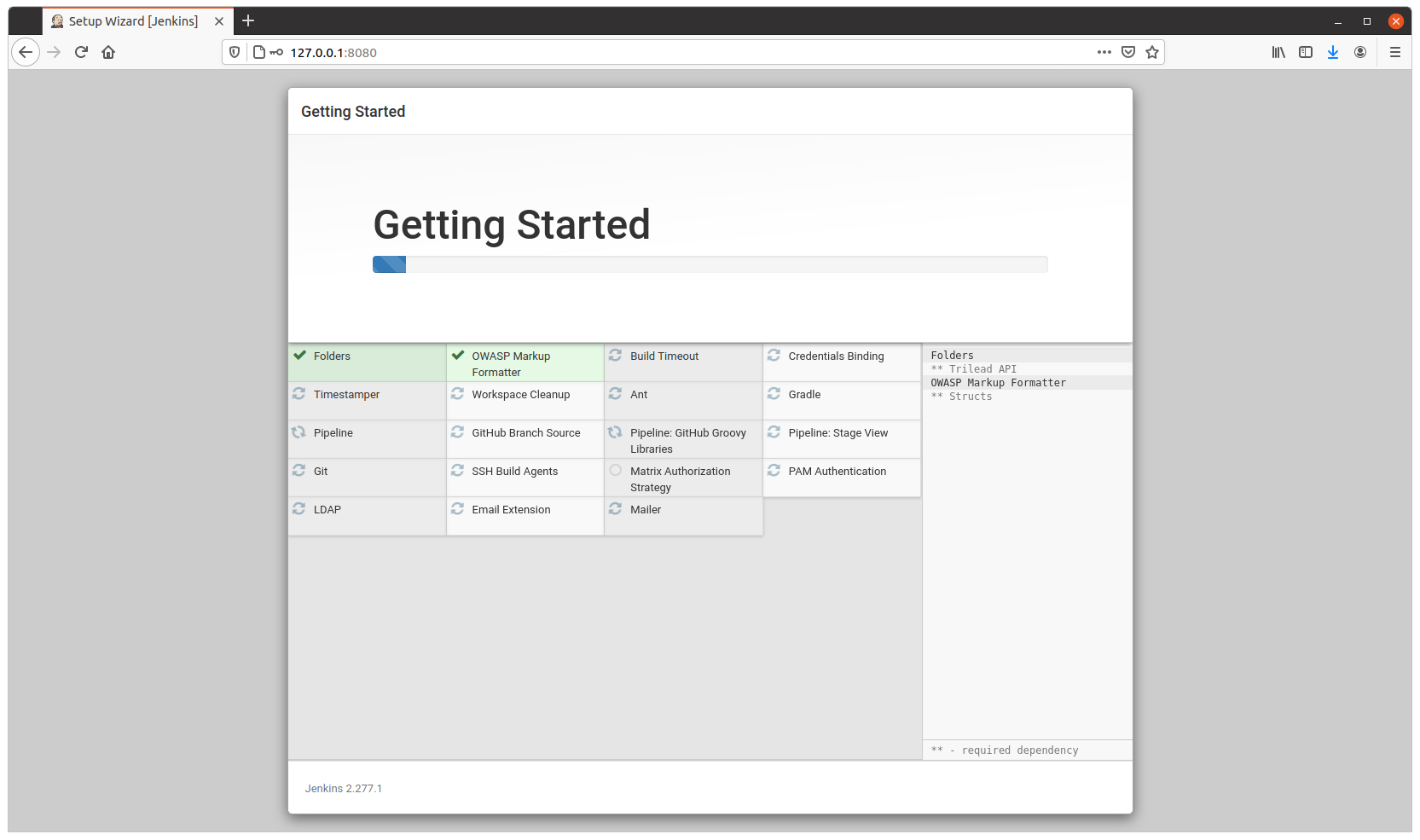
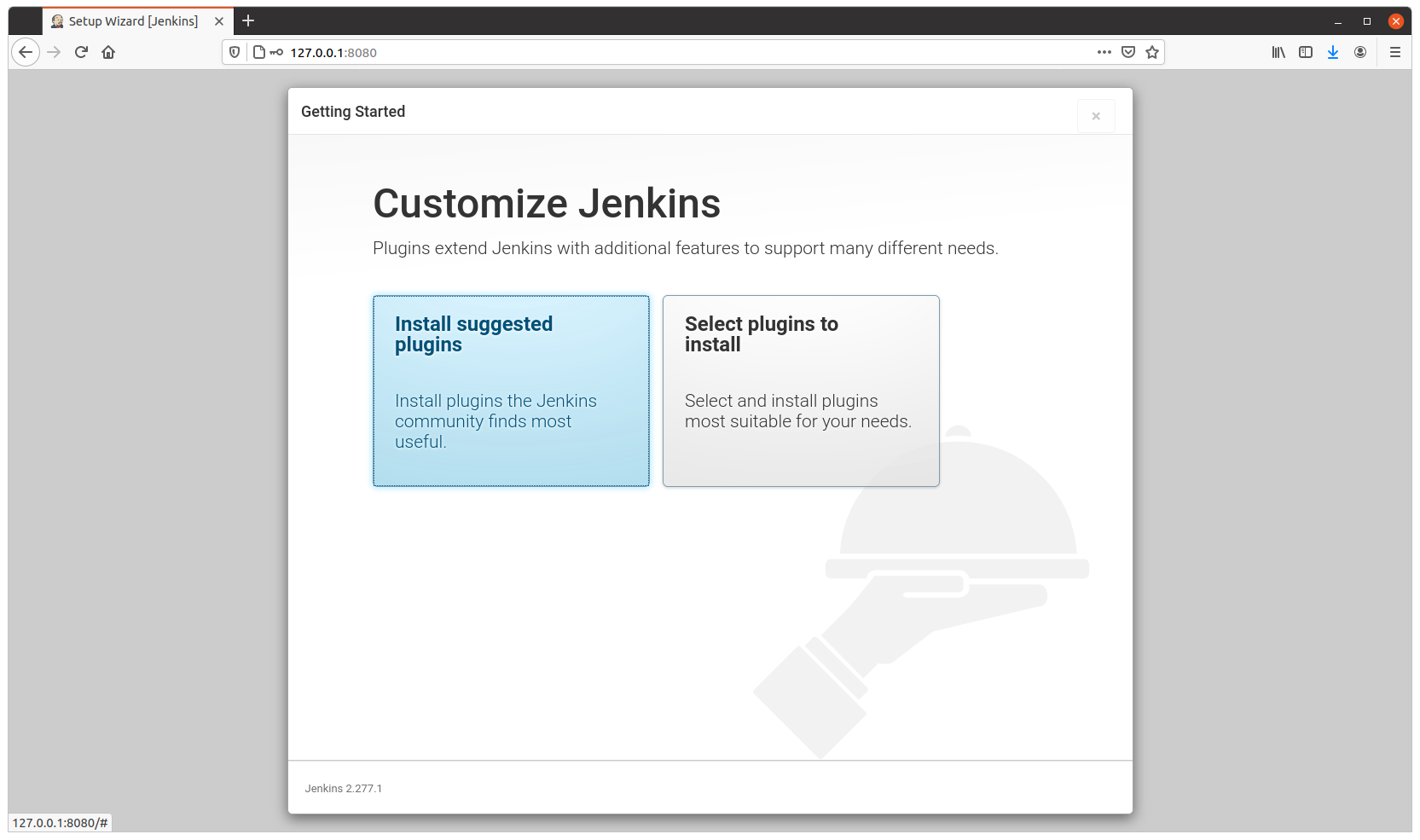
So I share with you my base Jenkins Dockerfile, so you can spawn a new Jenkins for your projects.
The Dockerfile installs Ubuntu 20.04 LTS as base image and add the required packages to run jenkins but also Development and Testing tools to use inside the Container to run Unit Testing on your code, for example. So you don’t need external Servers, for instance.
You will need 3 files:
Dockerfile
docker_run_jenkins.sh
requirements.txt
The requirements.txt file contains your PIP3 dependencies. In my case I only have pytest version 4.6.9 which is the default installed with Ubuntu 20.04, however, this way, I enforce that this and not any posterior version will be installed.
