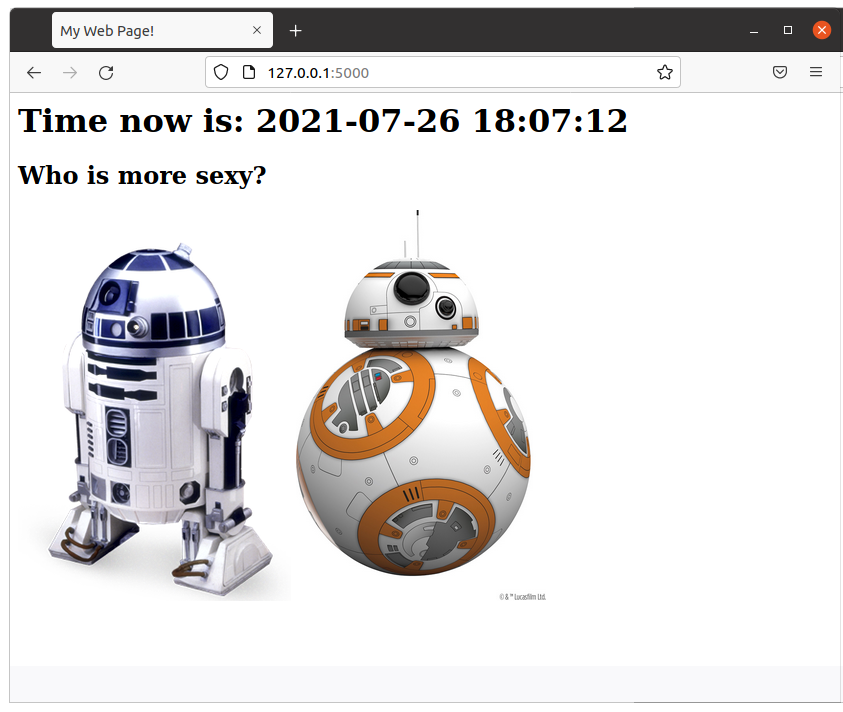
I added a new article about how to create a simple web Star Wars game using Flask. As always, I use Docker and a Dockerfile to automate the deployment, so you can test it without messing with your local system. The code is very simple and easy to understand.
This way I set an entry in /etc/hosts and I can do all the tests I want.
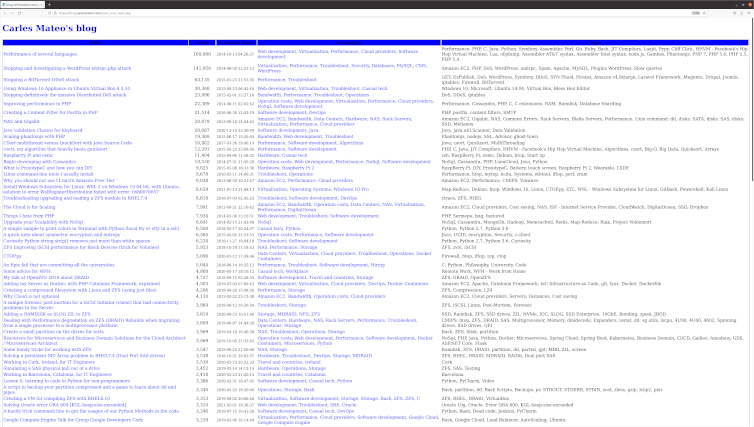
I added a new section to the blog, is a link where you can see all the articles published, ordered by number of views. /posts_and_views.php
Is in the main page, just after the recommended articles. Here you can see the source code.
I removed the Categories:
Storage
ZFS
In favor of:
Hardware
Storage
ZFS
So the articles with Categories in the group deleted were reassigned the Categories in the second group.
Visually:
I removed some annoying lines from the Quick Selection access. They came from inherited CSS properties from my WordPress, long time customized, and I created new styles for this section.
I adjusted the line-height to avoid separation between lines being too much.
I added a link in the section of Other Engineering Blogs that I like, to the great https://github.com/lesterchan site, author of many super cool WordPress plugins.
All the Operation Engineers and SREs that work with systems have found the situation of having a Server with the disk full of logs and needing to keep those logs, and at the same time needing the system to keep running.
This is an uncomfortable situation.