File requirements.txt:
pytest==4.6.9
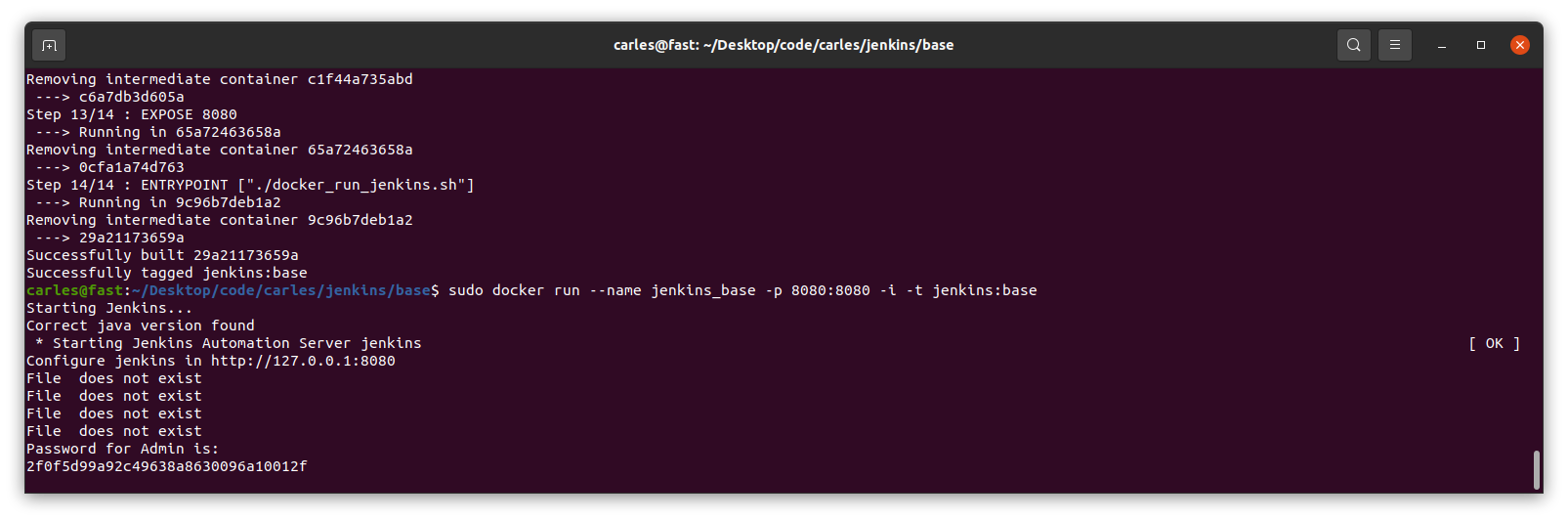
The file docker_run_jenkins.txt start Jenkins when the Container is run and it will wait until the initial Admin password is generated and then it will display it.
File docker_run_jenkins.sh:
#!/bin/bash
echo "Starting Jenkins..."
service jenkins start
echo "Configure jenkins in http://127.0.0.1:8080"
s_JENKINS_PASSWORD_FILE="/var/lib/jenkins/secrets/initialAdminPassword"
i_PASSWORD_PRINTED=0
while [ true ];
do
sleep 1
if [ $i_PASSWORD_PRINTED -eq 1 ];
then
# We are nice with multitasking
sleep 60
continue
fi
if [ ! -f "$s_JENKINS_PASSWORD_FILE" ];
then
echo "File $s_FILE_ORIGIN does not exist"
else
echo "Password for Admin is:"
cat $s_JENKINS_PASSWORD_FILE
i_PASSWORD_PRINTED=1
fi
done
That file has the objective to show you the default admin password, but you don’t need to do that, you can just start a shell into the Container and check manually by yourself.
However I added it to make it easier for you.
And finally you have the Dockerfile:
FROM ubuntu:20.04
LABEL Author="Carles Mateo" \
Email="jenkins@carlesmateo.com" \
MAINTAINER="Carles Mateo"
# Build this file with:
# sudo docker build -f Dockerfile -t jenkins:base .
# Run detached:
# sudo docker run --name jenkins_base -d -p 8080:8080 jenkins:base
# Run seeing the password:
# sudo docker run --name jenkins_base -p 8080:8080 -i -t jenkins:base
# After you CTRL + C you will continue with:
# sudo docker start
# To debug:
# sudo docker run --name jenkins_base -p 8080:8080 -i -t jenkins:base /bin/bash
ARG DEBIAN_FRONTEND=noninteractive
ENV SERVICE jenkins
RUN set -ex
RUN echo "Creating directories and copying code" \
&& mkdir -p /opt/${SERVICE}
COPY requirements.txt \
docker_run_jenkins.sh \
/opt/${SERVICE}/
# Java with Ubuntu 20.04 LST is 11, which is compatible with Jenkins.
RUN apt update \
&& apt install -y default-jdk \
&& apt install -y wget curl gnupg2 \
&& apt install -y git \
&& apt install -y python3 python3.8-venv python3-pip \
&& apt install -y python3-dev libsasl2-dev libldap2-dev libssl-dev \
&& apt install -y python3-venv \
&& apt install -y python3-pytest \
&& apt install -y sshpass \
&& wget -qO - https://pkg.jenkins.io/debian-stable/jenkins.io.key | apt-key add - \
&& echo "deb http://pkg.jenkins.io/debian-stable binary/" > /etc/apt/sources.list.d/jenkins.list \
&& apt update \
&& apt -y install jenkins \
&& apt-get clean
RUN echo "Setting work directory and listening port"
WORKDIR /opt/${SERVICE}
RUN chmod +x docker_run_jenkins.sh
RUN pip3 install --upgrade pip \
&& pip3 install -r requirements.txt
EXPOSE 8080
ENTRYPOINT ["./docker_run_jenkins.sh"]
Build the Container
docker build -f Dockerfile -t jenkins:base .
Run the Container displaying the password
sudo docker run --name jenkins_base -p 8080:8080 -i -t jenkins:base
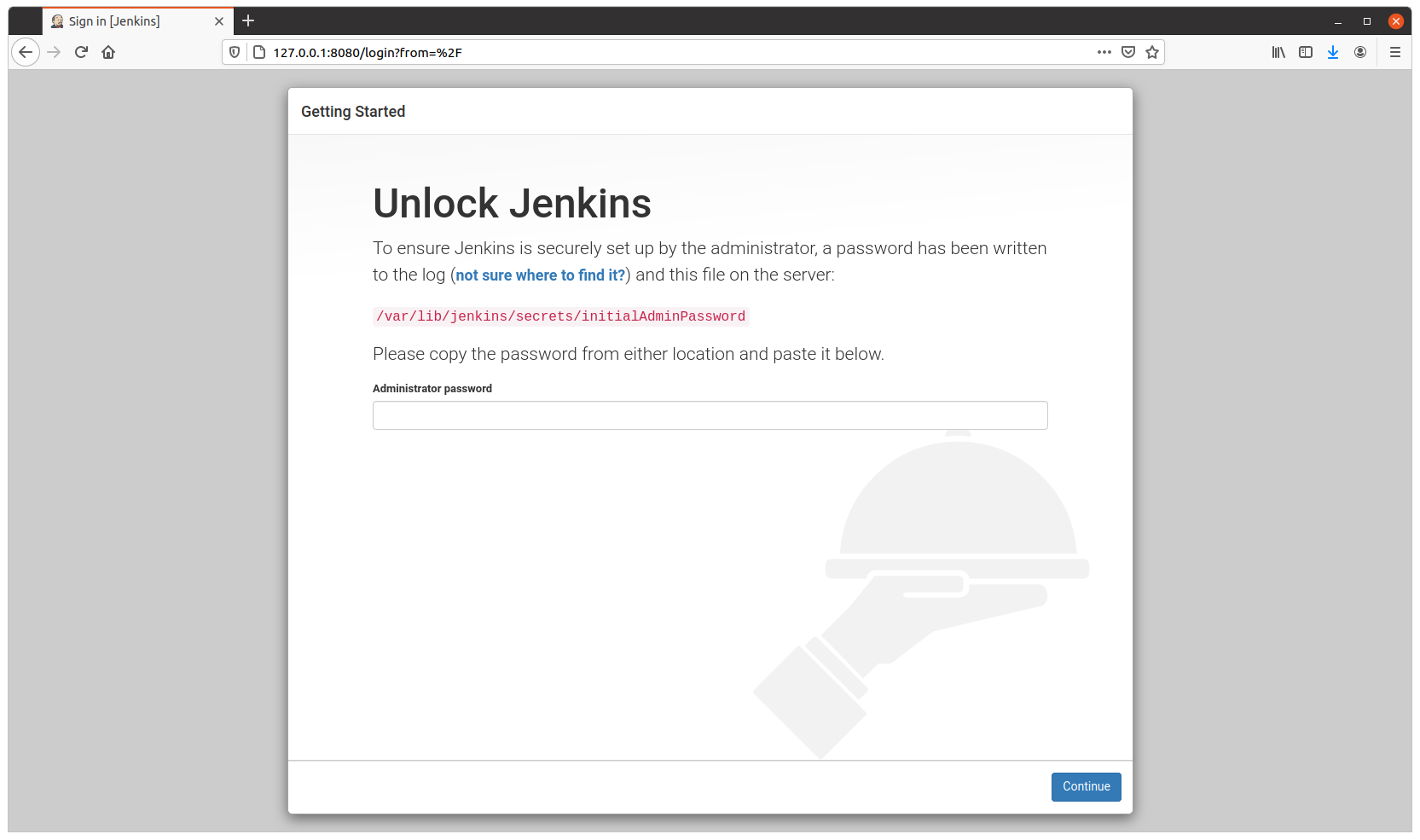
You need this password for starting the configuration process through the web.