I remember when I was being interviewed in Facebook, in Menlo Park, for a SDM position in the SRE (Software Development Manager) back in 2013-2014. They asked me about a situation where they have the Server disk full, and they deleted a big log file from Apache, but the space didn’t come back. They told me that nobody ever was able to solve this.
I explained that what happened is that Apache still had the fd (file descriptor), and that he will try to write to end of that file, even if they removed the huge log file with rm command, from the system they will not get back any free space. I explained that the easiest solution was to stop apache. They agreed and asked me how we could do the same without restarting the Webserver and I said that manipulating the file descriptors under /proc. They told me what I was the first person to solve this.
How it works
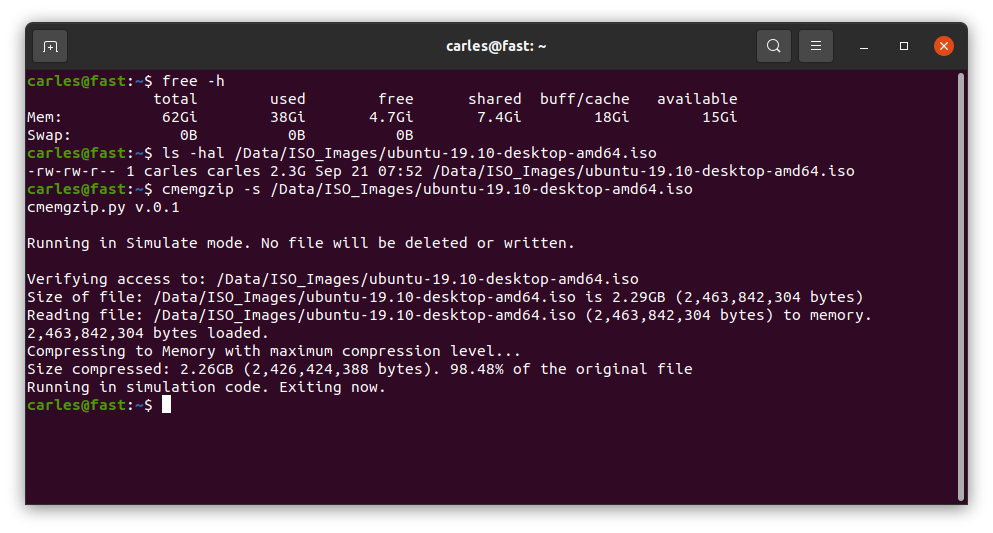
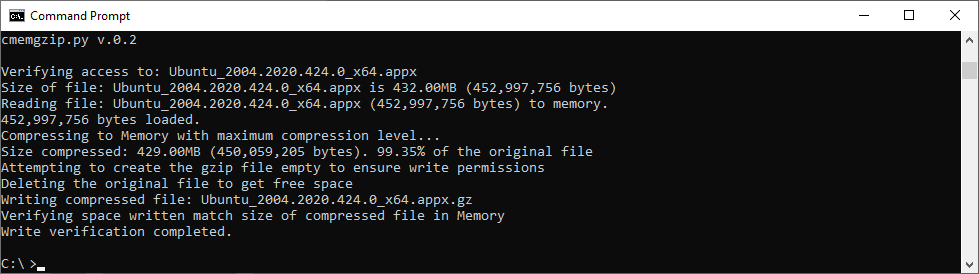
Basically cmemgzip will read a file, as binary, and will load it completely in to Memory.
Then it will compress it also in Memory. Then it will release the memory used to keep the original, will validate write permissions on the folder, will check that the compressed file is smaller than the original, and will delete the original and, using the new space now available in disk, write the compressed and smaller version of the file in gzip format.
Since version 0.3 you can specify an amount of memory that you will use for the blocks of data read from the file, so you can limit greatly the memory usage and compress files much more bigger than the amount of memory.
If for whatever reason the gz version cannot be written to disk, you’ll be asked for another route.
I mentioned before about File Descriptors, and programs that may keep those files open.
So my advice here, is that if you have to compress Apache logs or logs from a multi-thread program, and disk is full, and several instances may be trying to write to the log file: to stop Apache service if you can, and then run cmemgzip. I want to add it the future to auto-release open fd, but this is delicate and requires a lot of time to make sure it will be reliable in all the circumstances and will obey the exact desires of the SRE realizing the operation, without unexpected undesired side effects. It can be implemented with a new parameter, so the SysAdmin will know what is requesting.
Get the source code
You can decompress it later with gzip/gunzip.
So about cmemgzip you can git clone the project from here:
The program is written in Python 3, and I gave it License MIT, so you can use it and the Open Source really with Freedom.
Do you want to test in other platforms?
This is a version 0.3.
I have only tested it in:
Ubuntu 20.04 LTS Linux for x64
Ubuntu 20.04 LTS 64 bits under Raspberry Pi 4 (ARM Processors)
Windows 10 Professional x64
Mac OS X
CentOS
It should work in all the platforms supporting Python, but if you want to contribute testing for other platforms, like Windows 32 bit, Solaris or BSD, let me know.
Alternative solutions
You can create a ramdisk and compress it to there. Then delete the original and move the compressed file from ramdisk to the hard drive, and unload the ramdrive Kernel Module. However we find very often with this problems in Docker containers or in instances that don’t have the Kernel module installed. Is much more easier to run cmemgzip.
Another strategy you can do for the future is to have a folder based on ZFS and compression. Again, ZFS should be installed on the system, and this doesn’t happen with Docker containers.
cmemgzip is designed to work when there is no free space, if there is free space, you should use gzip command.
In a real emergency when you don’t have enough RAM, neither disk space, neither the possibility to send the log files to another server to be compressed there, you could stop using the swap, and fdisk the swap partition to be a ext4 Linux format, format it, mount is, and use the space to compress the files. And after moving the files compressed to the original folder, fdisk the old swap partition to change type to Swap again, and enable swap again (swapon).
Memory requirements
As you can imagine, the weak point of cmemgzip, is that, if the file is completely loaded into memory and then compressed, the requirements of free memory on the Server/Instance/VM are at least the sum of the size of the file plus the sum of the size of the file compressed. You guess right. That’s true.
If there is not enough memory for loading the file in memory, the program is interrupted gracefully.
I decided to keep it simple, but this can be an option for the future.
So if your VM has 2GB of Available Memory, you will be able to use cmemgzip in uncompressed log files around 1.7GB.
In version 0.3 I implemented the ability to load chunks of the original file, and compress into memory, so I would be able use less memory. But then the compression is less efficient and initial tests point that I’ll have to keep a separate file for each compressed chunk. So I will need to created a uncompress tool as well, when now is completely compatible with gzip/gunzip, zcat, the file extractor from Ubuntu, etc…
For a big Server with a logfile of 40TB, around 300GB of RAM should be sufficient (the Servers I use have 768 GB of RAM normally).
Honestly, nowadays we find ourselves more frequently with VMs or Instances in the Cloud with small drives (10 to 15GB) and enough Available RAM, rather than Servers with huge mount points. This kind of instances, which means scaling horizontally, makes more difficult to have NFS Servers were we can move those logs, for security.
So cmemgzip covers very well some specific cases, while is not useful for all the scenarios.
I think it’s safe to say it covers 95% of the scenarios I’ve found in the past 7 years.
cmemgzip will not help you if you run out inodes.
Usage
Usage is very simple, and I kept it very verbose as the nature of the work is Operations, Engineers need to know what is going on.
I return error level/exit code 0 if everything goes well or 1 on errors.
./cmemgzip.py /home/carles/test_extract/SherlockHolmes.txt
cmemgzip.py v.0.1
Verifying access to: /home/carles/test_extract/SherlockHolmes.txt
Size of file: /home/carles/test_extract/SherlockHolmes.txt is 553KB (567,291 bytes)
Reading file: /home/carles/test_extract/SherlockHolmes.txt (567,291 bytes) to memory.
567,291 bytes loaded.
Compressing to Memory with maximum compression level…
Size compressed: 204KB (209,733 bytes). 36.97% of the original file
Attempting to create the gzip file empty to ensure write permissions
Deleting the original file to get free space
Writing compressed file /home/carles/test_extract/SherlockHolmes.txt.gz
Verifying space written match size of compressed file in Memory
Write verification completed.