Visit http://127.0.0.1:8080 to configure Jenkins.
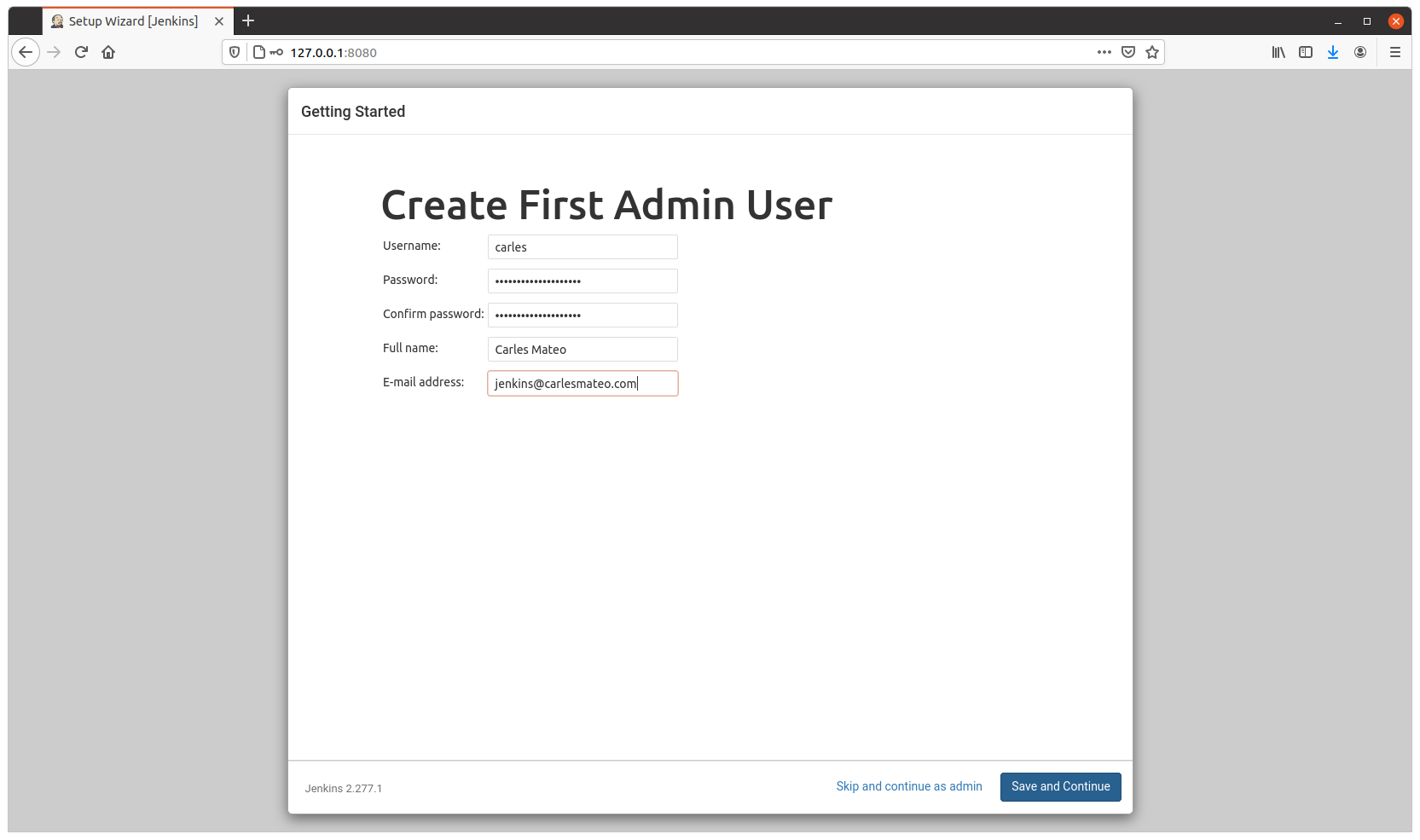
Configure as usual
Resuming after CTRL + C
After you configured it, on the terminal, press CTRL + C.
And continue, detached, by running:
sudo docker start jenkins_base
The image is 1.2GB in size, and will allow you to run Python3, Virtual Environments, Unit Testing with pytest and has Java 11 (not all versions of Java are compatible with Jenkins), use sshpass to access other Servers via SSH with Username and Password…
When you see this error for the first time it can be pretty ugly to detect why it happens.
At personal level I use only Linux for my computers, with an exception of a windows laptop that I keep for specific tasks. But my employers often provide me laptops with windows.
I suffered this error for first time when I inherited a project, in a company I joined time ago. And I suffered some time later, by the same reason, so I decided to explain it easily.
In the project I inherited the build process was broken, so I had to fix it, and when this was done I got the mentioned error when trying to run the Container:
standard_init_linux.go:190: exec user process caused "no such file or directory"
The Dockerfile was something like this:
FROM docker-io.battle.net/alpine:3.10.0
LABEL Author="Carles Mateo" \
Email="docker@carlesmateo.com" \
MAINTAINER="Carles Mateo"
ENV SERVICE cservice
RUN set -ex
RUN echo "Creating directories and copying code" \
&& mkdir -p /opt/${SERVICE}
COPY config.prod \
config.dev \
config.st \
requirements.txt \
utils.py \
cservice.py \
tests/test_cservice.py \
run_cservice.sh \
/opt/${SERVICE}/
RUN echo "Setting work directory and listening port"
WORKDIR /opt/${SERVICE}
EXPOSE 7000
RUN echo "Installing dependencies" \
&& apk add build-base openldap-dev python3-dev py-pip \
&& pip3 install --upgrade pip \
&& pip3 install -r requirements.txt \
&& pip3 install pytest
ENTRYPOINT ["./run_cservice.sh"]
So the project was executing a Bash script run_cservice.sh, via Dockerfile ENTRYPOINT.
That script would do the necessary amends depending if the Container is launched with prod, dev, or staging parameter.
I debugged until I saw that the Container never executed this in the expected way.
A echo “Debug” on top of the Bash Script would be enough to know that very basic call was never executed. The error was first.
After much troubleshooting the Container I found that the problem was that the Bash script, that was copied to the container with COPY in the Dockerfile, from a Windows Machines, contained CRLF Windows carriage return. While for Linux and Mac OS X carriage return is just a character, LF.
In that company we all use Windows. And trying to build the Container worked after removing the CRLF, but the Bash script with CRLF was causing that problem.
When I replace the CRLF by Unix type LF, and rebuild the image, and ran the container, it worked lovely.
A very easy, manual way, to do this in Windows, is opening your file with Notepad++ and setting LF as carriage return. Save the file, rebuild, and you’ll see your Container working.
Please note that in the Dockerfile provided I install pytest Framework and a file calles tests/test_cservice.py. That was not in the original Dockerfile, but I wanted to share with you that I provide Unit Testing that can be ran from a Linux Container, for all my projects. What normally I do is to have two Dockerfiles. One for the Production version to be deployed, another for running Unit Testing, and some time functional testing as well, from inside the Docker Container. So strictly speaking for the production version, I would not copy the tests/test_cservice.py and install pytest. A different question are internal Automation Tools, where it may be interested providing a All-in-One image, that can run the Unit Testing before start the service. It is interesting to provide some debugging tools in out Internal Automation Tools, so we can troubleshoot what’s going on in case of problems. Take a look at my previous article about Python version for Docker and Automation tools, for more considerations.
This article is written at 2021-03-22 so this conclusion will evolve as time passes.
Some of my articles are checked after 7 years, so be advised this choice will not be valid in a year. Although the reasoning and considerations to take in count will be the same.
I answer to the question: Why Carles, do you suggest to adopt Python 3.8, and not 3.9 or 3.7 for our Internal Automation Tools?.
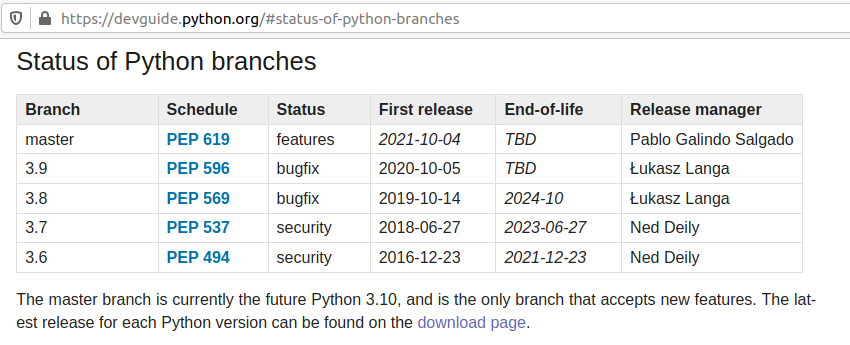
Python 3.6 was released on 2016-12-23 and will get EOL on 2021-12-23.
That’s EOL in 9 months. We don’t want to recommend that.
Python 3.7 was released on 2018-06-27 and will get EOL 2023-06-27.
That’s 2 years and 3 months from now. The Status of development is focus in Security bugfixes.
Python 3.9 was released 2020-10-05 that’s 5 months approx from now.
Honestly, I don’t recommend for Production a version of Software that has not been in the market for a year.
Most of the bugs and security bugs appears before the first year.
New features released, often are not widely fully tested , and bugs found and fixed, once a year has passed.
Python 3.8 was released on 2019-10-14.
That means that the new features have been tested for a year and five months approximately.
This is enough time to make appear most bugs.
EOL is 2024-10, that is 3 years and 7 months from now. A good balance of EOL for the effort to standardize.
Finally Python 3.8 is the Python mainline for Ubuntu 20.04 LTS.
If our deploy strategy is synchronized, we want to use Long Time Support versions, of course.
So my recommendation would be, at least for your internal tools, to use containers based in Ubuntu 20.04 LTS with Python 3.8.
We know Docker images will be bigger using Ubuntu 20.04 LTS than using other images, but that disk space is really a small difference, and we get the advantage of being able to install additional packages in the Containers if we need to debug.
An Ubuntu 20.04 Image with Pyhton 3.8 and pytest, uses 540 MB.
This is a small amount of space nowadays. Even if very basic Alpine images can use 25MB only, when you install Python they start to grow close to Ubuntu, to 360MB. The difference is not much, and if you used Alpine and you have suffered from Community packages being updated and becoming incompatible with wheel and you lost hours fixing the dependencies, you’ll really appreciate using my Ubuntu LTS packages approach.
Here is an easy trick that you can use for adding swap temporarily to a Server, VMs or Workstations, if you are in an emergency.
In this case I had a cluster composed from two instances running out of memory.
I got an alert for one of the Servers, reporting that only had 7% of free memory.
Immediately I checked it, but checked also any other forming part of the cluster.
Another one appeared, had just only a bit more memory than the other, but was considered in Critical condition too.
The owner of the Service was contacted and asked if we can hold it until US Business hours. Those Servers were going to be replaced next day in US Business hours, and when possible it would be nice not to wake up the Team. It was day in Europe, but night in US.
I checked the status of the Server with those commands:
# df -h
There are 13GB of free space in /. More than enough to be safe as this service doesn’t use much.
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 139M 298M 738M 320M
Swap: 0B 0B 0B
I checked the memory, ok, there are only 139MB free in this node, but 738MB are buff/cache. Buff/Cache is memory used by Linux to optimize I/O as long as it is not needed by application. These 738 MB in buff/cache (or most of it) will be used if needed by the System. The field available corresponds to the memory that is available for starting new applications (not counting the swap if there was any), and basically is the free memory plus a fragment of the buff/cache. I’m sure we could use more than 320MB and there is a lot if buff/cache, but to play safe we play by the book.
With that in mind it seemed that it would hold perfectly to Business hours.
I checked top. It is interesting to mention the meaning of the Column RES, which is resident memory, in other words, the real amount of memory that the process is using.
I had a Java process using 4.57GB of RAM, but a look at how much Heap Memory was reserved and actually being used showed a Heap of 4GB (Memory reserved) and 1.5GB actually being used for real, from the Heap, only.
It was unlikely that elastic search would use all those 4GB, and seemed really unlikely that the instance will suffer from memory starvation with 2.5GB of 4GB of the Heap free, ~1GB of RAM in buffers/cache plus free, so looked good.
To be 100% sure I created a temporary swap space in a file on the SSD.
(# means that I’m executing this as root, if you type literally with # in front, this will be a comment)
# fallocate -l 1G /swapfile-temp
# dd if=/dev/zero of=/swapfile-temp bs=1024 count=1048576 status=progress
1034236928 bytes (1.0 GB) copied, 4.020716 s, 257 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 4.26152 s, 252 MB/s
If you ask me why I had to dd, I will tell you that I needed to. I checked with command blkid and filesystem was xfs. I believe that was the reason.
The speed writing to the file is fair enough for a swap.
# chmod 600 /swapfile-temp
# mkswap /swapfile-temp
Setting up swapspace version 1, size = 1048572 KiB
no label, UUID=5fb12c0c-8079-41dc-aa20-21477808619a
# swapon /swapfile-temp
I check that memory is good:
# free -h
total used free shared buff/cache available
Mem: 5.7G 4.8G 117M 298M 770M 329M
Swap: 1.0G 0B 1.0G
And finally I check that the Kernel parameter swappiness is not too aggressive:
# sysctl vm.swappiness
vm.swappiness = 30
Cool. 30 is a fair enough value.
2022-01-05 Update for my students that need to add additional 16GB of swap to their SSD drive:
Me, with 4 more Senior BackEnd Engineers wrote the new e-Commerce for a multinational.
The old legacy Software evolved into a different code for every country, making it impossible to be maintained.
The new Software we created used inheritance to use the same base code for each country and overloaded only the specific different behavior of every country, like for the payment methods, for example Brazil supporting “parcelados” or Germany with specific payment players.
We rewrote the old procedural PHP BackEnd into modern PHP, with OOP and our own Framework but we had to keep the transactional code in existing MySQL Procedures, so the logic was split. There was a Front End Team consuming our JSONs. Basically all the Front End code was cached in Akamai and pages were rendered accordingly to the JSONs served from out BackEnd.
It was a huge success.
This e-Commerce site had Campaigns that started at a certain time, so the amount of traffic that would come at the same time would be challenging.
The project was working very well, and after some time the original Team was split into different projects in the company and a Team for maintenance and evolutives was hired.
At certain point they started to encounter duplicate transactions, and nobody was able to solve the mystery.
I’m specialized into fixing impossible problems. They used to send me to Impossible Missions, and I am famous for solving impossible problems easily.
So I started the task with a SRE approach.
The System had many components and layers. The problem could be in many places.
I had in my arsenal of tools, Software like mysqldebugger with which I found an unnoticed bug in decimals calculation in the past surprising everybody.
Previous Engineers involved believed the problem was in the Database side. They were having difficulties to identify the issue by the random nature of the repetitions.
Some times the order lines were duplicated, and other times were the payments, which means charging twice to the customer.
Redis Cluster could also play a part on this, as storing the session information and the basket.
But I had to follow the logic sequence of steps.
If transactions from customer were duplicated that mean that in first term those requests have arrived to the System. So that was a good point of start.
With a list of duplicated operations, I checked the Webservers logs.
That was a bit tricky as the Webserver was recording the Ip of the Load Balancer, not the ip of the customer. But we were tracking the sessionid so with that I could track and user request history. A good thing was also that we were using cookies to stick the user to the same Webserver node. That has pros and cons, but in this case I didn’t have to worry about the logs combined of all the Webservers, I could just identify a transaction in one node, and stick into that node’s log.
I was working with SSH and Bash, no log aggregators existing today were available at that time.