You can also simulate, without actually delete or write to disk, just in order to know what will be the
Installation
There are no third party libraries to install. I only use the standard ones: os, sys, gzip
So clone it with git in your preferred folder and just create a symbolic link with your favorite name:
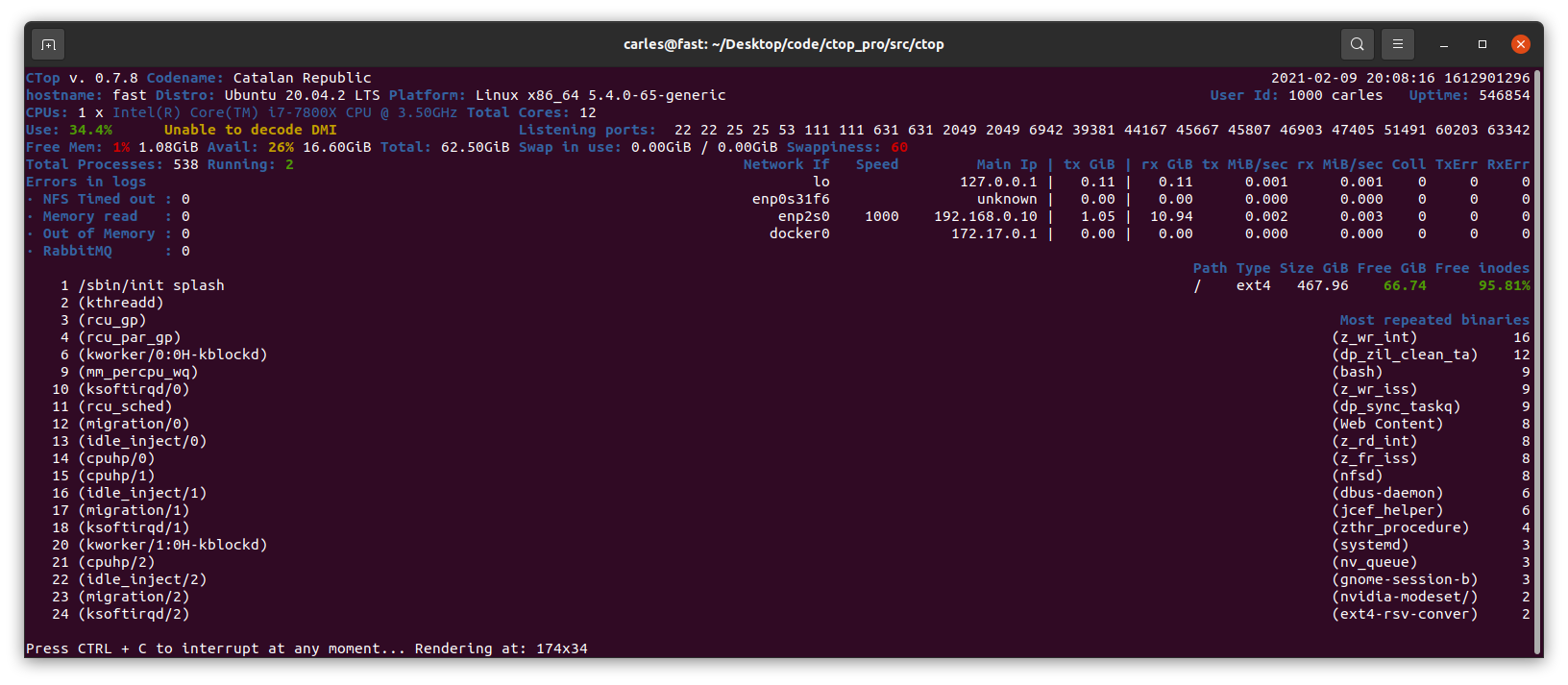
I have updated CTOP.py so now it detects if is running in a Google GCP instance.
So the list of instances/type of virtualization detected is:
Amazon AWS
Google GCP
OpenStack
VirtualBox
Docker containers
LXC
I’m working in detecting Raspberry Pi, models running CTOP, and in enabling the plugins system so anybody can easily expand the functionality of ctop.py.
v.0.7.8 Commented annotations and type hinting, to make CTOP compatible with Python 3.5.0. Added Available RAM. Added Google GCP detection. Inform if it doesn't have permissions to decode DMI. Print the userId (numeric) and the User (string), like: 1000 carles or 0 root. Logic for swappiness <= 10 Ok, >10 and <= 30 warning, >30 red (alert). Reduced digits for swap to 2, to avoid confusions.
I have updated my book Python 3 Combat Guide, with another full cycle, step by step, to convert an ugly script that escapes to shell to a nice OOP code with Unit Testing, step by step.
I have updated my book ZFS for Ubuntu 20.04 LTS, adding how to create a pool and Datasets for home, sharing NFS for the Media Player.