So when I started to catch web logs and grep a bit an smile was drawn into my face. :)
There were no transactions repeated by a bad behavior on MySQL Masters, or by BackEnd problems. Actually the HTTP requests were performed twice.
And the explanation to that was much more simple.
Many Windows and Mac User are used to double click in the Desktop to open programs, so when they started to use Internet, they did the same. They double clicked on the Submit button on the forms. Causing two JavaScript requests in parallel.
When I explained it they were really surprised, but then they started to worry about how they could fix that.
Well, there are many ways, like using an UUID in each request and do not accepting two concurrents, but I came with something that we could deploy super fast.
I explained how to change the JavaScript code so the buttons will have no default submit action, and they will trigger a JavaScript method instead, that will set a boolean to True, and also would disable the button so it can not be clicked anymore. Only if the variable was False the submit would be performed. It was almost impossible to get a double click as the JavaScript was so fast disabling the button, that the second click will not trigger anything. But even if that could be possible, only one request would be made, as the variable was set to True on the first click event.
That case was very funny for me, because it was not necessary to go crazy inspecting the different layers of the system. The problem was detected simply with HTTP logs. :)
People often forget to follow the logic steps while many problems are much more simple.
As a curious note, I still see people double clicking on links and buttons on the Web, and some Software not handling it. :)
This article talks about how at Riot Games they use Slack. Slack is really a powerful tool, and also makes the communication more human in companies with their approach and the funny icons and /giphy. I’m very serious when it comes to work but I recognize the friendly, warm, human and lovely touch these kind of animated icons bring to the conversations.
Remember that life of the SSD is different from spinning drives. I recommend to keep your backups on external spinning drives disconnected most of the time.
I updated it the Nov-01, as I normally do, bringing more content.
I’ve been paid the royalties for he past two months and I reinvested everything (and more from my pocket) in Hardware for working with ZFS.
I was offered by an editorial in The States to publish Python Combat Guide and other of my books worldwide. I was thinking it for a while. It was very good money, translation to multiple languages and platforms and marketing and a lot of promotion, but I would had loss the rights and the Freedom I have now, like the possibility to offer discount coupons to who I want and to update the contents often. So to celebrate my decision for you, readers of the blog, during September, I provide a discounted price of $5 USD for the fist 100 sales instead of the $25 USD suggested price. Use the following link:
As part of my effort to contributing with nice Open Source products to the Community I have made some investments to keep contributing to:
OpenZFS
My old tool for managing ZFS and Network shares easily
I’m writing a new book about managing ZFS for Small Business too, so I show how to operate on this hardware, good points and downsides.
I’m assembling a new Pc with ZFS plenty of Disk Storage within a mix of:
SAS Enterprise grade SSD 2.5″
SATA 12Gb Enterprise grade SSD 2.5″
SATA SSD 2.5″
SATA HDD 2TB 2.5″
SATA HDD 2TB 3.5″
I’m a big fan of Intel, but this time I have chosen AMD. Concretely a AMD Ryzen 7 3700X AM4 8 Core / 16 Threads, 3.6 GHz to 4.4 GHz with Turbo. The reason I chose this CPU is because it only uses 65W but still has 8 Cores / 16 Threads.
Also I want to see the performance of this AMD Ryzen with CMIPS and another important reason is that AMD motherboards support PCI 4.0. I have bought a NVMe SSD Samsung 980 PRO PCI 4.0 (x4) able to read at 6,400 MB/s. I will use this AMD box for running VMs as well. Basically Virtual Box and Docker.
I’ve been surprised that for 169.99 GBP I can have a very good Asus Motherboard with a 2.5 Gb Ethernet: ASUS ROG STRIX B550-F GAMING, AMD B550, AM4, DDR4, PCIe 4.0, SATA3, Dual M.2, CrossFire, 2.5GbE, USB 3.2 Gen2 A+C, ATX.
In order to have an Asus motherboard with a 2.5 Gb Ethernet for Intel I had to jump to a 254 GBP motherboard and Intel is still PCI 3.0. Actually there are PCI 10Gb NICs at 80 GBP so at some point I’ll upgrade my home network from Gigabit to 10 Gb. That will come slowly, but if the new equipment I assemble has 2.5 Gb when I upgrade the main switches to 10 Gb, at least I’ll be able to communicate at 2.5 Gb without ant additional change.
Also memory at 3200, speed that the AMD motherboard can provide, is more than affordable.
This new server will have 64 GB of RAM (Corsair DDR4 Vengeance PC4-25600 (3200)), as I plan to run VMs and use Volumes mounted via iSCSI and locally as block devices to improve my Software. I’ve bought a new UPS to keep it running in case power goes down. That’s something that doesn’t happen often in my city in Ireland, honestly, but I never forget that this happens in Barcelona two or three times per year, and that a high tension spike can burn your motherboard, drives, or electronics like the TV or the fridge. I’ve bought as well a new KVM Switch, a HDMI 4K and USB too one, so I don’t have to have so many keyboards. My logitech M720 allowed me to use it with 3 computers, but still I want something more operational. The KVM I bought allow me to switch with a button or within a hotkey in the keyboard.
I bought a new Icy box fox handling 6 2.5 drives in just one bay of the tower, and a 850 Watt Corsair PSU that will be able to power the many drives I want at the same time.
ZFS on Ubuntu 20.04.1 LTS A guide for Small/Medium Business and power users to work with ZFS. https://leanpub.com/zfs-ubuntu
Those can be purchased while I’m still working on them and get the updates that I’ll be publishing and keeping a communication with me about doubts or improvements.
Halloween Software Offers
I saw some Halloween offers and I purchased Software licenses for Software I use.
I contribute a lot to Open Source, and many years ago before Open Source existed I was creating Freeware Software. But I think that good commercial Software deserves to be supported. Like everything in life, if they are doing a good work that is useful to me, why not giving them support?. It is also a way to make sure they will continue producing amazing Software. And in the other hand, myself, I create Software. Some times commercial Software, and I like to be paid, so I apply the same principle.
This article covers the desperate situation where you had generated one or more instances, instructed Amazon to use a SSH Key Pair certs where only you have the Private Key, your instances are running, for example, an eCommerce site, running for months, and then you loss your Private Key (.pem file), and with it the SSH access to your instances’ Data.
Actually I’ve seen this situation happening several times, in actual companies. Mainly Start ups. And I solved it for them.
Assuming that you didn’t have a secondary method to access, which is another combination of username/password or other user/KeyPairs, and so you completely lost the access to the Database, the Webservers, etc… I’m going to show you how to recover the data.
For this article I will consider an scenario where there is only one Instance, which contains everything for your eCommerce: Webserver, code, and Database… and is a simple config, with a single persistent drive.
Warning: be very careful as if you use ephemeral drives, contents will be lost is you power off the instance.
Method 1: Quicker, launching a new instance from the previous
Step1: The first step you will take is to close the access from outside, using the Firewall, to avoid any new changes going to the disk. You can allow access to the instance only from your static Ip in the office/home.
Step 2: You’ll wait for 5 minutes to allow any transaction going on to conclude, and pending writes to be flushed to disk.
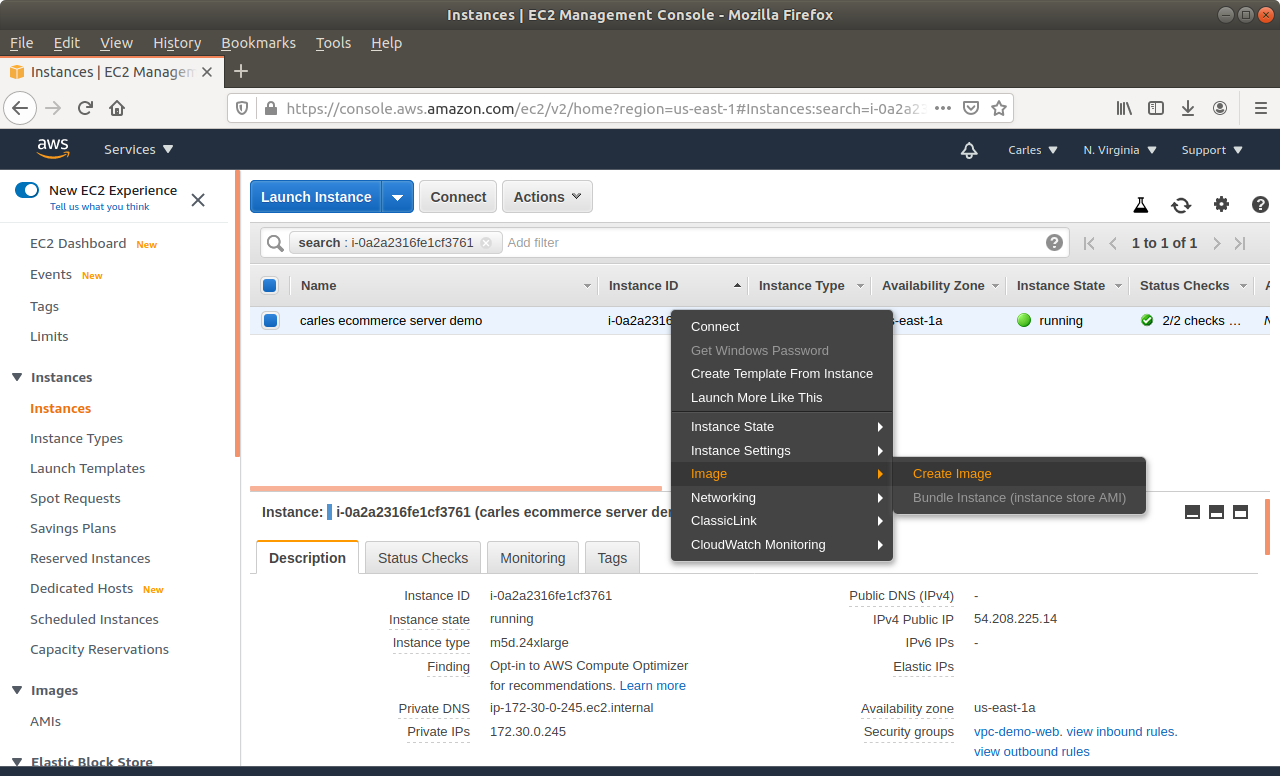
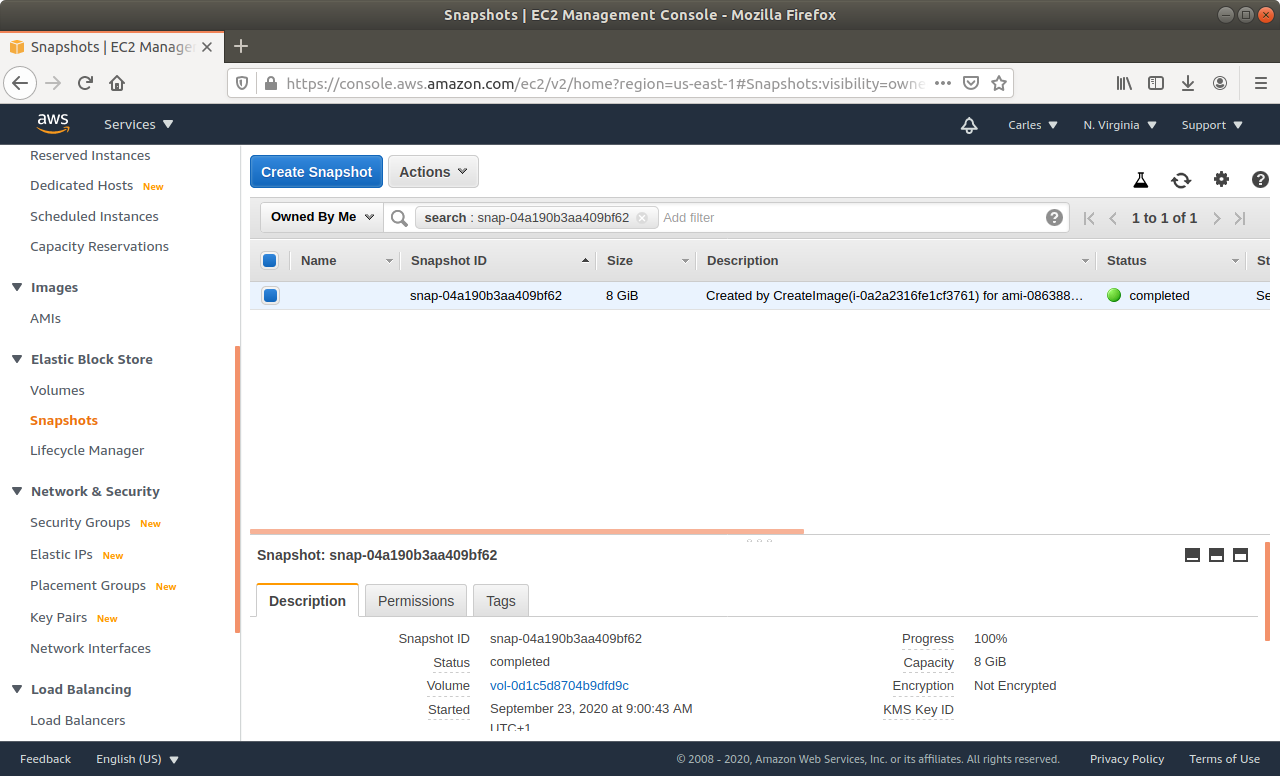
Step 3: From Amazon AWS Console, EC2, you’ll request an Snapshot. That step is to try to get extra security. Taking an Snapshot from a live, mounted, filesystem, is not the best of ideas, specially of a Database, but we are facing a desperate situation so we’re increasing the numbers of leaving this situation without Data loss. This is just for extra security and if everything goes well at the end you will not need this snapshot.
Make sure you select No reboot.
Step 4: Be very careful if you have extra drives and ephemeral drives.
Step 5: Wait till the Snapshot completes.
Step 6: Then request a graceful poweroff. Amazon will try to poweroff the Server in a gentle way. This may take two minutes.
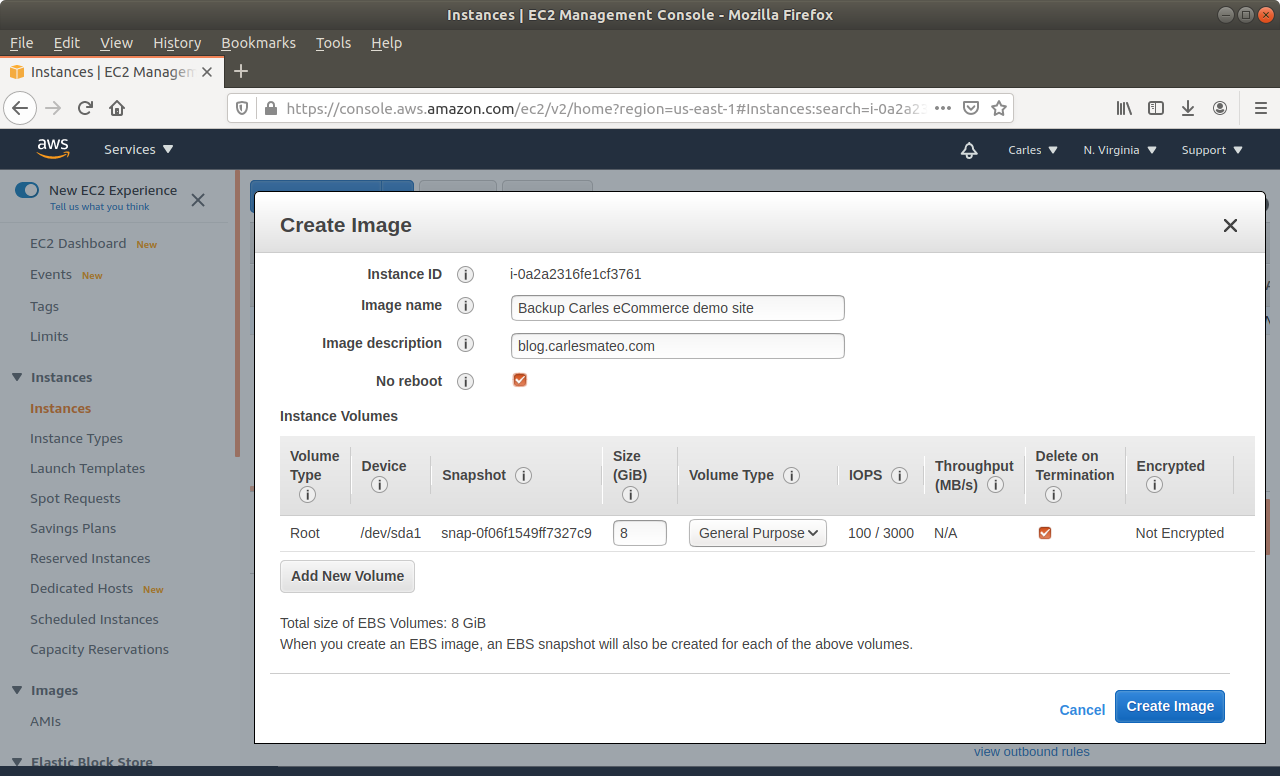
Step 7: When the instance is powered off, request a new Snapshot. This is the one we really want. The other was just to be more safe. If you feel confident you can just unclick No Reboot on the previous Step and do only one Snapshot.