If you like Star Wars and the Mandalorian, you may laugh has much as I did with this video:
As you see I’m writing more articles about Windows, Mac Os X, and proprietary Software. Some of my colleagues work in companies and use proprietary Software, so I’ll be writing more articles about those ecosystems. I spend more time now with colleagues working on all kind of projects, and with students that have other problems too, so I help them. However my main focus is Open Source, Architecture, Scaling, programming in Python and Java.
I reproduced your case in a VM and paste here step by step. :)
Note: First of all, please do a backup of your data. I added an empty new disk, so ZFS had no doubt what was the master drive. Although you should have no problem as the first drive already forms part of the pool, a backup is recommended.
Quick answer: You need the zpool attach command.
Basically:
sudo zpool attach hdd0 existinghdd blankhdd
After, do:
zpool status
And you will see that a mirror has been created. Your data on the already existing drive will be keep, and will be replicated to the new one (Resilvered).
As ZFS only copys the actual information this process will take more or less depending on the amount of Data.
In my VM 300 GB were replicated in 3 seconds, while my experience with SAS and SATA drives, I was Resilvering 10 TB in less than 24 hours (for that I was using drives from 10TB to 14TB SAS) .
Now the long answer with everything I did in my Virtual Box VM:
lsblk --scsi
identify the two empty drives by:
ls /dev/disk/by-id/
Select one of them and create a pool like your: sudo zpool create hdd0 id_of_mydrive
See that pool /hdd0 has been created and mounted on root.
sudo zpool statussudo zpool listsudo ls -al /hdd0
Fill with some random data (or better copy files there) to generate a drive like data like you. I generated from random:
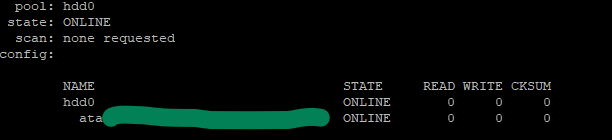
pool: hdd0
state: ONLINE
scan: resilvered 301M in 0 days 00:00:03 with 0 errors…
NAME STATE READ WRITE CKSUM hdd0 mirror-0 ata-VBOX_HARDDISK_VBa8... ONLINE 0 0 0 ata-VBOX_HARDDISK_VB8c... ONLINE 0 0 0
errors: No known data errors
I verified the checksums.
zpool list will return as well 99GB of space available, as two drives of 100GB are being used in mirror.
So as kaulex mentioned the format is: zpool attach
Where device is your previous vdev with data (the single hard drive with Data in the ZFS pool named ‘hdd0’).
As I did you want to use the Id of the device and not the name, so you will use the identifier in /dev/disk/by-id/ and not sdb, sdc… (Please note, adding /dev/ is not necessary). The reason to do not use device names like sdb, sdc, sdea, etc… is that those names may change why live is running or between reboots. The id never changes. In real systems, not Virtual Box, they may start by wwn or ata.
I’ve published a class to validate input from Keyboard in Java. Is something very simple, thinking basically about university students struggling to Scanner and nextInt() methods, and that can save many hours.
I decided to lower the price of my book to the minimum in LeanPub $5 USD while covid is going on in order to help people with their lives. https://leanpub.com/u/carlesmateo
I read with surprise that Comcast is capping the Internet use to 1.2TB per month, and that they will be charging excess.
So… if I contract a Backup with Carbonite or BackBlaze or DropBox or another company and I backup my 10TB files, Comcast will ruin me charging excesses… Or if I work from home, or the family watches a lot of Netflix… I can only thinK on their Cast Strategy of CastNumberOfClientsToBankrupcy.
A joke to indicate that I think they will loss clients.
Imagine yesterday I downloaded two images of Ubuntu, being 5 GB, installed Call of Duty in one computer 180 GB, installed few Xbox games 400 GB, listened to Spotify 10 Gb, watched youtube 3 GB, watched Netflix 4 GB, so 602 GB in one day.
Not counting the bandwidth WFH (Working from Home).
Not counting Windows Updates, TV updates, consoles updates, Android Updates, Ubuntu updates…
And this is done in the middle of the covid-19 pandemic, with so many people lock down at home, playing video games, watching movies, and requiring desperately distractions.
However the 12 Gbps SAS SSD were returning Checksum errors in ZFS when I did copy information or I ran scrub. I’m afraid the enclosure can only provide 6 Gbps at max, or a poor connection. Cables or expanders use to be the reason. I ordered new cables to make a direct connection to the HBA Controller without the enclosure to validate my theory and the drives stopped showing errors.