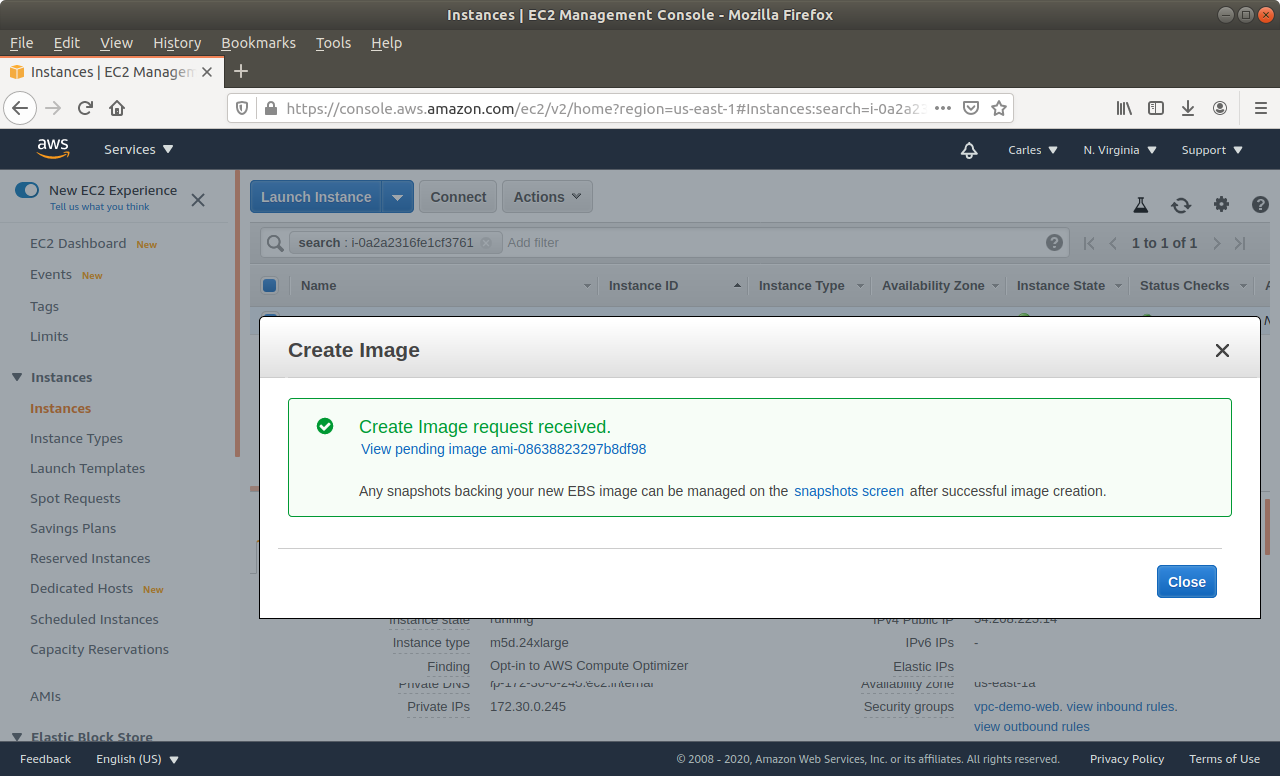
Step 8: Wait till the Snapshot completes.
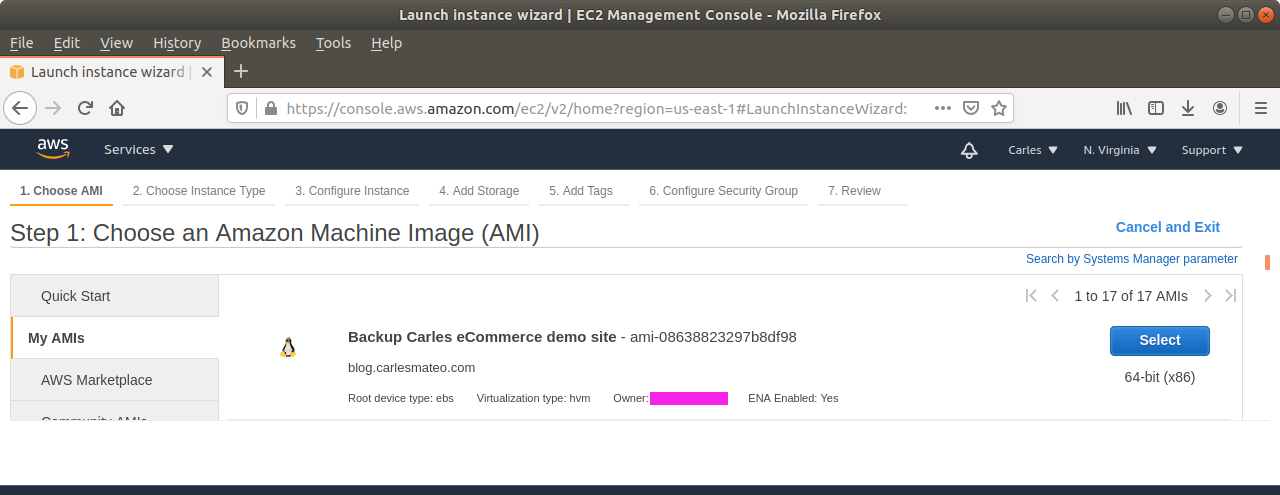
Step 9: Generate and upload the new key you will use to AWS Console, or ask Amazon to generate a key pair for you. You can do it while creating the new instance through the wizard.
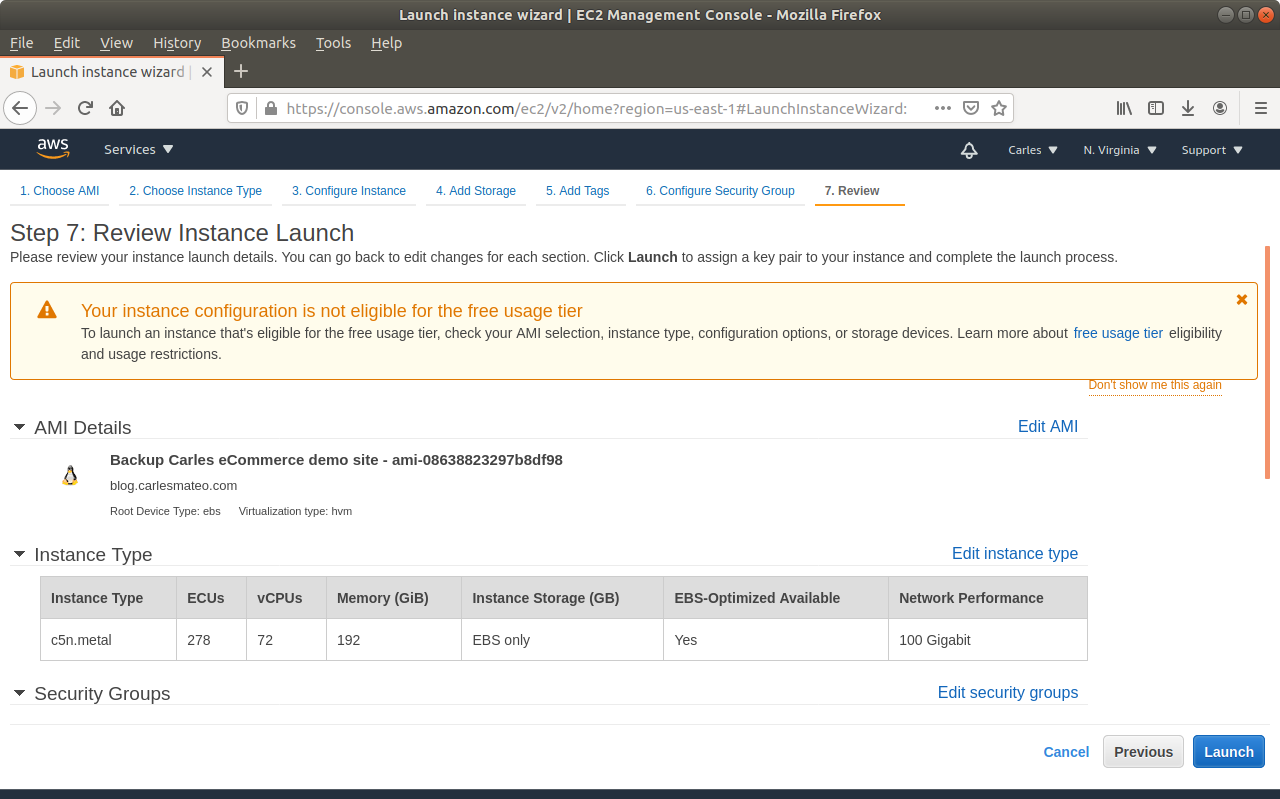
Step 10: Launch a new instance, based on your snapshot AMI. This will generate a copy of your previous instance (using the Snapshot) for the new one. Select the new Key pair. Finish assigning the Security groups, the elastic ip…
Step 11: Start the new instance. You can select a different flavor, like a more powerful instance, if you prefer. (scale vertically)
Step 12: Test your access by login via SSH with the new pair keys and from your static Ip which has access in the Firewall.