There is something good in all bad: I have been able to document and explain how to troubleshoot, actual errors in ZFS, in my book and talk about the problems with the cables, and the advantages of using a SAS controller even if you use SATA drives.
I got my first Excellent in an Assignment in an Ireland university, which makes me specially happy. And I keep going on studying in Linux Academy, the last course I did was GCP and Terraform, even if I knew both it helps me to keep my skills sharp.
I share with you some offers and charity bundles that I enrolled and enjoyed a lot:
There is an offer with Microsoft Pass which is that we can use Disney+ for free during 30 days.
I started watching the Mandalorian, Season 2, and is wonderfully displayed in 4K. The quality of the video surprised me. Not that many contents in Netflix are 4K and I really enjoyed the great quality of the image.
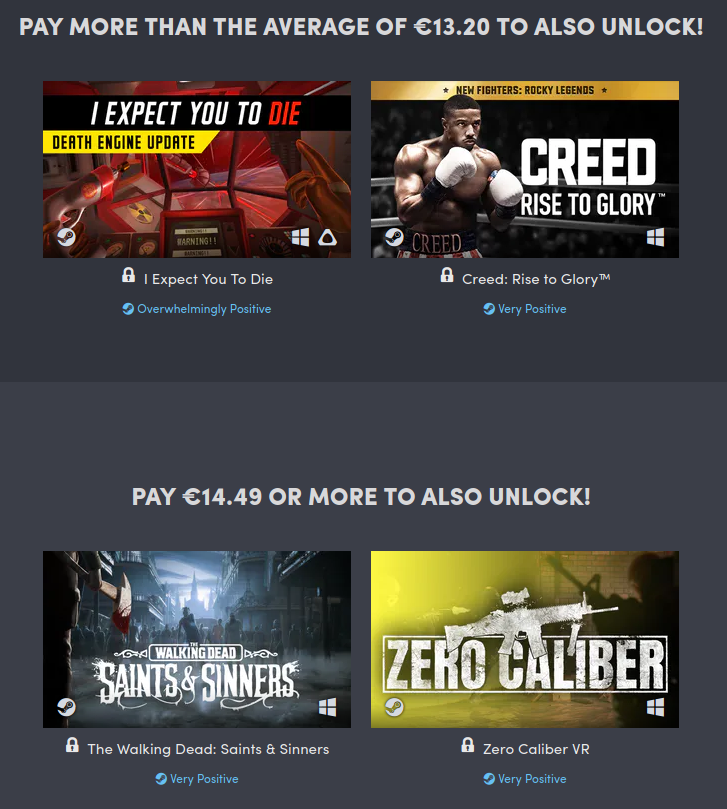
Humble Bundle offers a pack of 8 VR games per €13.45. If you like Virtual Reality and have your headset, this pack is amazing, and the benefits go to charity: Movember. The games are downloaded from Steam and the pack will last for 14 days.
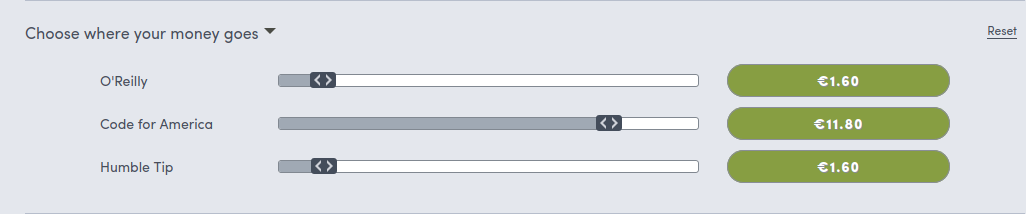
Don’t forget to balance how much of your contribution goes to every player.
Unfortunately by default most of the money goes to O’Reilly and Humble Tip and few to the Charity cause. You can change that from the web when going to to the payment.
This article talks about how at Riot Games they use Slack. Slack is really a powerful tool, and also makes the communication more human in companies with their approach and the funny icons and /giphy. I’m very serious when it comes to work but I recognize the friendly, warm, human and lovely touch these kind of animated icons bring to the conversations.
Remember that life of the SSD is different from spinning drives. I recommend to keep your backups on external spinning drives disconnected most of the time.