Step 13: Check that the web Starts correctly, check the Database logs to see if there is any corruption. Should not have any if graceful shutdown went well.
Step 14: Reopen the access from the Firewall, so the world can connect to your instance.
Method 2: Slower, access the Data and rebuild whatever you need
The second method is exactly the same until Step 6 included.
Step 7: After this, you will create a new instance based on your favorite OS, with a new pair of Keys.
Step 8: You’ll detach the Volume from the eCommerce previous instance (the one you lost access).
Step 9: You’ll attach the Volume to the new instance.
Step 10: You’ll have access to the Data from the previous instance in the new volume. type cat /proc/partitions or df -h to see the mountpoints available. You can then download or backup, or install the Software again and import the Database…
Step 11: Check that everything works, and enable the access worldwide to the Web in the Firewall (Security Group Inbound Rules).
If you are confident enough, you can use this method to upgrade the OS or base Software of your instance, making it part of your maintenance window. For example, to get the last version of Ubuntu or CentOS, MySQL, Python or PHP, etc…
I wanted to automate certain operations that we do very often, and so I decided to do a PoC of how handy will it be to create GUI applications that can automate tasks.
As locating information in several repositories of information (ldap, databases, websites, etc…) can be tedious I decided to create a small program that queries LDAP for the information I’m interested, in this case a Location. This small program can very easily escalated to launch the VPN, to query a Database after querying LDAP if no results are found, etc…
I share with you the basic application as you may find interesting to create GUI applications in Python, compatible with Windows, Linux and Mac.
I’m super Linux fan but this is important, as many multinationals still use Windows or Mac even for Engineers and SRE positions.
With the article I provide a Dockerfile and a docker-compose.yml file that will launch an OpenLDAP Docker Container preloaded with very basic information and a PHPLDAPMIN Container.
This article is more an exercise, like a game, so you get to know certain things about Linux, and follow my mental process to uncover this. Is nothing mysterious for the Senior Engineers but Junior Sys Admins may enjoy this reading. :)
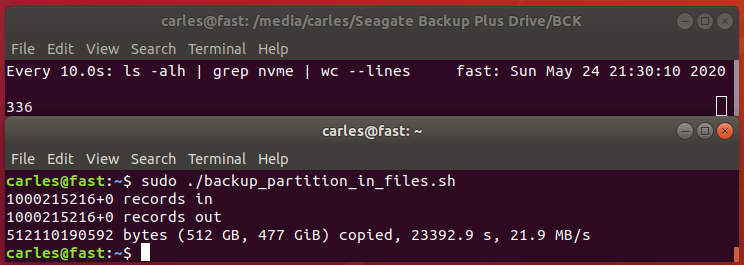
Ok, so the first thing is I wrote an script in order to completely backup my NVMe hard drive to a gziped file and then I will use this, as a motivation to go deep into investigations to understand.
So basically, we are going to restart the computer, boot with Linux Live USB Key, mount the Seagate Hard Drive, and run the script.
We are booting with a Live Linux Cd in order to have our partition unmounted and unmodified while we do the backup. This is in order to avoid corruption or data loss as a live Filesystem is getting modifications as we read it.
The problem with this first script is that it will generate a big gzip file.
By big I mean much more bigger than 2GB. Not all physical supports support files bigger than 2GB or 4GB, but even if they do, it’s a pain to transfer this over the Network, or in USB files, so we are going to do a slight modification.
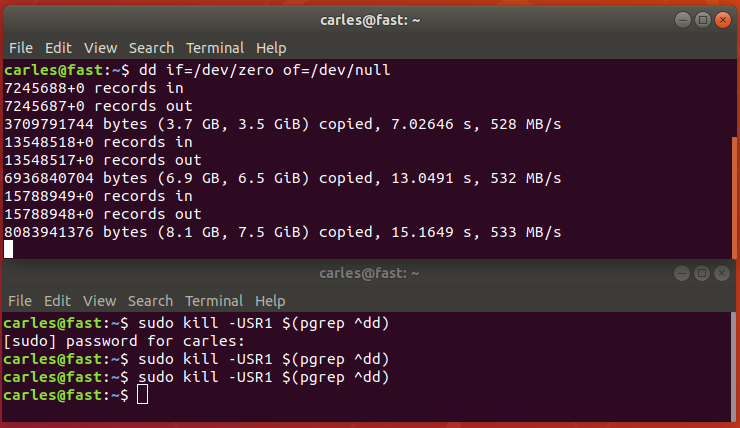
Then one may ask himself, wait, if pipes use STDOUT and STDIN and dd is displaying into the screen, then will our gz file get corrupted?.
I like when people question things, and investigate, so let’s answer this question.
If it was a young member of my Team I would ask:
Ok, try,it. Check the output file to see if is corrupted.
So they can do zcat or zless to inspect the file, see if it has errors, and to make sure:
gzip -v -t nvme.img.gz
nvme.img.gz: OK
Ok, so what happened?, because we were seeing output in the screen.
Assuming the young Engineer does not know the answer I would had told:
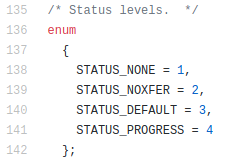
Ok, so you know that if dd would print to STDOUT, then you won’t see it, cause it would be sent to the pipe, so there is something more you’re missing. Let’s check the source code of dd to see what status=progress does
And then look for “progress”.
Soon you’ll find things like everywhere:
if (progress_time)
fputc ('\r', stderr);
Ok, pay attention to where is the data written: stderr. So basically the answer is: dd status=progress does not corrupt STDOUT and prints into the screen because it uses STDERR.
Other funny ways to get the progress would be to use:
So you would see in real time what was the advance and finally 512GB where compressed to around 336GB in 336 files of 1 GB each (except the last one)
Another funny way would had been sending USR1 signal to the dd process:
Hope you enjoyed this little exercise about the importance of going deep, to the end, to understand what’s going on on the system. :)
Instead of gzip you can use bzip2 or pixz. pixz is very handy if you want to just compress a file, as it uses multiple processors in parallel for the tasks.
xz or lrzip are other compressors. lrzip aims to compress very large files, specially source code.
You do df -h or ls / and the terminal freezes and not even CTRL + C works, you have a lock.
Normally this is due to a lock of the system trying to perform an IO.
Could be a physical spinning disk failing, but the most probably nowadays is that you have a network mount point and it is timing out.
If you execute mount and you get a timeout, and when you finally see the list you see a NFS, iSCSI or another kind of Network mount (you will see an Ip Address), check for errors.
To do this in CentOS/RHEL you can do as root:
dmesg | grep -i "timed"
or depending on the System
cat /var/log/messages | grep -i "timed"
You’ll get something like this:
[root@compute01 carles]# dmesg -T | grep timed | head -n5
[Fri Mar 20 02:27:44 2020] nfs: server storage07 not responding, timed out
[Fri Mar 20 02:27:44 2020] nfs: server storage07 not responding, timed out
[Fri Mar 20 02:27:44 2020] nfs: server storage07 not responding, timed out
[Fri Mar 20 02:27:44 2020] nfs: server storage07 not responding, timed out
[Fri Mar 20 02:27:45 2020] nfs: server storage07 not responding, timed out
Please note I use dmesg -T in order to have human readable date instead of Unix Epoch.