I updated it the Nov-01, as I normally do, bringing more content.
I’ve been paid the royalties for he past two months and I reinvested everything (and more from my pocket) in Hardware for working with ZFS.
I was offered by an editorial in The States to publish Python Combat Guide and other of my books worldwide. I was thinking it for a while. It was very good money, translation to multiple languages and platforms and marketing and a lot of promotion, but I would had loss the rights and the Freedom I have now, like the possibility to offer discount coupons to who I want and to update the contents often. So to celebrate my decision for you, readers of the blog, during September, I provide a discounted price of $5 USD for the fist 100 sales instead of the $25 USD suggested price. Use the following link:
As part of my effort to contributing with nice Open Source products to the Community I have made some investments to keep contributing to:
OpenZFS
My old tool for managing ZFS and Network shares easily
I’m writing a new book about managing ZFS for Small Business too, so I show how to operate on this hardware, good points and downsides.
I’m assembling a new Pc with ZFS plenty of Disk Storage within a mix of:
SAS Enterprise grade SSD 2.5″
SATA 12Gb Enterprise grade SSD 2.5″
SATA SSD 2.5″
SATA HDD 2TB 2.5″
SATA HDD 2TB 3.5″
I’m a big fan of Intel, but this time I have chosen AMD. Concretely a AMD Ryzen 7 3700X AM4 8 Core / 16 Threads, 3.6 GHz to 4.4 GHz with Turbo. The reason I chose this CPU is because it only uses 65W but still has 8 Cores / 16 Threads.
Also I want to see the performance of this AMD Ryzen with CMIPS and another important reason is that AMD motherboards support PCI 4.0. I have bought a NVMe SSD Samsung 980 PRO PCI 4.0 (x4) able to read at 6,400 MB/s. I will use this AMD box for running VMs as well. Basically Virtual Box and Docker.
I’ve been surprised that for 169.99 GBP I can have a very good Asus Motherboard with a 2.5 Gb Ethernet: ASUS ROG STRIX B550-F GAMING, AMD B550, AM4, DDR4, PCIe 4.0, SATA3, Dual M.2, CrossFire, 2.5GbE, USB 3.2 Gen2 A+C, ATX.
In order to have an Asus motherboard with a 2.5 Gb Ethernet for Intel I had to jump to a 254 GBP motherboard and Intel is still PCI 3.0. Actually there are PCI 10Gb NICs at 80 GBP so at some point I’ll upgrade my home network from Gigabit to 10 Gb. That will come slowly, but if the new equipment I assemble has 2.5 Gb when I upgrade the main switches to 10 Gb, at least I’ll be able to communicate at 2.5 Gb without ant additional change.
Also memory at 3200, speed that the AMD motherboard can provide, is more than affordable.
This new server will have 64 GB of RAM (Corsair DDR4 Vengeance PC4-25600 (3200)), as I plan to run VMs and use Volumes mounted via iSCSI and locally as block devices to improve my Software. I’ve bought a new UPS to keep it running in case power goes down. That’s something that doesn’t happen often in my city in Ireland, honestly, but I never forget that this happens in Barcelona two or three times per year, and that a high tension spike can burn your motherboard, drives, or electronics like the TV or the fridge. I’ve bought as well a new KVM Switch, a HDMI 4K and USB too one, so I don’t have to have so many keyboards. My logitech M720 allowed me to use it with 3 computers, but still I want something more operational. The KVM I bought allow me to switch with a button or within a hotkey in the keyboard.
I bought a new Icy box fox handling 6 2.5 drives in just one bay of the tower, and a 850 Watt Corsair PSU that will be able to power the many drives I want at the same time.
ZFS on Ubuntu 20.04.1 LTS A guide for Small/Medium Business and power users to work with ZFS. https://leanpub.com/zfs-ubuntu
Those can be purchased while I’m still working on them and get the updates that I’ll be publishing and keeping a communication with me about doubts or improvements.
Halloween Software Offers
I saw some Halloween offers and I purchased Software licenses for Software I use.
I contribute a lot to Open Source, and many years ago before Open Source existed I was creating Freeware Software. But I think that good commercial Software deserves to be supported. Like everything in life, if they are doing a good work that is useful to me, why not giving them support?. It is also a way to make sure they will continue producing amazing Software. And in the other hand, myself, I create Software. Some times commercial Software, and I like to be paid, so I apply the same principle.